




23.8億件もあるRedditの投稿をまるごと保存してローカルのオフラインで検索できる「Redd-Archiver」
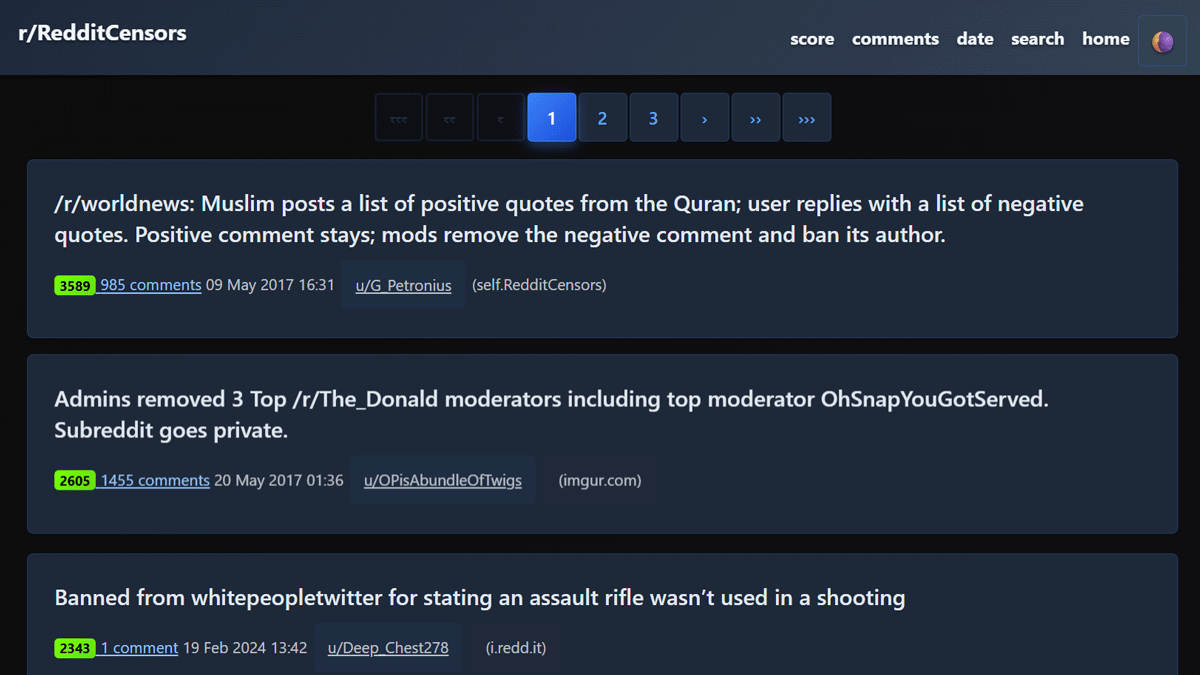
世界最大級のコミュニティSNSであるRedditは2005年に始まり、2024年12月時点で23.8億件もの膨大な投稿が蓄積されています。これらの過去の全ての投稿をローカルに保存してオフラインで閲覧・全文検索可能にするツール「Redd-Archiver」が公開されています。
19-84/redd-archiver: A PostgreSQL-backed archive generator that creates browsable HTML archives from link aggregator platforms including Reddit, Voat, and Ruqqus.
https://github.com/19-84/redd-archiver
◆デモサイト
