




ChatGPTのミスを見つけるためのGPT-4ベースのモデル「CriticGPT」が開発される

OpenAIが、ChatGPTの誤りを検出するAIモデル「CriticGPT」を開発したことを発表しました。CriticGPTはChatGPTと同じくGPT-4をベースに開発されているそうです。
Finding GPT-4’s mistakes with GPT-4 | OpenAI
https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4/
ChatGPTなどのチャットAIを使うと、少ない操作でコードを生成したり長文を作成したりできます。しかし、チャットAIが生成するコードや文章には誤りが含まれることも多く、「ChatGPTで生成したコードをそのまま使った結果、バグが存在しており実害を被った」という報告も存在しています。
ChatGPTが生成したコードのバグを見落としたせいで150万円以上の損失を被った失敗談 - GIGAZINE

新たに、OpenAIはChatGPTの誤りを検出して訂正するAIモデル「CriticGPT」を開発しました。CriticGPTはGPT-4をベースに開発されたモデルで、「手動でミスを含めたコード」と「コードのミスを訂正する文章」を学習することでコードのエラー検出能力と訂正能力が強化されています。
CriticGPTの使用例が以下。ChatGPTが生成したコードに対して、CriticGPTが「この用途でのstartswithメソッドの利用は適切ではない」と指摘しつつ代替案を提示しています。

以下のグラフは「人間(緑)」「CriticGPT(オレンジ)」「人間とCriticGPT(ピンク)」で「コードに対する批評の完全性」を比べてものです。人間の批評よりもCriticGPTの批評の方が完全性が高いことが分かります。
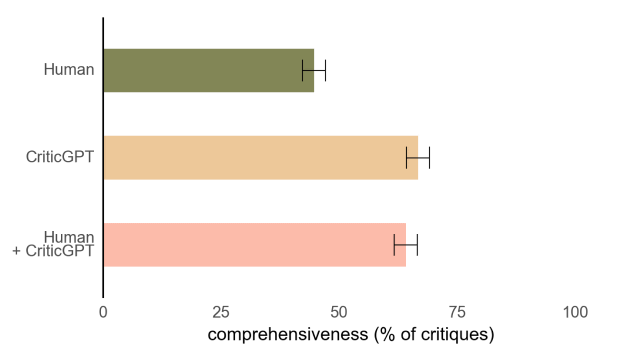
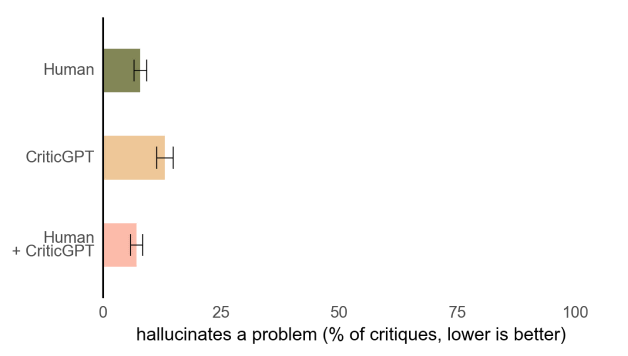
「コードに対する批評に事実と異なる情報(ハルシネーション)が含まれる割合」を比べたグラフが以下。ハルシネーションが含まれる割合は、人間がCriticGPTを使った際に最も低くなることが分かります。
OpenAIは「複雑化するAIシステムを調整するには、より優れたツールが必要です」と述べ、今後もCriticGPTのようなAIの出力を調整するツールを開発する意向を示しています。
・関連記事
OpenAIがGPT-4の思考を1600万個の解釈可能なパターンに分解できたと発表 - GIGAZINE
OpenAIがmacOS向け画面共有サービスのMultiを買収 - GIGAZINE
OpenAIがリアルタイム分析データベース提供のRocksetを買収 - GIGAZINE
AIを作るAIを作る - GIGAZINE
・関連コンテンツ








in AI, ソフトウェア, Posted by log1o_hf
You can read the machine translated English article A GPT-4-based model called 'CriticGPT' w….