




無料でウェブ魚拓やインターネットアーカイブのようにページやサイトを保存できブラウザ履歴・ブックマークなどからも全自動保存OKのオープンソースでセルフホスト可能な「ArchiveBox」使ってみたよレビュー

Wayback Machineやウェブ魚拓など、特定時点のウェブページのデータを保存するサービスは多数存在しています。そうしたアーカイブサービスのうち、「ArchiveBox」はオープンソースで開発されており、セルフホストすることで自分だけのデータを保存可能になるサービスとのことなので、実際に使い勝手を確かめてみました。
ArchiveBox/ArchiveBox: 🗃 Open source self-hosted web archiving. Takes URLs/browser history/bookmarks/Pocket/Pinboard/etc., saves HTML, JS, PDFs, media, and more...
https://github.com/ArchiveBox/ArchiveBox

ArchiveBoxのセットアップ方法はパッケージマネージャーを利用するものとDockerを利用するものがありますが、今回はDockerを利用するため、下記のリンクから自分の環境に合った方法でDockerをインストールします。
Install Docker Engine | Docker Documentation
https://docs.docker.com/engine/install/
今回はDebianを利用するため、下記のコマンドを入力しました。
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/debian \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Dockerがインストールできたら、下記のコードを実行してセットアップを行います。
docker run -v $PWD/data:/data -it archivebox/archivebox init --setup
セットアップ中に管理ユーザーの「ユーザーネーム」「メールアドレス」「パスワード」「パスワード(確認)」の入力を求められるので順次入力します。
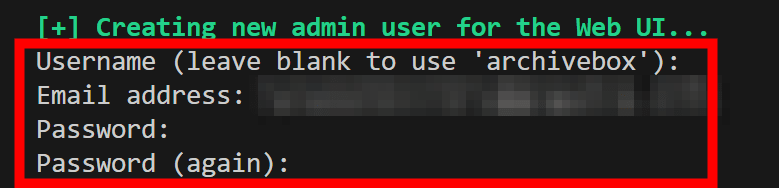
続いて下記のコードでサーバーを起動します。
docker run -v $PWD/data:/data -p 80:8000 archivebox/archivebox server
サーバーの起動後、ブラウザでアクセスすると下図のような画面が表示されました。まだ何も保存していないのでデータが0件になっています。
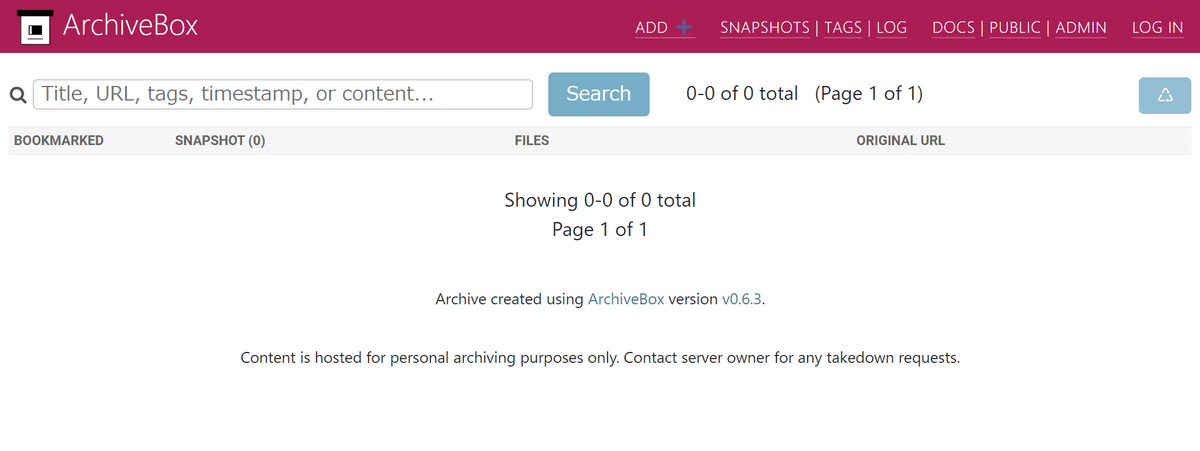
さっそくウェブページを保存していきます。ArchiveBoxには下記の通りさまざまな保存方法が用意されています。
◆1:コマンドラインからURLを指定
◆2:ウェブアプリからURLを入力
◆3:Pocketやブラウザのブックマークをまとめて指定
◆4:拡張機能で閲覧したページを自動指定
◆1:コマンドラインからURLを指定
コマンドラインで保存したいURLを指定するには下記のコードを実行すればOK。「https://gigazine.net」の部分で保存するアドレスを指定しています。
docker run -v $PWD/data:/data -it archivebox/archivebox add 'https://gigazine.net'
