




AWSのブロックストレージがどのように進化してきたのかを中の人が語る
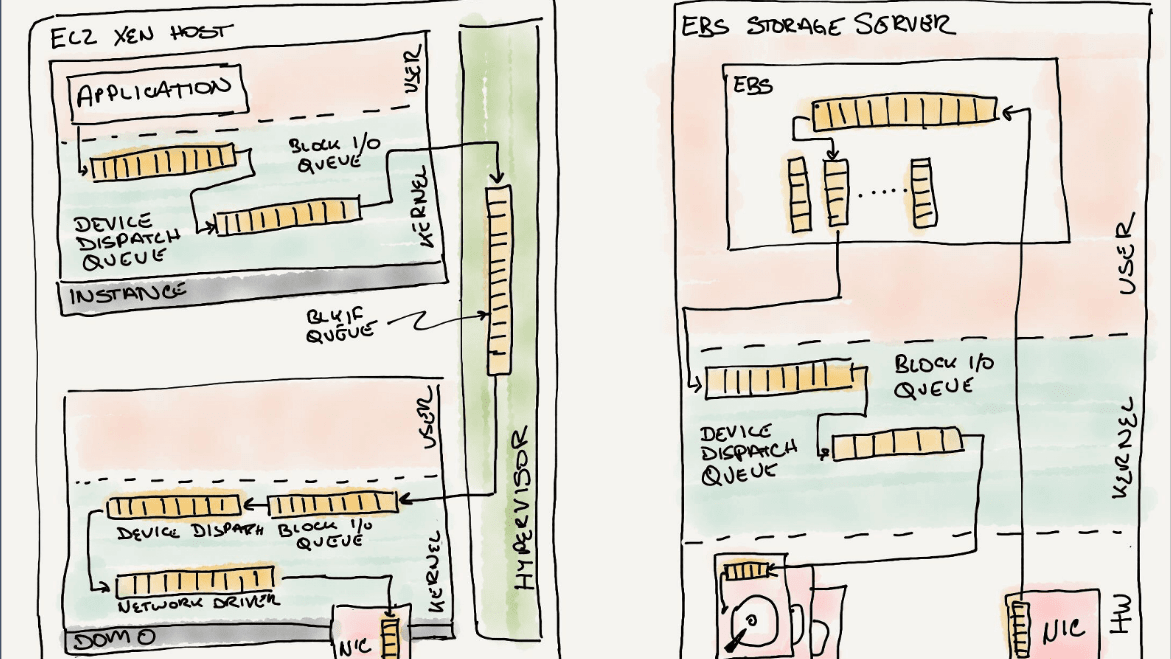
10年以上にわたりAWSのElastic Block Store(EBS)の開発に関わってきたマーク・オルソン氏が、EBSが共有ドライブに依存する単純なブロックストレージサービスから、毎日140兆回以上の操作を実行する大規模なネットワークストレージシステムへ発展するまでを振り返るブログ記事を投稿しました。
Continuous reinvention: A brief history of block storage at AWS | All Things Distributed
https://www.allthingsdistributed.com/2024/08/continuous-reinvention-a-brief-history-of-block-storage-at-aws.html

EC2がベータ版で使用可能になってから2年後の2008年にEBSはサービスを開始しました。当初はEC2インスタンスにネットワーク接続のブロックストレージを提供するというシンプルなアイデアでスタートしており、1人か2人のストレージ専門家と数人の分散システム担当者しかいませんでした。
オルソン氏はAmazonに転職する前はネットワークとセキュリティの分野で働いており、2011年にAmazonに転職すると同時にストレージに取り組み始めたとのこと。オルソン氏はインスタンスのIOリクエストをEBSストレージ操作に変換するEBSクライアントの開発を始め、EBSの進化とともにEBSのほぼ全てのコンポーネントに取り組んできました。
