I tried using 'ArchiveBox' which can be self-hosted with open source that can save pages and sites like web gyotaku and internet archives for free and fully automatic save from browser history, bookmarks, etc. Review

There are many services that save web page data at a specific point in time, such as
ArchiveBox/ArchiveBox: ???? Open source self-hosted web archiving. Takes URLs/browser history/bookmarks/Pocket/Pinboard/etc., saves HTML, JS, PDFs, media, and more...
https://github.com/ArchiveBox/ArchiveBox

There are two methods for setting up ArchiveBox, one using a package manager and the other using Docker, but since we will use Docker this time, install Docker using the method that suits your environment from the link below.
Install Docker Engine | Docker Documentation
https://docs.docker.com/engine/install/
Since I am using Debian this time, I entered the following command.
[code] sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
'deb [arch='$(dpkg --print-architecture)' signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/debian \
'$(. /etc/os-release && echo '$VERSION_CODENAME')' stable' | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin[/code]
Once Docker is installed, run the code below to set it up.
[code]docker run -v $PWD/data:/data -it archivebox/archivebox init --setup[/code]
During setup, you will be asked to enter the administrative user's 'user name', 'e-mail address', 'password', and 'password (confirmation)', so enter them in order.
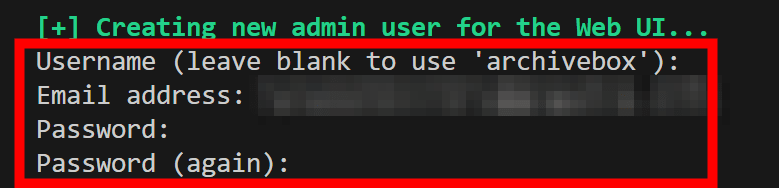
Then start the server with the following code.
[code]docker run -v $PWD/data:/data -p 80:8000 archivebox/archivebox server[/code]
After starting the server, when you access it with a browser, the screen shown below is displayed. Since nothing has been saved yet, the data is 0.
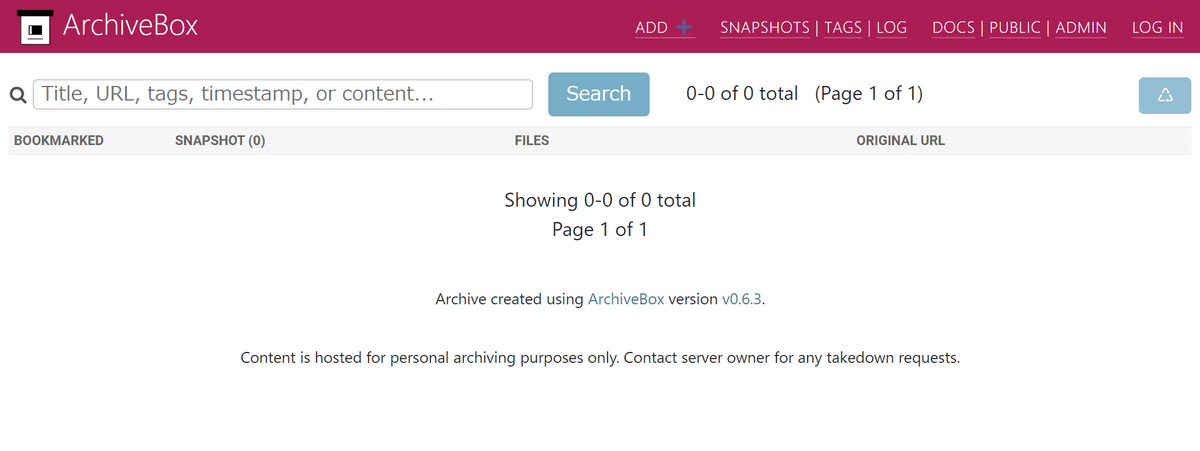
Now save the web page. ArchiveBox provides various storage methods as follows.
◆ 2: Enter the URL from the web application
◆ 3: Specify Pocket and browser bookmarks collectively
◆ 4: Automatically specify pages viewed with extensions
◆ 1: Specify the URL from the command line
To specify the URL you want to save on the command line, execute the following code. The address to be saved is specified in the 'https://gigazine.net' part.
[code]docker run -v $PWD/data:/data -it archivebox/archivebox add 'https://gigazine.net'[/code]
Saving has started. It looks like you are downloading various data.

In the case of GIGAZINE's top page, saving was completed in about 1 minute. Try 'https://google.co.jp' and 'https://youtube.com' in the same way.
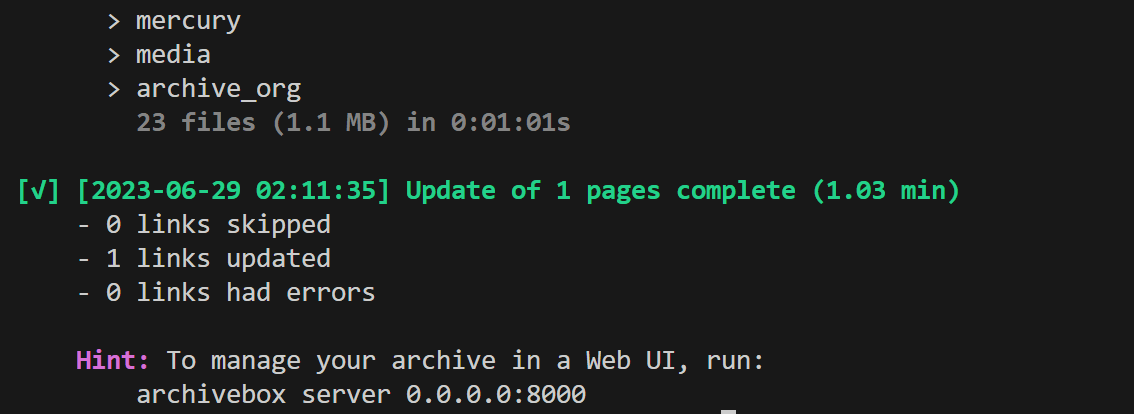
Regarding YouTube, it was not progressing at all even after 5 minutes from the start of saving, so enter 'Ctrl + C' once to interrupt.
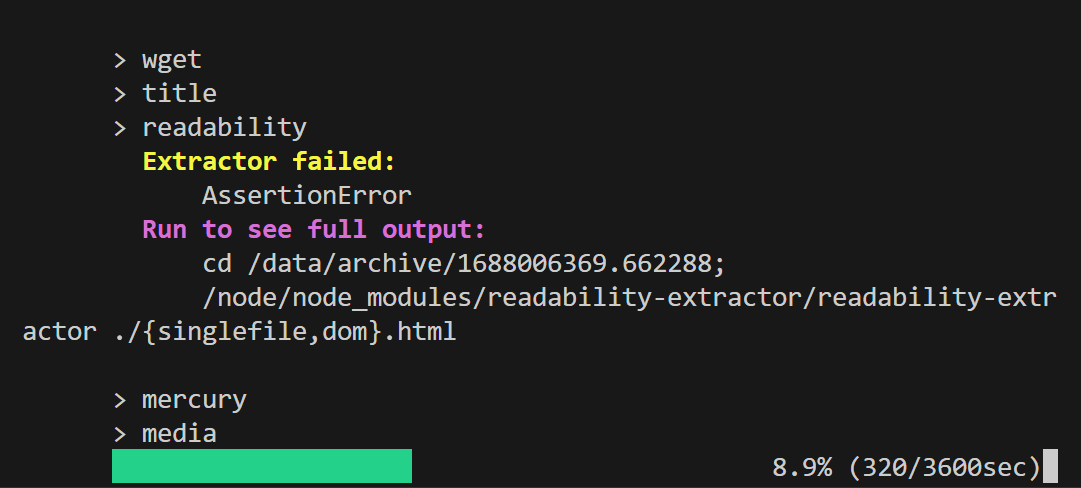
Even if it is interrupted, the data downloaded up to the point of interruption is saved, and it is possible to resume saving from the point of interruption at any time by executing the code displayed at the time of interruption.