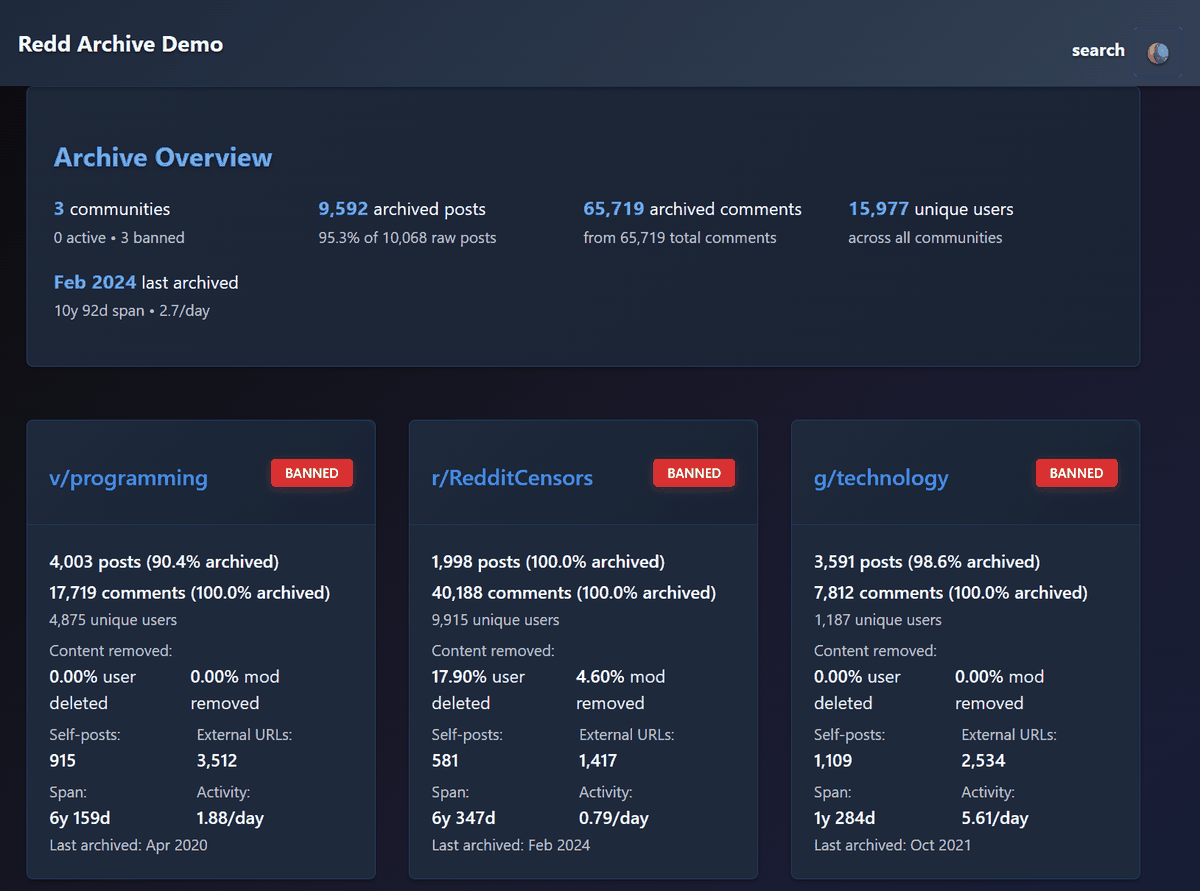
Redd Archive - Browse 9,592 Posts Across 3 Communities
https://online-archives.github.io/redd-archiver-example/
◆Redd-Archiverの特徴
・JavaScriptを使用せずHTMLとCSSのみで構成
・ライトモード、ダークモード対応
・レスポンシブデザインによりPCでもスマホでも閲覧可能
・キーボードナビゲーションおよびスクリーンリーダーに対応
・保守・拡張用に18個の専用モジュールを用意
・REST APIやMCPによる投稿やコメント取得など、プログラムからアクセスできる30以上のエンドポイント
・Torでの利用を想定した設計
・PostgreSQLを用意することで全文検索が可能
・すでに閉鎖されているVoatやRuqqusのアーカイブにも対応
◆インストール方法
