




OpenAIが開発している新型AI「Q*(キュースター)」とは一体どのようなものだと推測されているのか?

2023年11月のサム・アルトマンCEO解任騒動の一因として話題になったのが、OpenAIの新たなAI開発プロジェクト「Q*(キュースター)」です。このQ*は、従来の大規模言語モデルには苦手だった数学的推論の能力が強化されており、より汎用人工知能(AGI)の研究に画期的な進歩をもたらすのではないかと予想されています。そんなQ*がどういうAIなのかについて、AIについて詳しいジャーナリストのティモシー・B・リー氏がまとめています。
How to think about the OpenAI Q* rumors - by Timothy B Lee
https://www.understandingai.org/p/how-to-think-about-the-openai-q-rumors
リー氏は以下の問題を例に出しています。
「ジョンはスーザンにリンゴを5個与え、さらに6個を与えました。それからスーザンはリンゴを3個食べて、チャーリーに3個あげました。彼女は残りのリンゴをボブにあげ、ボブは1つ食べました。ボブはリンゴの半分をチャーリーにあげました。ジョンはリンゴを7個チャーリーにあげ、チャーリーはリンゴの3分の2をスーザンにあげました。それからスーザンはチャーリーにリンゴを4個あげました。チャーリーは今リンゴを何個持っていますか?」

最終的にチャーリーが持っているリンゴは、8個が正解です。計算自体は決して難しくはありませんが、問題文の内容に沿って段階的に数字を追いかけていく必要があります。
大規模言語モデルにとって、5や6といった数字はトークンに過ぎません。大規模言語モデルはこのトークンがトレーニングデータに何千回も出現するため、5+6=11であるという計算であれば経験的に学習します。しかし、[3+[{(5+6)-3}-1]/2+7]/3+4=8といった長い計算の例はトレーニングデータに含まれていません。そのため、こうした計算を一度に実行しようとすると大規模言語モデルが間違った答えを出してしまう可能性がきわめて高くなるというわけです。
2022年1月に発表された(PDFファイル)論文で、Googleの研究者が「大規模言語モデルは一度に1ステップずつ推論するように促されれば、より良い結果を出す」と論じました。思考連鎖推論により、大規模言語モデルは複雑な計算問題をいくつかのステップに分割し、そのステップ1つ1つの正解をトレーニングデータから導くという方法です。
