




個人それぞれの好みに沿ったおすすめコンテンツを簡単にピックアップできるオープンソースなレコメンドエンジン「Metarank」を使ってみた

十人十色という四字熟語があるように、人はそれぞれ「見たいコンテンツ」が異なっているものです。ウェブサービスやアプリにおいて、ユーザーごとに適切なコンテンツを表示できればサービスの満足度が高まるのは間違いありません。「Metarank」はそうした個人ごとの最適化を簡単に行えるうえにオープンソースでセルフホスト可能なレコメンドエンジンとのことなので、実際に使ってどんなものなのか確かめてみました。
Metarank - open-source personalised ranker
https://www.metarank.ai/
metarank/metarank: A low code Machine Learning peersonalized ranking service for articles, listings, search results, recommendations that boosts user engagement. A friendly Learn-to-Rank engine
https://github.com/metarank/metarank
MetarankはDockerを利用して起動するため、下記のリンクから自分の環境に合った方法でDockerをインストールします。
Install Docker Engine | Docker Documentation
https://docs.docker.com/engine/install/
今回はCentOSを利用するため、下記のコマンドを入力しました。
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo systemctl start docker
早速Metarankを起動……したいところですが、まずは最適化を行うための元データを用意していきます。Metarankでは「コンテンツの情報」「ユーザーの情報」「ユーザーに何を表示したのか」「ユーザーが何を選択したのか」という4つの情報を元に最適化を行うとのこと。この4つの情報は、すべて「Event」という同じ形式のデータで扱われます。
例えば「コンテンツの情報」であれば下記の通り。「"event": "item"」はこのイベントが「コンテンツ情報の追加・更新」であることを意味しており、「"item": "item1"」でコンテンツ情報のIDを指定しています。Metarankの推薦結果はこのIDで返ってきます。また、「"fields"」には推薦する際に役立ちそうなデータを入力しておけばOK。
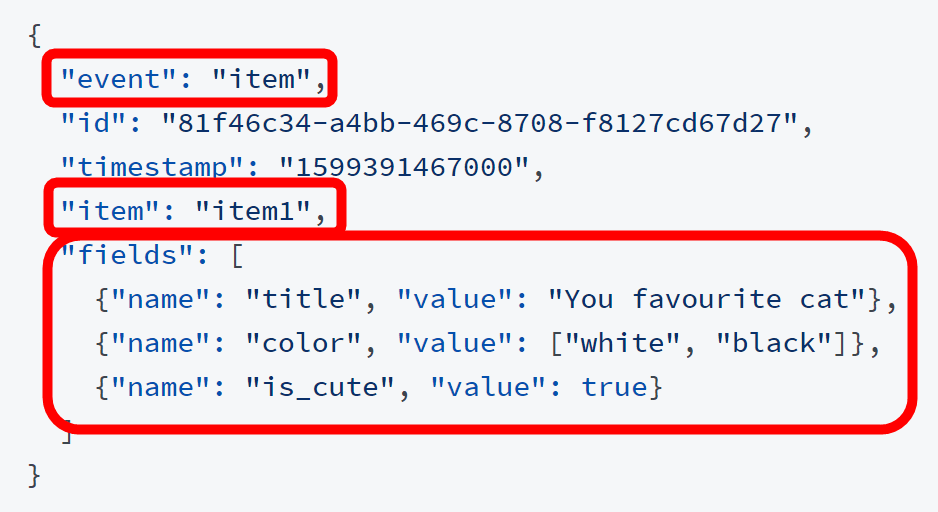
ユーザーの情報を追加・更新する際の形式は下記のようになります。event欄が「user」になったほか、ユーザーIDの指定が「user」欄で行われています。
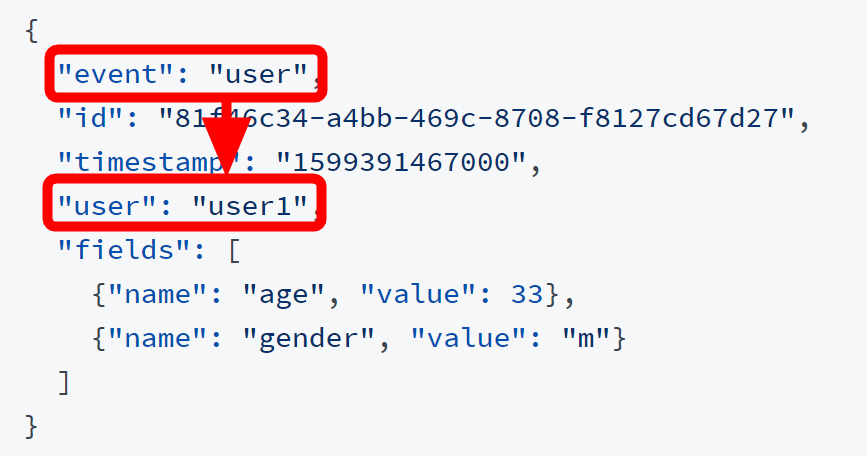