今回はWindowsにDocker DesktopとGit for WindowsのGit Bashを用意した環境で構築します。作業フォルダでRedd-Archiverのリポジトリをクローンします。
git clone https://github.com/19-84/redd-archiver.git
redd-archiverフォルダに移動し、空のデータフォルダを作成。
cd redd-archiver mkdir -p data output/.postgres-data logs tor-public
環境設定ファイル「.env」を「.env.example」からコピーします。
cp .env.example .env
.envファイルをテキストエディタで開き「POSTGRES_PASSWORD」を指定し、その他の設定値も必要に応じて変更します。
POSTGRES_PASSWORD="任意の文字列"
コンテナを起動します。
docker compose up -d
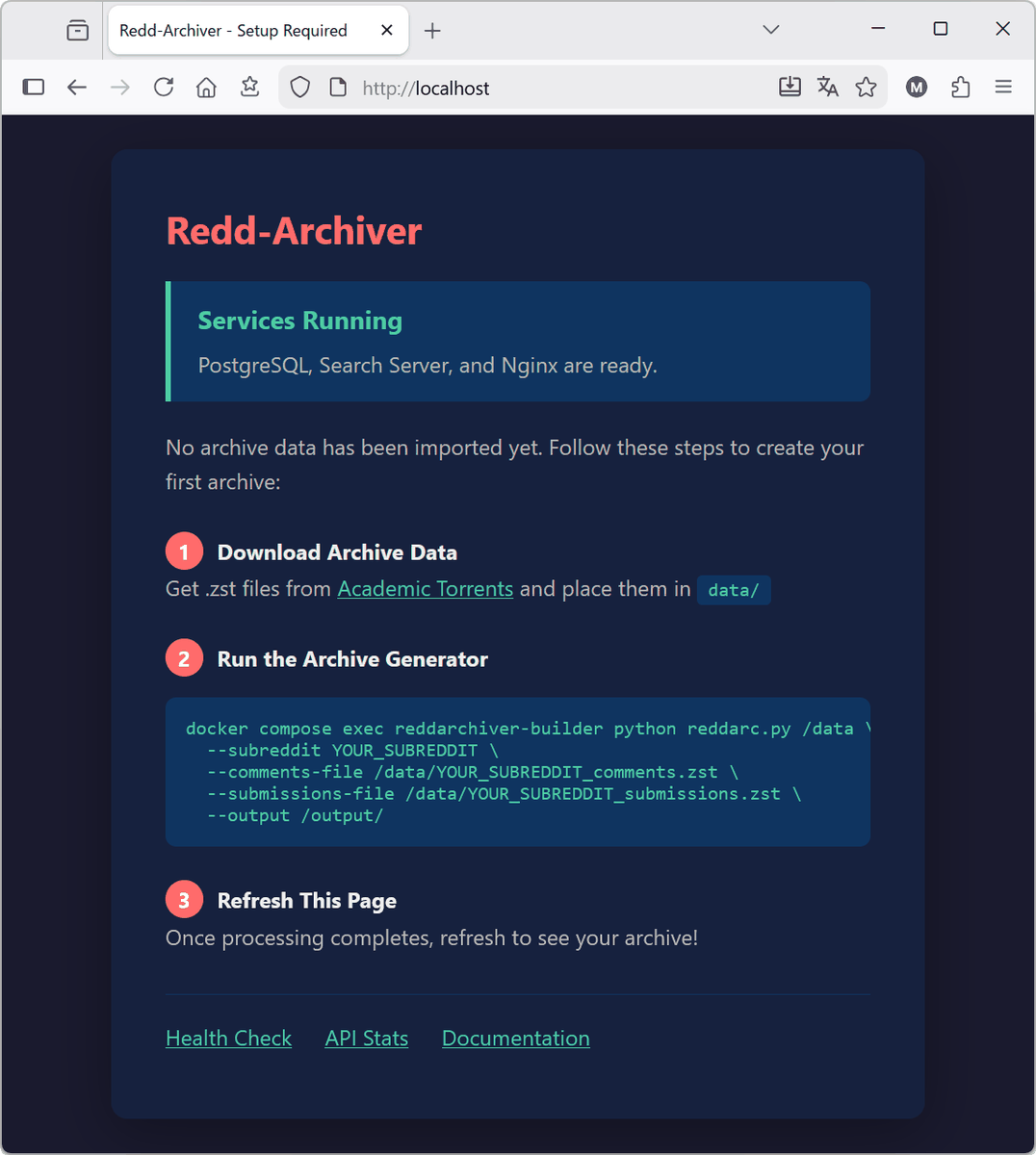
