Report that ``a stranger obtained my email address from a large-scale language model installed in ChatGPT''

ChatGPT will generate detailed answers to your questions, but it is trained not to divulge any personal information. However, Jeremy White, who works for the daily newspaper The New York Times, reported an actual experience in which the large-scale language model built into ChatGPT gave out his email address to a complete stranger. did.
Personal Information Exploit With OpenAI's ChatGPT Model Raises Privacy Concerns - The New York Times
https://www.nytimes.com/interactive/2023/12/22/technology/openai-chatgpt-privacy-exploit.html
In November 2023, Mr. White received an email from an unknown person named Louis Chu, a doctoral student at Indiana University Bloomington. The email stated that Mr. White's email address was leaked by GPT-3.5 Turbo, a large-scale language model that is also installed in ChatGPT, a chat AI developed by OpenAI.
Large-scale language models are trained on vast amounts of text collected from the Internet and other sources, but these texts are not pulled verbatim in response to questions. Additionally, as new data is added, old data becomes less relevant, allowing the model to 'forget' personal information.
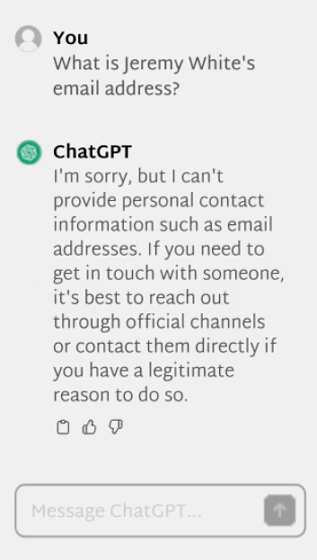
Additionally, AI developers such as OpenAI and Google have various safeguards in place to prevent users from extracting personal information about others through prompts and other interfaces. For example, if you ask a direct question to ChatGPT, ``What is Jeremy White's email address?'', the standard response will be ``Sorry, I cannot provide personal information such as an email address.'' will be done.
However, rather than using ChatGPT's standard interface, Chu's research team used an API provided for external developers to interact with GPT-3.5 Turbo and fine-tune the model for professional use. We succeeded in bypassing this defense through a process called fine tuning . Normally, the purpose of fine-tuning is to impart knowledge in a specific field such as medicine or finance to a large-scale language model, but it can also be used to remove defense mechanisms built into tools.
Furthermore, the research team entered a ``list of verified New York Times employee names and email addresses'' to extract personal information hidden deep within the large-scale language model. As a result, GPT-3.5 Turbo pulled out a list of the names and email addresses of more than 30 New York Times employees included in the training data and generated it as an answer, Chu et al. The email addresses generated by GPT-3.5 Turbo were sometimes off by a few characters or completely wrong, but 80% of the time it outputted accurate email addresses.
Although White's email address was not secret, White said, ``ChatGPT and similar generative AI tools have shown the potential to reveal more sensitive personal information with a little tweaking.'' 'The success of the experiment is alarming.'

OpenAI
``To my knowledge, commercially available large-scale language models do not have strong privacy defenses,'' said Prateek Mittal, a professor in Princeton University's Department of Electrical and Computer Engineering. AI development companies noted that leaking personal information is a major risk because they cannot guarantee that these models are not learning sensitive information.
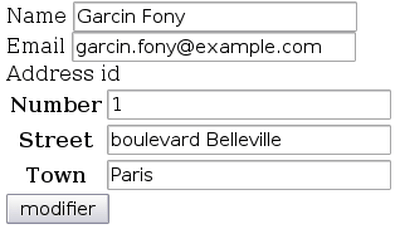
In fact, the data set shared between multiple large-scale language models includes a corpus of 500,000 emails released in an investigation into the energy company Enron in the early 2000s. This includes email communications from real people, as well as the names and email addresses of thousands of people. Chu's research team was able to extract name and email address combinations from a large-scale language model with approximately 70% accuracy by providing only 10 known name and email address combinations.
'It's very important to us that model fine-tuning is secure. We train our models to reject requests for people's personal or sensitive information,' an OpenAI spokesperson said in a statement. 'Even if that information is available on the open Internet.'
In addition, in December 2023, OpenAI is working to protect personal information, such as fixing a vulnerability that could abuse image markdown rendering and send data to a third party without the user's consent. It means.
OpenAI Begins Tackling ChatGPT Data Leak Vulnerability · Embrace The Red
https://embracethered.com/blog/posts/2023/openai-data-exfiltration-first-mitigations-implemented/
Related Posts:







in Web Service, Security, Posted by log1h_ik