「ユーザーに何を表示したのか」という情報は、「ユーザーがどれを選んだのか」だけでなく、「どれを選ばなかったのか」を考慮に入れるために利用されています。下記の例では、「user1」が「cat」という文字を検索した際に、「item3」「item1」「item2」の順で表示したという意味になっています。itemの後ろについている「relevancy」欄にMetarank以外のランク付けシステムのスコアを入力しておくと精度が上がるとのこと。Metarankだけを利用する場合はMetarankの推薦結果をそのまま打ち返す形で入力することになります。
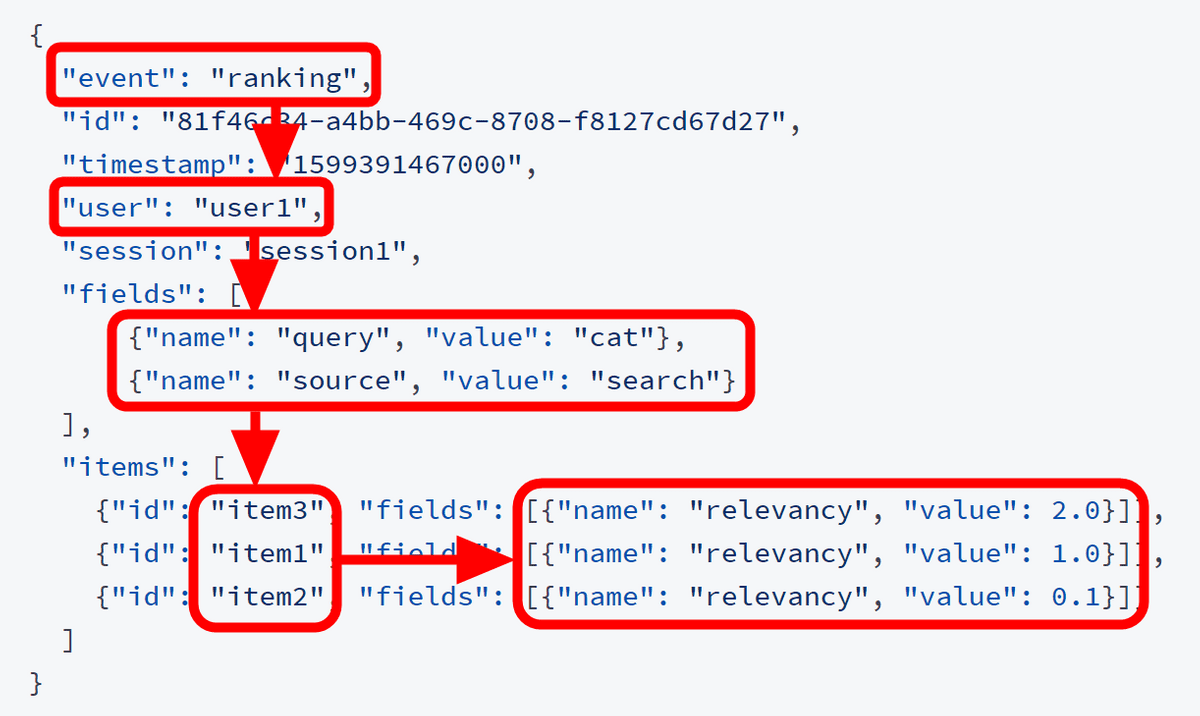
そして「ユーザーが何を選択したのか」というイベントでMetarankにどのコンテンツを推薦するべきだったかを教えていくわけです。下記の例ではuser1がitem1を購入した模様。

Metarankは、まっさらな状態から上記の4パターンのイベント情報を入れていくことでどんどん推薦の精度が上がっていくようになっています。起動後に順番にイベント情報を流し込んでもいいのですが、イベント情報をJSONL形式でまとめてgzip圧縮した状態のものを用意し、起動時に指定することでローカルから直接読み込む事が可能です。
今回は公式が用意しているデモ用のデータを利用してみます。デモデータは多数の映画の情報で構成されており、それぞれの映画のデータには「タイトル」「評価」「ジャンル」「俳優」「監督」などが記載されています。
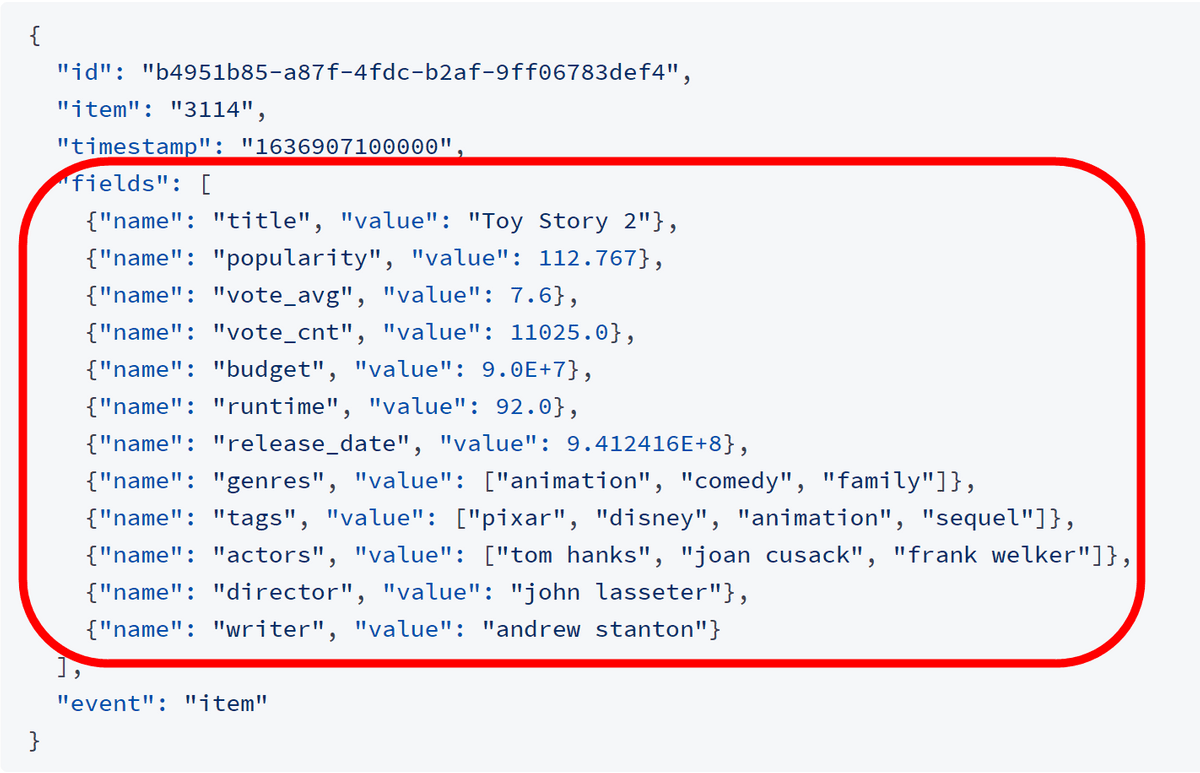
下記のコマンドでイベントデータをダウンロード。
