Apple develops a large-scale language model ``Ferret'' that can answer questions by looking at images, and weight information is released
Apple has released weight information for Ferret , a multimodal large-scale language model that can perform tasks by combining images and text. Weight data is provided under CC-BY-NC license and may be used for research purposes only.
apple/ml-ferret
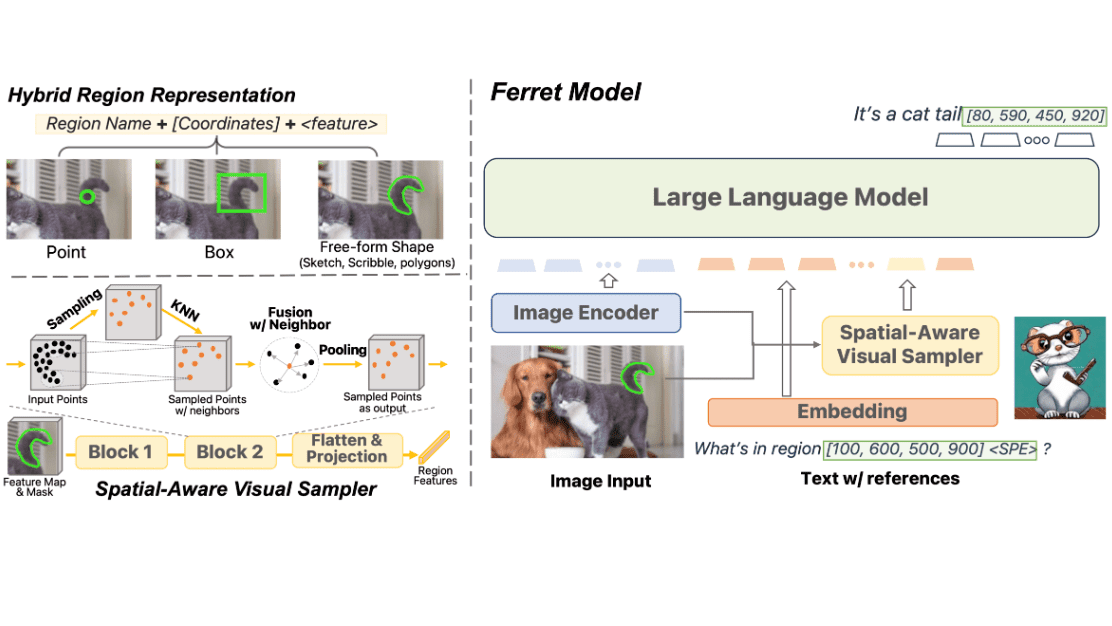
Ferret is a multimodal large-scale language model released on October 30, 2023, and is characterized by its ability to specify and interpret image regions. There are three ways to specify an area: ``point,'' ``rectangle,'' and ``free form.''
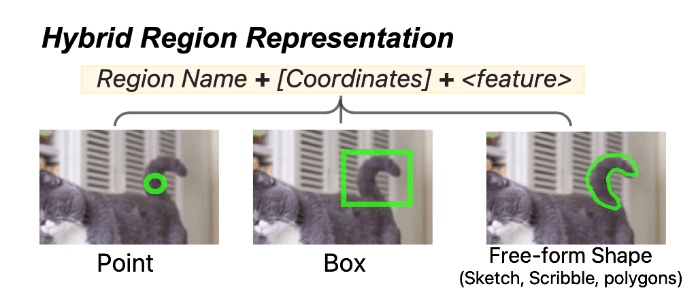
By specifying a part of the image, it is possible to refer to the area and ask a question using text, such as 'What is in the area [100, 600, 500, 900]?' The Ferret model can respond based on images and text, such as 'It's a cat's tail.' At the same time, it will also respond with more accurate area information.
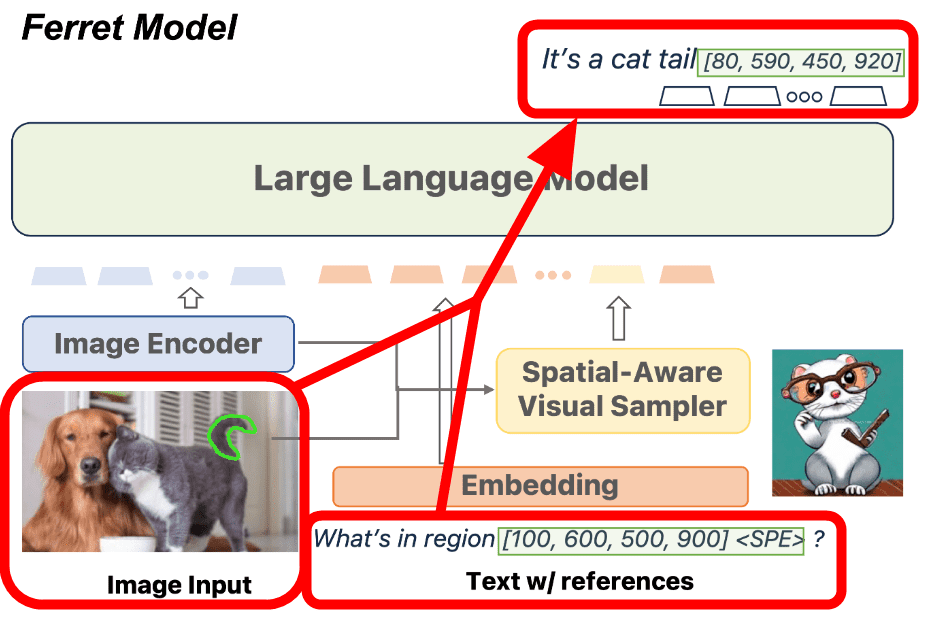
The Ferret model is trained using eight A100 GPUs with 80GB of memory based on the large-scale language model 'Vicuna' released in March 2023, and this time Apple has released the difference from Vicuna's weights. It is data only. Vicuna is explained in the article below.

