




AIが出力したデータで学習するとAIが崩壊する「AIの自食障害」とは?

AIのトレーニングには膨大なデータが必要となりますが、このデータにAIが生成したデータを使うと将来的に深刻な悪影響が生じるという研究結果を、ライス大学のデジタル信号処理グループが発表しました。
Breaking MAD: Generative AI could break the internet | Rice News | News and Media Relations | Rice University
https://news.rice.edu/news/2024/breaking-mad-generative-ai-could-break-internet
Cannibal AIs Could Risk Digital 'Mad Cow Disease' Without Fresh Data : ScienceAlert
https://www.sciencealert.com/cannibal-ais-could-risk-digital-mad-cow-disease-without-fresh-data
GPT-4やStable Diffusionなどの生成AIのトレーニングには膨大な量のデータが必要とされており、開発者たちはすでにデータの供給限界に直面しています。
AIを開発するために必要なデータが急速に枯渇、たった1年で高品質データの4分の1が使用不可に - GIGAZINE

この状況下で、AIが生成したデータの使用が選択肢として浮上していますが、ライス大学のリチャード・バラニュク教授が率いる研究チームはこれが危険な結果をもたらす可能性があると警告しています。
研究チームは、生成AIモデルの訓練にAIが生成したデータを使用することの長期的な影響に焦点を当てた研究を行いました。その結果、AIが自身の生成したデータから学習する「自己消費トレーニング」を繰り返すと、出力結果の品質や多様性が徐々に低下していくことが判明。研究チームはこの現象を「Model Autophagy Disorder(MAD:モデル自食障害)」と名付けています。
研究チームは「前の世代の出力結果のみでのトレーニング」「前の世代の出力結果と固定された実データを組み合わせたデータセットでトレーニング」「前の世代の出力結果と新しい実データを組み合わせたデータセットでトレーニング」という3つのパターンを用意して、MADを検証しました。
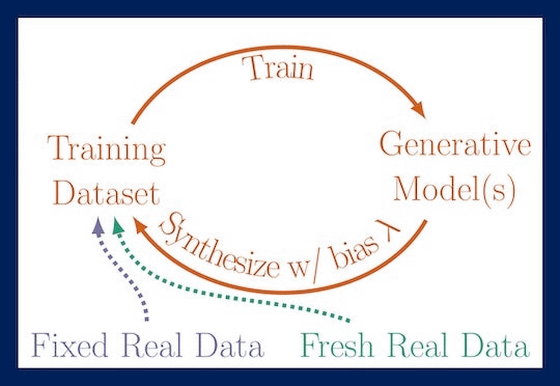
すると、新しい実データが得られない2パターンでモデルの出力が次第にゆがんでいき、出力結果から品質や多様性が失われていくことが明らかになりました。例えば、以下の画像のように人間の顔を生成した場合、世代(t)を重ねていくと顔に格子状の傷のようなノイズが乗りました。