保存が始まりました。さまざまなデータをダウンロードしている様子。

GIGAZINEのトップページの場合、約1分で保存が完了しました。同様の手順で「https://google.co.jp」や「https://youtube.com」も試してみます。
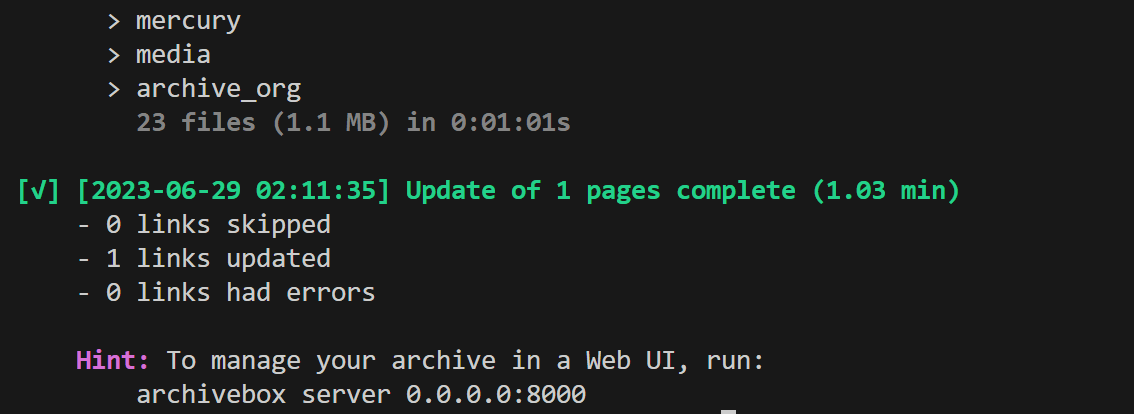
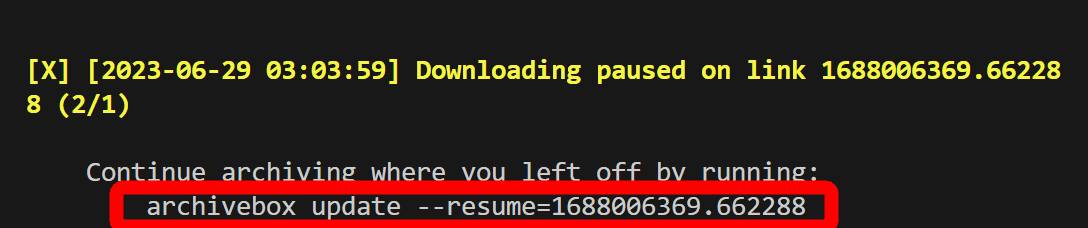
YouTubeについては保存開始から5分経過しても全然進行していなかったので、一度「Ctrl + C」を入力して中断します。
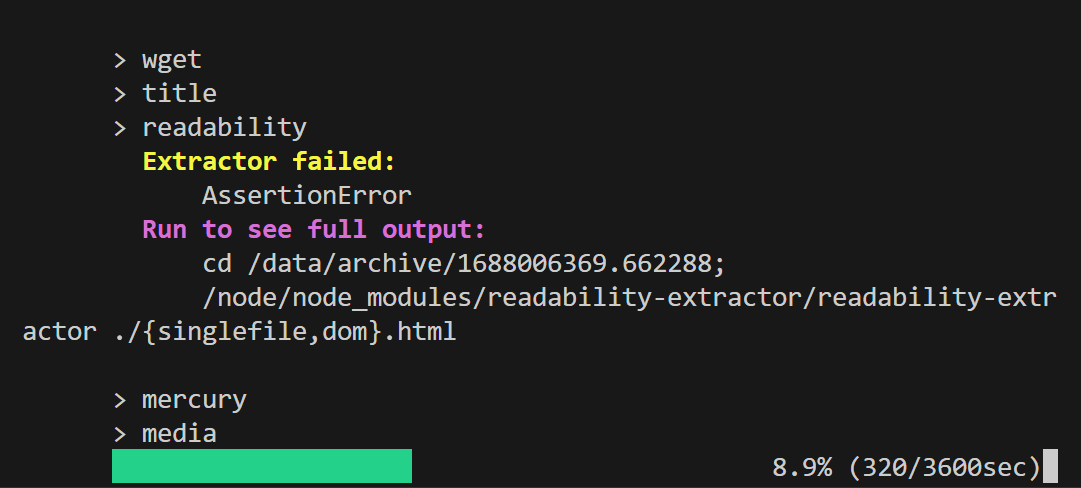
中断しても、中断時点までにダウンロードしたデータは保存されており、さらに中断時に表示されるコードを実行することでいつでも中断時点から保存を再開することも可能です。
コマンドの実行時にデータを保存する方法のほか、スケジュールを指定して定期的にページを保存する方法も用意されているとのことです。
◆2:ウェブアプリからURLを入力
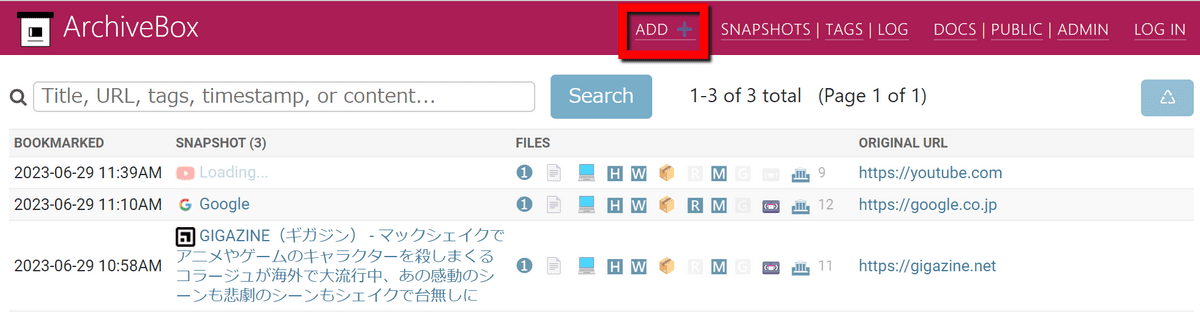
続いてGUI経由で新たなウェブページを保存してみます。ArchiveBoxのトップページにある「ADD」をクリック。
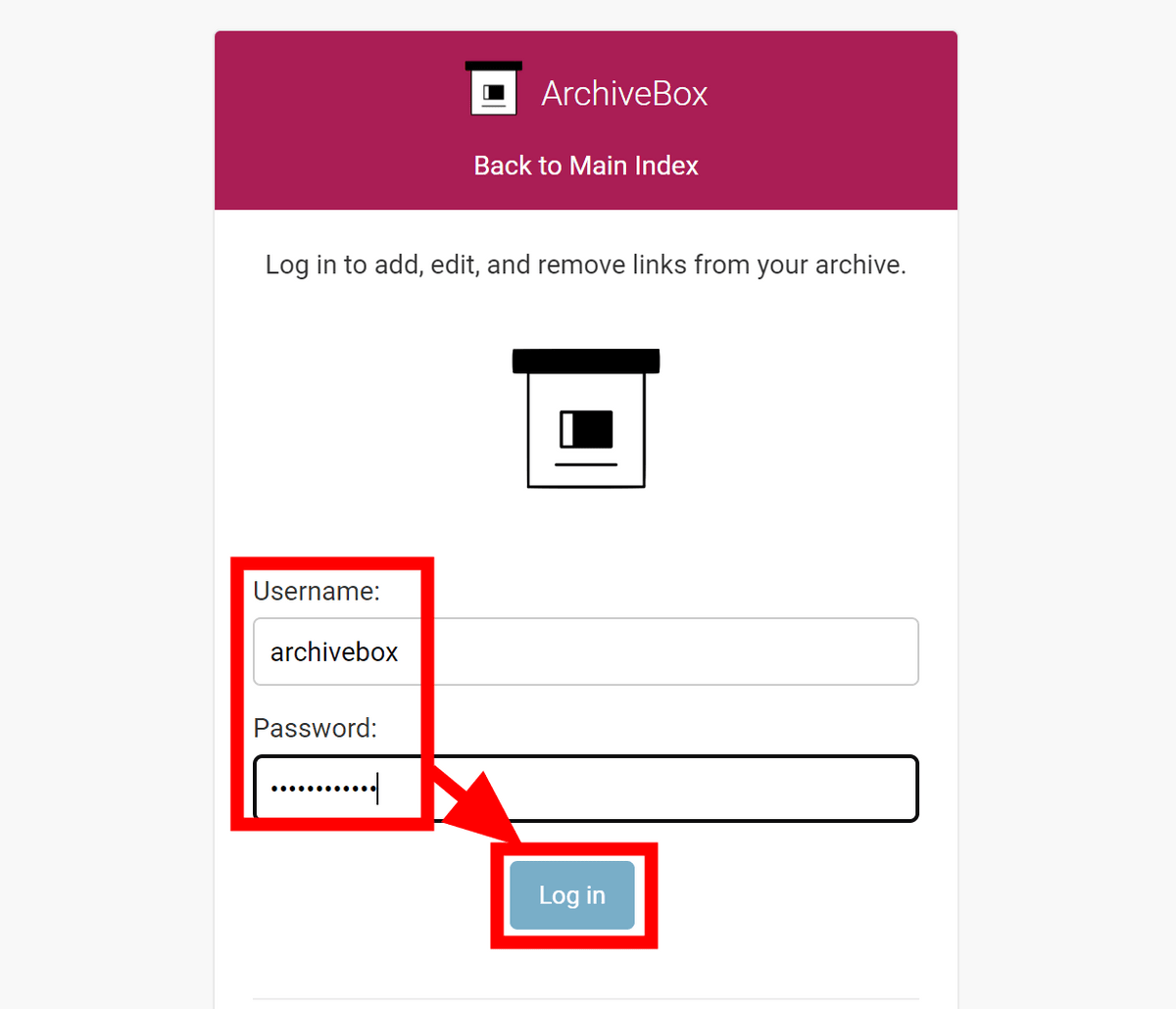
セットアップ時に設定したユーザーネームとパスワードでログインします。
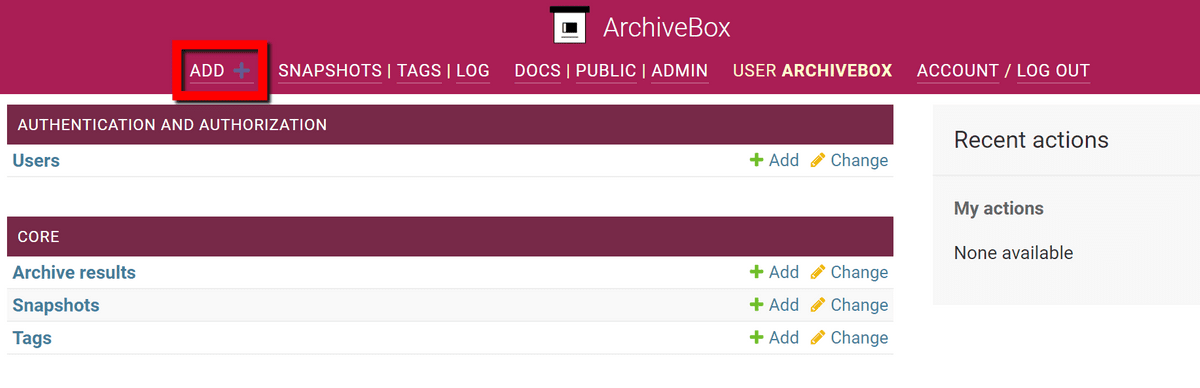
もう一度「ADD」をクリック。
すると下図のようにURLを入力できる画面になりました。