curl -O -L https://github.com/metarank/metarank/raw/master/src/test/resources/ranklens/events/events.jsonl.gz
続いてモデルの名前や「イベントで入力された情報のどの部分を重視するのか」というウェイトの設定を行うためのファイル「config.yml」を用意します。今回は公式がチューニングしたファイルを下記のコードでダウンロードしました。自分のデータを利用する際でもある程度は自動で生成してくれるので少し修正するだけで良いとのこと。
curl -O -L https://raw.githubusercontent.com/metarank/metarank/master/src/test/resources/ranklens/config.yml
イベントデータと設定ファイルが用意できたら下記のコードでMetarankを起動します。
docker run -i -t -p 8080:8080 -v $(pwd):/opt/metarank metarank/metarank:latest standalone --config /opt/metarank/config.yml --data /opt/metarank/events.jsonl.gz
自動でイベントデータの読み込みと機械学習が行われ、下の画面になったら準備完了。
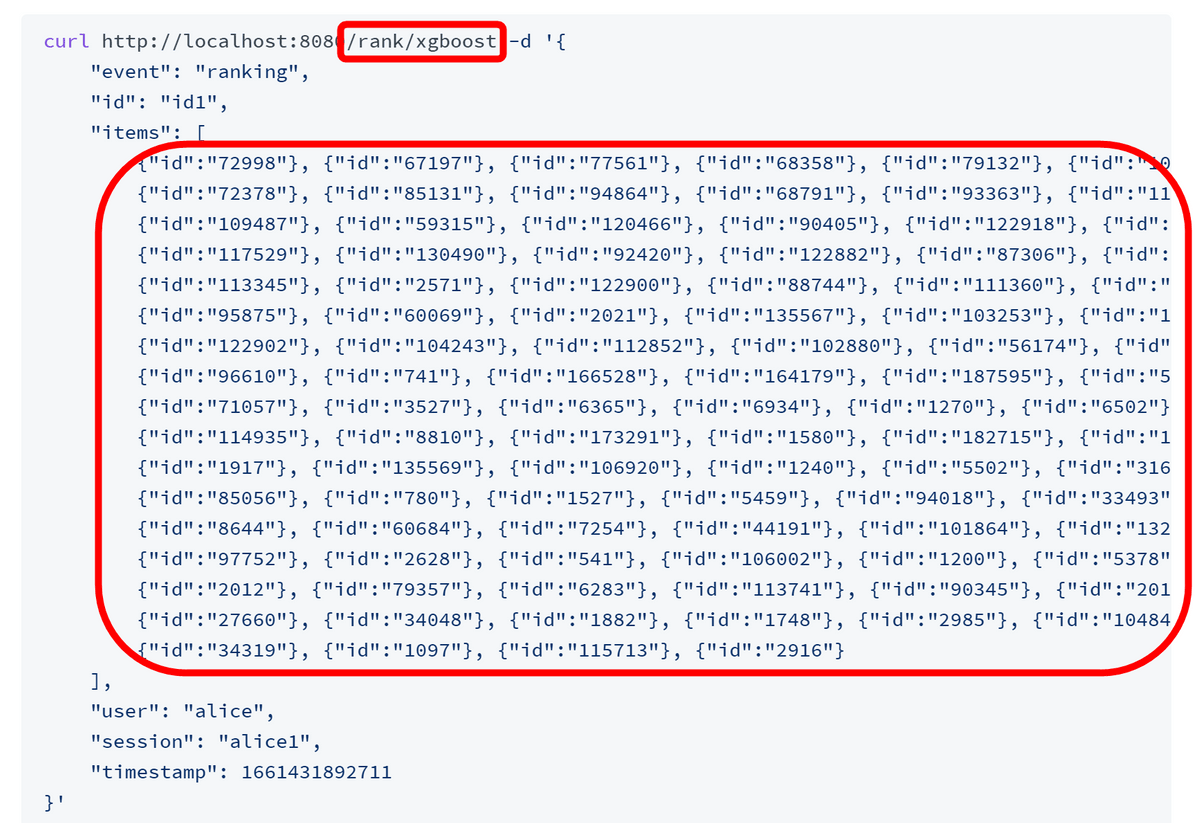
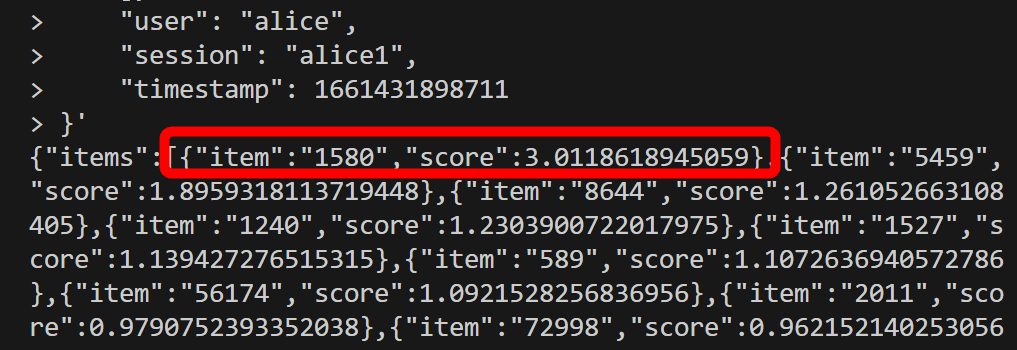
