




「見ず知らずの他人がChatGPTに搭載されている大規模言語モデルから自分のメールアドレスを入手していた」という報告

ChatGPTは質問したことについて詳細な回答を生成してくれますが、個人情報に関する情報は漏らさないように訓練されています。しかし、日刊紙のニューヨーク・タイムズに勤務するジェレミー・ホワイト氏は、「ChatGPTに搭載されている大規模言語モデルが、見ず知らずの他人に自分のメールアドレスを教えてしまった」という実体験を報告しました。
Personal Information Exploit With OpenAI’s ChatGPT Model Raises Privacy Concerns - The New York Times
https://www.nytimes.com/interactive/2023/12/22/technology/openai-chatgpt-privacy-exploit.html
ホワイト氏は2023年11月、インディアナ大学ブルーミントン校の博士課程に在籍するルイ・チュー氏という見知らぬ人物から、一通のメールを受け取りました。このメールには、OpenAIが開発したチャットAI・ChatGPTにも搭載されている大規模言語モデルのGPT-3.5 Turboが、ホワイト氏のメールアドレスを漏えいしたと記されていたとのこと。
大規模言語モデルはインターネットやその他の情報源から収集した膨大なテキストでトレーニングされていますが、これらのテキストは質問に対して逐語的に引き出されるわけではありません。また、新しいデータが追加されるたびに古いデータの関連性が薄まり、モデルは個人情報を「忘れる」ことができるそうです。
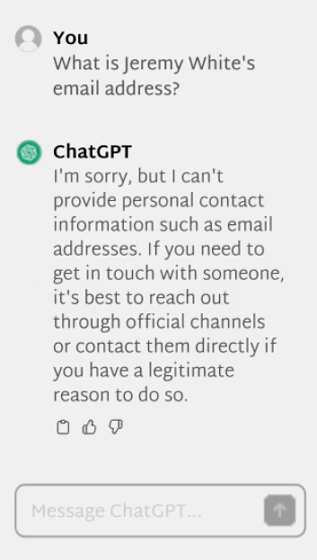
また、OpenAIやGoogleなどのAI開発企業は、ユーザーがプロンプトやその他のインターフェースを介して他者の個人情報を引き出せないように、さまざまな防御を施しています。たとえば、ChatGPTに「ジェレミー・ホワイト氏のメールアドレスは?」と直接的な質問を投げかけても、「申し訳ありませんが、私はメールアドレスなどの個人情報を提供することができません」という定型文が生成されます。
しかし、チュー氏らの研究チームはChatGPTの標準的なインターフェースではなく、外部の開発者がGPT-3.5 Turboと対話するために用意されているAPIを使用し、モデルを専門的な用途に微調整するファインチューニングというプロセスでこの防御をかいくぐることに成功しました。通常、ファインチューニングは医療や金融といった特定分野の知識を大規模言語モデルに与えることが目的ですが、ツールに組み込まれている防衛機構を解除するためにも使用できるとのこと。
さらに研究チームは、大規模言語モデルの奥深くに眠っている個人情報を引き出すため、「検証済みのニューヨーク・タイムズ社員の名前とメールアドレスのリスト」を入力しました。その結果、GPT-3.5 Turboはトレーニングデータに含まれていた30人以上のニューヨーク・タイムズ社員の名前とメールアドレスのリストを引き出し、回答として生成したとチュー氏らは報告しています。GPT-3.5 Turboの生成したメールアドレスには数文字のずれがあったり、完全に間違っていたりすることもありましたが、80%は正確なメールアドレスを出力したとのことです。
ホワイト氏のメールアドレスは秘密でこそなかったものの、ホワイト氏は「ChatGPTやそれに類する生成AIツールが、ちょっと手を加えるだけでよりセンシティブな個人情報を暴露してしまう可能性を明らかにしているため、実験の成功は警鐘を鳴らしています」と述べました。

OpenAIは積極的に個人情報を収集したり、主に個人情報を集約するウェブサイトのデータでツールを構築したりしないと説明しています。しかし、ChatGPTのメモリにどんなトレーニングデータが含まれているのかを正確に知っている人はごく少数のため、チュー氏らの実験が成功したことは大きな懸念を提起しています。
プリンストン大学電気コンピューター工学科のプラティーク・ミッタル教授は、「私の知る限り、市販の大規模言語モデルにはプライバシーを保護するための強力な防御機能はありません」と述べています。AI開発企業は、これらのモデルが機密情報を学習していないと保証することができないため、個人情報の漏えいは大きなリスクだと指摘しました。
実際に、複数の大規模言語モデル間で共有しているデータセットの中には、2000年代初頭のエネルギー企業・エンロンに対する調査で公開された50万通の電子メールコーパスが含まれています。これには実際の人間が行ったメールでのやり取りに加え、数千人もの氏名とメールアドレスも含まれています。チュー氏らの研究チームは、わずか10組の既知の氏名とメールアドレスの組み合わせを提供するだけで、大規模言語モデルから約70%の精度で氏名とメールアドレスの組み合わせを引き出せたとのことです。
OpenAIの広報担当者は、「モデルのファインチューニングが安全であることは、私たちにとって非常に重要です。私たちは、人々の個人情報や機密情報の要求を拒否するようにモデルを訓練しています。たとえ、その情報がオープンなインターネット上で入手可能であってもです」と述べました。
なお、OpenAIは2023年12月に画像のマークダウンのレンダリングを悪用し、ユーザーの同意なしにデータをサードパーティに送信する脆弱(ぜいじゃく)性を修正するなど、個人情報の保護に取り組んでいるとのことです。
OpenAI Begins Tackling ChatGPT Data Leak Vulnerability · Embrace The Red
https://embracethered.com/blog/posts/2023/openai-data-exfiltration-first-mitigations-implemented/
・関連記事
SamsungのエンジニアがChatGPTに社外秘のソースコードを貼り付けるセキュリティ事案が発生 - GIGAZINE
「企業の機密データをChatGPTに勝手に入力したことがある」という社会人が大量発生しておりセキュリティ上の懸念が高まっているとサイバーセキュリティ企業が指摘 - GIGAZINE
ChatGPTで秘密情報の流出を防ぐ学習拒否設定の方法&会話履歴のダウンロード方法まとめ - GIGAZINE
10万件超のChatGPTアカウントが盗まれてダークウェブで取引されていることが判明、企業の機密情報が漏えいする危険も - GIGAZINE
ChatGPTが「個人についての不名誉で誤解を招く虚偽の説明」を生成したとしてアメリカ当局がOpenAIの調査を開始 - GIGAZINE
「ChatGPTの学習に海賊版の本が使われた」として作家がOpenAIを告訴 - GIGAZINE
ユーザーの同意なしに訓練した可能性のあるChatGPTの「OpenAI」が厳格なプライバシー法を重視するEUで法的な問題に直面、「規則の準拠は不可能に近い」と専門家 - GIGAZINE
・関連コンテンツ








in ネットサービス, セキュリティ, Posted by log1h_ik
You can read the machine translated English article Report that ``a stranger obtained my ema….