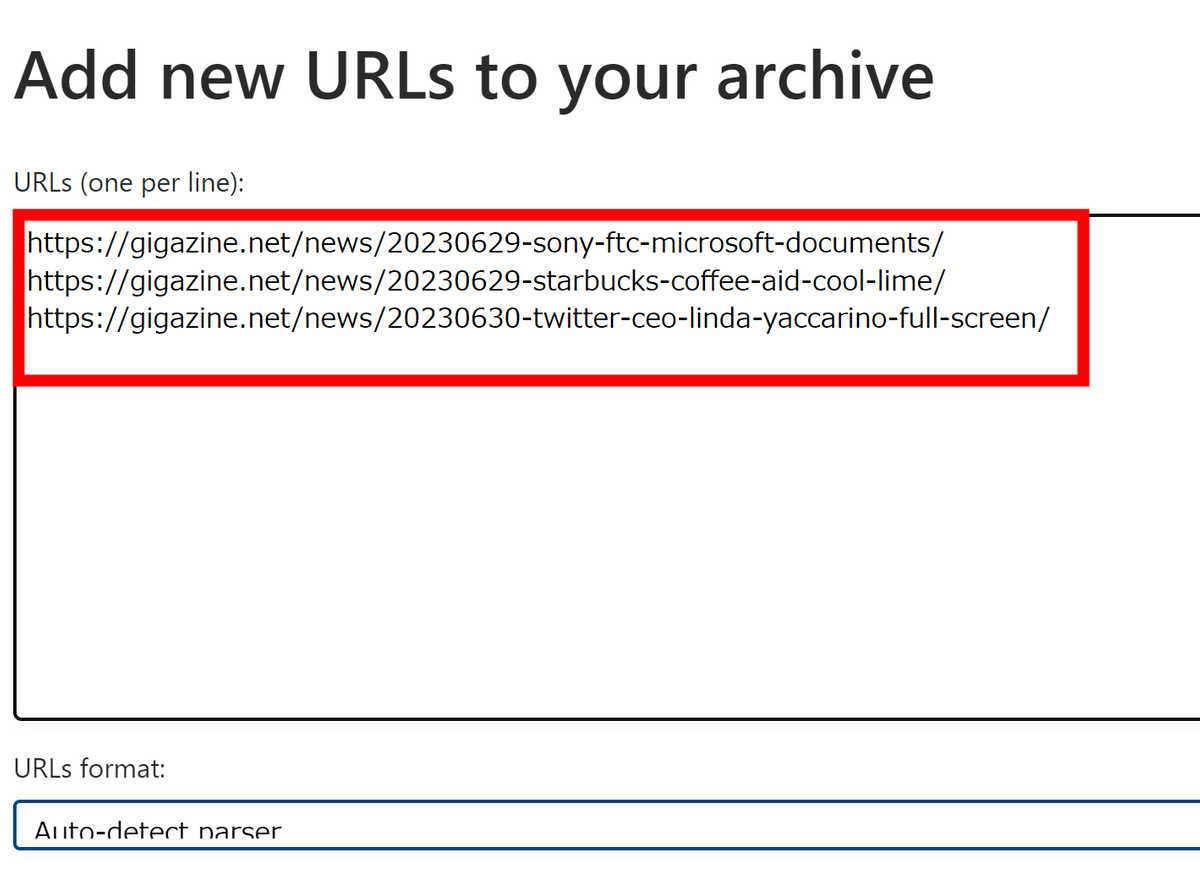
タグや保存の深さ、どの形式で保存するかを選択して「Add URLs and archive」をクリック。形式の選択については、何も選択しなければ全ての形式で保存されます。特定の形式のみを指定する場合、「title(タイトル)」を選択しないとデータの保存が完了した後もずっとタイトルが「pending(処理中)」と表示される点に注意が必要です。

「URLを追加中」という画面になりました。「Log」をクリックします。
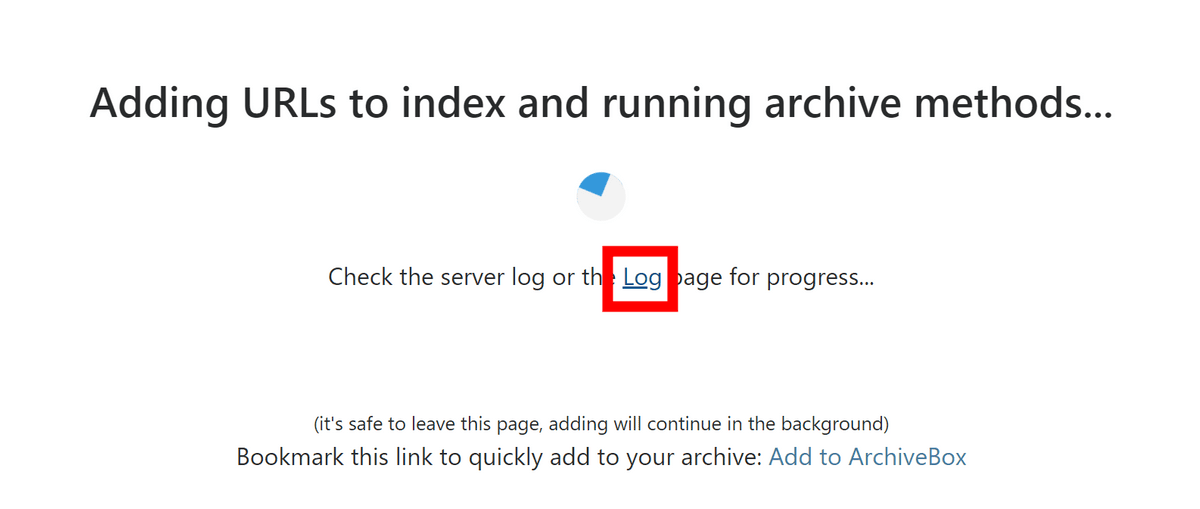
Log画面では各記事のデータが処理されていく様子が確認できました。
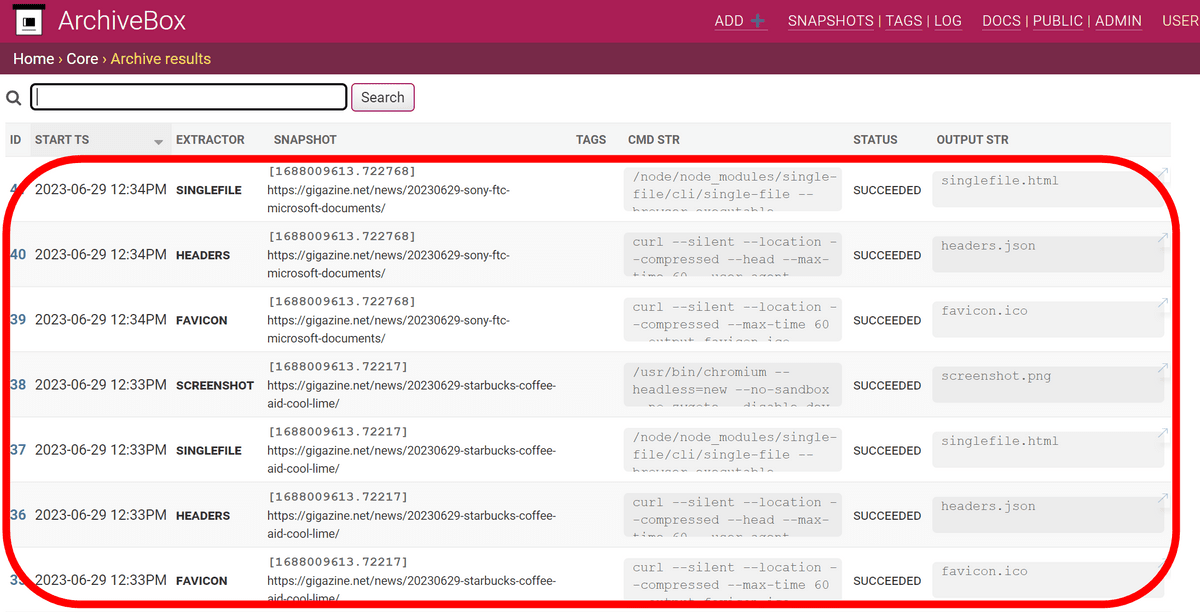
しばらく待ってからトップページに戻るとデータが追加されているのが確認できます。
◆3:Pocketやブラウザのブックマークをまとめて指定
ウェブアプリからURLを追加する時に、シンプルに一行ずつURLを並べていく形式のほか、PocketやブラウザのブックマークからのエクスポートデータやRSSを入力することができます。入力可能な形式はURL追加ページの「URLs format」欄で確認できます。
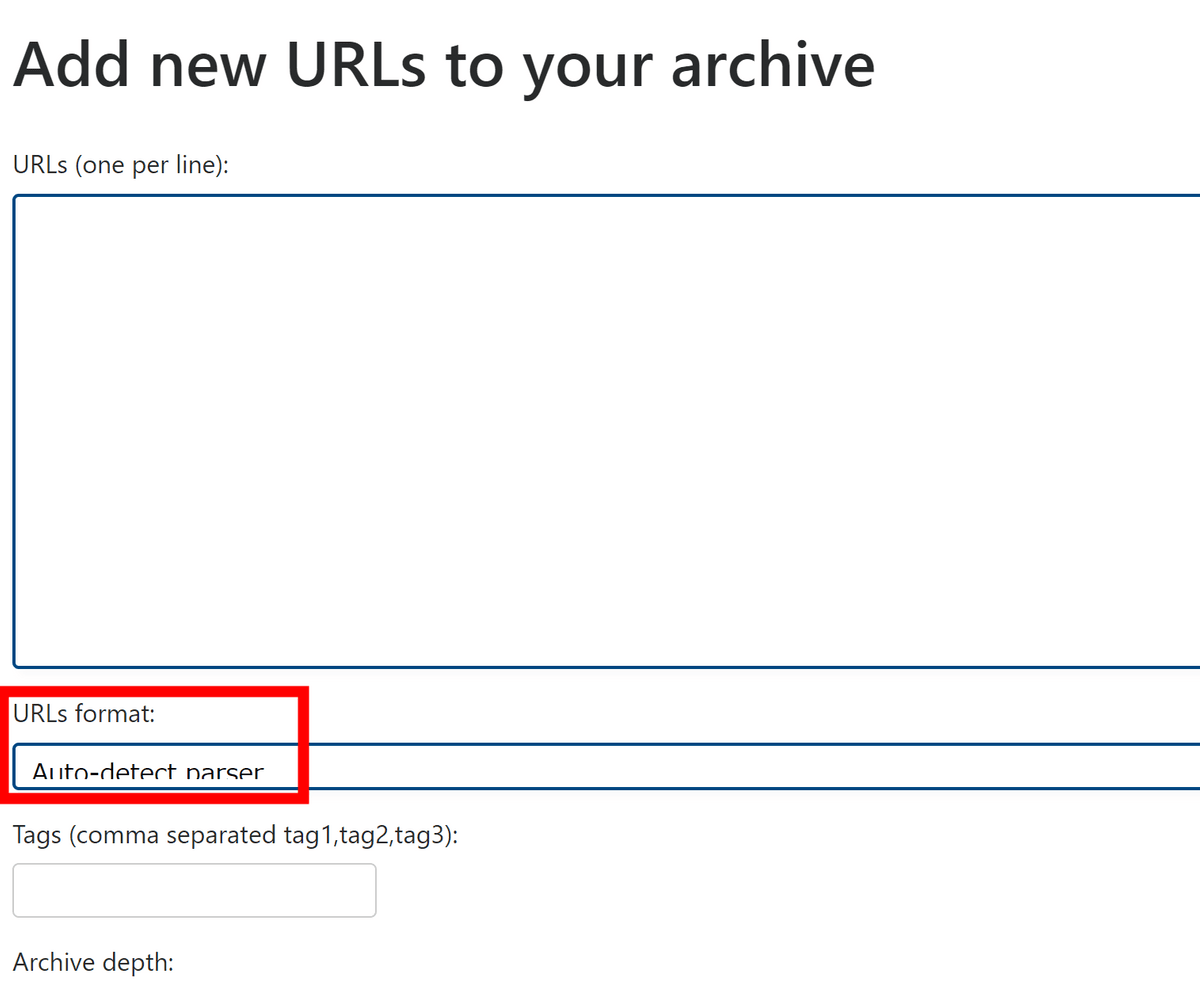
多数の選択肢が用意されていますが、どの形式で入力する場合でも基本的にURLs format欄では「Auto-detect parser(自動選択)」を選択しておけば大丈夫。
それぞれのサービスからデータをエクスポートする方法がArchiveBoxのドキュメントにまとめられていました。エクスポートしたデータをURLs欄に貼り付ければOKというわけです。
・Pocket
・Pinboard