早速Metarankを利用してみます。Metarankの推薦結果をもらうには「Rank API」というAPIを利用すればOK。今回はクイックスタートガイドに記載されているコマンドを入力します。URLがRank APIのエンドポイントを指す「rank」になっており、「xgboost」というモデル名が指名されています。「items」欄では「どのコンテンツたちをランク付けしてほしいのか」を指定します。Metarankは単体でリコメンデーションを行うのではなく、他の検索エンジンやリコメンドエンジンの結果を元にパーソナライズを行うわけです。今回の「items」欄ではSF映画のトップ100が指定されているとのこと。
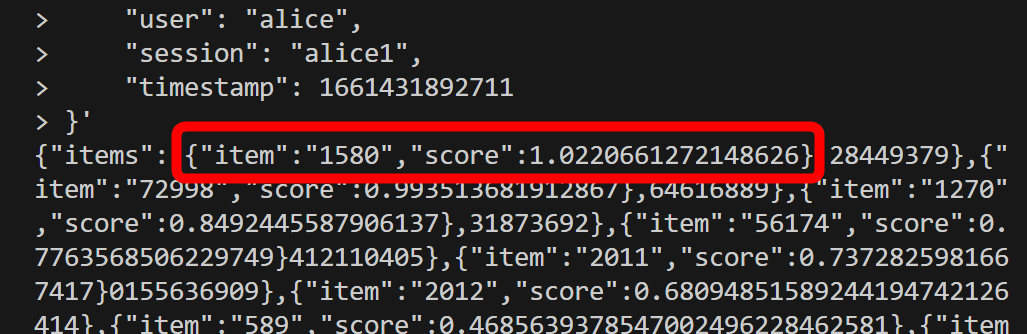
Metarankからはitemのidと推薦度スコアのデータが返ってきます。例えば今回であればidが「1580」の作品が「1.022~」のスコアでトップとなっています。
この返答を元の映画データと合わせて下図のように表示することを考えてみます。

Metarankからの推薦データは100件分ありますが、画面に表示されたのは12件なので「Feedback API」に12件分のデータを入力します。こうすることでMetarankが「ユーザーが選ばなかった作品」を考慮することが可能になるわけです。
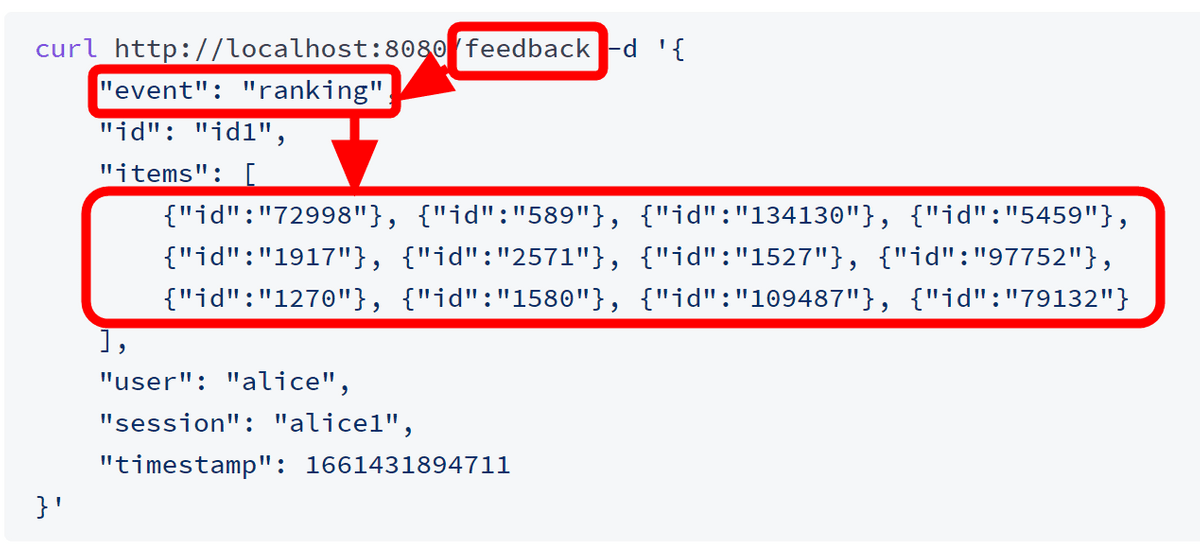
Feedback APIを通して、作品idが「1580」の作品をユーザーがクリックしたというデータを入力してみます。
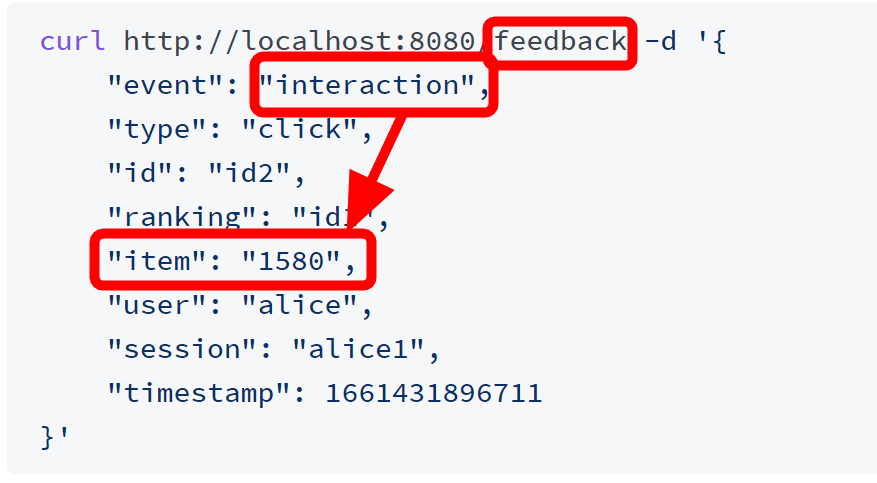
