OpenAI developed by ChatGPT is filed a class action lawsuit over AI learning data

Clarkson Law Firm based in California, claiming that the training dataset used to train the chatbot AI ``ChatGPT'' developed by artificial intelligence company OpenAI infringes the copyrights and privacy of countless people. filed a class action lawsuit against OpenAI.
The AI Arms Race and Why We Need to Come Together Now — Clarkson
OpenAI Complaint
(PDF file) https://storage.courtlistener.com/recap/gov.uscourts.cand.414754/gov.uscourts.cand.414754.1.0.pdf

OpenAI Sued for Using 'Stolen' Data, Violating Your Privacy With ChatGPT | PCMag
https://www.pcmag.com/news/openai-sued-for-using-stolen-data-violating-your-privacy-with-chatgpt
ChatGPT maker OpenAI faces class action lawsuit over data to train AI - The Washington Post
https://www.washingtonpost.com/technology/2023/06/28/openai-chatgpt-lawsuit-class-action/
ChatGPT developed by OpenAI is based on a large-scale language model called GPT. And part of the dataset used for learning by GPT 3.5 is an open source dataset provided by the non-profit organization Common Crawl . The dataset provided by Common Crawl consists of a total of 45 TB of text collected from the Internet since 2008, and it is said that it still has a size of 570 GB even after filtering for learning.
Clarkson Law Firm said that OpenAI trained GPT and ChatGPT on vast amounts of text found on the internet without asking for consent or warning users, and that federal and state privacy laws do not allow it to do so. alleging a violation of Filed a complaint in the United States Court for the Northern District of California dated June 28, 2023. The plaintiff, Clarkson Law Firm, has asked OpenAI to ``temporarily suspend the provision of ChatGPT until various security measures are taken,'' and to establish an independent council to evaluate OpenAI's AI. We are seeking damages for scraping personal information without consent.
Clarkson Law Firm claims on its official blog that ``OpenAI and its partner Mirosoft are preparing to make huge profits from AI technology despite collecting personal information without consent.'' Did.

Clarkson Law Firm also said, ``Microsoft has invested billions of dollars (about hundreds of billions of yen) in OpenAI and used its powerful technology to create a global AI arms race.The most innovative An almost unimaginable amount of data has been collected to build this technology, much of this information comes from the personal data of nearly everyone who has ever used the Internet, including children of all ages. Collected without permission, everywhere, from everyone, everything at once.'
In the United States, the copyright of data used in training datasets is not clearly defined legally. There is an idea of `` fair use '' in the United States, but it is still being discussed at the time of article creation whether the use of data for this training dataset is fair use. Stable Diffusion and Midjourney, which are the same generative AI as ChatGPT, have also been filed a class action lawsuit, claiming that the images contained in the dataset `` LAION-5B '' used for learning are used without consent from artists and creators.
A class action lawsuit is filed against image generation AI ``Stable Diffusion'' and ``Midjourney''-GIGAZINE

American daily newspaper The Washington Post and IT news site PCMag asked OpenAI for comments, but it seems that there was no response.
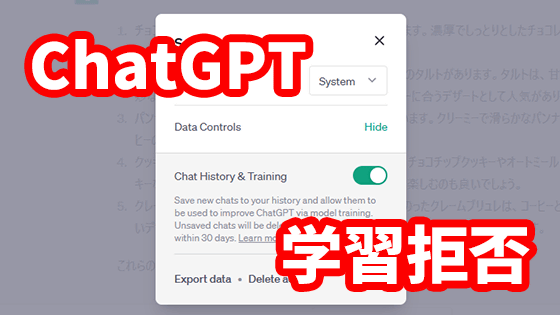
In April 2023, OpenAI added a setting to ChatGPT that refuses to use the entered personal information and confidential information for learning.
How to set learning refusal to prevent leakage of confidential information with ChatGPT & How to download conversation history Summary - GIGAZINE
Related Posts:







in Software, Web Service, Web Application, Posted by log1i_yk