・Instapaper
・Reddit Saved Posts
・Shaarli
・Unmark.it
・Wallabag
・Chrome Bookmarks
・Firefox Bookmarks
・Safari Bookmarks
・Opera Bookmarks
◆4:拡張機能で閲覧したページを自動指定
まだ開発中の機能ではあるものの、Google Chrome版とFirefox版の拡張機能が用意されています。今回はChrome版の拡張機能を実際に使ってみます。Google Chrome版の拡張機能のページにアクセスし、「Chromeに追加」をクリック。
権限を確認して「拡張機能を追加」をクリックします。
ブラウザの右上にArchiveBoxのマークが追加されるので、クリックして「Config」を開いて初期設定を行います。「Archive Mode」では「設定したサイトだけ保存するAllowlist形式」と「設定したサイト以外を保存するBlocklist形式」が選択可能。「ArchiveBox Base URL」にはArchiveBoxのサーバーを設置したURLを入力します。また、拡張機能経由で保存したサイトにタグを付けたい場合は「Tags」欄で設定すればOK。設定できたら、下部の入力欄にリストに追加したいドメインを入力して「+」ボタンをクリック。
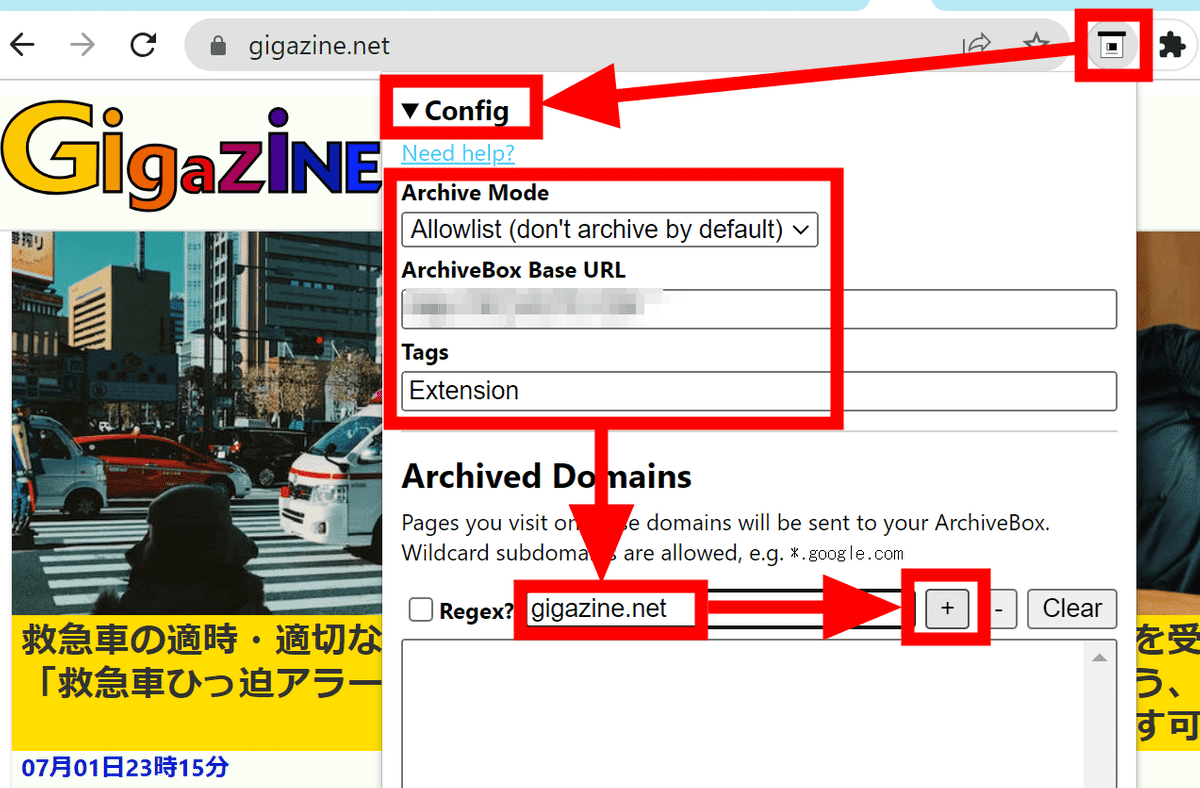
ドメイン全体の指定のほか、個別ページを正規表現ベースで指定することも可能です。
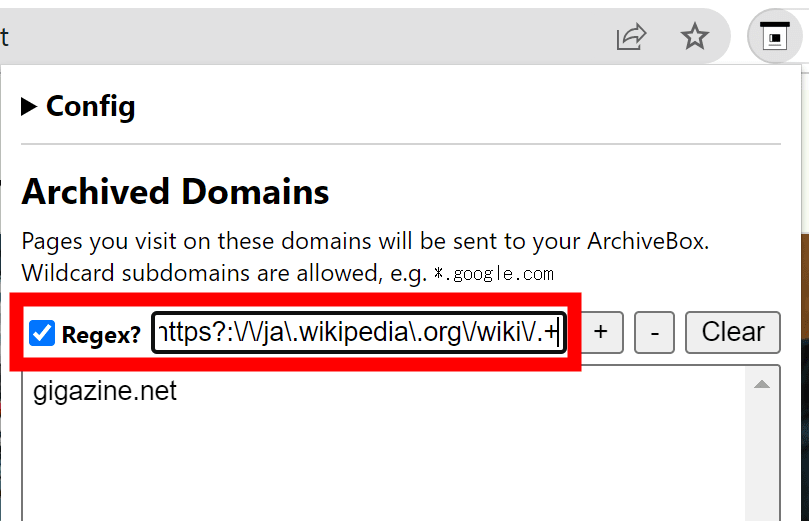
拡張機能の設定部分では特に認証の設定がありませんが、ページを保存するにはもちろん認証が必要です。拡張機能をインストールしたブラウザでArchiveBoxにログインすると自動でその認証情報を読み取って利用するとのこと。