Googleがこの論文を発表する数カ月前、OpenAIは小学校レベルの数学の文章題8500問で構成されるデータセット「GSM8K」と、それを解くための新しいテクニックに関する論文を発表しました。OpenAIは、大規模言語モデルに100の答えを生成させ、「検証モデル」と呼ばれる2つ目のモデルを使って各回答を評価します。大規模言語モデルは、100個の回答のうち検証者によって最も高く評価されたものを出力するというわけです。

この検証モデルをトレーニングするのは大規模言語モデルをトレーニングするのと同じくらい難しいと思うかもしれませんが、OpenAIによれば、小規模な生成モデルと小規模な検証モデルを組み合わせることで、30倍のパラメーターを持つより大きな生成モデルと同程度の結果が得られるとのこと。
さらに2023年5月の論文では、OpenAIは小学校の算数問題を超えてもっと難しい数学の問題にもチャレンジしていることを明らかにしました。ここでは検証モデルが答えを採点するのではなく、解答の各ステップを検証モデルで評価するという方法を採用しています。
例えば以下の画像では、「とある分数の分母は分子の3倍より7小さい。分数が2/5に相当する場合、分数の分子は何倍か?」という問題を大規模言語モデルに解かせたところ。「分子をxと置きます」「分母は3x-7となります」「x/(3x-7)=2/5と立式できます」「5x=2(3x-7)」「5x=6x-14」と順番に解いており、それぞれは正しいので検証モデルによってOKの評価をもらった証として緑色の絵文字が表示されています。最後の「だからx=7です」という結論の部分が間違えているので、検証モデルによってNGの評価となり、赤の絵文字が表示されています。
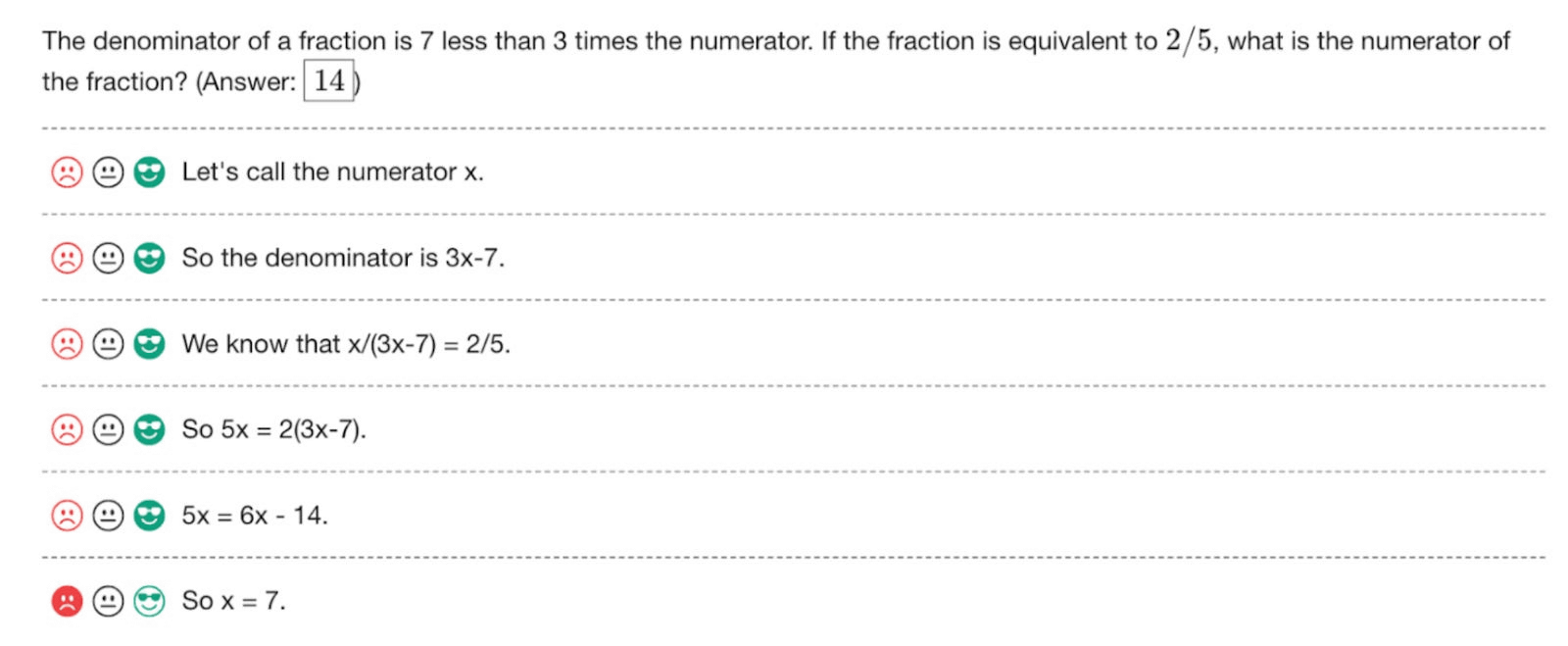
この方法のメリットは、推論プロセスの各ステップで検証モデルを使用すると解答の正確性が高くなるということです。しかし、トレーニングデータは問題と解答がセットにはなっているものの、推論ステップそのものが合っているかどうかを検証する方法がありません。そこでOpenAIは、7万5000種類の解法におけるのべ80万ステップについて、人間を雇用して正しいかどうかを最終的に評価するというやり方を導入しています。
計算ではなく、論理問題の場合はどうなるでしょうか?リー氏は以下の問題を例題として挙げています。
「披露宴で5つのテーブルが用意されており、1つのテーブル当たり3人のゲストを座らせます。
・アリスはベサニー、エレン、キミーと同席したくない。
・ベサニーはマーガレットと同席したくない。
・チャックはナンシーと座りたくない。
