




Appleが画像を見て質問に答えられる大規模言語モデル「Ferret」を開発、ウェイトの情報が公開される
画像とテキストを組み合わせてタスクをこなせるマルチモーダル大規模言語モデルの「Ferret」のウェイト情報をAppleが公開しました。ウェイトのデータはCC-BY-NCライセンスでの提供となっており、研究目的でのみ利用可能です。
apple/ml-ferret
https://github.com/apple/ml-ferret
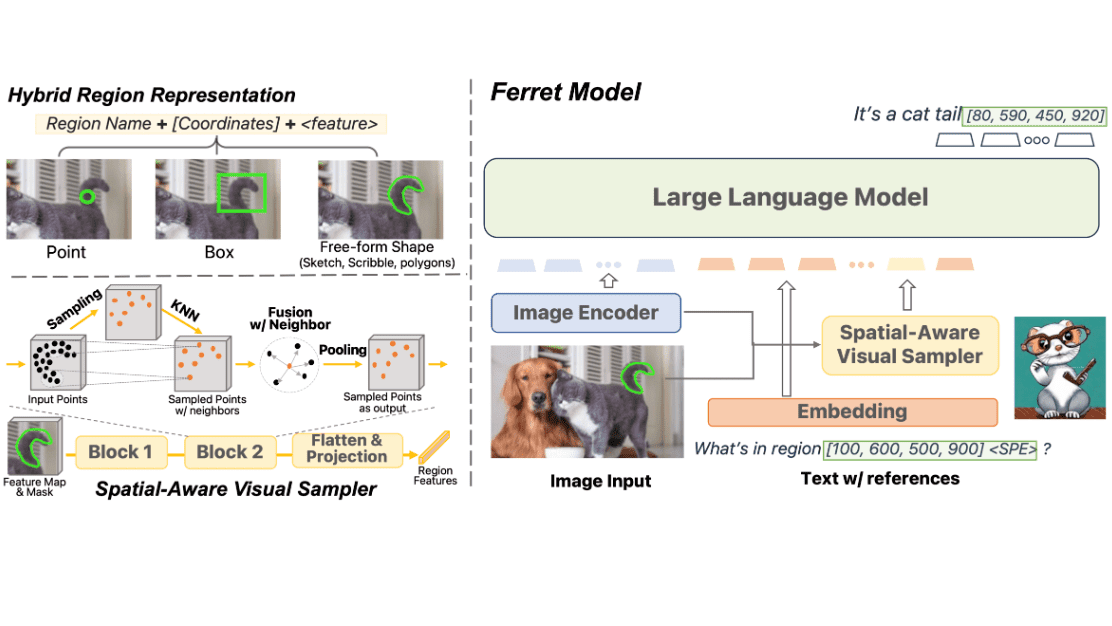
Ferretは2023年10月30日に公開されたマルチモーダル大規模言語モデルで、画像の領域を指定して解釈する能力があることが特徴です。領域の指定方法には「点」「四角形」「フリーフォーム」の3種類が存在しています。
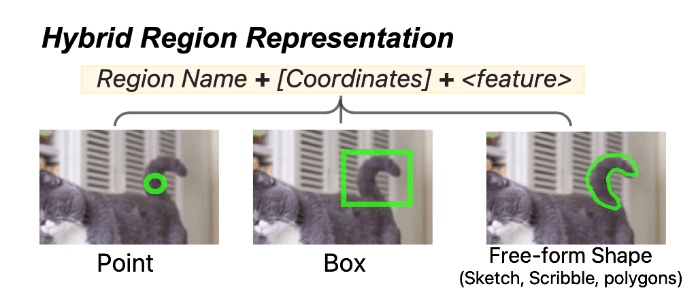