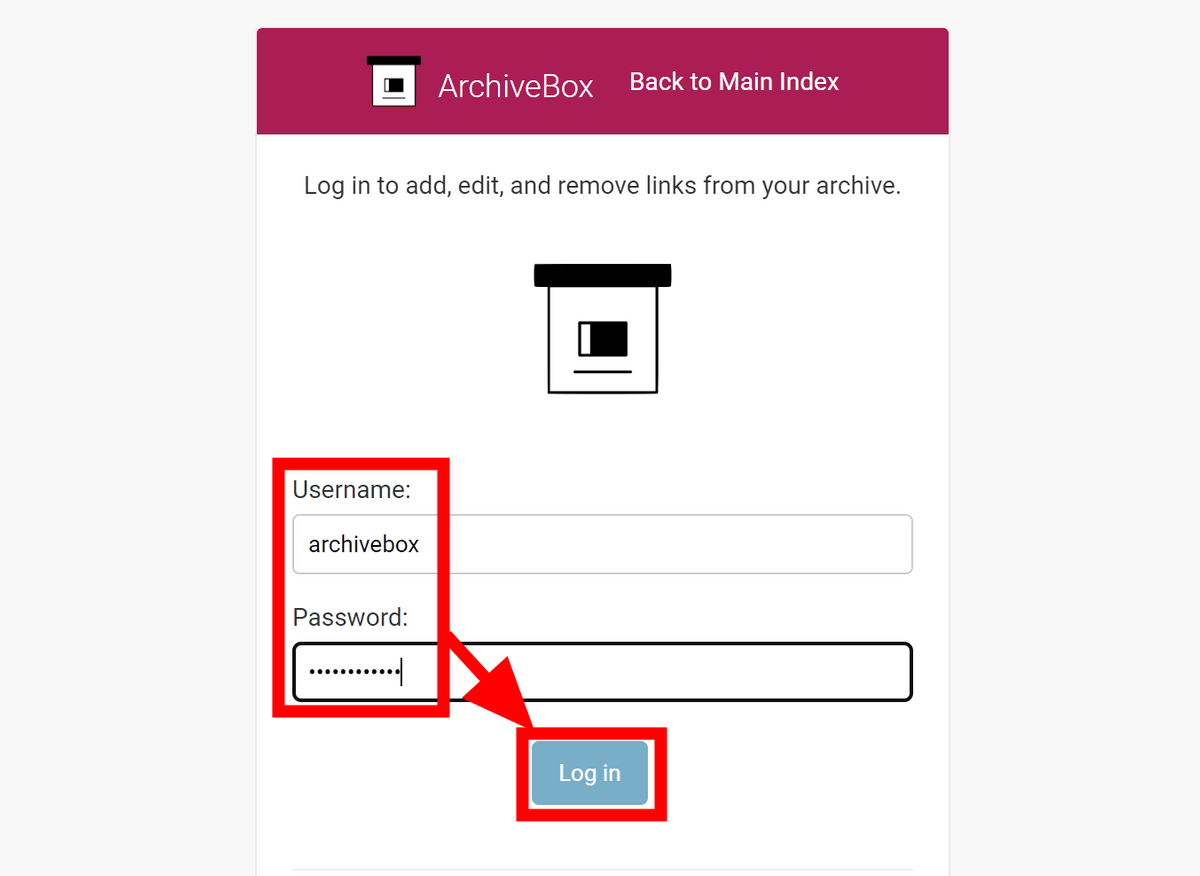
設定が完了したら、適当にいくつかのページを閲覧してみます。
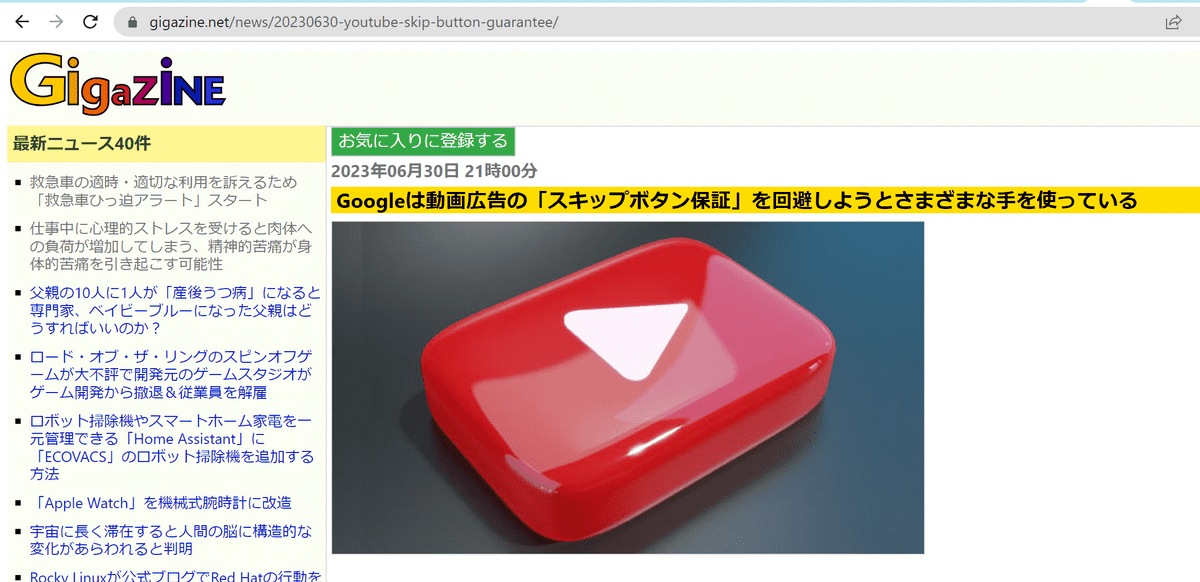
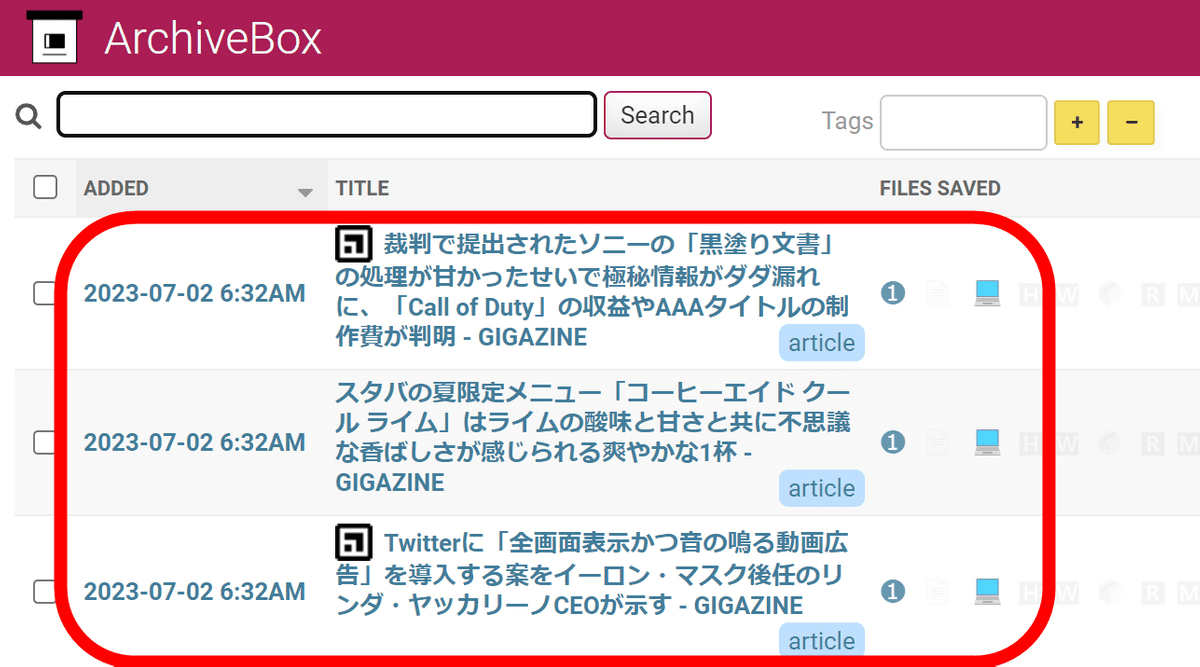
ArchiveBoxを開くと、閲覧したページが次々と保存されているのが確認できました。
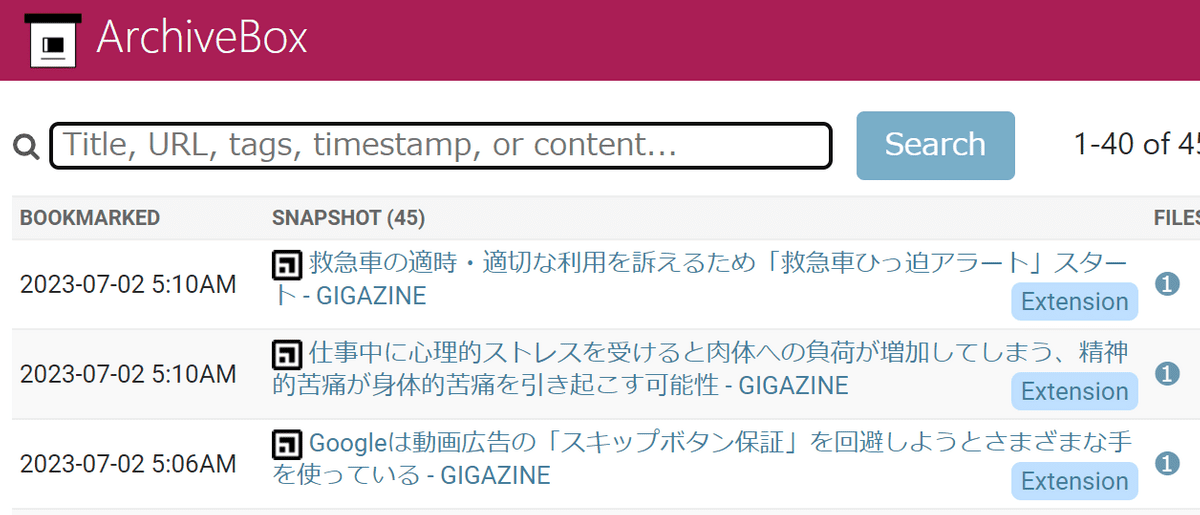
◆サーバーに保存されるデータはこんな感じ
GIGAZINEのほか、GoogleとYouTubeの保存データを通してどんなデータが保存されているのかを確認してみます。GIGAZINEのスナップショットをクリック。
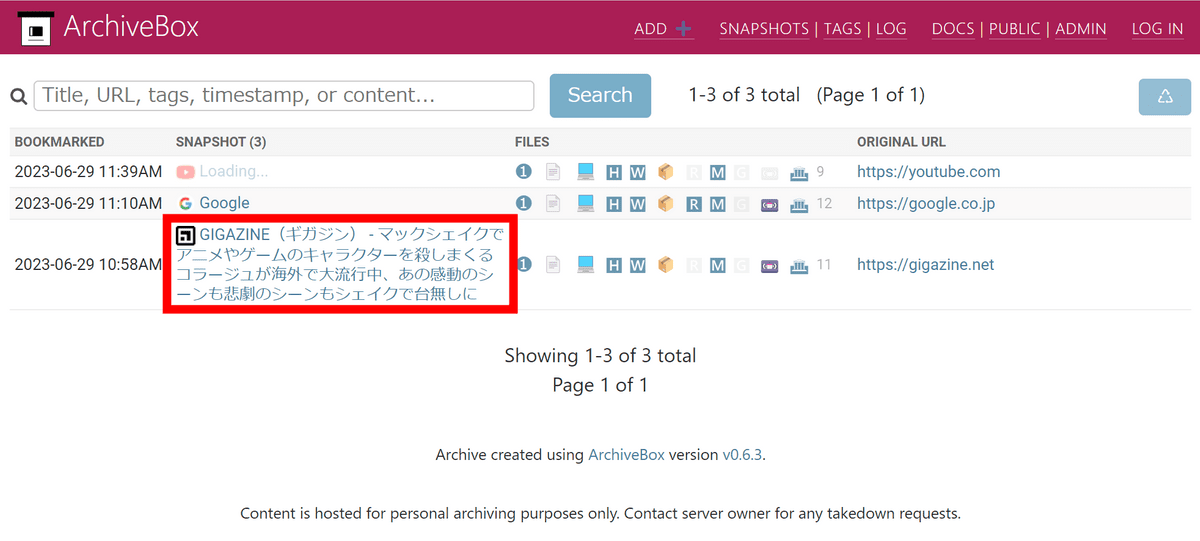
するとデータの保存形式が一覧できます。
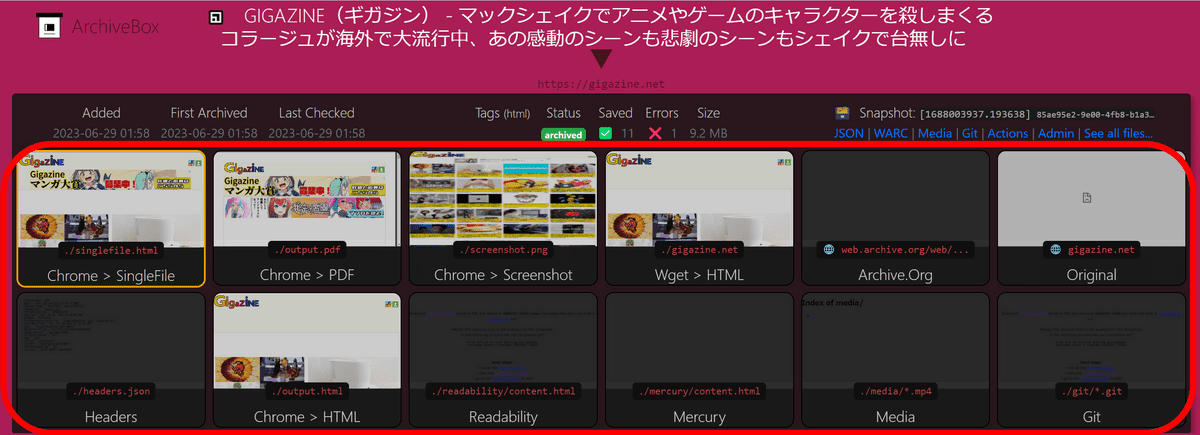
それぞれの形式の詳細は下記の通り。
・Chrome - SingleFile
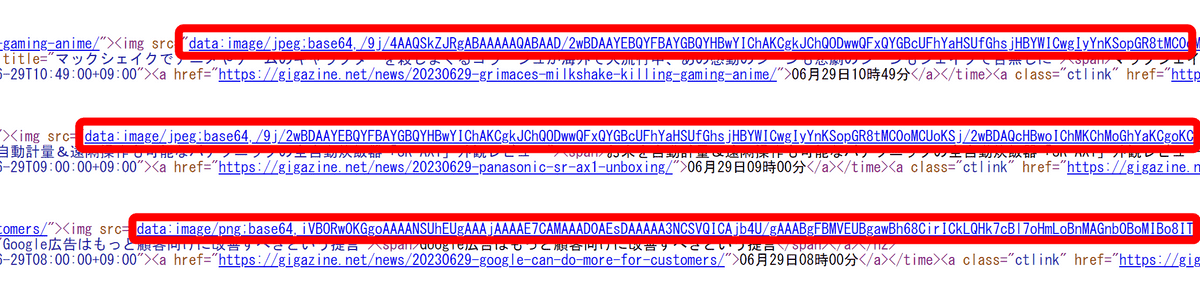
「SingleFile」の名前の通り、1つのファイルに全てのデータが保存されています。
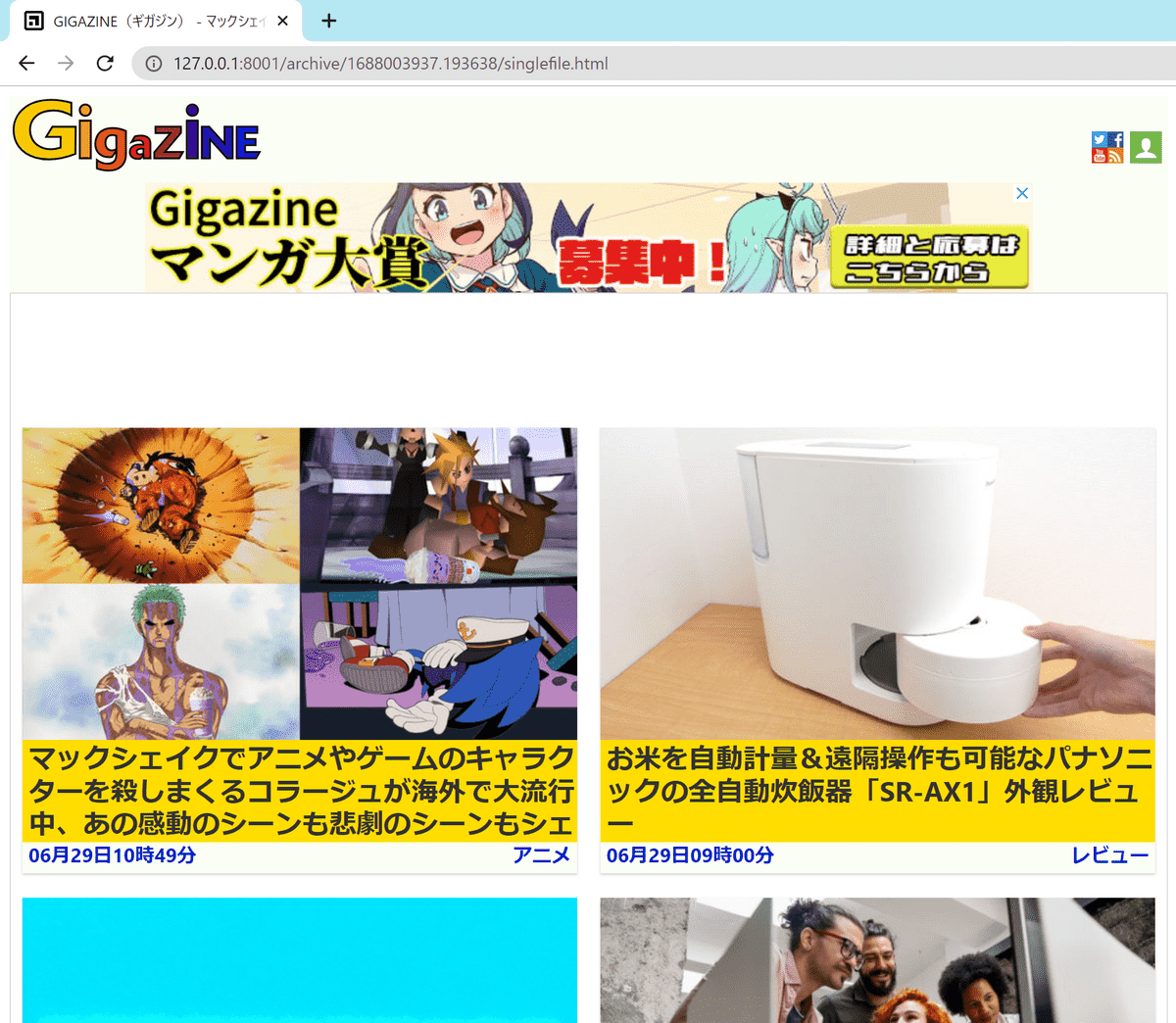
もともとはリンクだった画像はbase64でエンコードされた状態で埋め込んでありました。
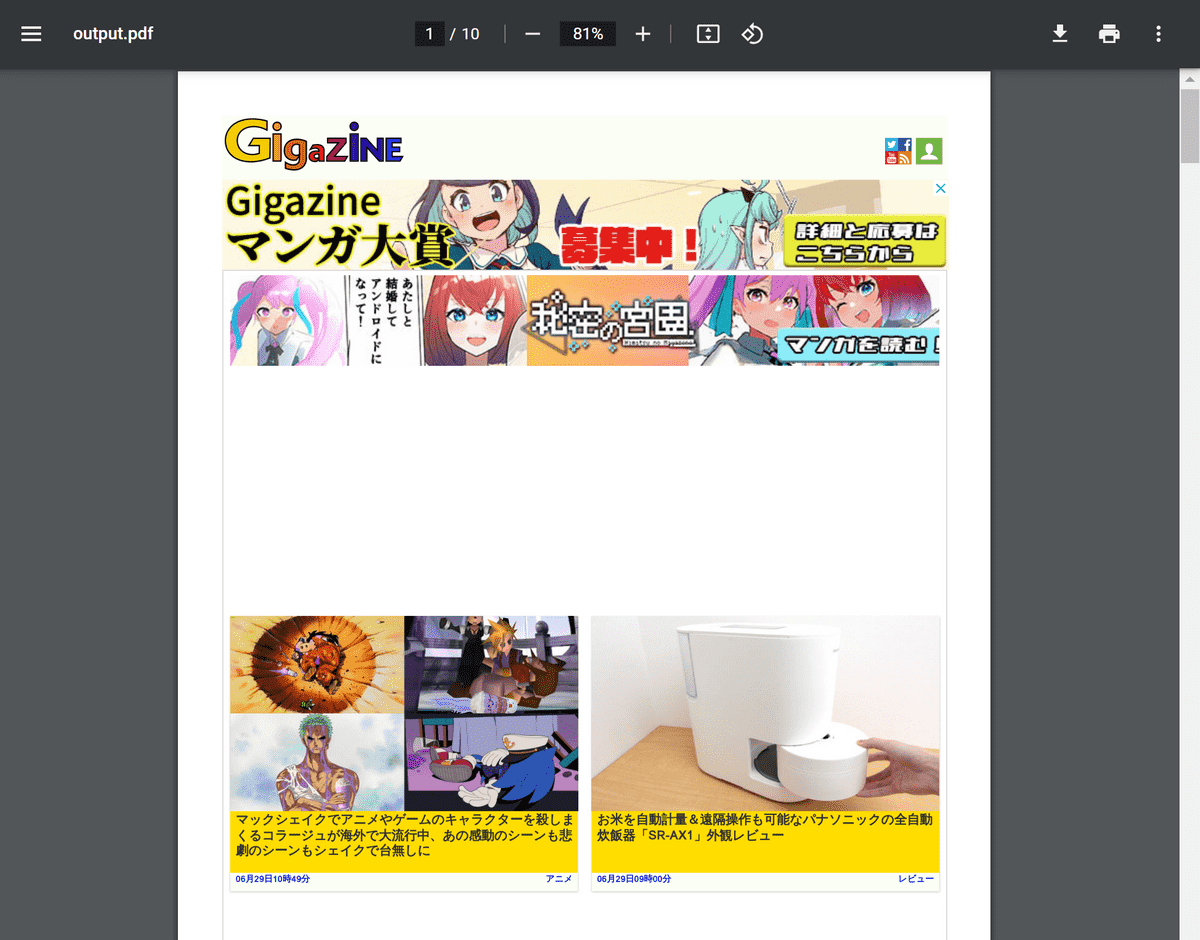
・Chrome - PDF
Chromeでページをレンダリングした結果がPDF形式で保存されます。