コンピューターがストレージとやりとりする基本は昔から変化していません。ストレージデバイスとCPUがともにバスに接続されており、CPUがリクエストをデバイスに送信するとデバイスはメモリのデータをHDDやSSDなど耐久性のあるメディアに保存するか、メディアからデータを読み出してメモリに配置します。
複数のリクエストが同時に届くとストレージはリクエストを待ち行列に入れ、順番に処理を行います。ネットワークストレージシステムではさまざまなレイヤーにおいて待ち行列が用意されており、例えば「OSカーネルとストレージアダプタ間」「ホストストレージアダプタとストレージファブリック間」「ターゲットストレージアダプタとストレージメディア間」などがあるとのこと。
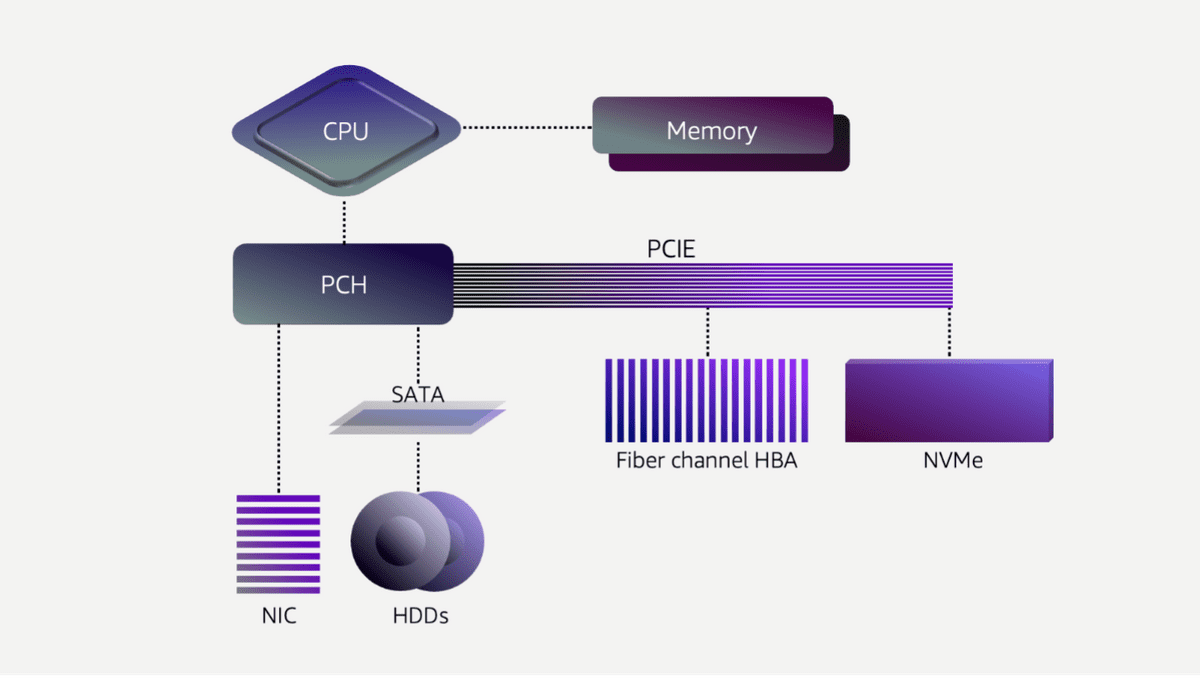
2008年にEBSがスタートした時、ストレージのほとんどはHDDで、サービス全体のレイテンシはほとんどHDDのレイテンシによって決まっていました。メーカー側も高速化のためにさまざまな工夫をこらしていますが、HDDは回転するプラッタの適切な位置にアームを動かす必要があるという物理的制約により必ず平均6~8ミリ秒のレイテンシが発生するほか、データが断片的に分散して保存されていると読み出しに時間がかかり、時折数百ミリ秒のレイテンシが発生する場合もあったそう。
そのため、初期のEBSのレイテンシは数十ミリ秒単位で測定されており、数十マイクロ秒単位のネットワークレイテンシが追加されてもほとんど影響がなかったとのこと。EBS開発チームは別のワークロードに影響を与えるワークロードのことを「noisy neighbor(うるさい隣人)」と名付け、この隣人の影響を軽減することに取り組みました。