画像の一部を指定することで、テキストで「領域[100, 600, 500, 900]には何がありますか?」のように領域を参照して質問することが可能です。Ferretモデルは画像とテキストを元に、「ネコの尻尾です」のように回答することができます。同時に、より正確な領域の情報も返答してくれるとのこと。
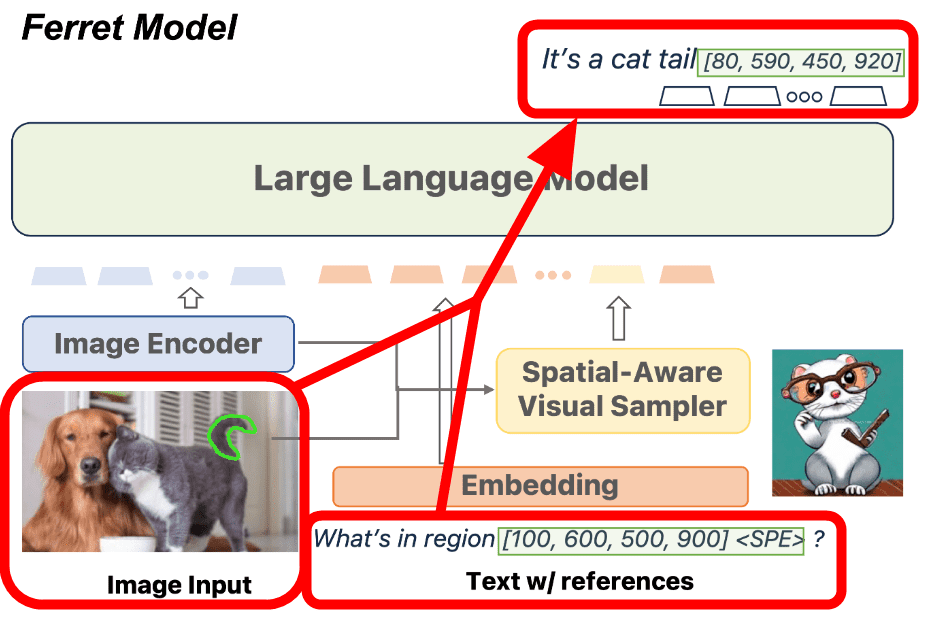
Ferretモデルは2023年3月に公開された大規模言語モデル「Vicuna」をベースにメモリ80GBのA100 GPUを8個使用してトレーニングされており、今回Appleが公開したのはVicunaのウェイトからの差分データのみとなっています。Vicunaについては下記の記事で解説しています。
ChatGPTに匹敵する性能の日本語対応チャットAI「Vicuna-13B」のデータが公開され一般家庭のPC上で動作可能に - GIGAZINE