・フィオナはヘンリーともチャックとも座りたくない。
・ジェイソンはベサニーやドナルドと座りたくない。
・グラントはイングリッド、ナンシー、オリビアと座りたくない。
・ヘンリーはオリビア、ルイーズ、マーガレットと座りたくない。
・ルイーズはマーガレット、オリビアと同席したくない。
これらの好みがすべて尊重されるようにゲストを座らせるには、どうしたらいいでしょうか?」
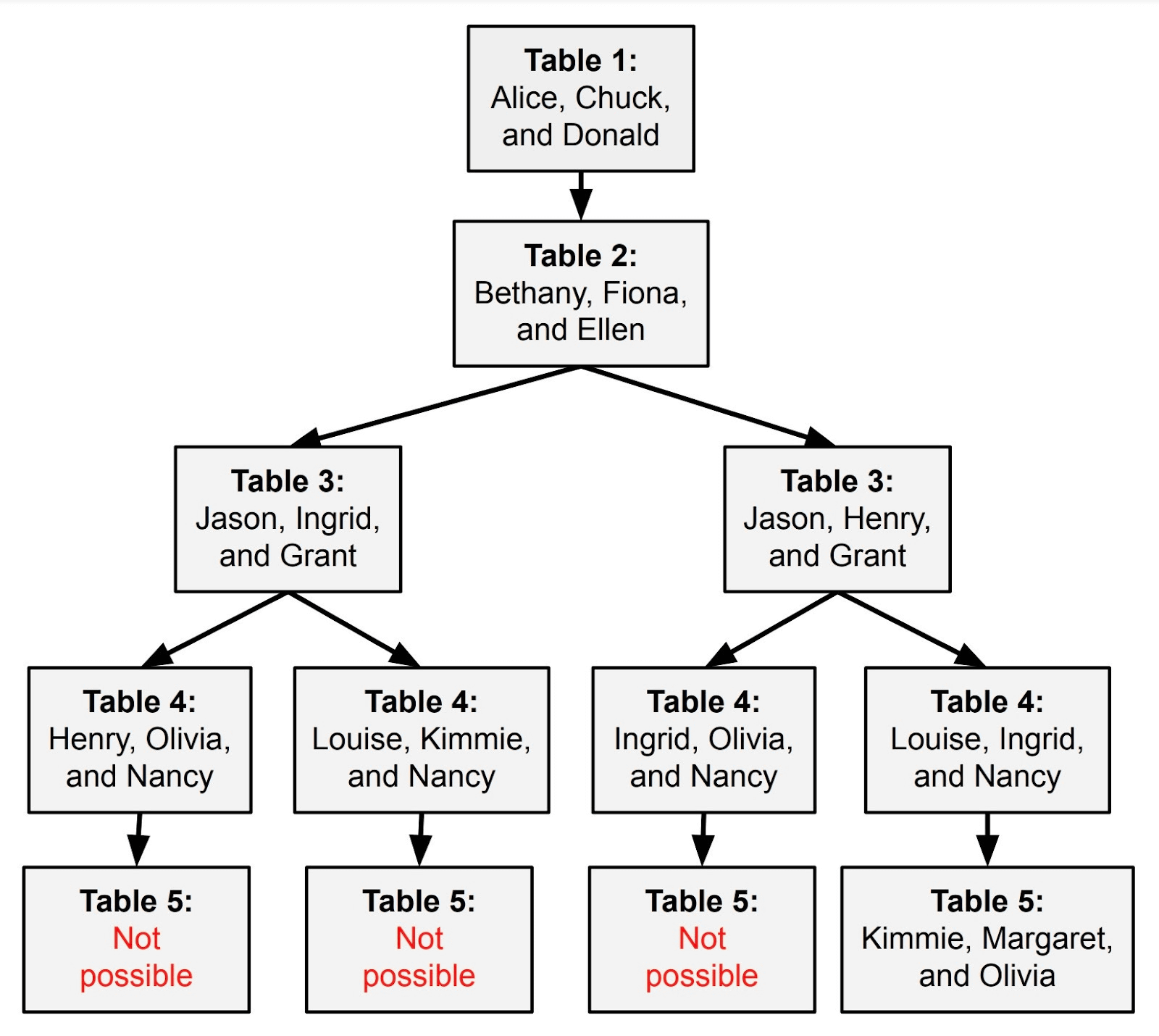
上記の問題をGPT-4に入力すると、GPT-4は段階的に推論を始めます。3つ目のテーブルまでは解決が進んだものの、4つ目のテーブルで解答できなくなってしまいました。この問題は提示された順番通りに上から素直に条件を推理していくと、後の条件が前の条件と関連してしまうため、解答に矛盾が発生してしまうためです。
大規模言語モデルがこの問題を解くためには、以下のようなルートをたどって推論を進めていく必要があります。全問正解できるのは一番右のルートのみで、それ以外はどうやっても破綻してしまいます。つまり、正しい解答をできる推論ルートを引く確率は4分の1になってしまうというわけです。
Google DeepMindとプリンストン大学の研究者が2023年5月に発表した論文で、1本の推論ルートで問題を解決するのではなく、さまざまな方向に分岐する一連の推論ルートを体系的にチェックできるようにする「Tree of Thoughts」と呼ばれるアプローチを発表しました。研究チームは、このアルゴリズムが従来の大規模言語モデルでは解決が難しかった問題や文章生成でも大きな効果を発揮すると論じました。
そして、この「複数の推論ルートを体系的にチェックする」という部分で、Google DeepMindが注目したのが囲碁AIのAlphaGoです。さまざまな手を一瞬で評価して判断するAlphaGoを大規模言語モデルと組み合わせれば、大規模言語モデルの推論能力も向上する可能性があります。
OpenAIは2023年初めに、コンピューター科学者であるノーム・ブラウン氏を雇用しました。ブラウン氏は超人的なレベルでポーカーをプレイできるAIを開発した人物で、その後はMetaでもAIの研究を行っていたとのこと。Metaの主任AI研究者であるヤン・ルクン氏は「Q*はOpenAIの計画である可能性があります。彼らはほとんどQ*の開発に取り組むために、ノーム・ブラウン氏を雇ったようなものです」と述べています。
Please ignore the deluge of complete nonsense about Q*.
