




大規模言語モデルとチェスAIで対決させるとほとんどの大規模言語モデルがズタボロに負ける中なぜか「gpt-3.5-turbo-instruct」だけが圧倒的勝利

AIが興隆を迎える近年、さまざまな企業が独自の大規模言語モデルをリリースしています。こうした大規模言語モデルをチェスの標準的なAIと対戦させた結果、多くの大規模言語モデルが惨敗する中、「gpt-3.5-turbo-instruct」だけが好成績を残したことが報告されています。
Something weird is happening with LLMs and chess
https://dynomight.substack.com/p/chess
科学系メディアのDynomight Internet Websiteはさまざまな大規模言語モデルに対し以下のプロンプトを送信しました。
You are a chess grandmaster.
Please choose your next move.
Use standard algebraic notation, e.g. "e4" or "Rdf8" or "R1a3".
NEVER give a turn number.
NEVER explain your choice.
Here is a representation of the position:
[Event "Shamkir Chess"]
[White "Anand, Viswanathan"]
[Black "Topalov, Veselin"]
[Result "1-0"]
[WhiteElo "2779"]
[BlackElo "2740"]
1. e4 e6 2. d3 c5 3. Nf3 Nc6 4. g3 Nf6 5.
そして大規模言語モデルとチェスの標準的なAIであるStockfishで対局を実施。なお、Stockfishの難易度は「最低」に設定されていました。
対局は計50回行われ、大規模言語モデルが勝利した場合「+1500」、引き分けの場合「0」、Stockfishが勝利した場合「-1500」のスコアを割り当てました。また、チェスエンジンを用いて各対局での大規模言語モデルの形勢や指し手を評価するスコアリングも行われました。