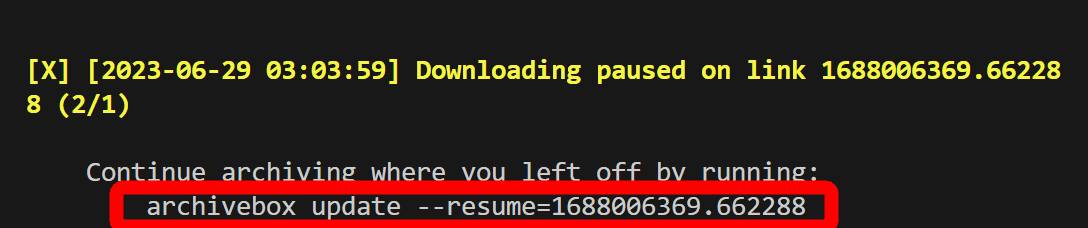
In addition to the method of saving data when executing a command, there is also a method
◆ 2: Enter the URL from the web application
Next, try saving a new web page via the GUI. Click 'ADD' on the top page of ArchiveBox.
Log in with the username and password you set during setup.
Click 'ADD' again.
Then you will see a screen where you can enter the URL as shown below.
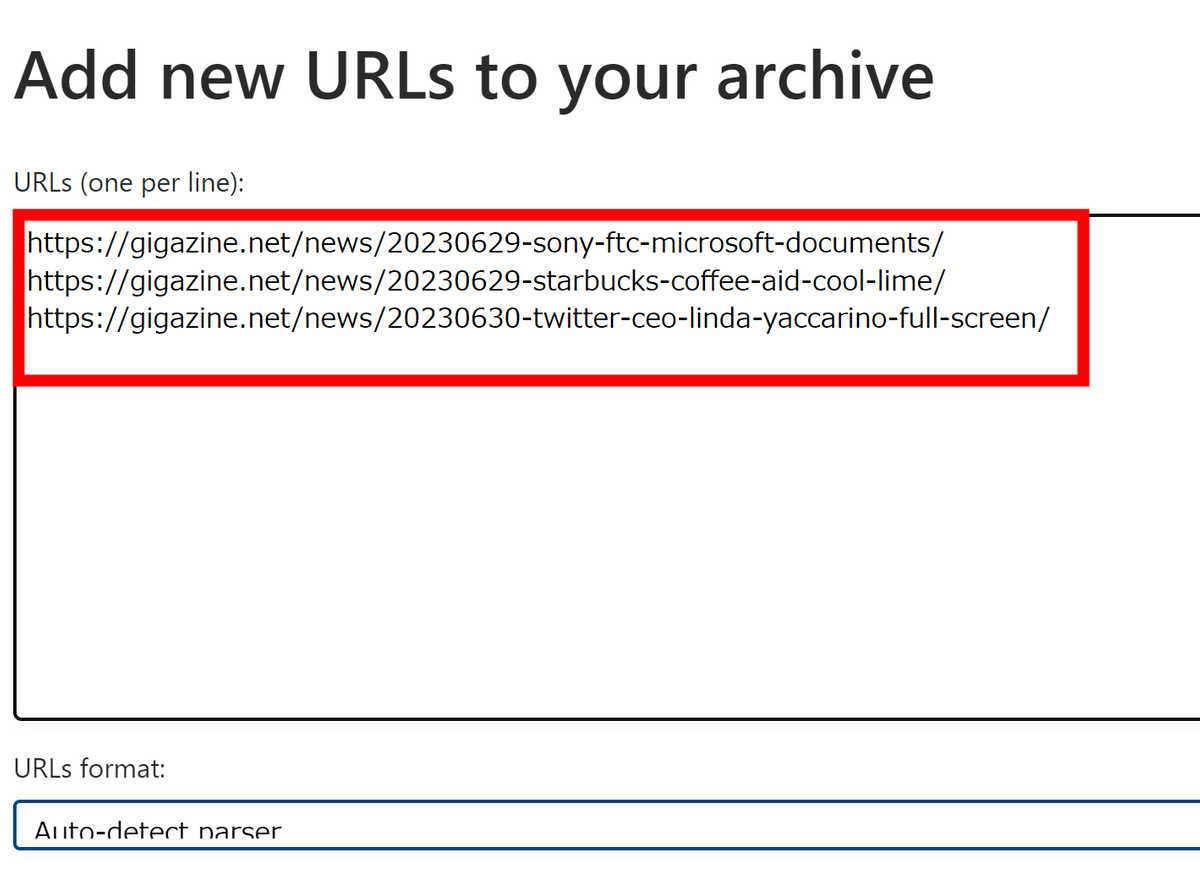
Select tags, storage depth, and in which format to save and click 'Add URLs and archive'. As for format selection, if nothing is selected, all formats will be saved. Note that if you specify only a specific format, if you do not select 'title', the title will be displayed as 'pending' long after the data has been saved.

The screen says 'Adding URL'. Click Log.
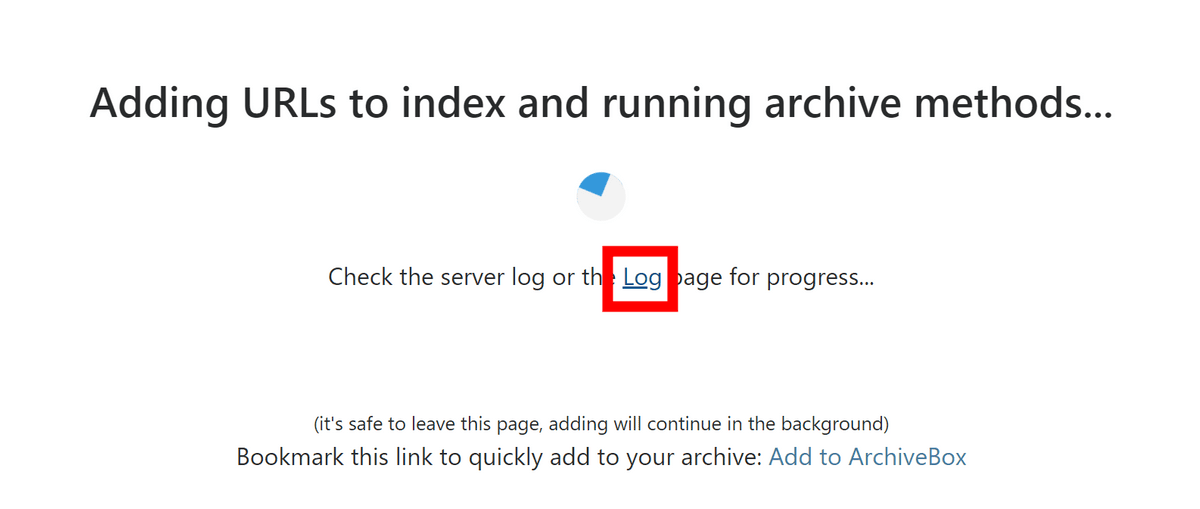
On the Log screen, you can see how the data of each article is processed.