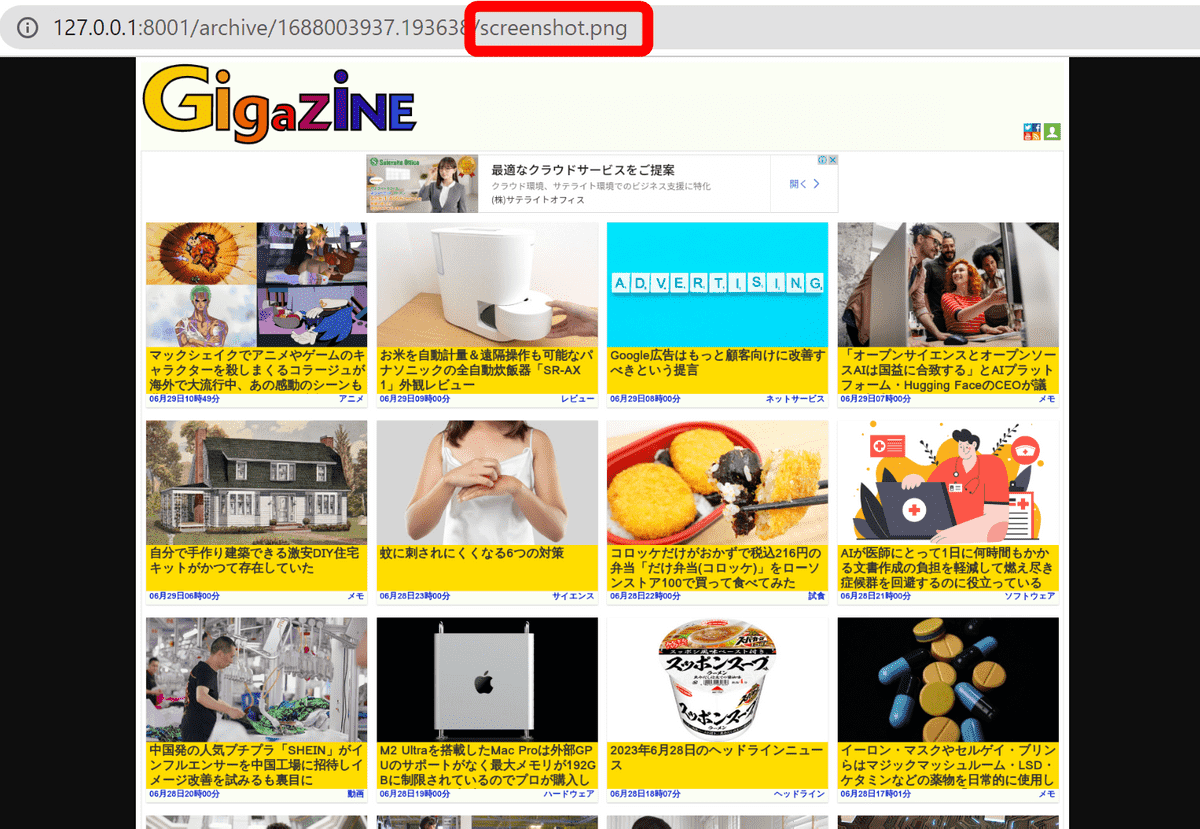
・Chrome - Screenshot
Chromeでレンダリングした結果が画像として保存されます。
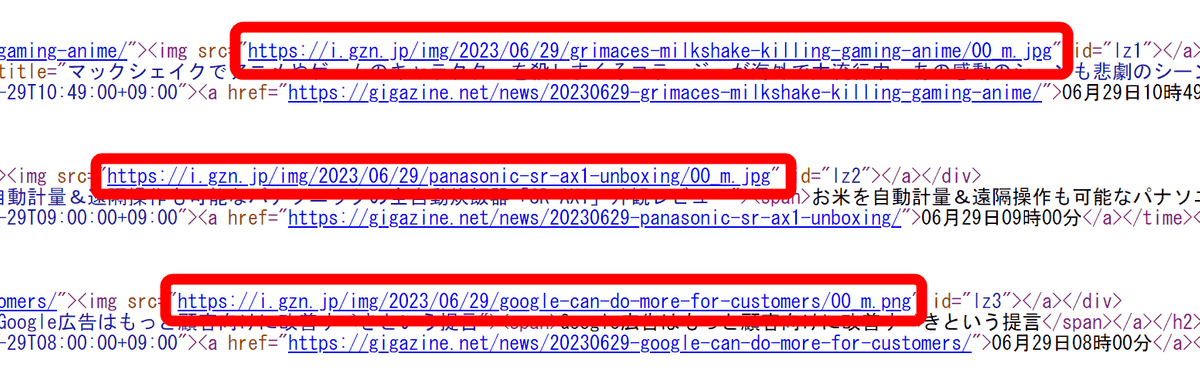
・Wget
HTMLファイルをダウンロードしてそのまま保存します。もちろん画像は外部リンクのままとなっており、元の画像が削除された場合は表示できなくなります。
・Archive.Org
Wayback Machineの当該サイトへのリンクとなっています。
・Original
元のサイトへのリンクです。今回の場合であればhttps://gigazine.netへのリンク。
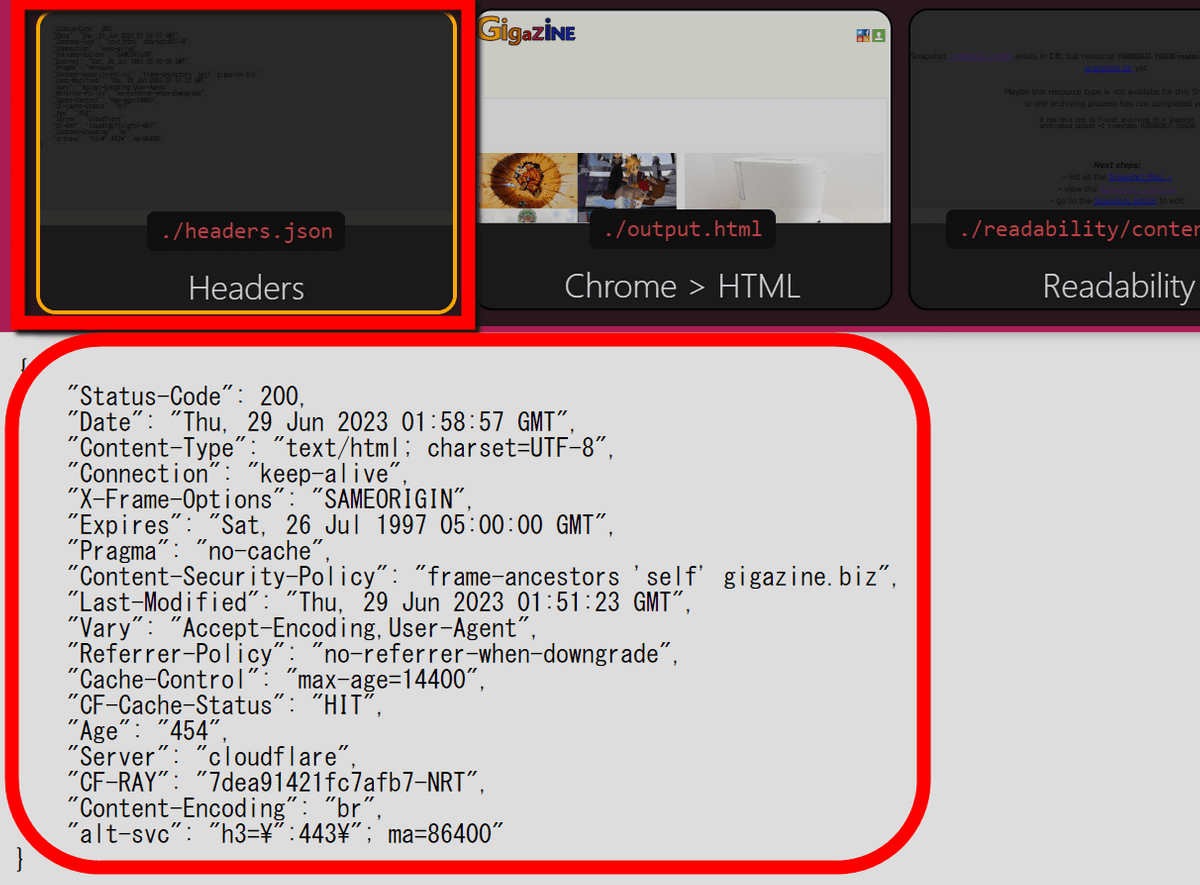
・Headers
レスポンスの際のヘッダ情報が保存されています。
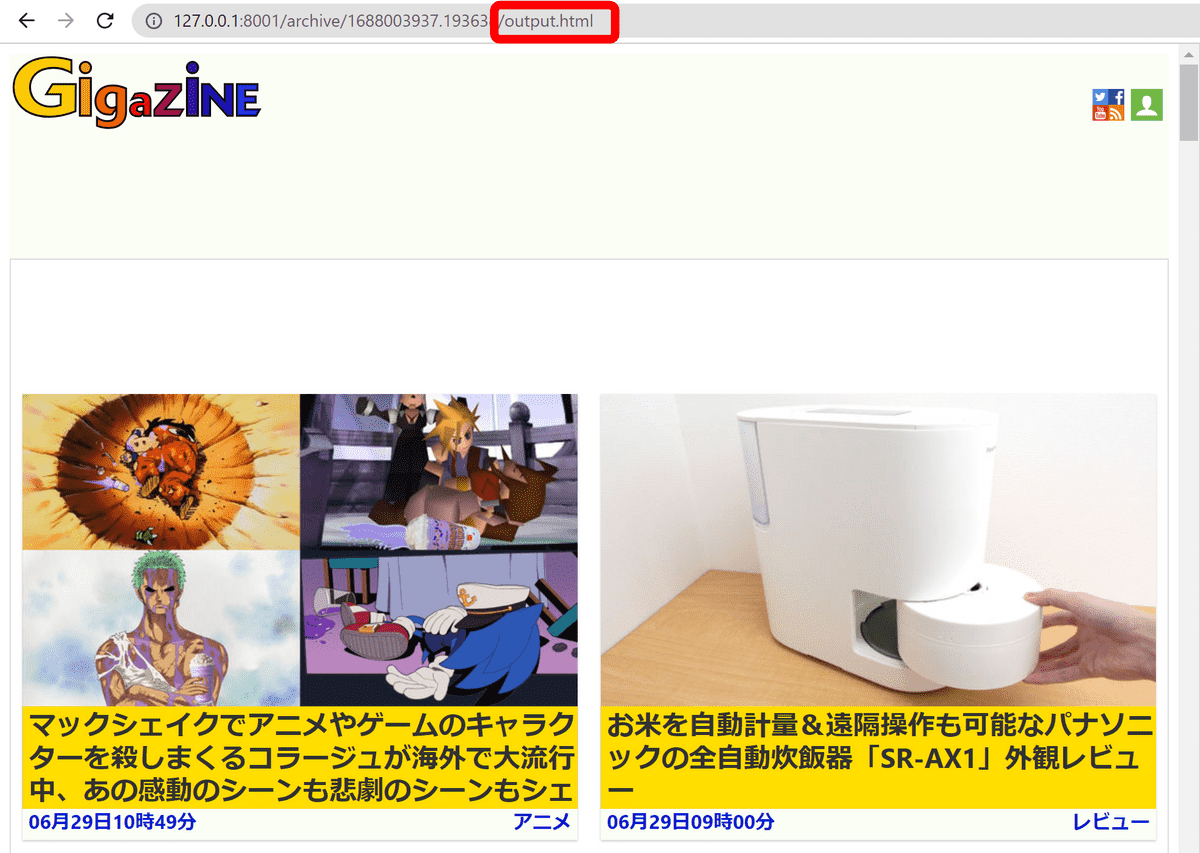
・Chrome > HTML
Chrome経由で保存したHTMLファイルを「output.html」という名前で保存します。
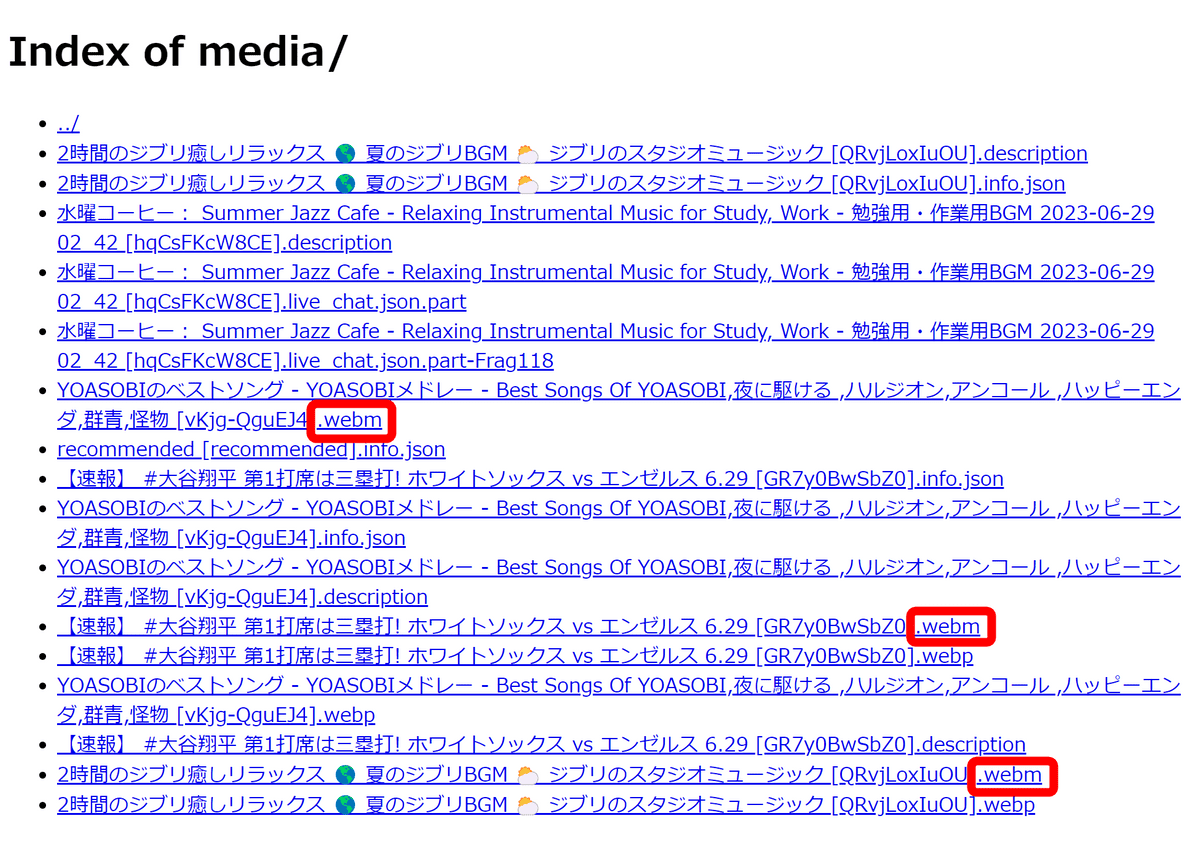
・Media
ページに埋め込まれているメディアが保存されています。GIGAZINEやGoogleでは何のデータも保存されていませんでしたが、YouTubeのデータを確認してみると下図のようになりました。このうち、「webm」形式のファイルではYouTubeの動画データが完全な形式で保存されている模様。
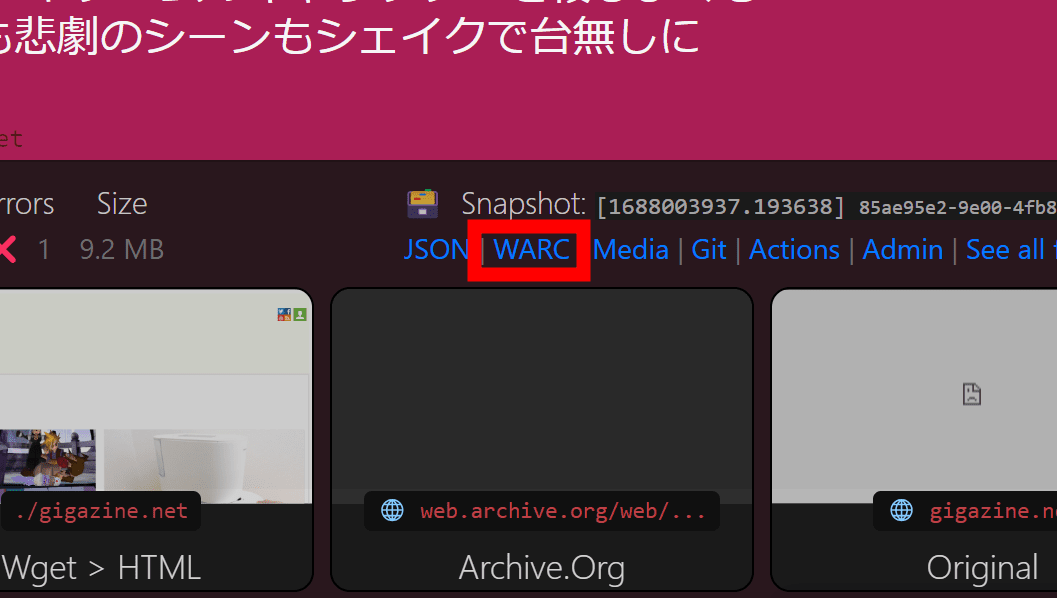