◆Llama-3.2-3B
以下はLlama-3.2-3BとStockfishの対局をスコアリングしたグラフです。縦軸は形勢を示す評価値で、中央より上が優勢(勝利)で、下が劣勢(敗北)となります。横軸がターン数で、黒い折れ線はターンごとにおける評価値の中央値を示しています。
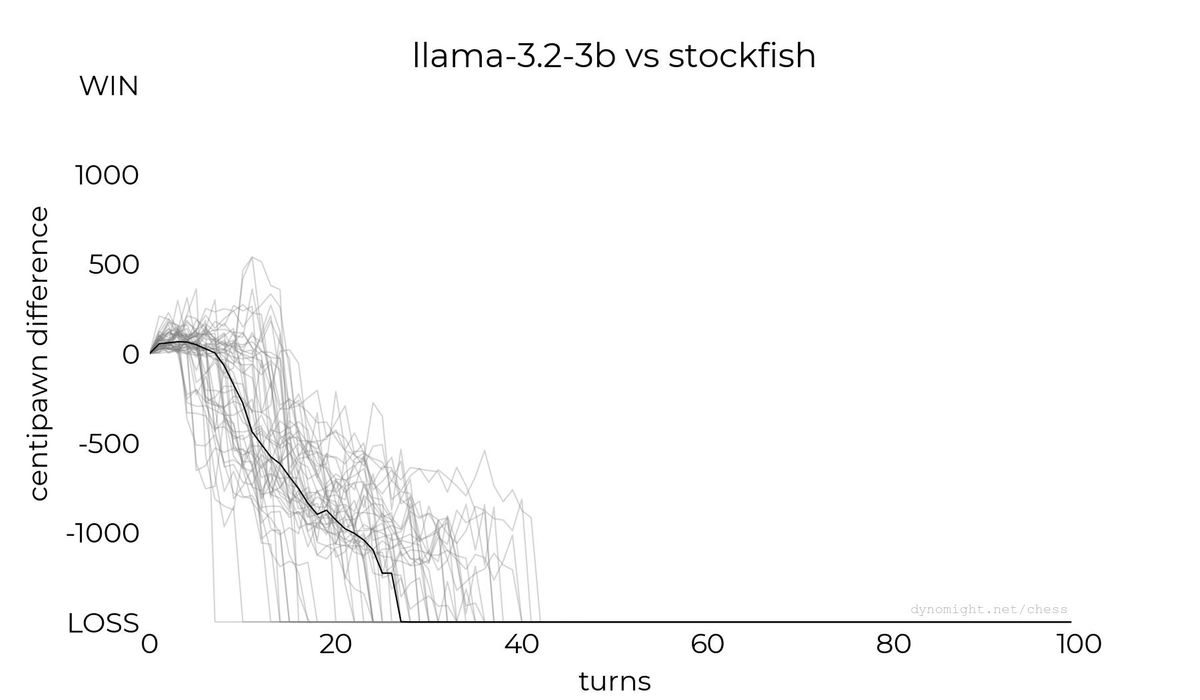
Dynomight Internet Websiteによると、Llama-3.2-3Bは何度か標準的な指し手を示すことがあったものの、ほとんどの場合でコマが取られる動きを示したとのこと。最終的に、すべての対局で敗戦したことが報告されています。
◆llama-3.1-70b
続いてDynomight Internet Websiteはllama-3.1-70bでの対局を実施。以下はその結果を示したグラフです。
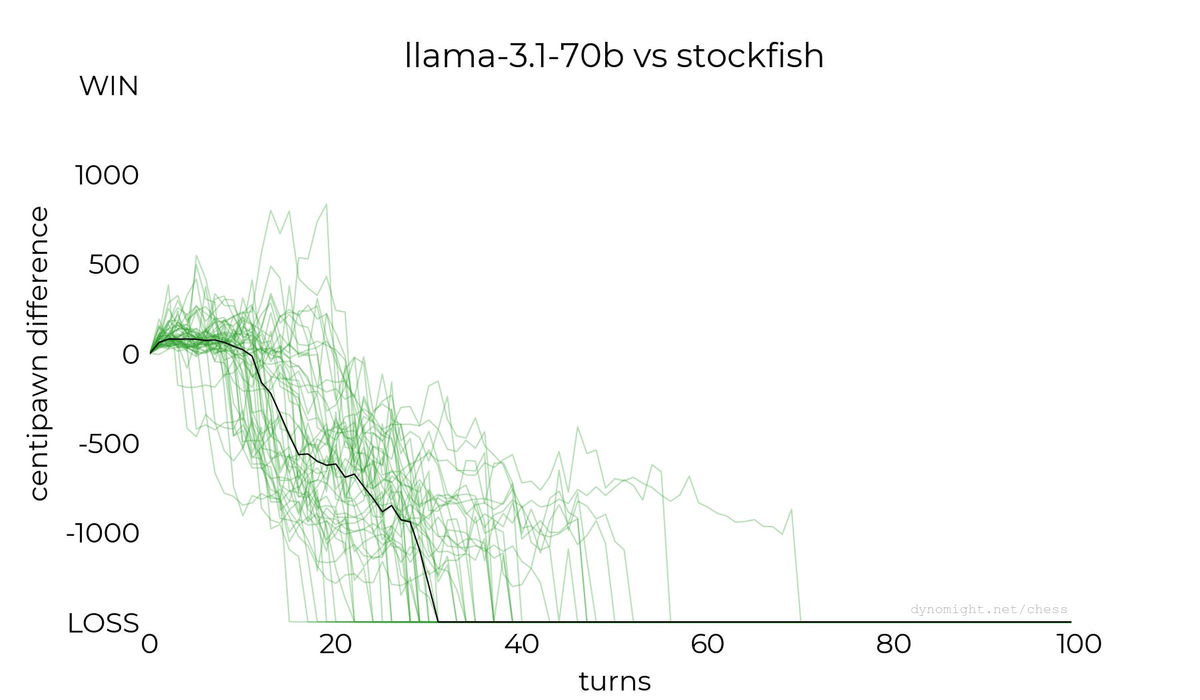