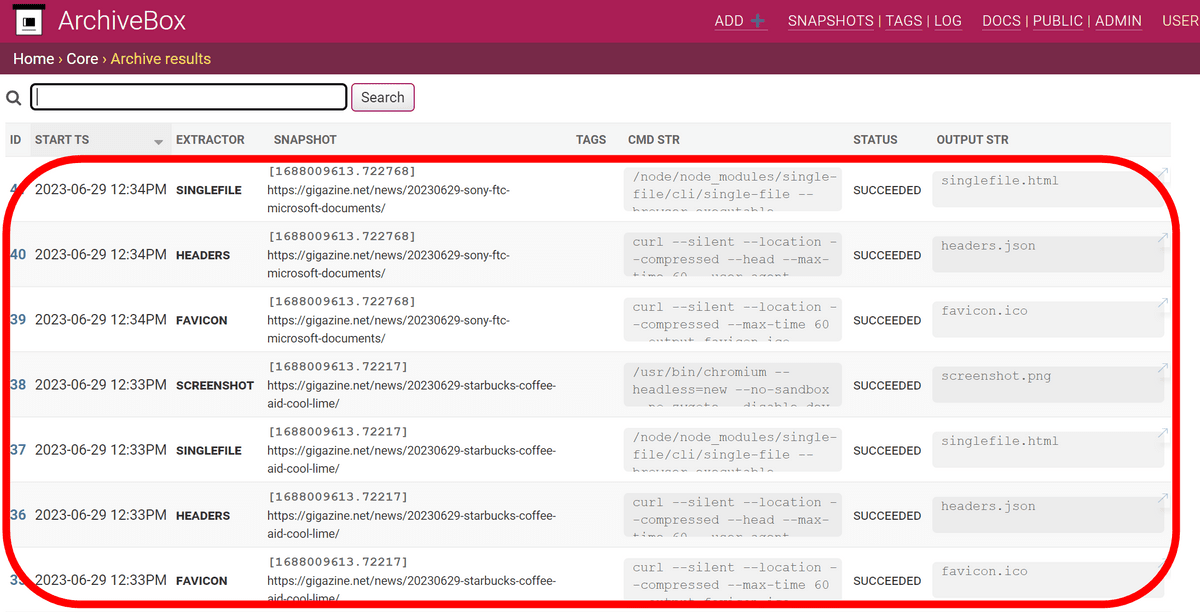
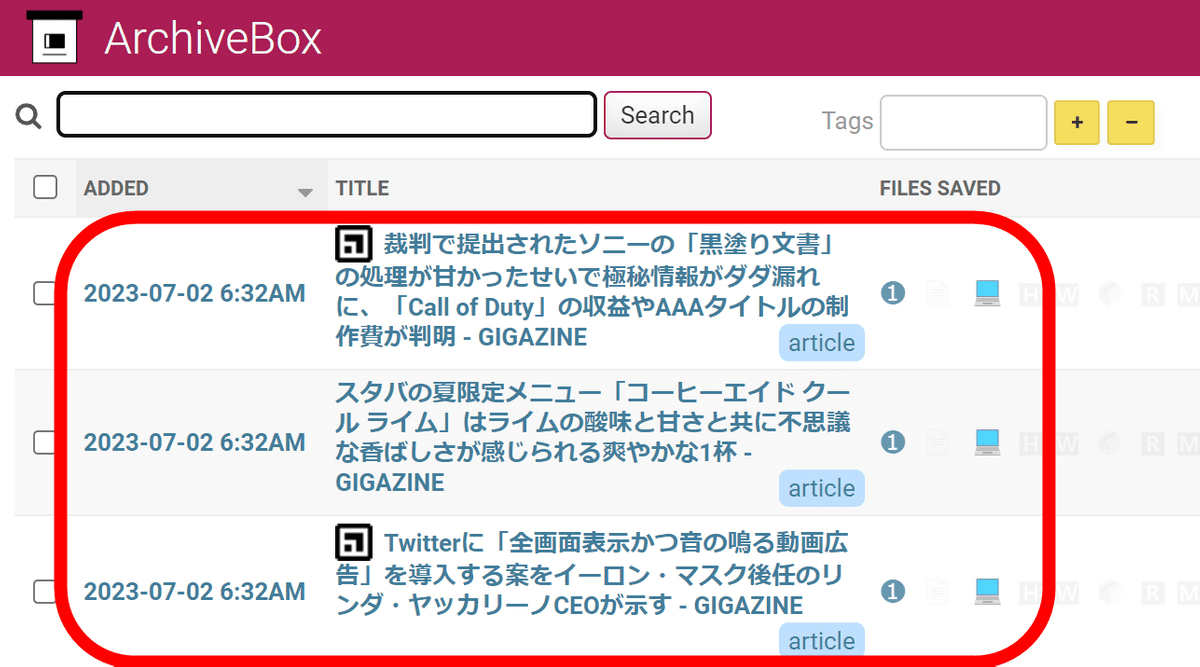
After waiting for a while and returning to the top page, you can see that the data has been added.
◆ 3: Specify Pocket and browser bookmarks collectively
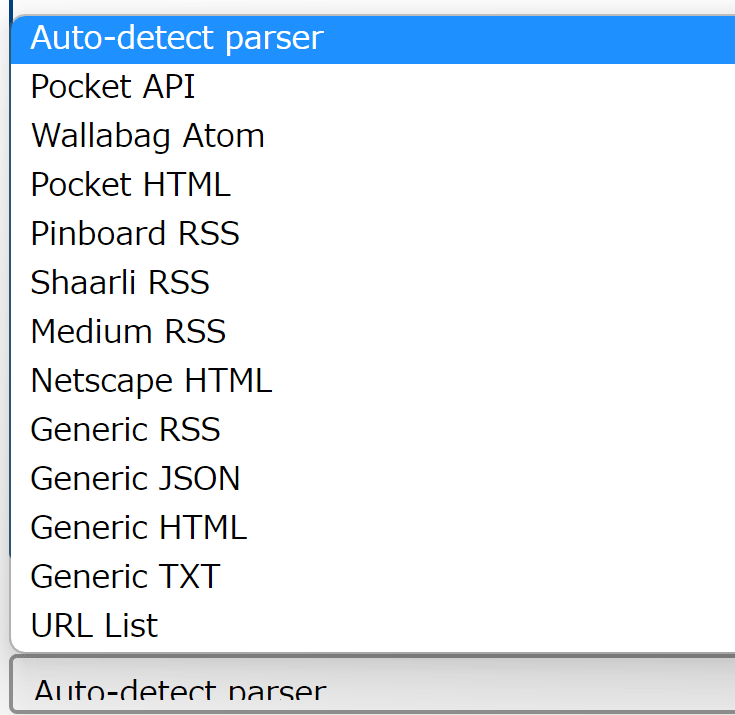
When adding URLs from a web application, you can simply line up the URLs line by line, or you can enter export data from Pocket or browser bookmarks and RSS. You can check the formats that can be entered in the 'URLs format' field on the URL addition page.
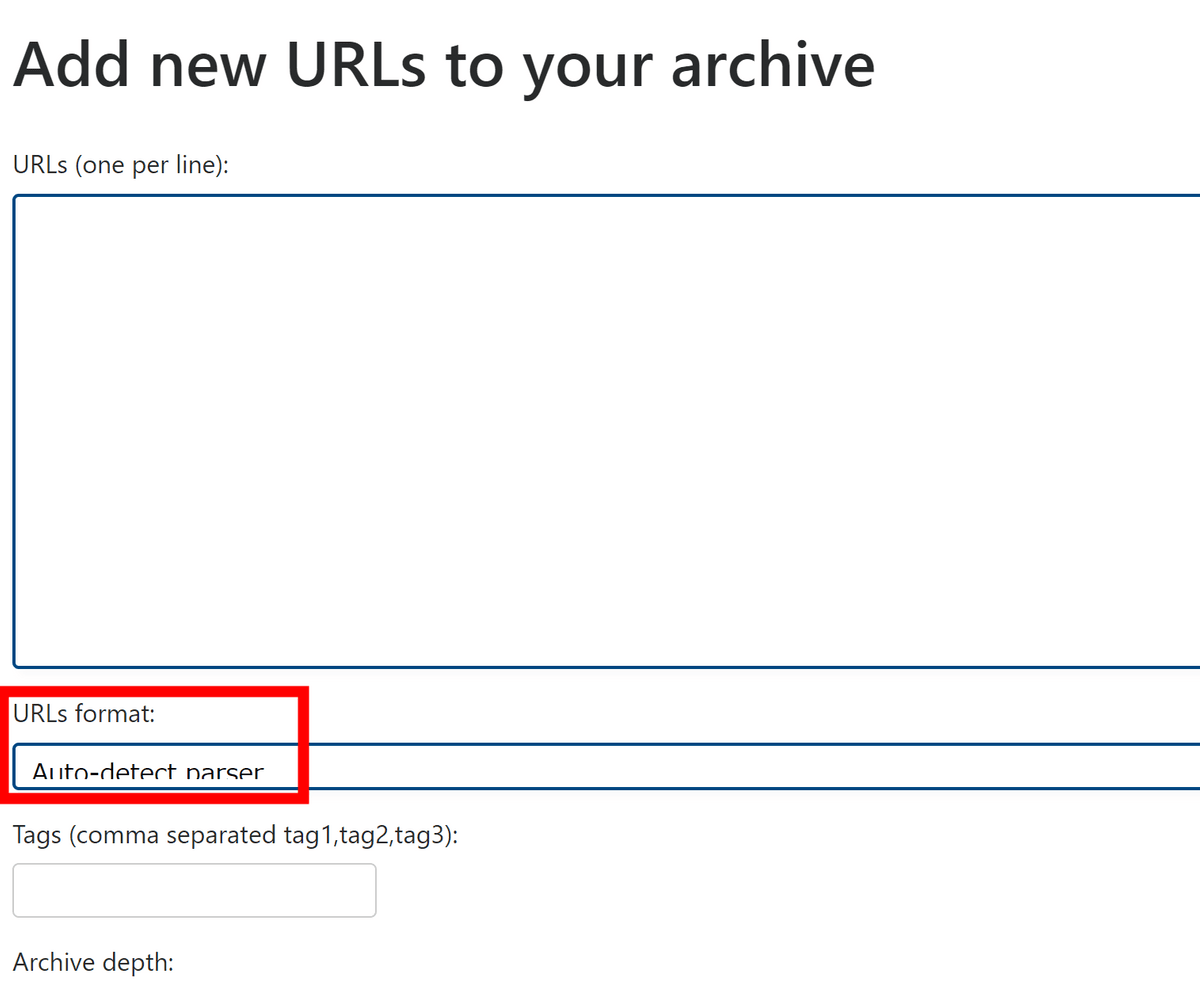
There are many options available, but basically it is okay to select 'Auto-detect parser' in the URLs format field when entering in any format.