コンテナが起動したらブラウザで「http://localhost」にアクセスします。初期ページが表示されればツールの用意は完了です。
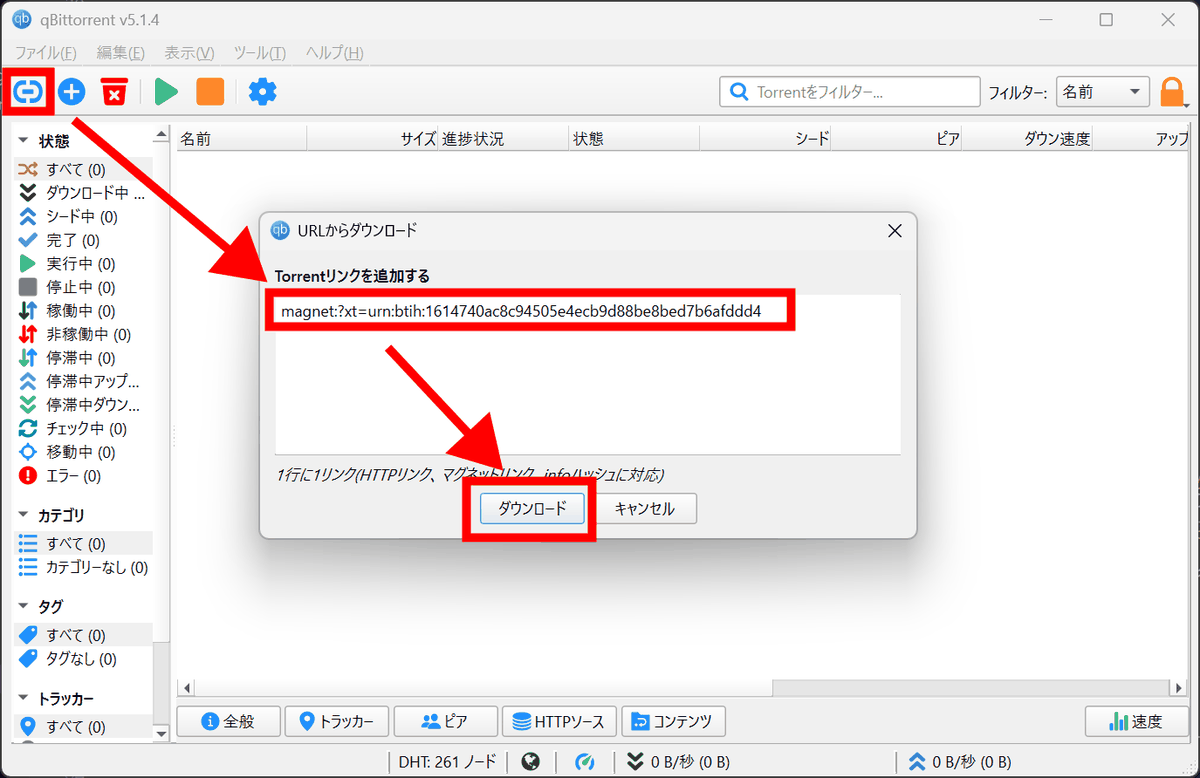
元になるRedditの2005年6月から2024年12月までの全ての投稿データはAcademic Torrentsに公開されています。「サブレディット」と呼ばれるテーマやコミュニティごとに分けられたZSTファイルが約8万ほどあるためqBittorrentなどTorrentが利用できるダウンローダーでマグネットリンクからファイルを取得しました。
magnet:?xt=urn:btih:1614740ac8c94505e4ecb9d88be8bed7b6afddd4
qBittorrentを起動し「リンク追加」ボタンからマグネットリンクを入力し「ダウンロード」をクリック。
ファイルの一覧が表示されるので、1つのサブレディットの元の投稿とコメントのセットのデータを選択、保存先をredd-archiverフォルダ下のdataフォルダに設定して「OK」をクリック。