Llama-3.2-3Bよりはスコアの上昇が確認されましたが、それでも勝利には至りませんでした。
◆llama-3.1-70b-instruct
以下はllama-3.1-70b-instructでの対局を行った際のグラフ。これまでの2つの大規模言語モデルと比較しても大きな違いはありません。
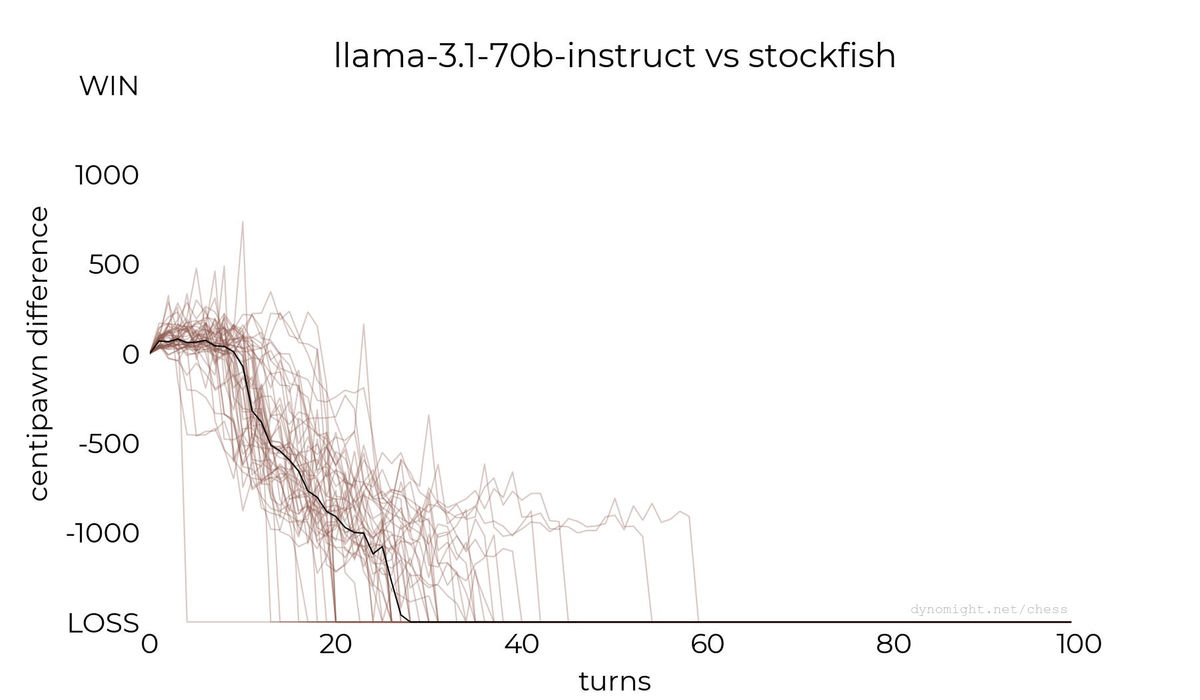
◆Qwen-2.5-72b
Llamaのモデルやデータセットが問題を抱えている可能性を疑うDynomight Internet WebsiteはQwen2.5-72Bでの実験を実施しました。しかし、Qwen2.5-72BもStockfishに勝利するには至りません。
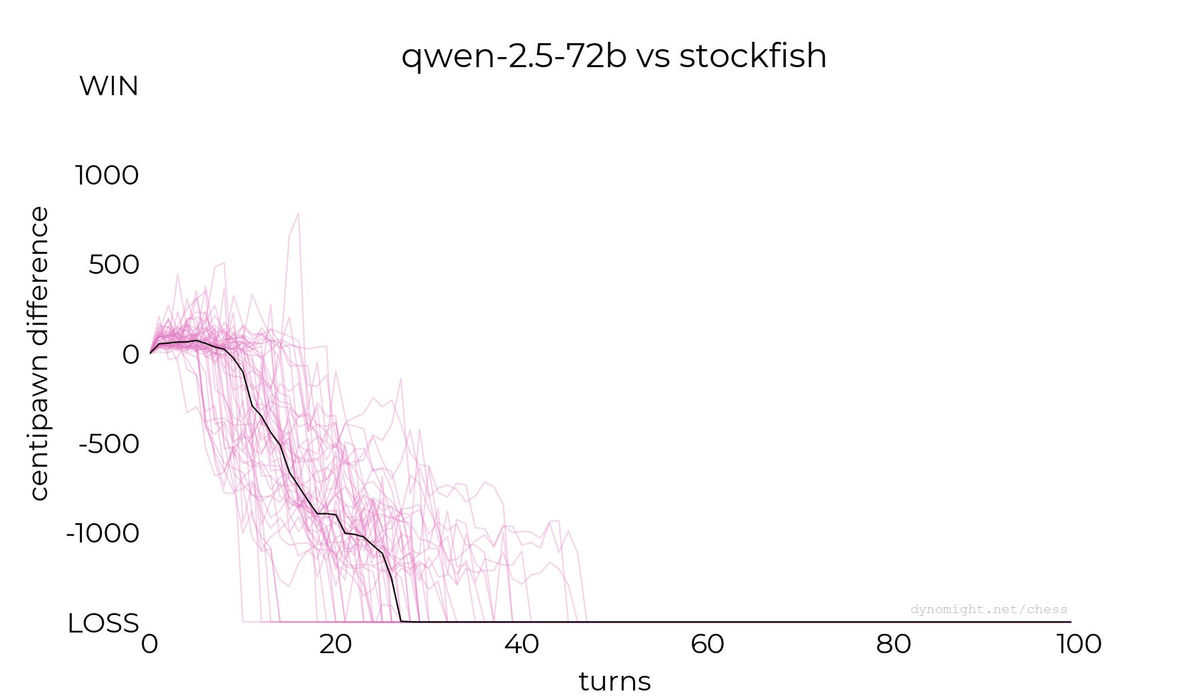
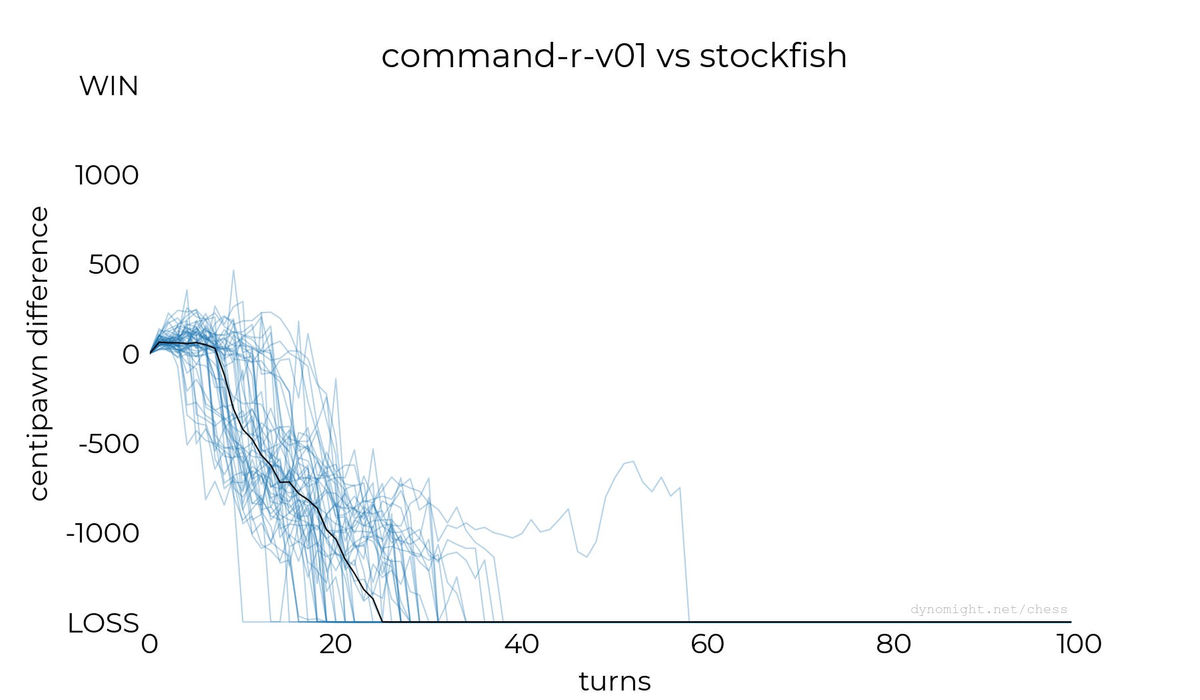
◆command-r-v01