The ArchiveBox documentation summarizes how to export data from each service. It is OK if you paste the exported data in the URLs field.
・
・Pinboard
・Instapaper
・Reddit Saved Posts
・Shaarli
・Unmark.it
・Wallabag
・Chrome Bookmarks
・Firefox Bookmarks
・Safari Bookmarks
・Opera Bookmarks
◆ 4: Automatically specify pages viewed with extensions
Although the feature is still in development , there are extensions available for Google Chrome and Firefox . This time I will actually use the Chrome version extension. Go to the Google Chrome version extension page and click 'Add to Chrome'.
Check permissions and click Add extension.
Since the ArchiveBox mark is added to the upper right of the browser, click it to open 'Config' and make the initial settings. In 'Archive Mode', 'Allowlist format to save only the set site' and 'Blocklist format to save other than the set site' can be selected. Enter the URL where the ArchiveBox server is installed in 'ArchiveBox Base URL'. Also, if you want to tag the site saved via the extension function, you can set it in the 'Tags' field. After setting, enter the domain you want to add to the list in the input field at the bottom and click the '+' button.
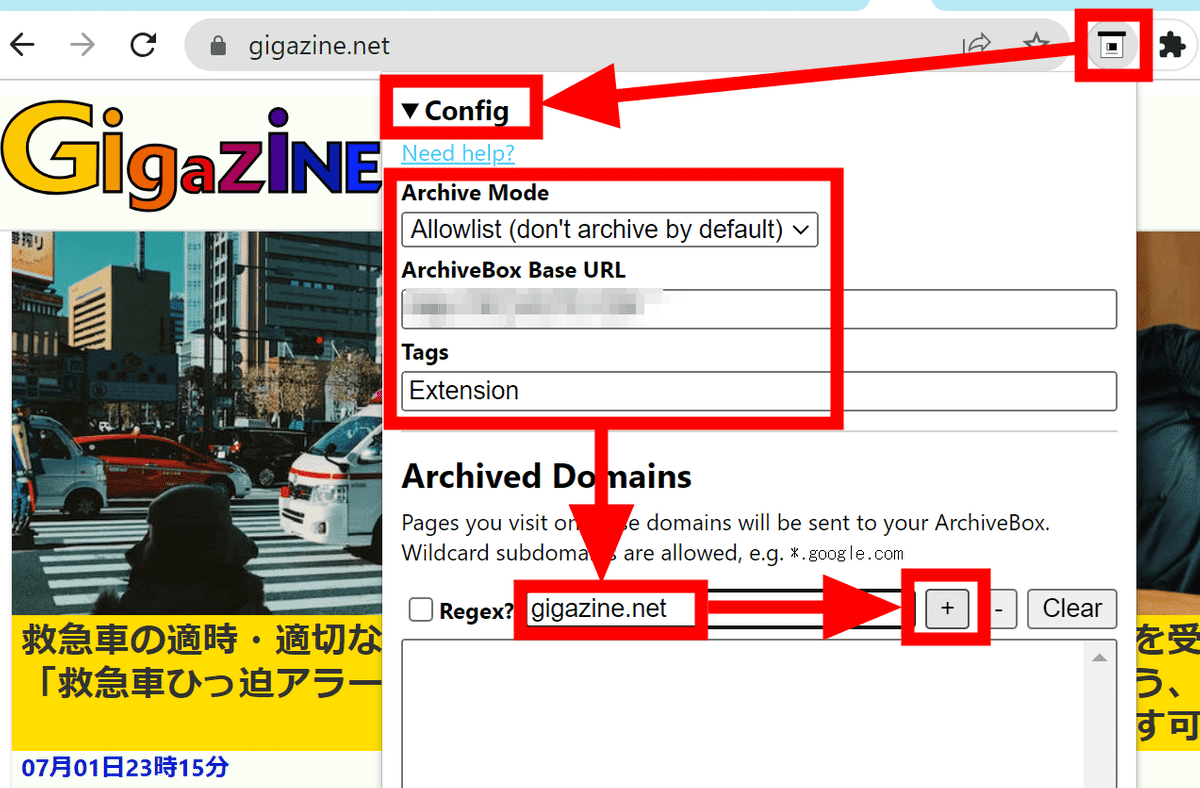
In addition to specifying the entire domain, it is also possible to specify individual pages based on regular expressions.
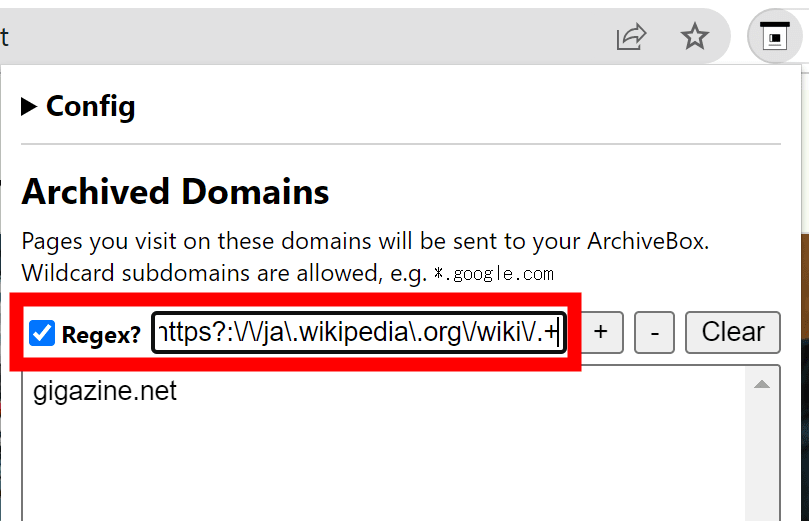
There is no specific authentication setting in the configuration part of the extension, but of course authentication is required to save the page. If you log in to ArchiveBox with a browser that has the extension installed, it will automatically read and use the authentication information.
After completing the settings, browse some pages at random.
When I opened ArchiveBox, I could see that the pages I visited were saved one after another.