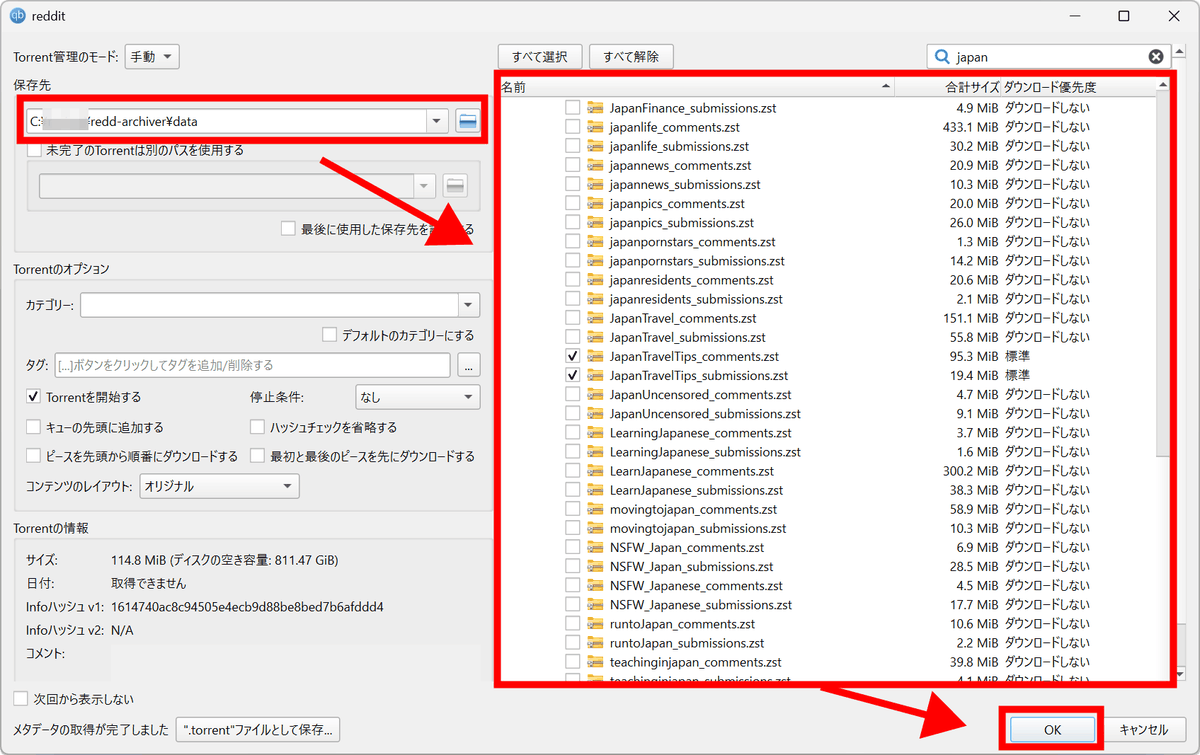
ダウンロードが完了したら「YOUR_SUBREDDIT」部分をダウンロードしたサブレディット名に置き換え以下の生成用コマンドを実行します。
docker compose exec reddarchiver-builder sh -lc \ 'uv run python reddarc.py /data/reddit/subreddits24 \ --subreddit YOUR_SUBREDDIT \ --comments-file /data/reddit/subreddits24/YOUR_SUBREDDIT_comments.zst \ --submissions-file /data/reddit/subreddits24/YOUR_SUBREDDIT_submissions.zst \ --output /output'
エラーが発生する場合は、以下のコマンドを実行してから再度生成用コマンドを実行してください。