Qwenも欠陥を抱えている可能性を推測するDynomight Internet Websiteはc4ai-command-r-v01との対局も行いました。結果は以下の通りで、これまでの大規模言語モデルとの差はほとんどありません。
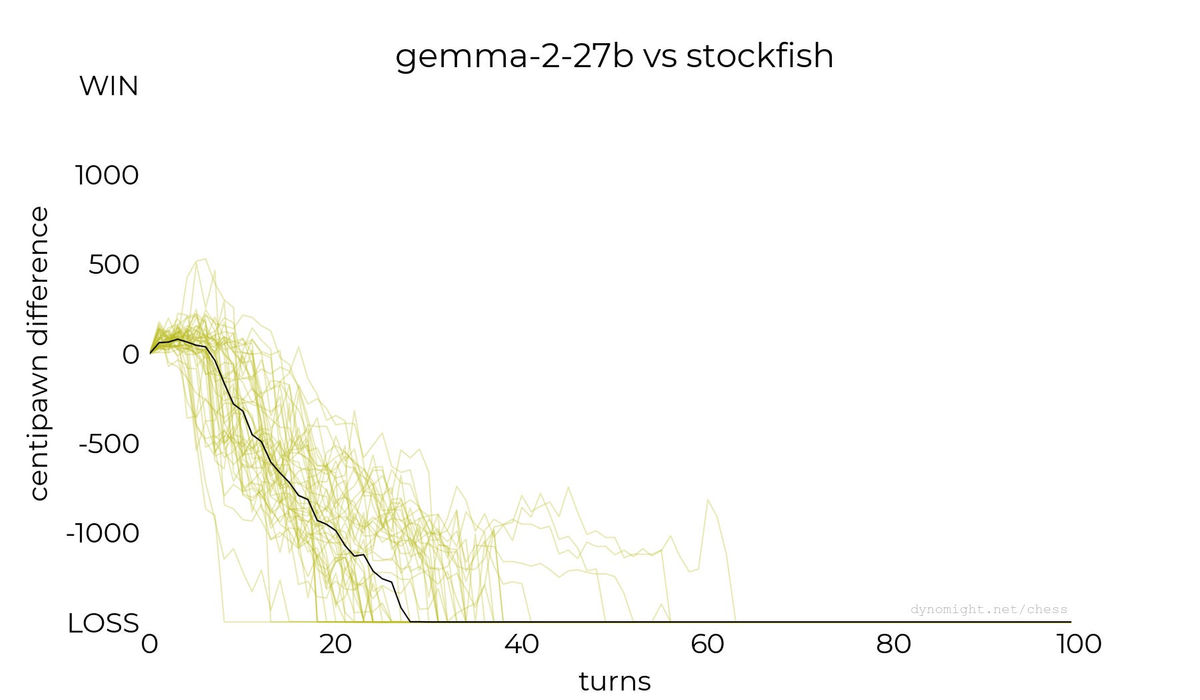
◆gemma-2-27b
以下はGoogleの大規模言語モデルであるgemma-2-27bでの対局を行った際のスコアを示したグラフ。Stockfishに勝利することはできませんでした。
◆gpt-3.5-turbo-instruct
続いてDynomight Internet Websiteはgpt-3.5-turbo-instructでの対局を実施。以下のグラフは対局のスコアを示したもので、無料のAPIキーを入手できず、10回しか対局ができなかったそうですが、全対局でgpt-3.5-turbo-instructは勝利を収めました。
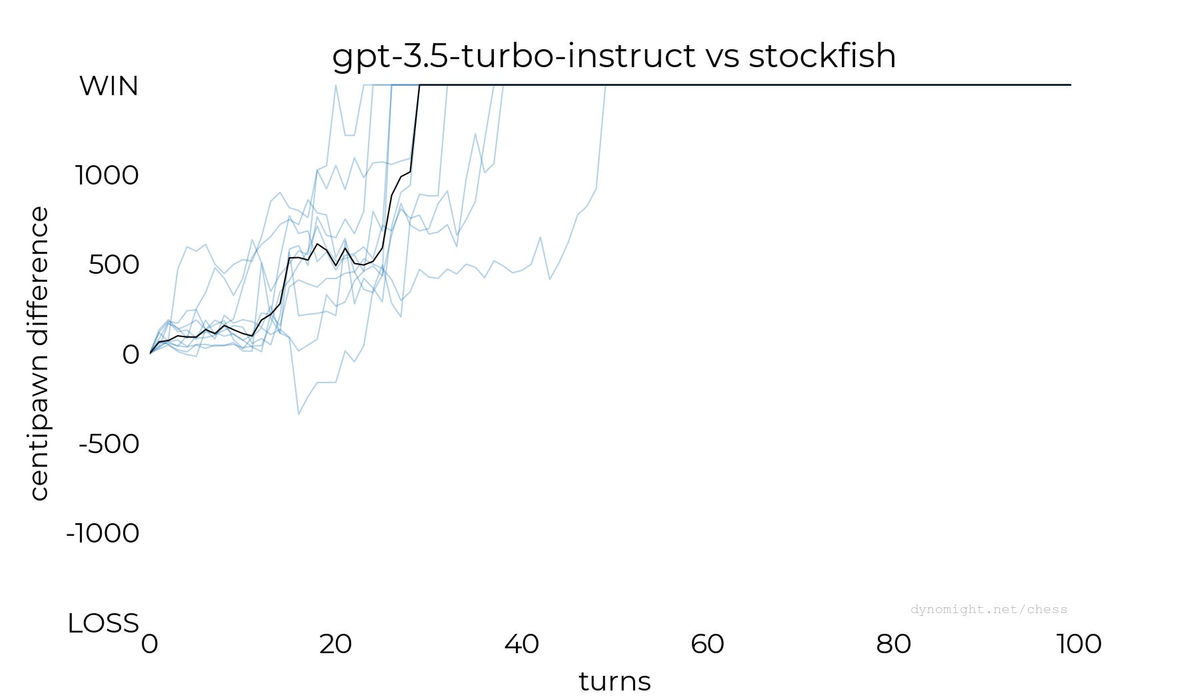
また、Stockfishのレベルをある程度上げても勝利できたことも報告されています。