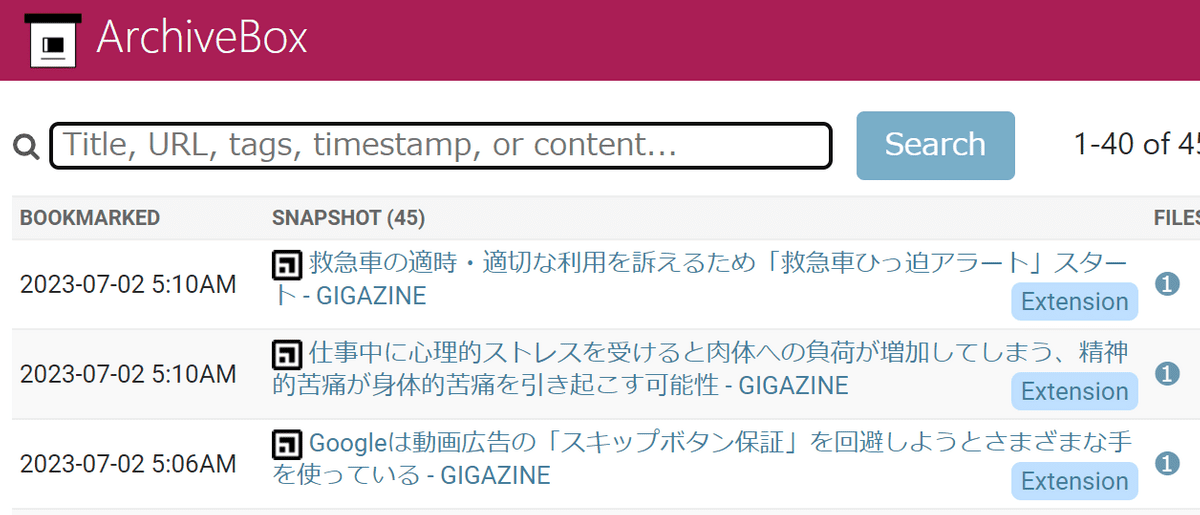
◆ The data saved on the server looks like this
In addition to GIGAZINE, let's check what kind of data is saved through the saved data of Google and YouTube. Click the snapshot of GIGAZINE.
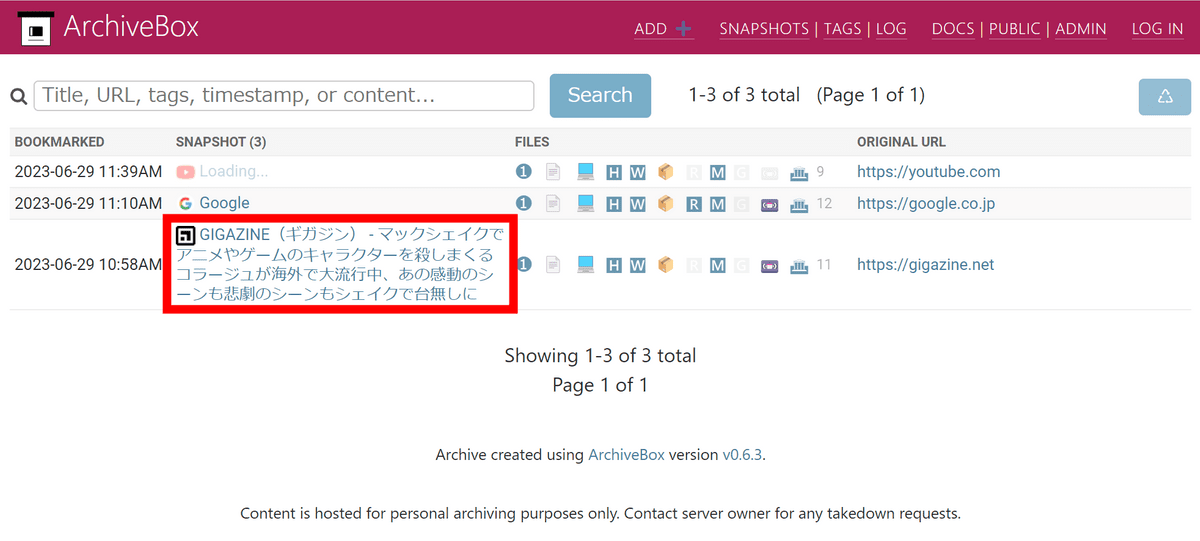
Then you can see a list of data save formats.
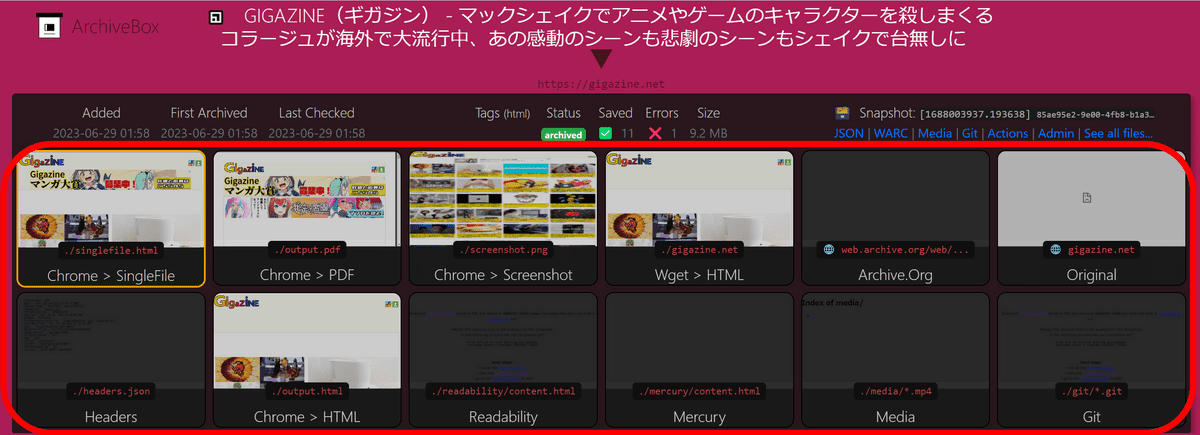
Details of each format are as follows.
・Chrome-Single File
As the name 'SingleFile' suggests, all data is saved in one file.
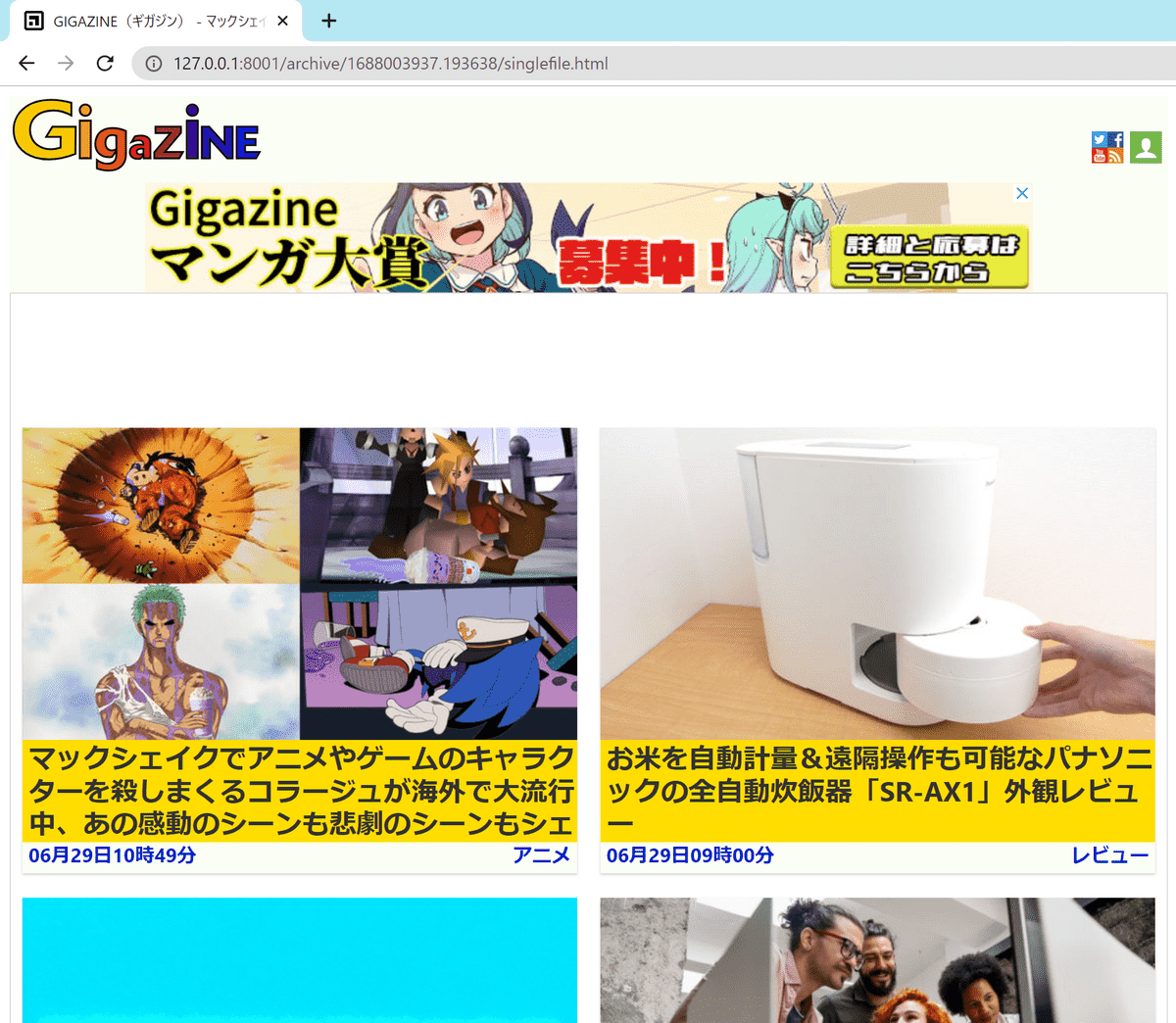
The image that was originally a link was embedded in the base64-encoded state.