こうした項目の他に、右上には「WARC」という欄も存在しています。このリンクを通してウェブページ保存用のフォーマットである「WARC」形式のファイルをダウンロード可能でした。
どんな形式でデータが保存されるのかをさらにじっくり確認したい場合は公式が用意しているデモを確認してみてください。
また、ArchiveBoxがデータを取得する際に内部で利用しているChromeのプロファイルを指定してChromeを起動し、サイトにログインすることで認証が必要なサイトのデータも保存可能とのこと。
無料ブログサービスの閉鎖などの原因によってウェブサイトは意外と簡単になくなってしまうものですが、ArchiveBoxのようにローカルにデータを保存できるツールを活用することでいざという時も焦らずにすみそうです。
・関連記事
ウェブ上の情報を記録・保存するインターネット・アーカイブが予期せぬ大量アクセスにより約2時間にわたりダウン - GIGAZINE
インターネットアーカイブが電子書籍の著作権を巡る大手出版社との著作権訴訟の一審で敗訴 - GIGAZINE
無料で読める140万冊の本をインターネットアーカイブが公開 - GIGAZINE
インターネット上のあらゆる情報を保存するインターネットアーカイブは個人収蔵レベルの雑誌まで引き取って電子化している - GIGAZINE
新型コロナウイルスの影響で「インターネット・アーカイブ」の通信量が秒間60ギガビットに到達、月間通信量は20ペタバイト以上 - GIGAZINE
・関連コンテンツ



in ソフトウェア, レビュー, ウェブアプリ, Posted by log1d_ts
You can read the machine translated English article I tried using 'ArchiveBox' which can be ….