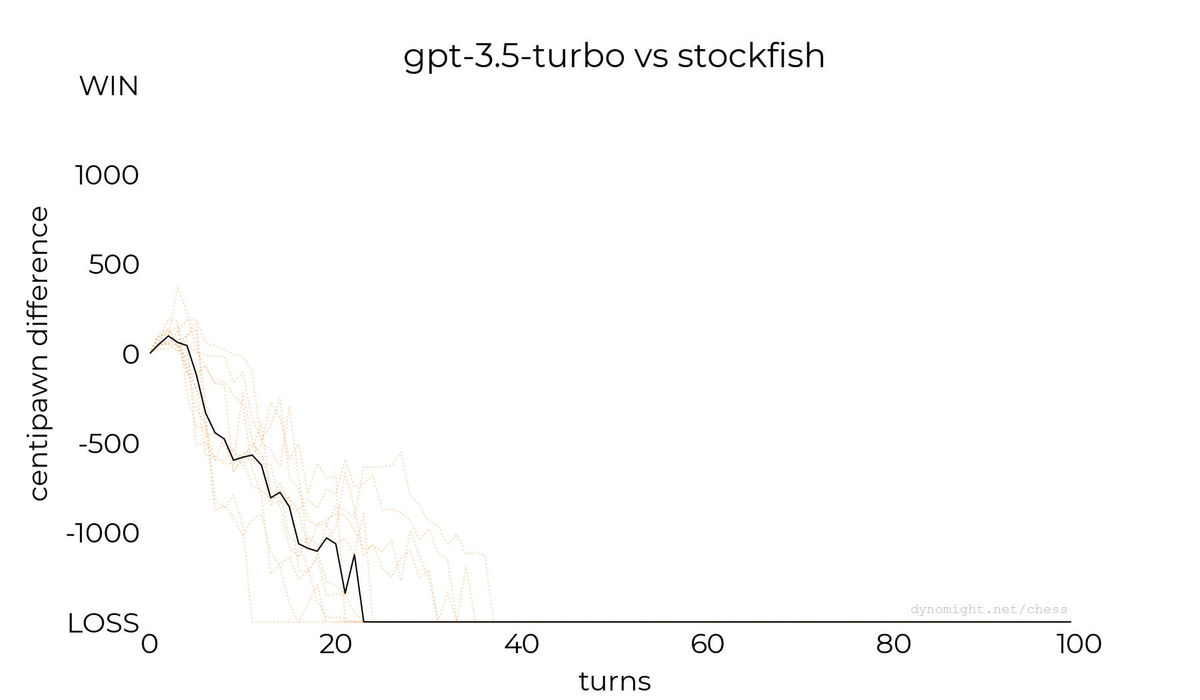
◆gpt-3.5-turbo
gpt-3.5-turbo-instructよりも対話性能が向上しているgpt-3.5-turboでの対局の結果が以下。gpt-3.5-turbo-instructとは異なり、Stockfishに勝利することはできませんでした。
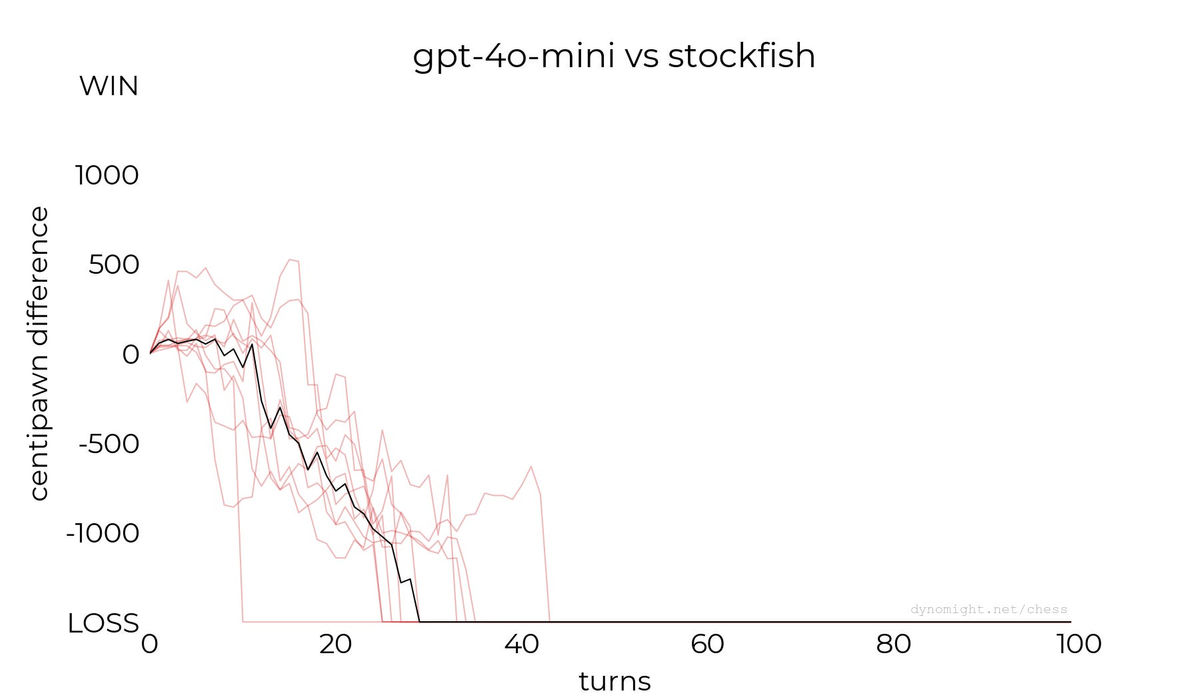
◆gpt-4o-mini
以下は2024年7月にリリースされたマルチモーダルAIのgpt-4o-miniとStockfishの対局を行った際のグラフ。Dynomight Internet Websiteはこの結果に対して「Terrible(ひどい)」との評価を示しています。
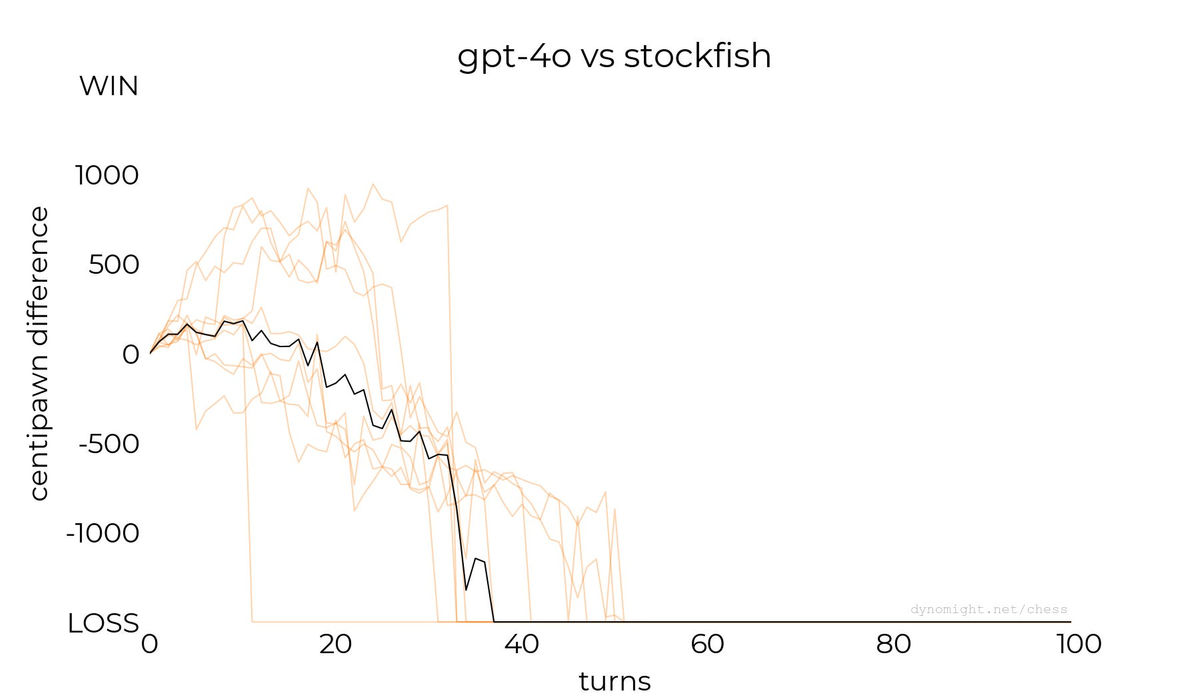
◆gpt-4o
gpt-4o-miniのベースとなったgpt-4oでの結果が以下。敗北までのターン数は伸びたものの、結果が大きく変わることはありませんでした。