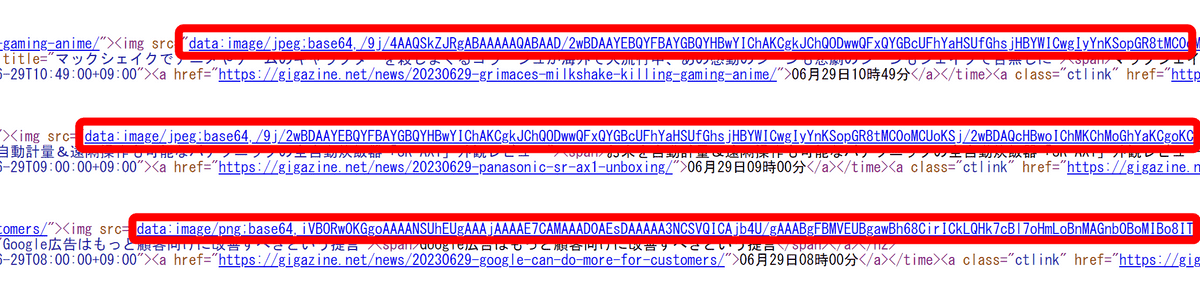
・Chrome-PDF
The result of rendering the page in Chrome is saved in PDF format.
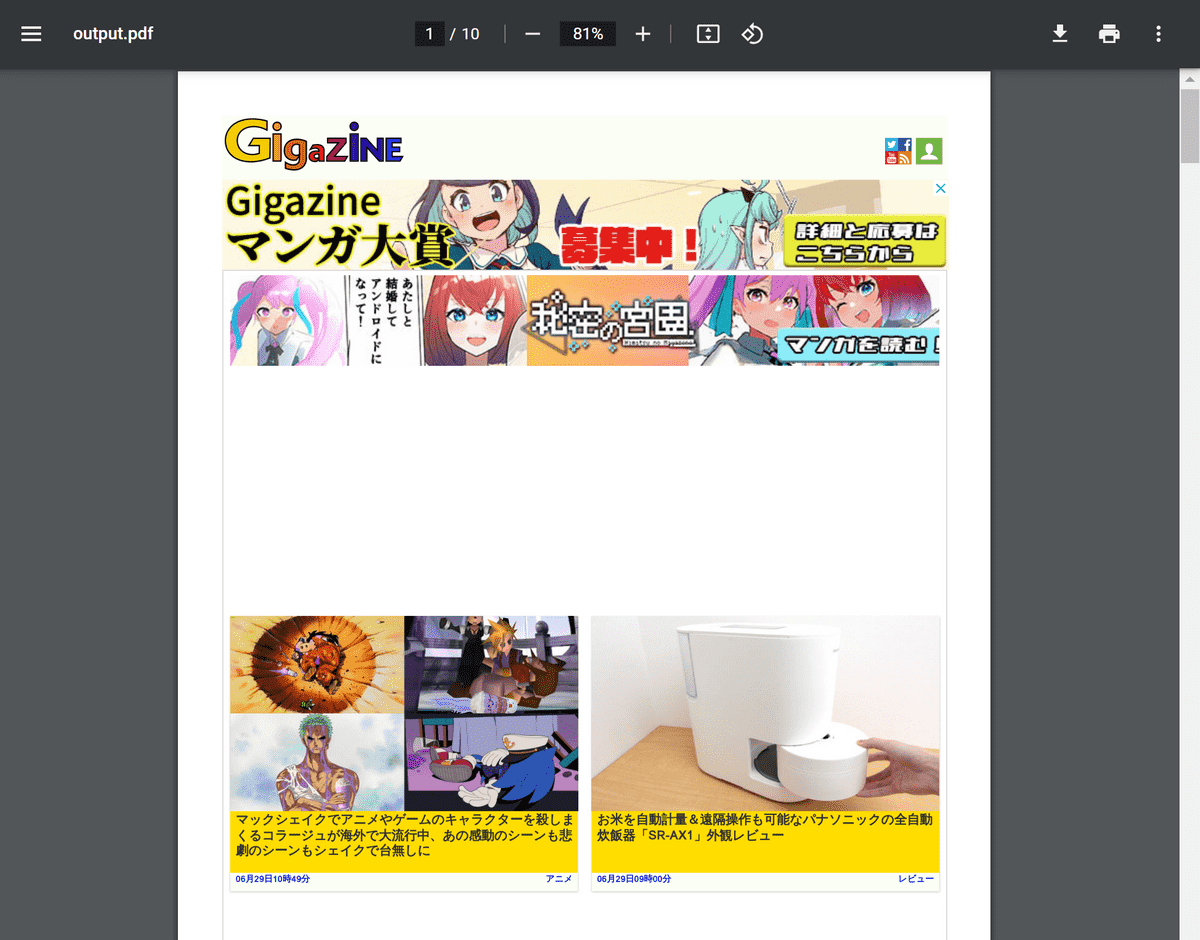
・Chrome-Screenshot
The result rendered by Chrome is saved as an image.
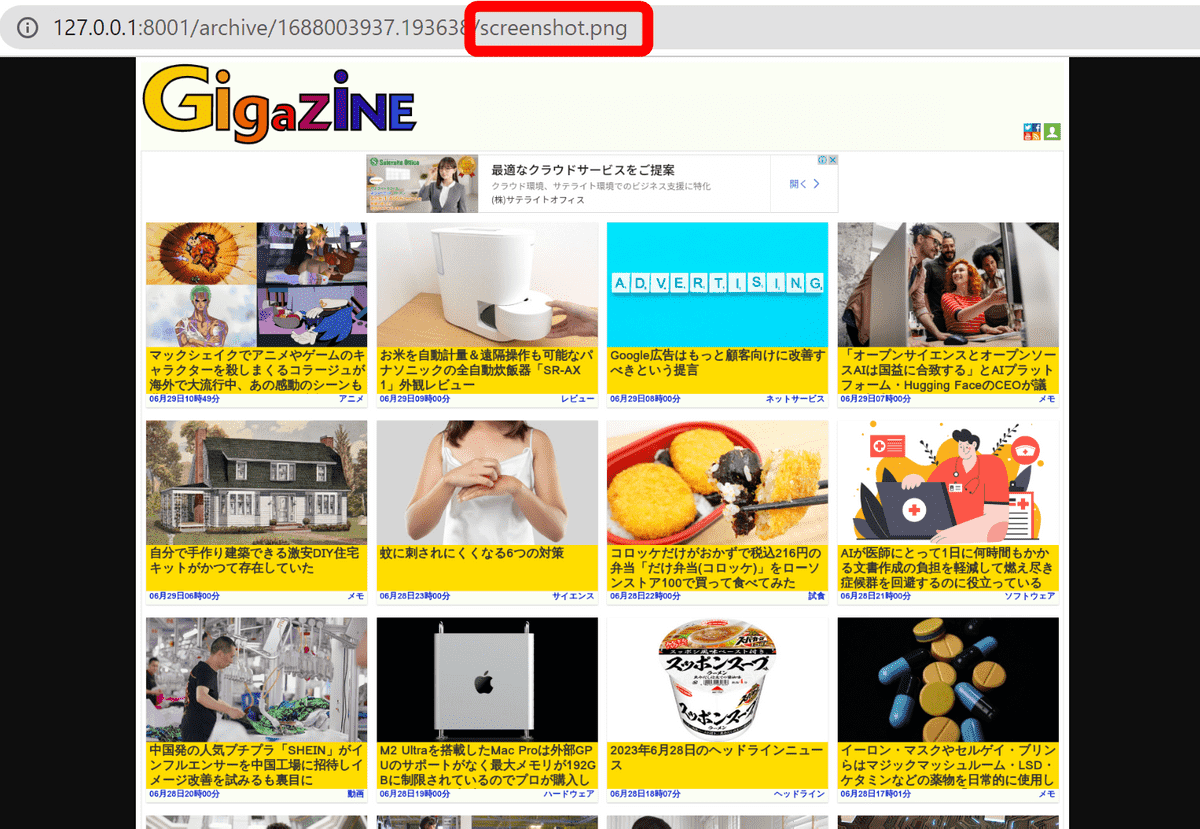
・Wget
Download the HTML file and save it as is. Of course, the image remains an external link and cannot be displayed if the original image is deleted.