docker compose exec reddarchiver-builder sh -lc 'uv remove playwright && \ touch /app/README.md'
今回は1つのサブレディットについて、116MBのファイル容量で約63万件の投稿を含むアーカイブを処理します。
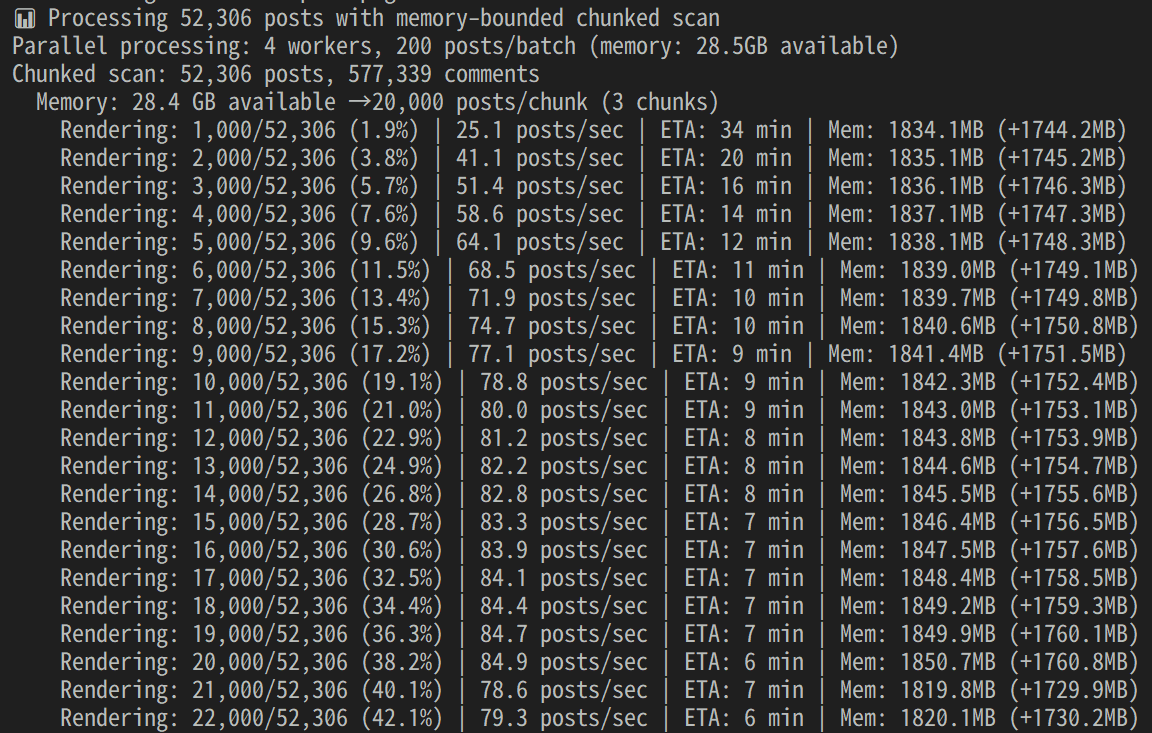
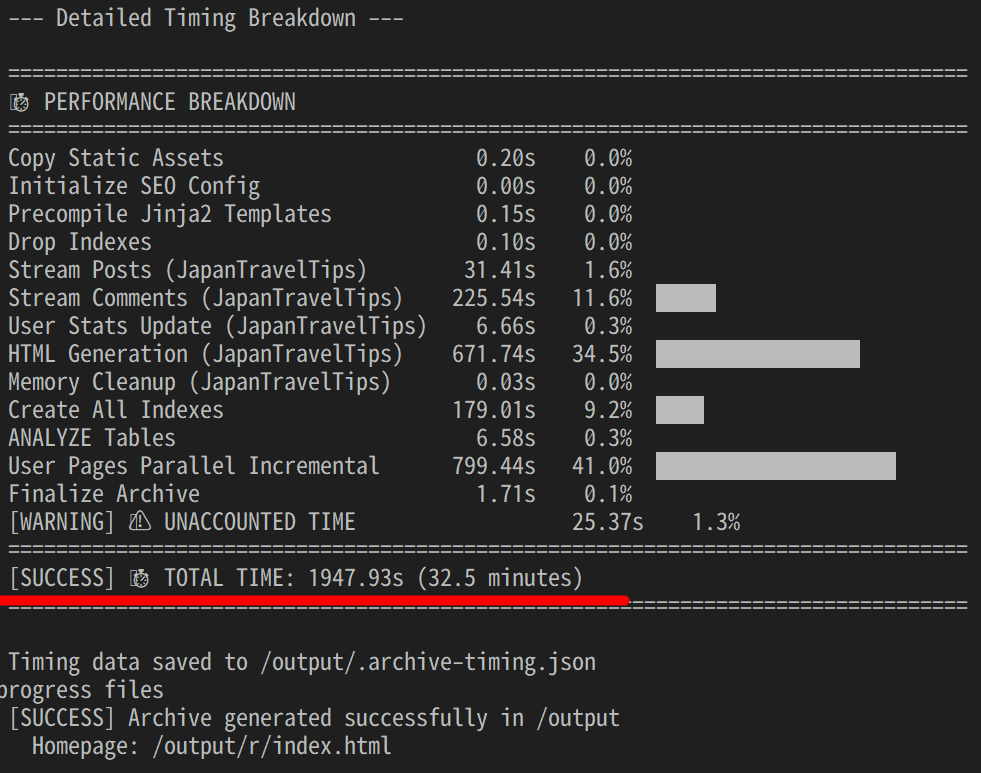
作業が完了し、それぞれの作業の内訳が出力されています。今回は約33分程かかりました。
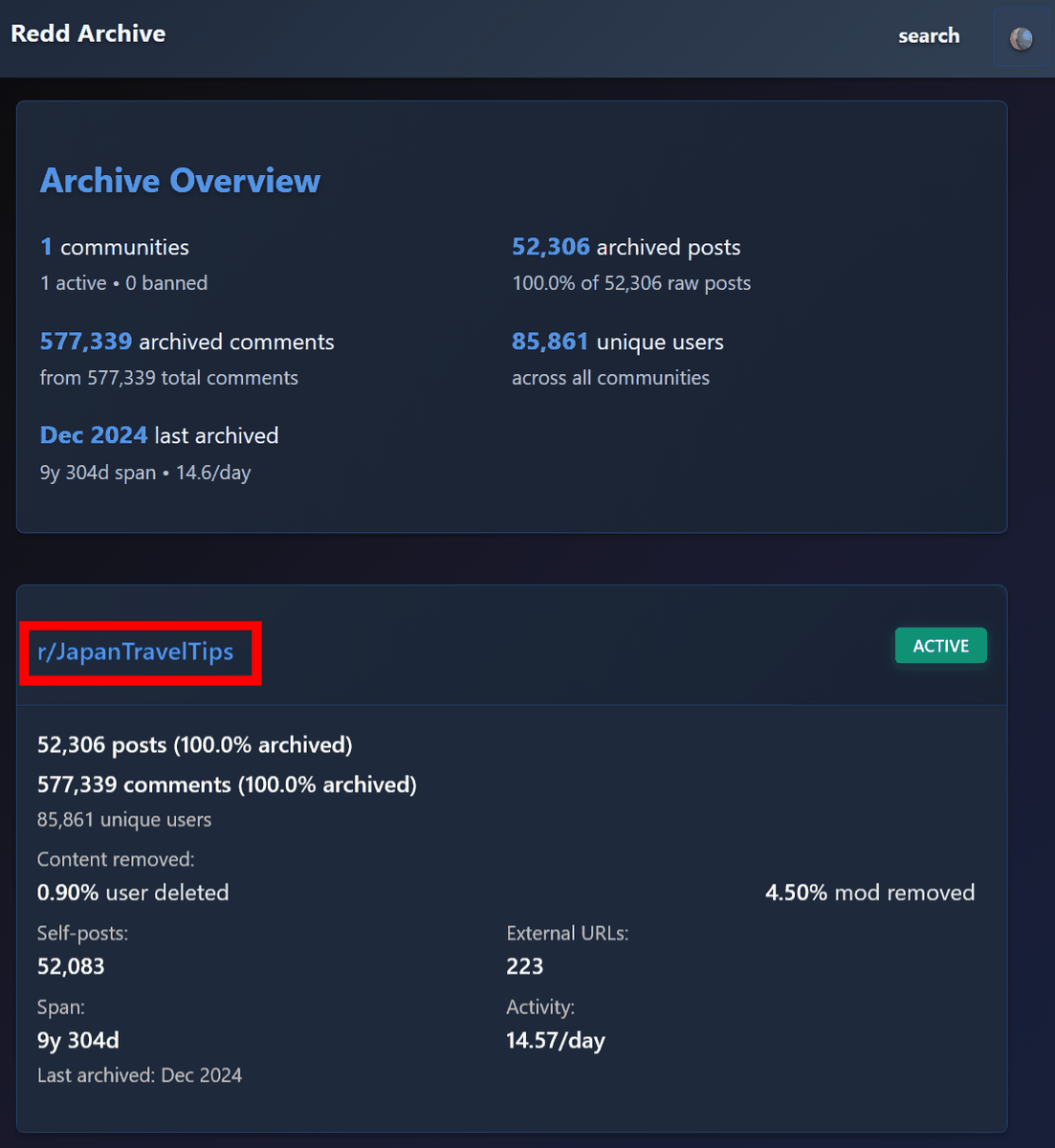
ブラウザで「http://localhost/」を更新すると、今回作成したアーカイブの統計情報が表示されます。サブレディット名をクリックすると…
投稿のリストが表示されるので、見たい投稿名をクリック。
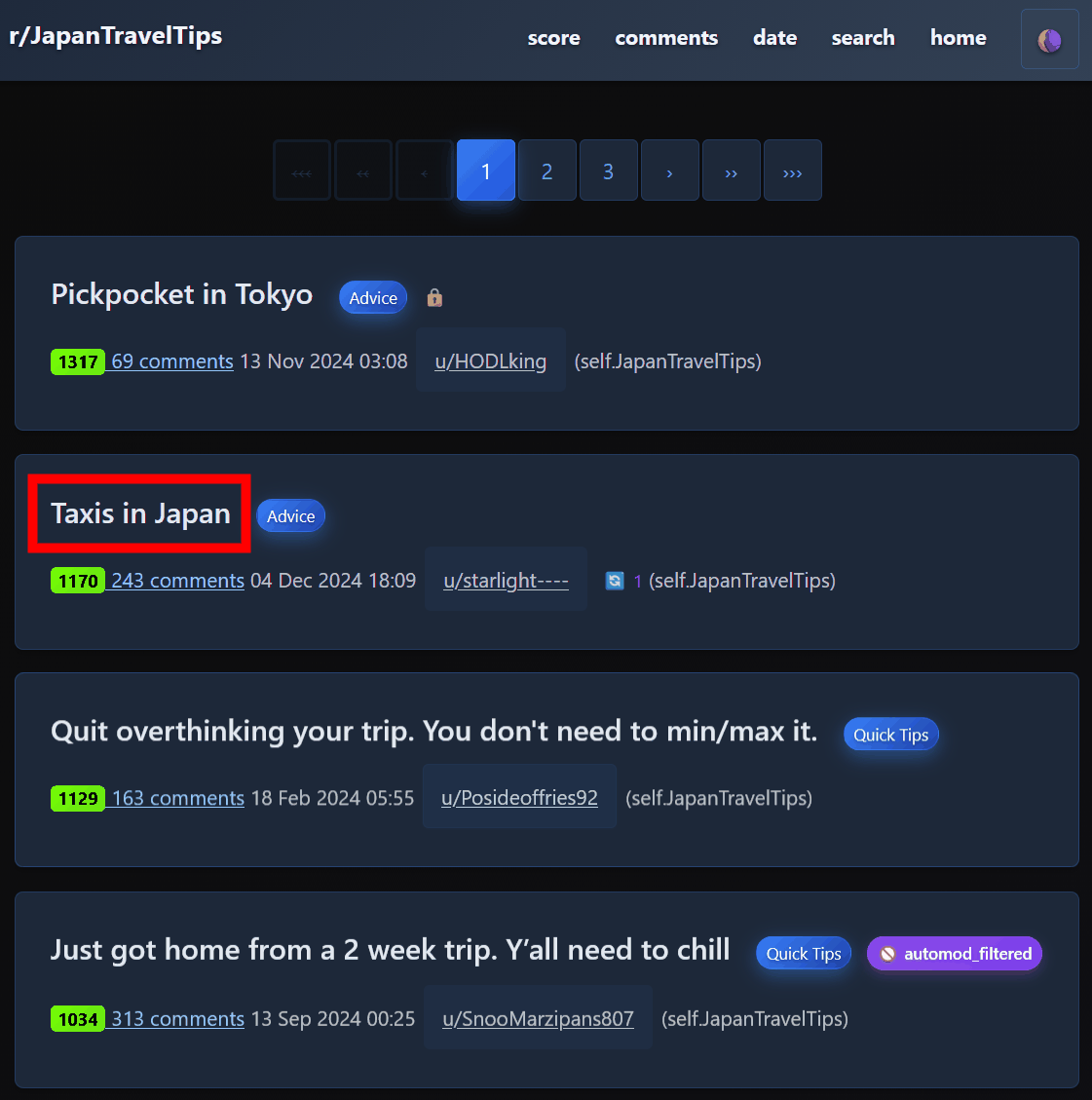
投稿内容やコメントが確認できます。