ドライブのスケジュールアルゴリズムを変更したり、スピンドル間でユーザーのワークロードのバランスを取ったりするなどの改善を行ったものの、ユーザーのワークロードは予測不可能であり、必要な一貫性を実現できませんでした。
SSDは物理的なアームなどの制約がなく、HDDに比べると非常に素早くランダムアクセスを行うことができるため、EBS開発チームはHDDをSSDに置き換えるだけでほぼ全ての問題が解決すると考えていたとのこと。2012年にSSDの利用が開始され、メディア部分のレイテンシは大きく改善しましたが、システム全体としてみるとEBS開発チームが期待していたほどは改善されておらず、ネットワークやソフトウェア部分に注目する必要がでてきました。
システムのパフォーマンス向上のためにさまざまな指標を計測することでEBS開発チームは「どの部分を改善するべきか」を調査。短期的な改善のための取り組みと長期的なアーキテクチャ変更の取り組みを同時に進めました。また、開発チームを分割し、担当する領域を分割することで継続的に同じ領域を改善できるようにしたとのこと。
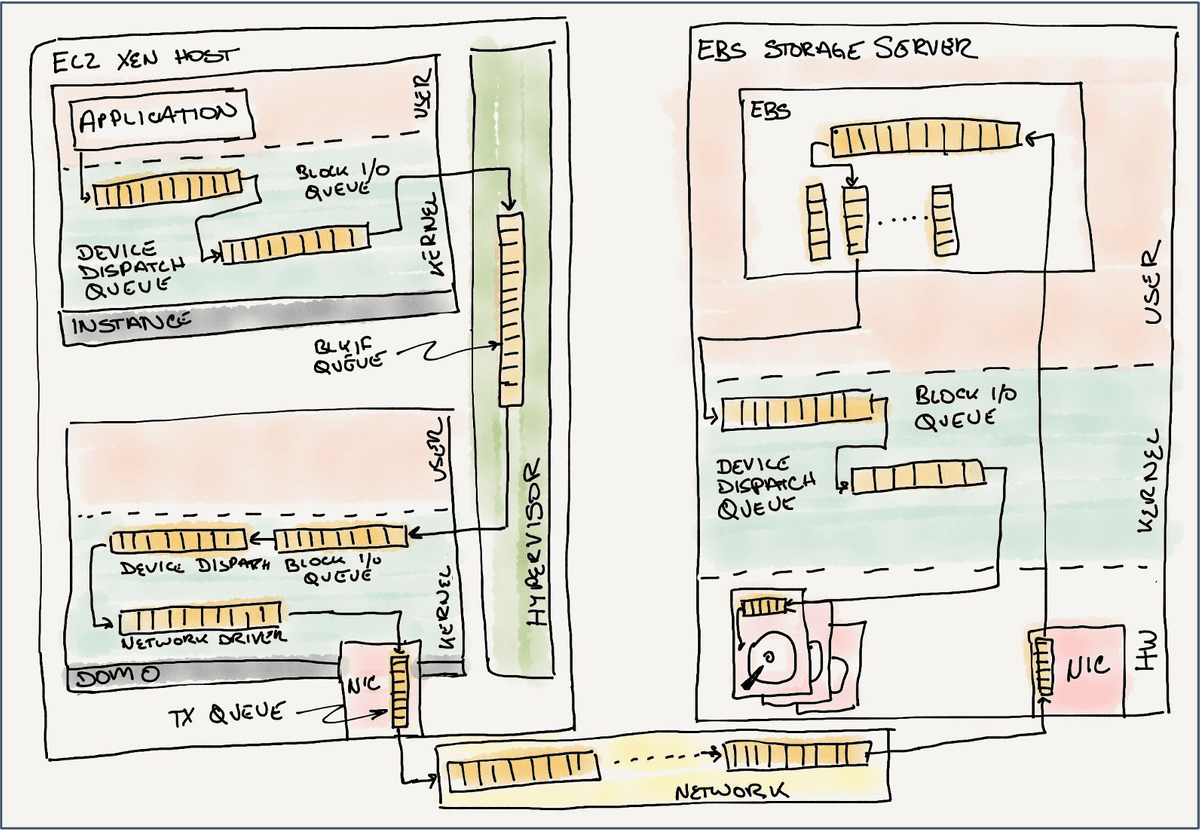
EBS開発チームは仮想化を活用したり、Nitroという専用ハードウェアを開発してパケット処理などを担当させることで処理速度を改善。同時にTCPの代わりとなるプロトコル「Scalable Relatable Diagram(SRD)」の開発などでネットワークのオーバーヘッドも削減していきました。オルソン氏は「常に仮定を疑い、測定・分析を行う事で最も重要な点に注目することが大切だ」と述べています。