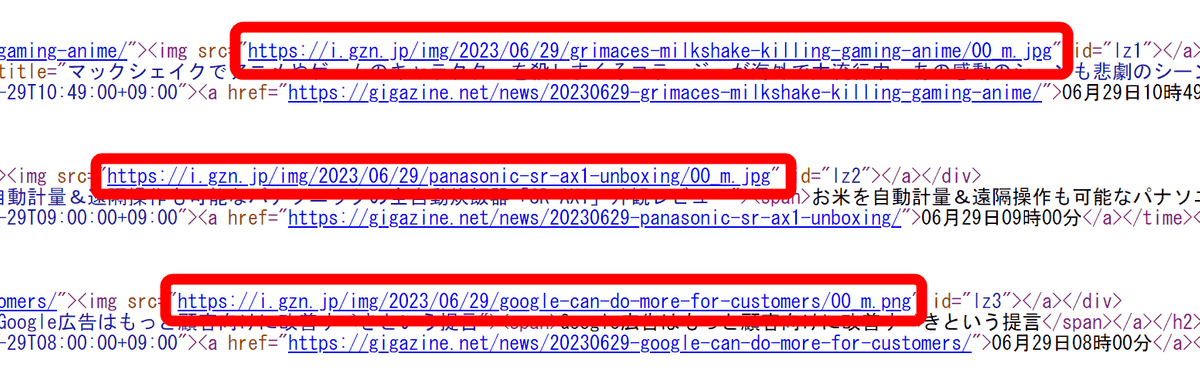
・Archive Org
It is a link to the site of Wayback Machine.
・Original
Link to original site. In this case, a link to https://gigazine.net.
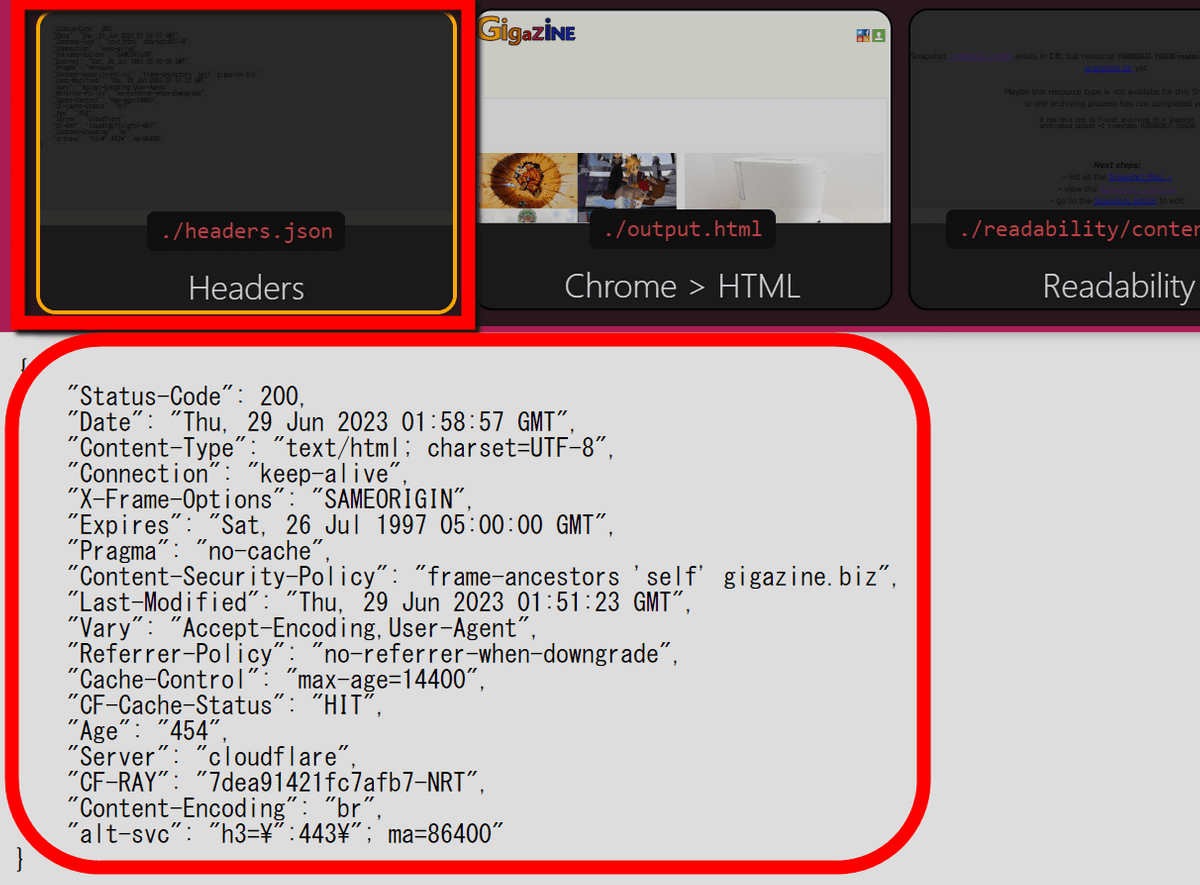
・Headers
It stores the header information of the response.