VicunaはMeta AIが2023年2月に発表したLLaMAをベースにファインチューニングしたモデルであるため、Ferretモデルを利用するにはFerretモデル差分のライセンスであるCC-BY-NC以外にも、VicunaおよびLLaMAのライセンスに従う必要があります。
GitHubのページにてデモの起動方法や動作の様子が公開されています。デモではGradio Web UIが使用されており、下図の通り画像を入力して領域を指定すると左下に領域データが表示されます。後はその領域データを元にテキストで質問すればOK。今回の例では「物体[region0]と物体[region1]の間にはどんな関係性がありますか?」と質問しています。
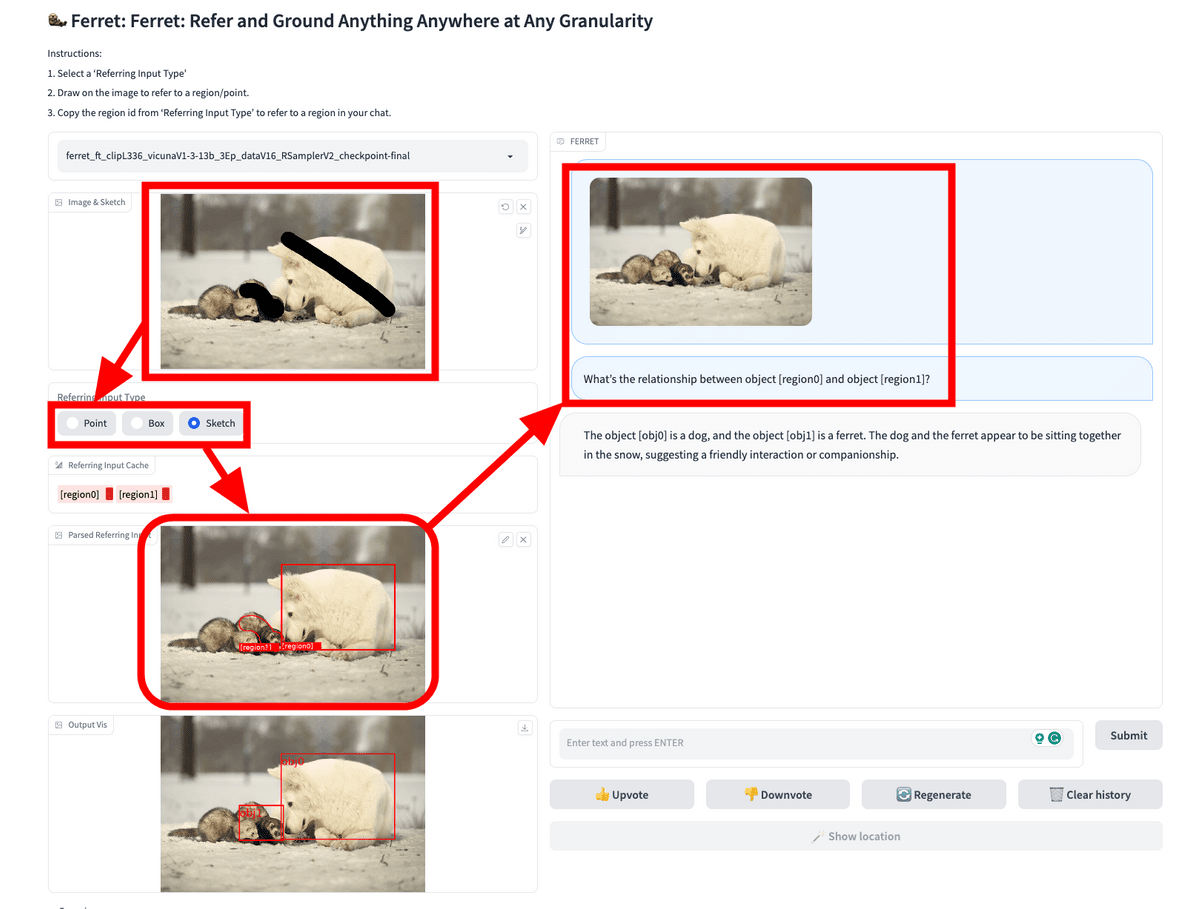
Ferretの返答は「物体[obj0]は犬、物体[obj1]はフェレットです。犬とフェレットは雪の中で一緒に座っており、友好的な関係を示しています」となりました。

同時に、Ferretがそれぞれの領域内でどの部分を認識したのかという領域データも返答されています。

なお、デモを利用するにはVicunaのウェイトとFerretの差分データを元にFerretのウェイトを生成する手順が必要とのことです。
・関連記事
Appleは大規模言語モデルをiPhone上でローカルに動作させることを目指している - GIGAZINE
Appleの機械学習チームがAppleシリコンで機械学習モデルをトレーニング・デプロイするためのフレームワーク「MLX」をGitHubで公開 - GIGAZINE
Googleが「大規模言語モデルに視覚を与える仕組み」について解説、メルカリと協力して作成したデモも公開 - GIGAZINE
文字・音声・画像を同時に処理して人間以上に自然なやりとりができるGPT-4を超える性能のマルチモーダルAI「Gemini」がリリースされる - GIGAZINE
Anthropicが大規模言語モデル「Claude 2.1」をリリース、最大20万トークン・15万ワードを読込可能で幻覚が半減し新しいAPI統合などを提供 - GIGAZINE
・関連コンテンツ








in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article Apple develops a large-scale language mo….