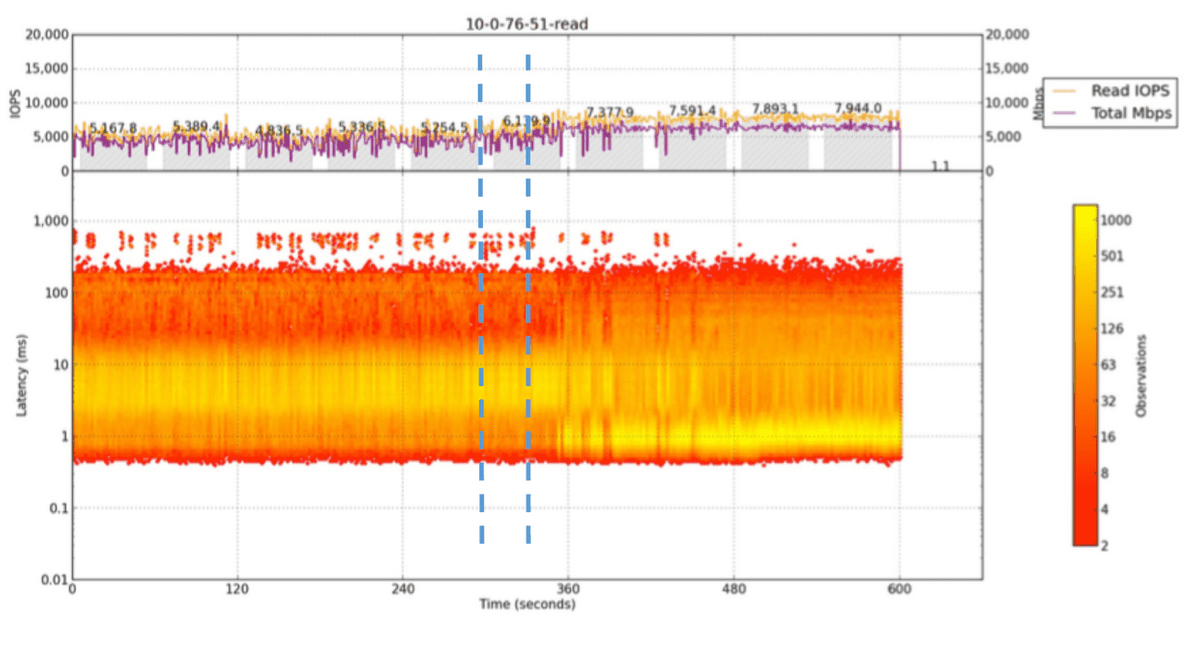
こうした開発チームの努力の結果、サービス開始当初は10ミリ秒以上あったEBSの平均レイテンシは2024年時点で1ミリ秒未満に改善されました。EBSはEC2インスタンスのシステムディスクという用途上、耐久性だけでなくパフォーマンスも重視する必要があるというストレージシステムとしてはやや特殊な制約があり、毎日140兆回以上の操作を実行する大規模なネットワークストレージシステムへ発展させるには最上部のゲストOSから最下部のカスタムSSD設計まで多くのレイヤーにまたがる大規模な分散システムの理解が必要だったとのこと。
オルソン氏は「お客様は常にさらなる向上を求めており、その挑戦こそが、私たちが革新と反復を続ける原動力だ」とブログを締めくくっています。
・関連記事
AWSの可用性を高め、成長を支えた「ゾーン」という考え方 - GIGAZINE
Amazonの最高技術責任者(CTO)が考える「2024年以降の技術動向予測」はどんな感じなのか? - GIGAZINE
AWSを10年運用してわかったことをAmazonの最高技術責任者が語る - GIGAZINE
Amazonのサクラレビューが多いカテゴリ上位5選&信頼できるカテゴリ上位5選 - GIGAZINE
Amazonの検証済みレビューでさえサクラの可能性がある - GIGAZINE
・関連コンテンツ






in ハードウェア, ソフトウェア, ネットサービス, Posted by log1d_ts
You can read the machine translated English article An insider explains how AWS block storag….