




CloudflareがAIクローラーを無限生成迷路に閉じ込める「AI Labyrinth」を発表

クラウドコンピューティングサービスのCloudflareが、不正行為をするボットをAIが生成する迷路に閉じ込める「AI Labyrinth」を発表しました。
Trapping misbehaving bots in an AI Labyrinth
https://blog.cloudflare.com/ai-labyrinth/
AIのトレーニングに利用するデータをインターネット上からスクレイピング(収集)するのに使用されるボットがクローラーです。クローラーはインターネット上からあらゆる情報を収集するため、AI企業は「生成AIモデルのトレーニングにコンテンツを利用された」としてコンテンツ制作者から訴訟を起こされています。
こういった動きに対処するため、AI企業の中には「クローラーが収集したデータをAIのトレーニングに利用しないようにするためのオプション」を提供しているところもあります。他にも、AIトレーニング用のスクレイピングを実行するクローラーをブロックするための「robots.txt」も存在しています。しかし、AI企業はそれぞれ異なるクローラーを使用しており、クローラーの名前も頻繁に更新されているため、企業によっては「robots.txt」の要求を無視するケースもあるそうです。
生成AI検索エンジンのPerplexityはクローラーを防ぐ「robots.txt」を無視してウェブサイトから情報を抜き出している - GIGAZINE