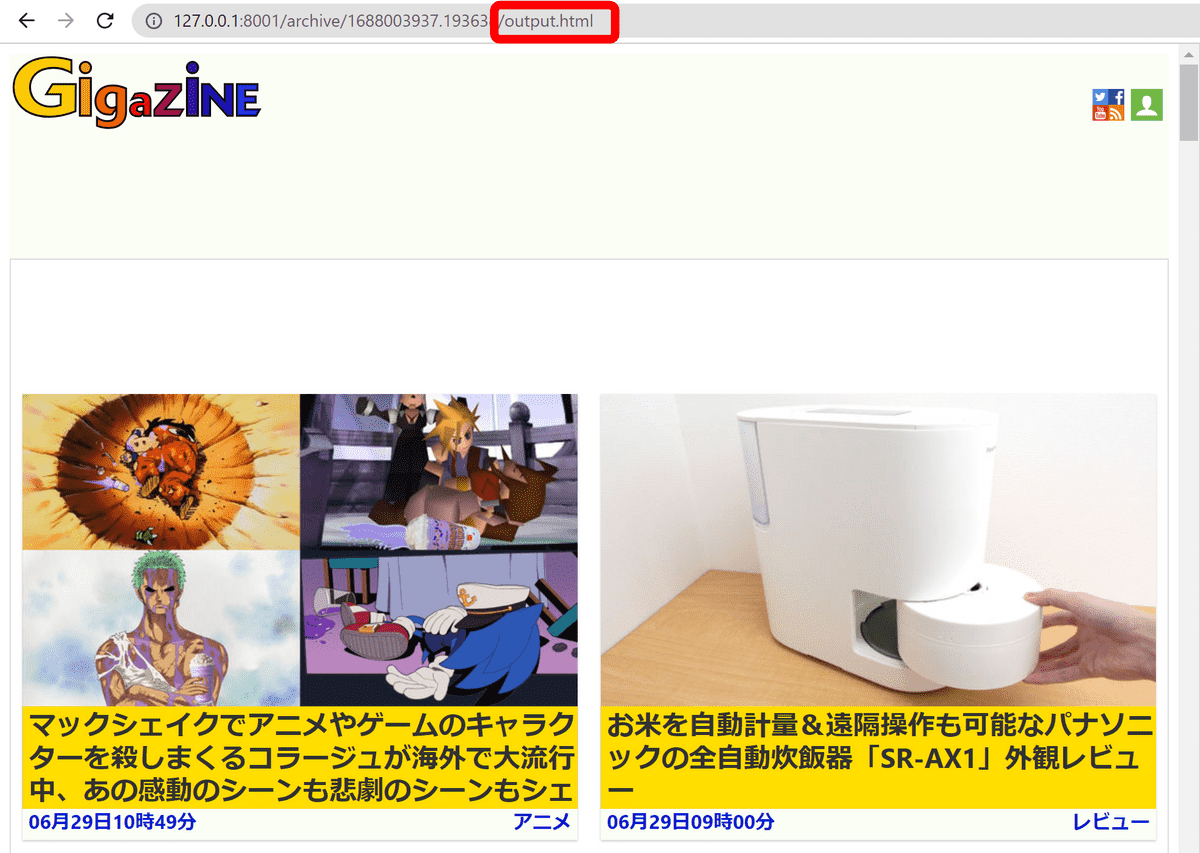
・Chrome > HTML
Save the HTML file saved via Chrome with the name 'output.html'.
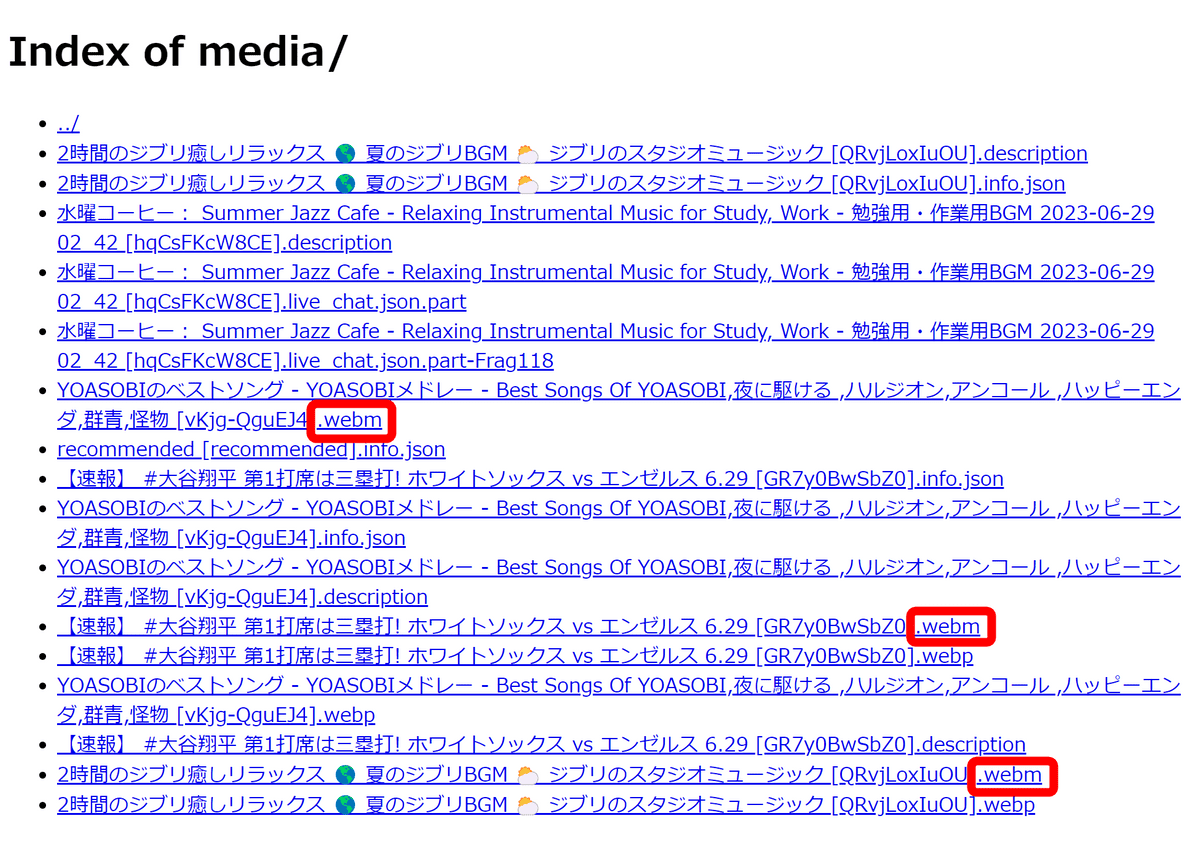
・Media
Contains media embedded in the page. No data was saved in GIGAZINE or Google, but when I checked the YouTube data, it looked like the figure below. Among them, it seems that the YouTube video data is saved in a complete format in the 'webm' format file.
In addition to these items, there is also a column called 'WARC' in the upper right. Through this link, it was possible to download a file in '
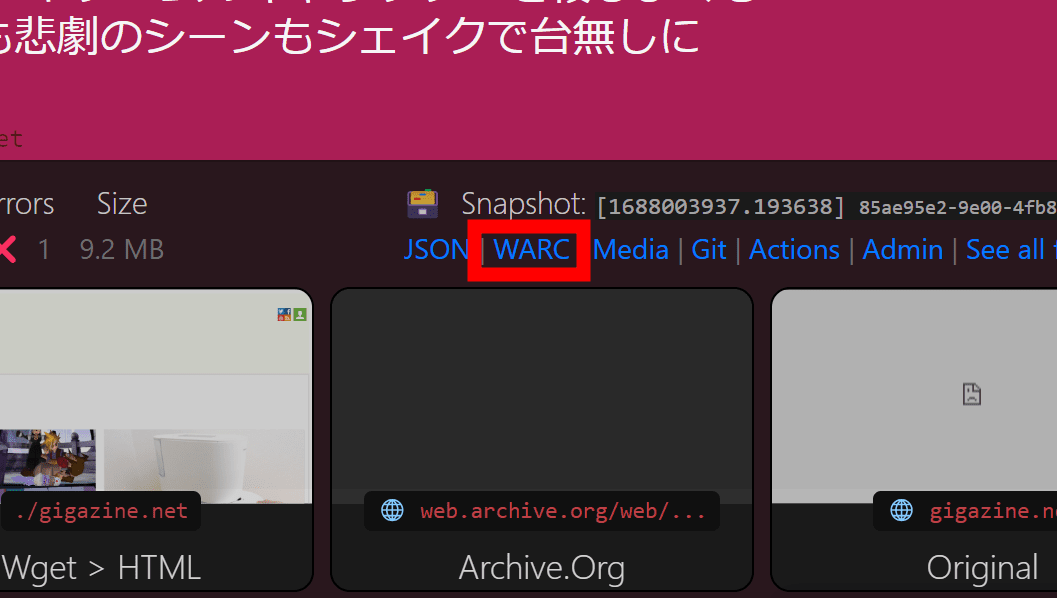
If you want to take a closer look at what format the data is saved in, check out the official demo .
Also, when ArchiveBox acquires data, it is possible to save the data of the site that requires authentication by specifying the profile of Chrome used internally, starting Chrome, and logging in to the site.
Websites are unexpectedly easily lost due to reasons such as the closure of free blog services, but by using tools that can save data locally like ArchiveBox, it seems that you will not be rushed in case of emergency.
Related Posts:




in Review, Software, Web Application, Posted by log1d_ts