次に、研究チームは、前の世代のAIの出力結果から自己消費トレーニング用の高品質なデータを選ぶ「チェリーピッキング」を再現する実験を行いました。
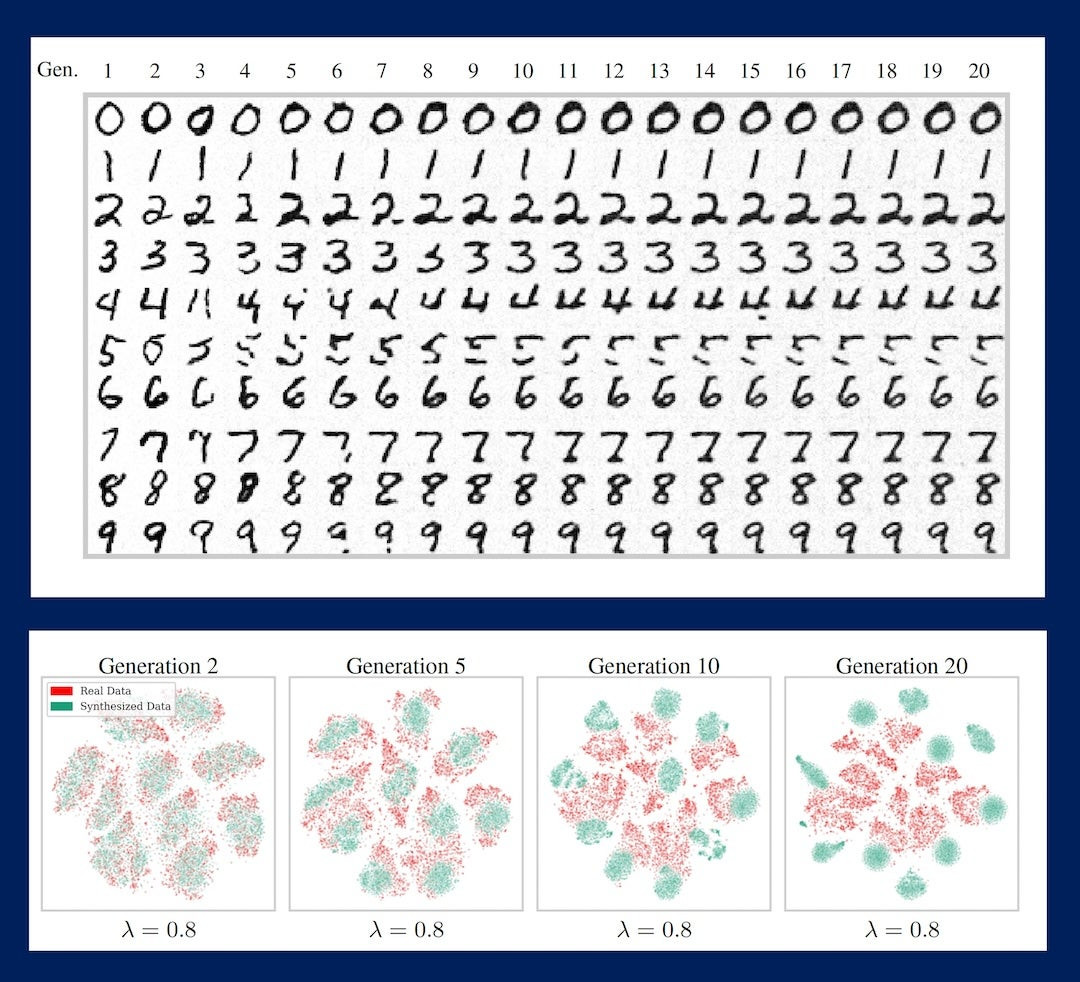
まずチェリーピッキングを行わず、固定した実データと前の世代が生成したデータでトレーニングを重ねていったAIの各世代に0から9までの数字を出力させた結果が以下。第5世代から文字が崩れて原型をとどめなくなり、第20世代になるとただの染みのような結果が出力されており、品質が急激に劣化しているのがわかります。なお、下の段に並ぶ図は、実データ(赤)とAIが生成したデータ(緑)の分布が世代を経てどのように変化していくかを視覚的に示したものです。

一方で、チェリーピッキングを行って高品質な結果を優先的に含むデータセットでトレーニングを重ねたAIに出力させた結果が以下。長い世代にわたって高品質なデータが保持されており、第20世代に至ってもほとんどがちゃんと読める数字となっています。ただし、すべての世代で出力結果がほぼ同じ形となっており、多様性が大きく失われていることがわかります。
バラニュク教授は「MADが何世代にもわたって制御されないまま放置された場合、インターネット全体のデータ品質と多様性が損なわれる可能性があります。AIの自食障害によって予期されていない結果が近い将来に意図せず起こることは避けられないでしょう」と警告しました。
・関連記事
NVIDIAがAIを訓練するために1日で人間の一生分の動画を集めているとの指摘 - GIGAZINE
AIトレーニングサービス経由で顧客のクラウド環境にアクセスできる脆弱性をセキュリティ企業が報告 - GIGAZINE
OpenAIが「正確かつ分かりやすい文章を出力するAI」の開発手法を公開 - GIGAZINE
「AIのトレーニングにかかるコストはわずか3年で1000億ドルに上昇するかもしれない」とAnthropicのCEOが予想 - GIGAZINE
「オープンソース」を称するAIモデルは実際どのくらいオープンなのか? - GIGAZINE
・関連コンテンツ








in AI, ソフトウェア, サイエンス, Posted by log1i_yk
You can read the machine translated English article What is 'AI's self-eating disorder' ….