2025年3月19日、Cloudflareは「スクレイピング禁止の指示に従わないクローラー」を混乱させ、リソースを浪費させるための新しいアプローチとして「AI Labyrinth」を発表しました。
AI Labyrinthは「スクレイピング禁止の指示に従わないクローラー」を検出すると、クローラーのリクエストをブロックするのではなく、クローラーが移動したくなるほど説得力のある一連のAI生成ページへのリンクを提供します。このコンテンツは本物に見えますが、あくまでAIが生成したコンテンツであり、Cloudflareが保護しているウェブサイトのコンテンツではないため、クローラーは時間とリソースを無駄にすることとなるわけです。
AI Labyrinthは「説得力のある人間が生成したかのようなコンテンツ」を生成するため、オープンソースモデルのWorkers AIを使用して、さまざまなトピックに関する独自のHTMLページを作成します。このコンテンツをオンデマンドで作成するのではなく、クロスサイトスクリプティング(XSS)脆弱性を防ぐためにコンテンツをサニタイズし、より高速に取得できるようCloudflare R2に保存する事前生成パイプラインを実装しました。
さらに、最初にさまざまなトピックのセットを生成し、次にトピックごとにコンテンツを作成することで、より多様で説得力のある結果が得られることも判明しています。また、インターネット上での誤情報の拡散につながる不正確なコンテンツを生成しないことも重要であるため、「生成するコンテンツは現実的で科学的事実に関連するものであり、クロール対象のサイトと関連性がないもの、または独自のものではないものにする必要があります」とCloudflareは説明しています。
CloudflareはAI Labyrinthを無料プランを含むあらゆるユーザーに提供予定です。
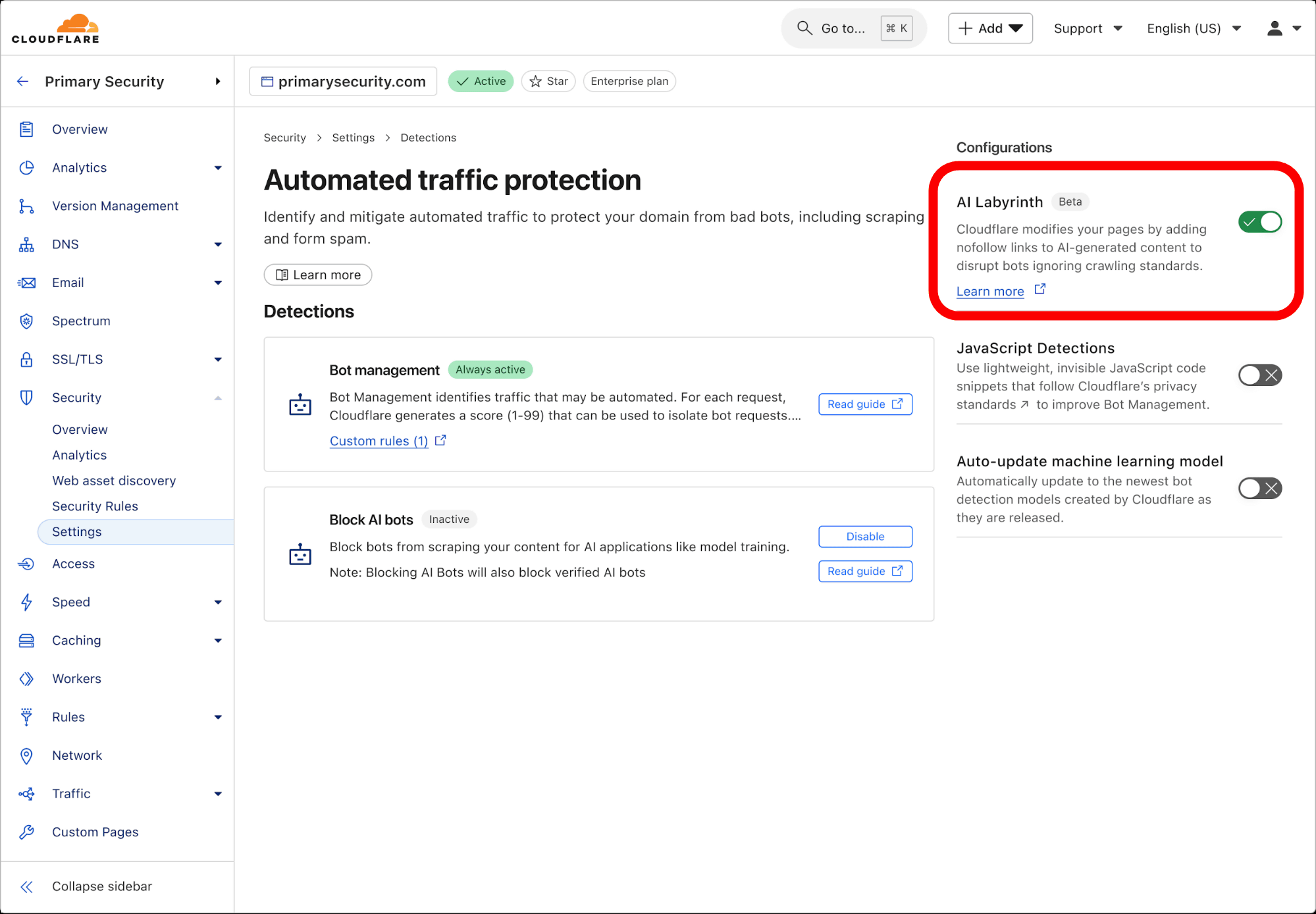
AI Labyrinthが生成したコンテンツは、ページの元の構造やコンテンツを乱すことなく、カスタムHTML変換プロセスによって既存のページに隠しリンクとしてシームレスに統合されます。AI Labyrinthが生成する各ページには、検索エンジンのインデックス作成を防止してSEOを保護するための適切なメタディレクティブが含まれるそうです。また、慎重に実装された属性とスタイル設定により、これらのリンクが人間の訪問者には表示されないように配慮されています。加えて、一般ユーザーへの影響を最小限に抑えるため、リンクは不正なクローラーであるとの疑いがある場合にのみ表示されるそうです。正当なユーザーと検証済みのクローラーは、通常通りにコンテンツを閲覧できるよう設計されています。