— Yann LeCun (@ylecun) November 24, 2023
One of the main challenges to improve LLM reliability is to replace Auto-Regressive token prediction with planning.
Pretty much every top lab (FAIR, DeepMind, OpenAI etc) is working on that and some have already published…
ブラウン氏はポーカーやディプロマシーをプレイするAIの研究を行っていましたが、「これからはこれらの手法を真に一般化する方法を研究しています」と2023年6月にポストしています。
I’m thrilled to share that I've joined @OpenAI! ???? For years I’ve researched AI self-play and reasoning in games like Poker and Diplomacy. I’ll now investigate how to make these methods truly general. If successful, we may one day see LLMs that are 1,000x better than GPT-4 ???? 1/
— Noam Brown (@polynoamial) July 6, 2023
AlphaGoやブラウン氏のポーカー用AIで使われている手法は、特定のゲームに特化したものでした。しかし、ブラウン氏は「もし一般的なバージョンを発見できれば、その恩恵は非常に大きなものになるだろう」と予測しました。
しかし、リー氏はOpenAIがQ*を真に完成させるには少なくとも2つの大きな課題を克服する必要があると述べています。
1つは、「大規模言語モデルが自己再生を行う方法を発見すること」です。例えばAlphaGoは、対戦して勝ったか負けたかの結果が自身にフィードバックされました。OpenAIのQ*も精度を上げるためには、問題に対して解決したのかどうかの結果を自身にフィードバックさせる仕組みが求められます。2023年5月の時点では、OpenAIはその正しさのチェックに雇用した人間を使っていました。もし画期的な進歩があったとするならば、2023年内に重大な発見があったといえます。
もう1つは、「一般的な推論アルゴリズムには可能な解を探索しながらその場で学習する能力が必要」だということ。
今日のニューラルネットワークはトレーニングと推論を分離しています。例えば、AlphaGoは囲碁の対戦中に学習して進化することはなく、対局が終わってから自分にフィードバックさせて学習していきます。しかし、実際の人間であれば、囲碁の対局中に起こり得るあらゆる状況を経験し、そのまま学習しながら対局を行うことができます。
リー氏は、「真に一般的な推論エンジンを構築するには、もっと根本的なアーキテクチャの革新が必要なのではないでしょうか? 人間の脳がそうであるように、我々はこれが可能であることを知っています。しかし、OpenAIやDeepMind、あるいは他の誰かがシリコンでそれを行う方法を見つけ出すまでには、しばらく時間がかかるかもしれません」と述べています。
・関連記事
文字・音楽・画像を同時に処理する「マルチモーダルAI」の性能がよく分かるGoogleの「Gemini」ハウツー動画11種を解説 - GIGAZINE
Google製チャットAI「Bard」の年齢制限が13歳以上に緩和&グラフ生成機能や途中式表示機能なども追加される - GIGAZINE
ChatGPTの回答には政治的偏りによるバイアスが潜んでいるという研究結果 - GIGAZINE
Googleが最新の大規模言語モデル「PaLM 2」や生成AIを用いたGoogle Workspaceの新機能を「Google I/O 2023」で発表予定 - GIGAZINE
・関連コンテンツ







in ソフトウェア, Posted by log1i_yk
You can read the machine translated English article What is the new AI 'Q * (Q Star)' develo….