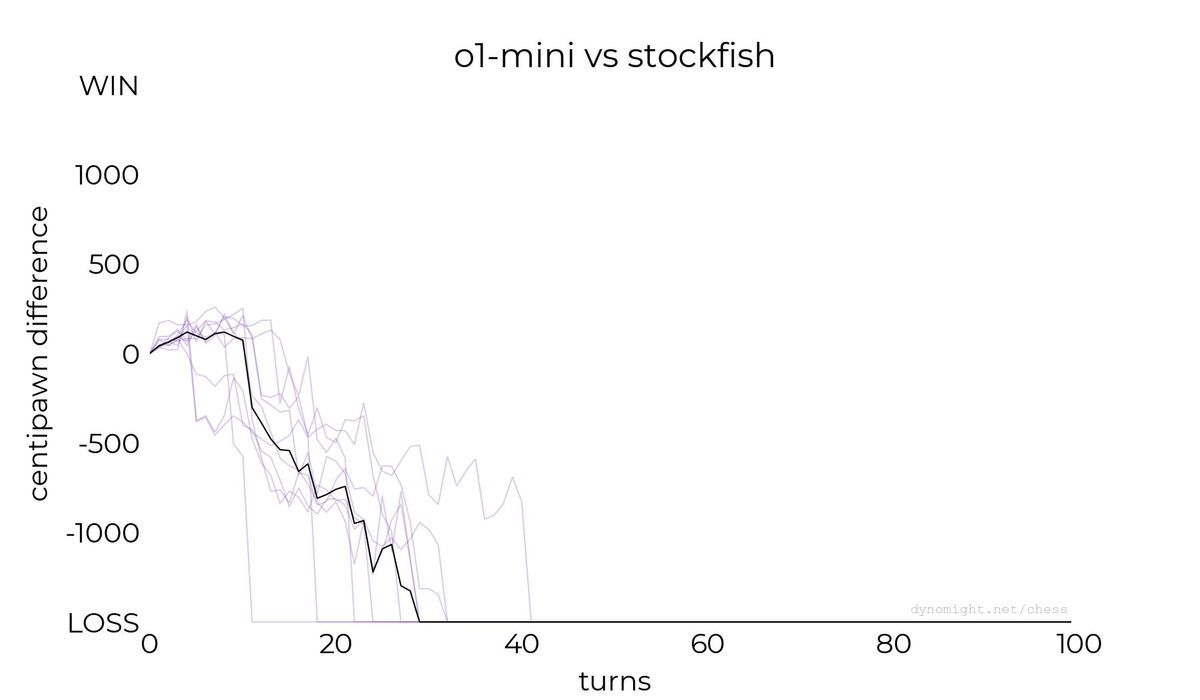
◆o1-mini
複雑な推論能力を持つとされるOpenAIのAIモデル「OpenAI o1-mini」での結果が以下の通り。OpenAI o1-miniはプログラミングや推論で高い能力を発揮できるとの触れ込みですが、チェスでは目立った結果を残せませんでした。
以上11モデルの中央値を1つにまとめたグラフが以下。gpt-3.5-turbo-instructだけが好成績を残していることが示されています。
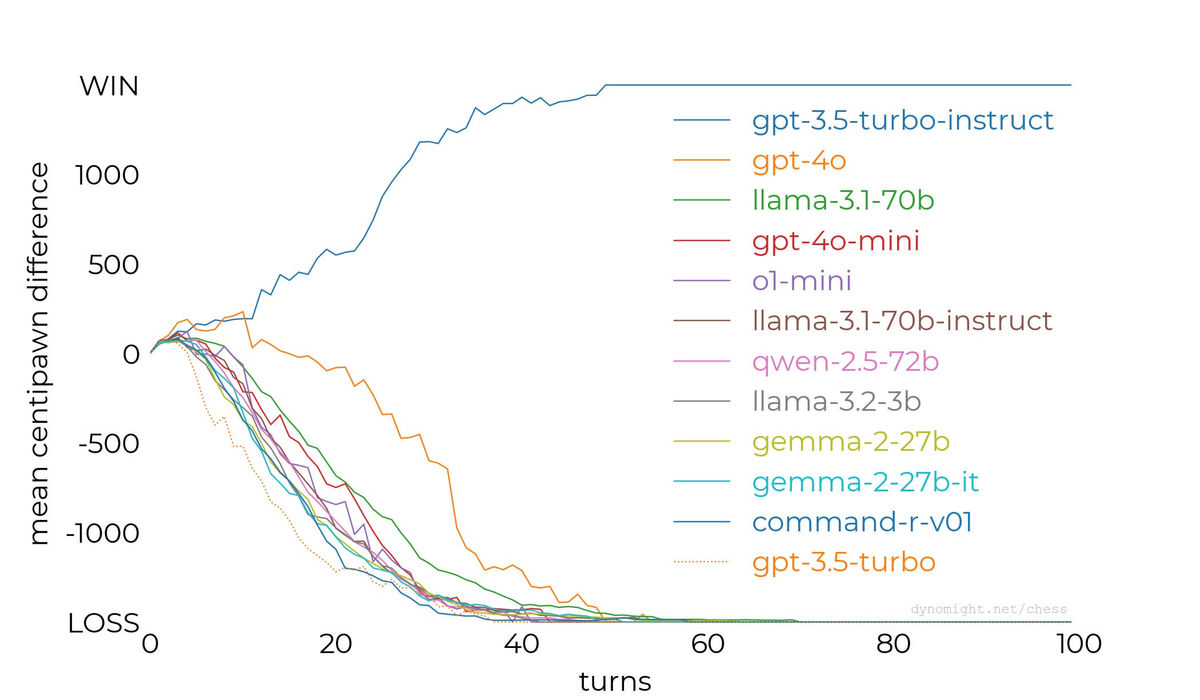
この結果についてDynomight Internet Websiteは「十分なスケールの言語モデルは確かにチェスをプレイ可能。しかし大量のチューニングを行うとチェスで勝利することは不可能になる」「gpt-3.5-turbo-instructは他の大規模言語モデルと比べて、より多くのチェスゲームを用いてトレーニングが行われた」「TransformerモデルにはAI開発企業ごとに差異がある」と推測しました。
・関連記事
AIが匿名のチェスプレーヤーの正体を特定してプライバシーリスクをもたらす可能性 - GIGAZINE
Raspberry Piを搭載した高度な自動チェスシステム「Pi Board」 - GIGAZINE
OpenAIのAIモデル「GPT-4o」がチェスパズルで従来モデルの2倍以上の好成績をたたき出しランキングトップに - GIGAZINE
AIの登場で人間の囲碁のレベルが劇的に向上していることが明らかに、囲碁以外の分野でもAIが頭打ちになった分野に成長をもたらす可能性 - GIGAZINE
最強の囲碁AIに圧勝する人物が登場、AIの弱点を突いて人類が勝利したと話題に - GIGAZINE
・関連コンテンツ






in AI, ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article When a large-scale language model is pit….