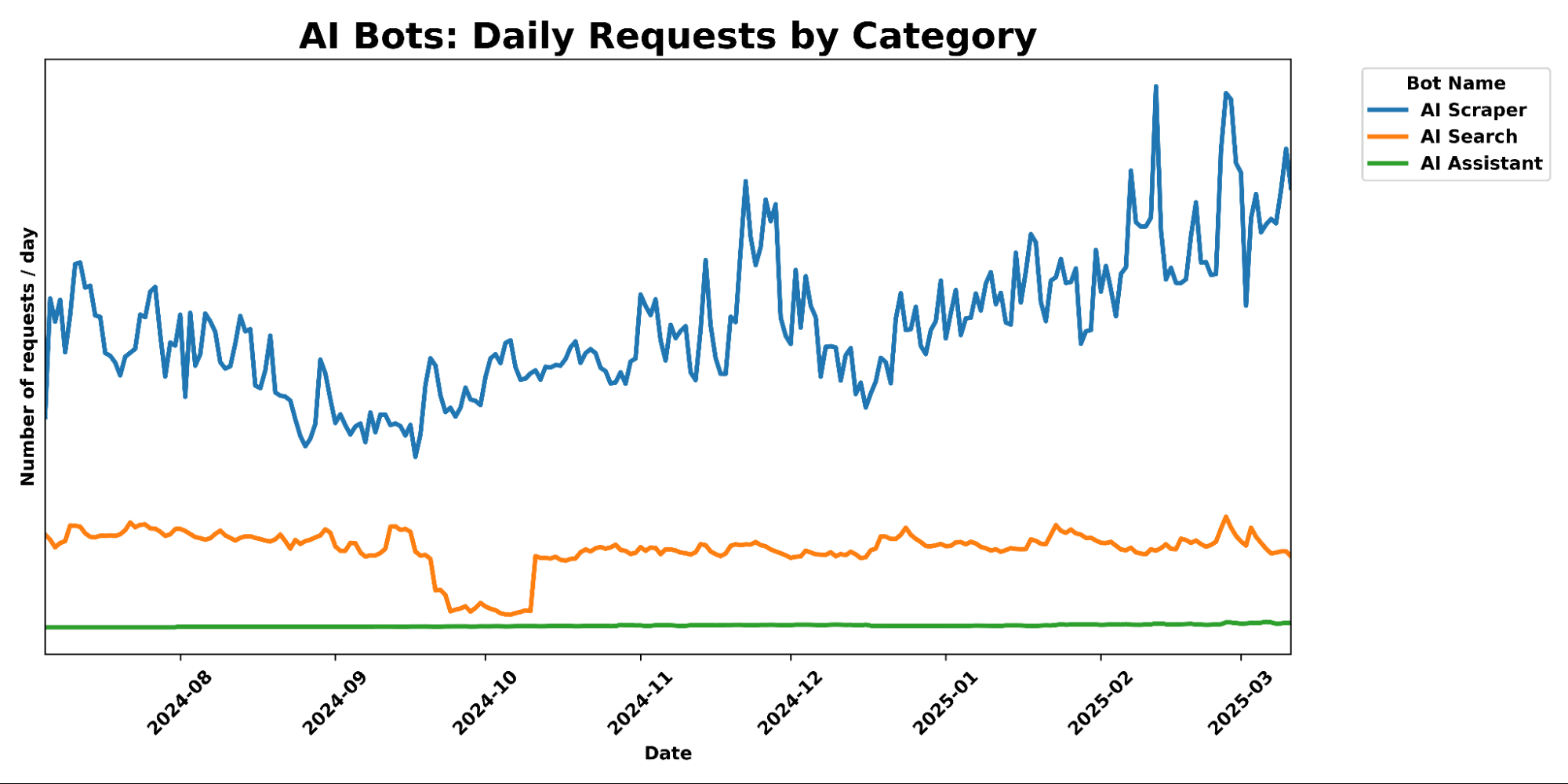
以下のグラフは、各種クローラーの1日あたりのリクエスト数をまとめたグラフ。横軸が時間の経過を表しています。クローラーの種類は青線がAIスクレイパー、オレンジ色がAI検索、緑色がAIアシスタントを表しており、時間の経過と共にAIスクレイパーによるリクエストのみ急増していることがよくわかります。
AI Labyrinthのアプローチが特に効果的なのは、継続的に進化するボット検出システムでの役割です。AI Labyrinthが作成したリンクを人間が表示したりクリックしたりすることはないため、リンクがクリックされればそれは即座にクローラーによるものであることがわかります。これについてCloudflareは、「強力な識別メカニズムが提供され、機械学習モデルに取り込まれる貴重なデータが生成されることにもつながる」と説明しました。どのクローラーがどのリンクをたどっているかを分析することで、検出されない可能性のある新しいボットパターンとシグネチャを識別できるようになり、不正なクローラーへの対処を継続的に改善することが可能となります。
なお、AI Labyrinthと同じようにAIが生成した迷路にクローラーを閉じ込める手法が開発されています。
AIトレーニング用のデータをかき集めるクローラーを無限生成される迷路に閉じ込める「Nepenthes」が開発される - GIGAZINE

・関連記事
OpenAIが将来のAIモデルの改善に向けたウェブクローラー「GPTBot」を発表、同時にAIによる無断での学習を防ぐためのブロック方法も公開 - GIGAZINE
Googleが生成AIのトレーニングに自分のウェブサイトが使われないようにするオプションを発表、もう遅いという指摘も - GIGAZINE
OpenAIとMicrosoftがAIをめぐる著作権侵害で作家から訴えられる - GIGAZINE
大手日刊紙のニューヨーク・タイムズがOpenAIとMicrosoftを著作権侵害で提訴 - GIGAZINE
OpenAI対ニューヨーク・タイムズ裁判でOpenAIが「ニューヨーク・タイムズは自社の記事を引き出すためにChatGPTをハッキングした」と主張 - GIGAZINE
・関連コンテンツ





in AI, ソフトウェア, ネットサービス, Posted by logu_ii
You can read the machine translated English article Cloudflare launches 'AI Labyrinth' to tr….