Vicuna is a fine-tuned model based on LLaMA announced by Meta AI in February 2023, so in order to use the Ferret model, in addition to CC-BY-NC, which is a license for Ferret model differences, Vicuna and LLaMA must comply with the license .
How to start the demo and how it works is published on the GitHub page . The demo uses Gradio Web UI, and as shown in the image below, if you input an image and specify an area, the area data will be displayed at the bottom left. After that, all you have to do is ask questions in text based on the area data. In this example, we are asking, 'What kind of relationship is there between object [region0] and object [region1]?'
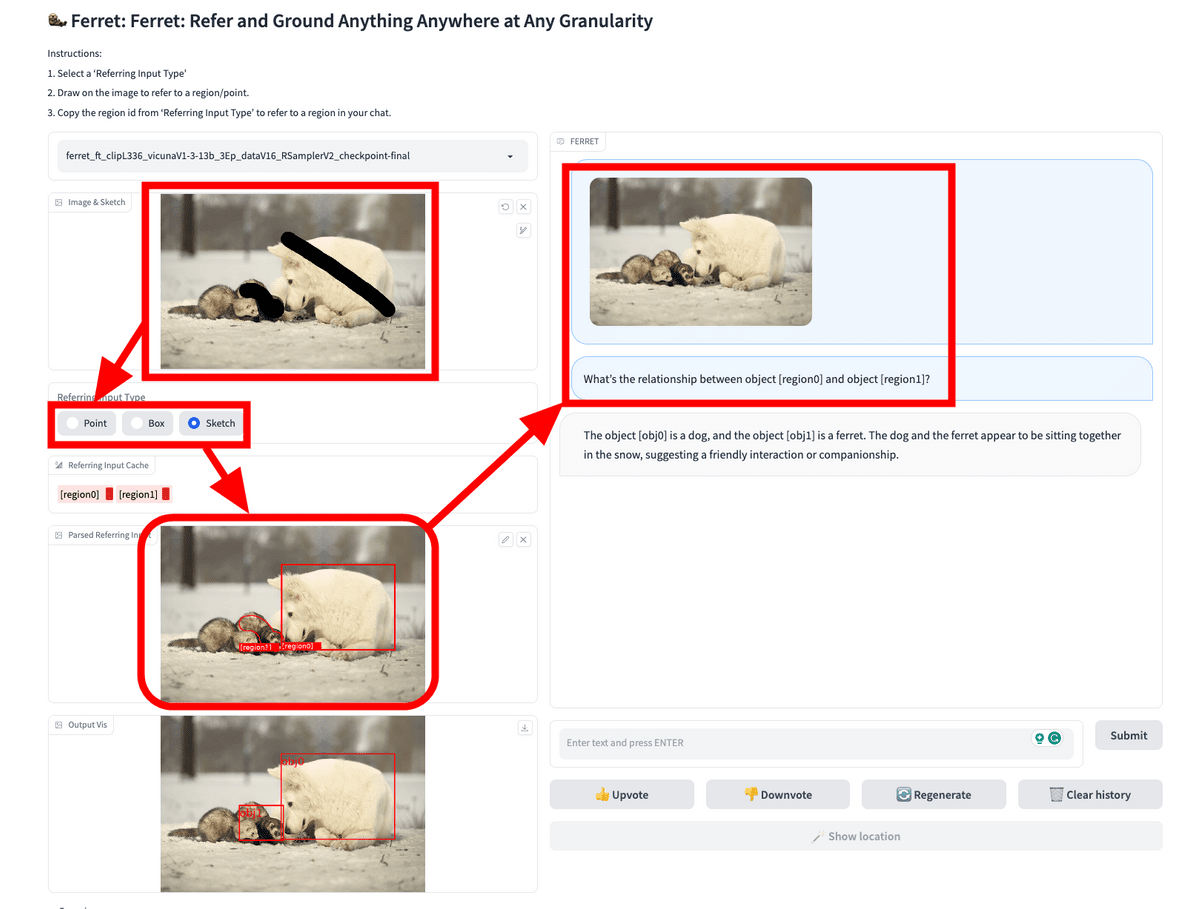
Ferret's response was 'Object [obj0] is a dog and object [obj1] is a ferret. The dog and ferret are sitting together in the snow, indicating a friendly relationship.'

At the same time, area data indicating which parts of each area were recognized by Ferret is also returned.

In addition, in order to use the demo, it is necessary to generate Ferret weights based on the difference data between Vicuna weights and Ferret.
Related Posts:





in Software, Posted by log1d_ts