再び同じ100件で推薦度スコアを計算させてみると、今度はスコアが「3.01~」と約3倍になっており、ユーザーに合わせてパーソナライズできていることが分かります。そのほか、1580番の作品と俳優や監督などの共通点がある作品のスコアが向上するとのこと。
初期状態では学習結果がメモリに保存されており、Metarankを終了した際にデータが消えてしまいますが、データの保存先にRedisを選択することができ、永続的にデータを保管したり、複数のMetarankインスタンスを立ち上げてスケール性能を確保したりするなどの使い方も可能となっています。
・関連記事
機械学習でGIGAZINEの関連記事を自動生成するサーバーを作ってみました - GIGAZINE
「ゲームとTwitterとFacebookしかしないなんてもったいない」、Gunosy開発チーム根掘り葉掘りインタビュー - GIGAZINE
「よくないね!」ボタンには意味があるのか? - GIGAZINE
「好きな曲と似た雰囲気の曲」をAIが1億2000万曲の中から見つけ出してくれる「Maroofy」 - GIGAZINE
GoogleやYouTubeで表示される広告を自分好みに変更できる「マイアドセンター」の使い方まとめ - GIGAZINE
・関連コンテンツ


in ソフトウェア, レビュー, Posted by log1d_ts
You can read the machine translated English article I tried using an open source recommendat….