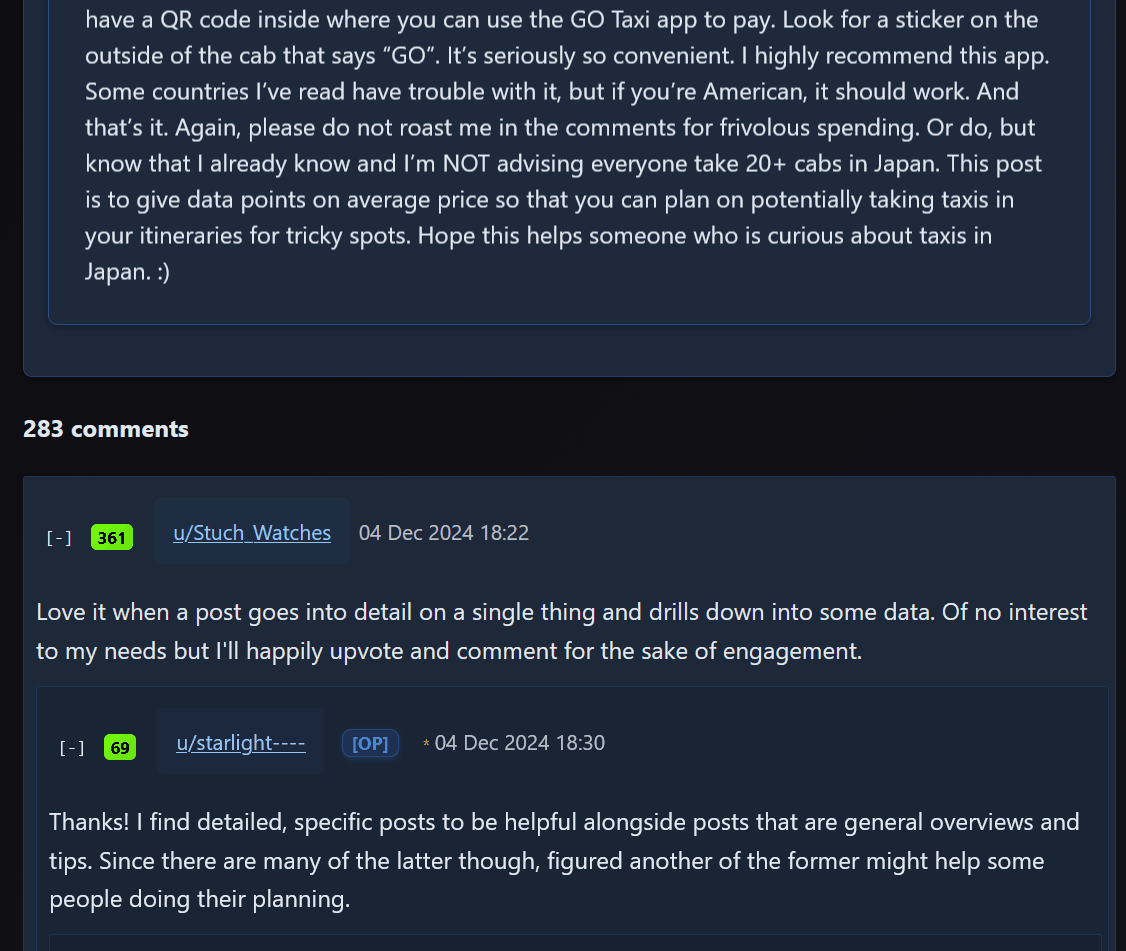
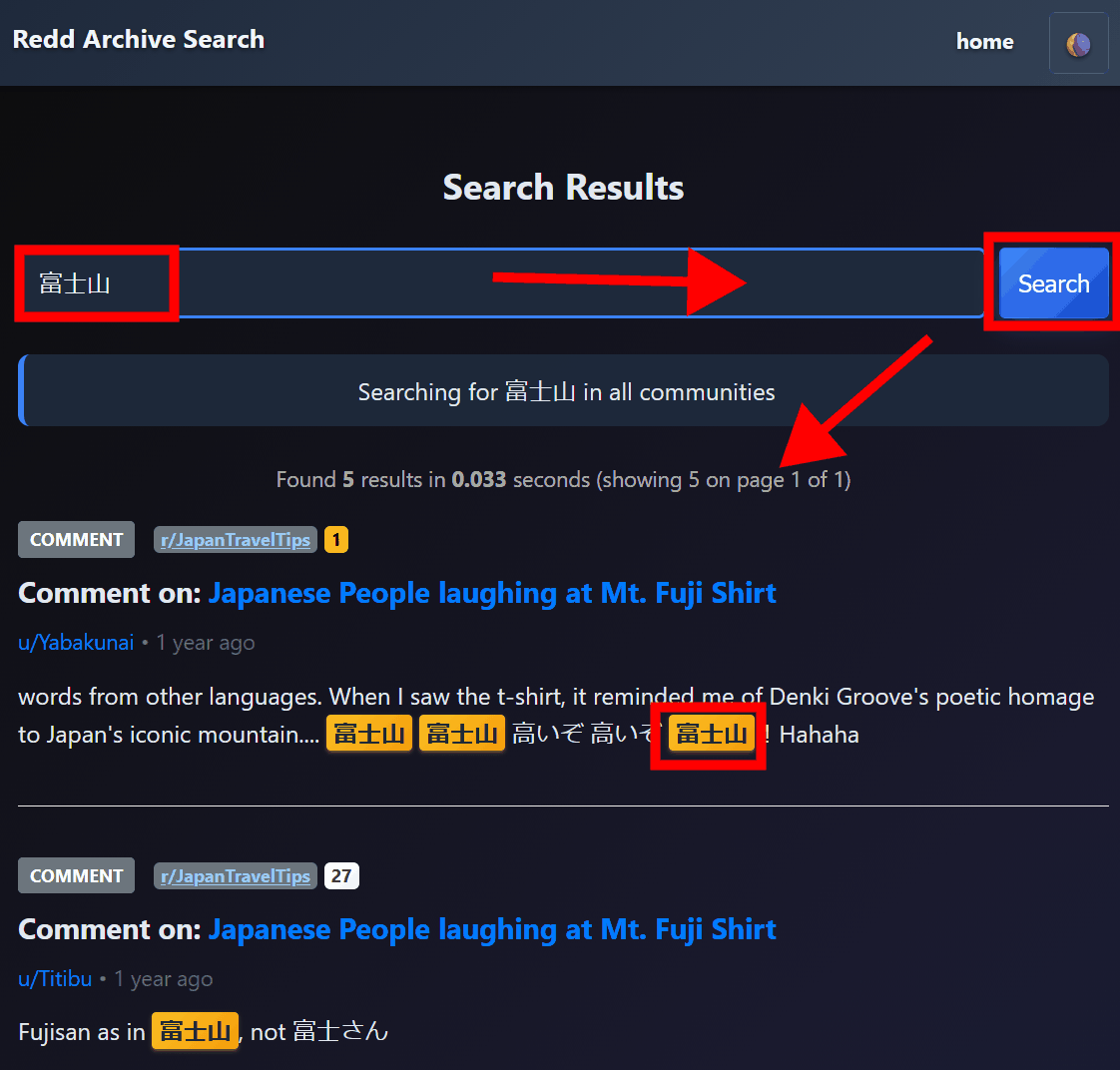
検索を行うためページ上部の「search」をクリック。
検索ページが表示されるので検索したいキーワードを入力して「search」をクリックすると、キーワードを含む投稿のリストが表示されます。
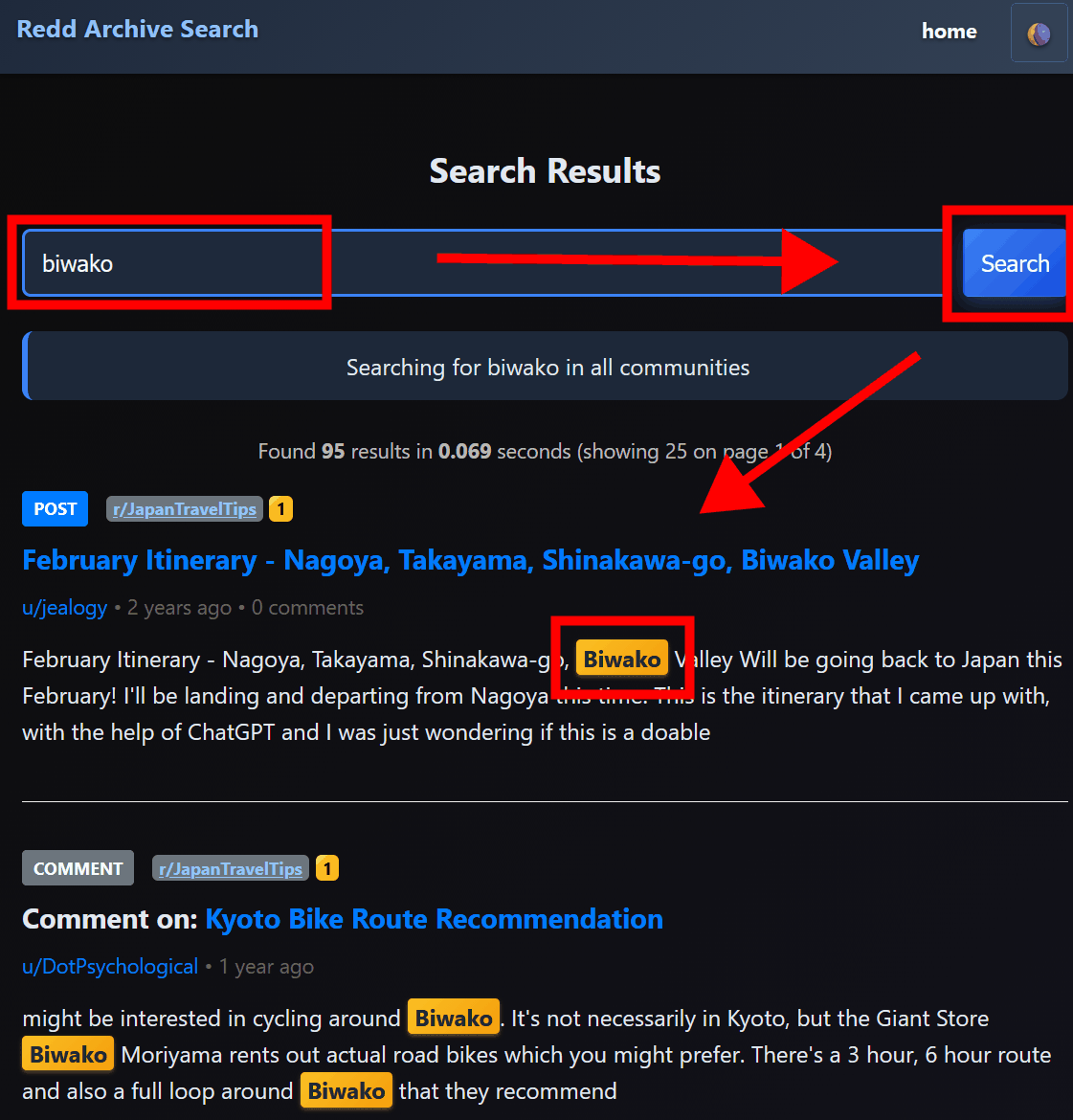
データベースの仕様として日本語での検索は正しく行えず、「富士山」に対して「富士山」で検索すれば抽出されますが「富士」で検索しても抽出されませんでした。
なお、見積もりとして100GB分の投稿データのZSTファイルはHTML化すると1.5TBになり、データベース用には160GBの容量が必要とのことです。Redd‑Archiverでは適度に分散させたインスタンスを用意することを推奨しています。

・関連記事
Redditのモデレーターが映画のセックスシーンを共有したとして有罪に、女性の品位をおとしめたというレア判決 - GIGAZINE
Googleの検索結果に表示されたコンテンツをAIトレーニングのため違法に盗んだとしてRedditがPerplexityなど4社を提訴 - GIGAZINE
RedditがInternet Archiveをブロック、AI企業によるWayback Machineのアーカイブ不正利用を阻止するため - GIGAZINE
Redditがコミュニティの抗議活動を抑え込むポリシー変更を実施、大規模サブレディットの公開設定切り替え時にリクエスト提出を義務化 - GIGAZINE
Redditが掲示板上の話題を検索したり要約したりできるチャットAI「Reddit Answers」を発表 - GIGAZINE
・関連コンテンツ



in ソフトウェア, レビュー, Posted by darkhorse_logmk
You can read the machine translated English article 'Redd-Archiver' allows you to save all 2….