超高精度な国産音声認識AI「ReazonSpeech」が無償公開されたので文字起こし機能を使ってみた
東京に拠点を置くテクノロジー企業「レアゾン・ホールディングス」が、1万9000時間に及ぶ国内最大級の日本語音声コーパス「ReazonSpeech」を無償公開しました。同時に、OpenAIが開発した超高性能音声認識AI「Whisper」に匹敵する性能をアピールする文字起こしサービスも公開されていたので、実際に使ってみました。
超高精度で商用利用可能な純国産の日本語音声認識モデル「ReazonSpeech」を無償公開 - Reazon Human Interaction Lab
https://research.reazon.jp/news/reazonspeech.html
ReazonSpeech - Reazon Human Interaction Lab
https://research.reazon.jp/projects/ReazonSpeech/
レアゾン・ホールディングスは「ReazonSpeech」のプロダクト群として、文字起こしに使える「ReazonSpeech音声認識モデル」、テレビの録画データなどから音声コーパスを自動抽出できる「ReazonSpeechコーパス作成ツール」、合計1万9000時間に及ぶ高品質な日本語音声認識モデル学習用コーパス「ReazonSpeech音声コーパス」の3種を無償公開しました。中でも、「ReazonSpeech音声認識モデル」はWhisperに匹敵する精度を実現しているとのこと。レアゾン・ホールディングスは「ReazonSpeech音声認識モデル」を用いた文字起こしサービスも同時公開していたので、実際に文字起こし精度を確認してみました。
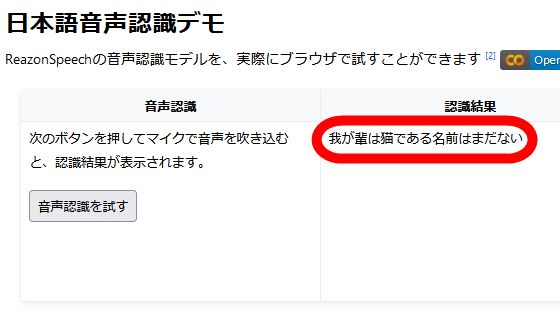
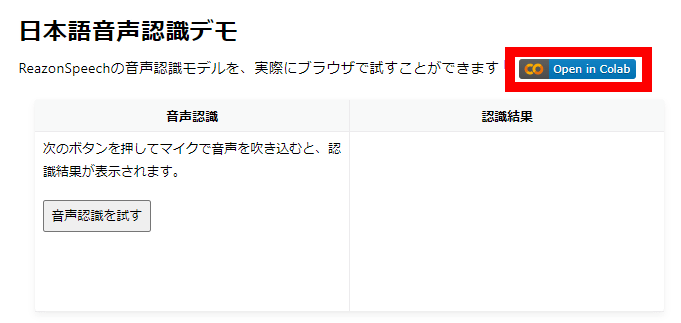
まず、文字起こしサービスのデモページにアクセスして「音声認識を試す」をクリック。
画面左上にマイクの使用許可を求めるポップアップが表示されたら「許可」をタップします。
すると、「録音中(5秒間)」と表示されるので、文字起こしさせたい文章を5秒間読み上げます。
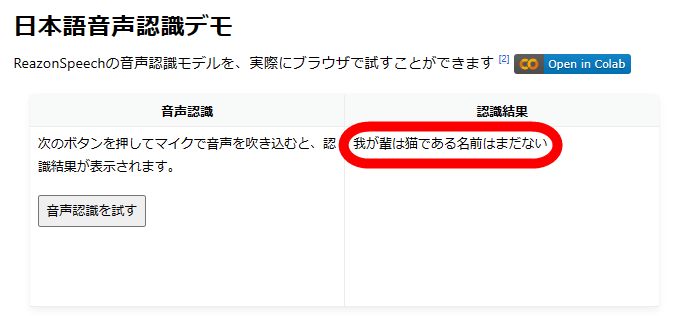
音声認識は5秒で自動的に終了し、画面右側に文字起こし結果が表示されます。「吾輩は猫である」の冒頭を読み上げた結果、正しく文字起こししてくれました。
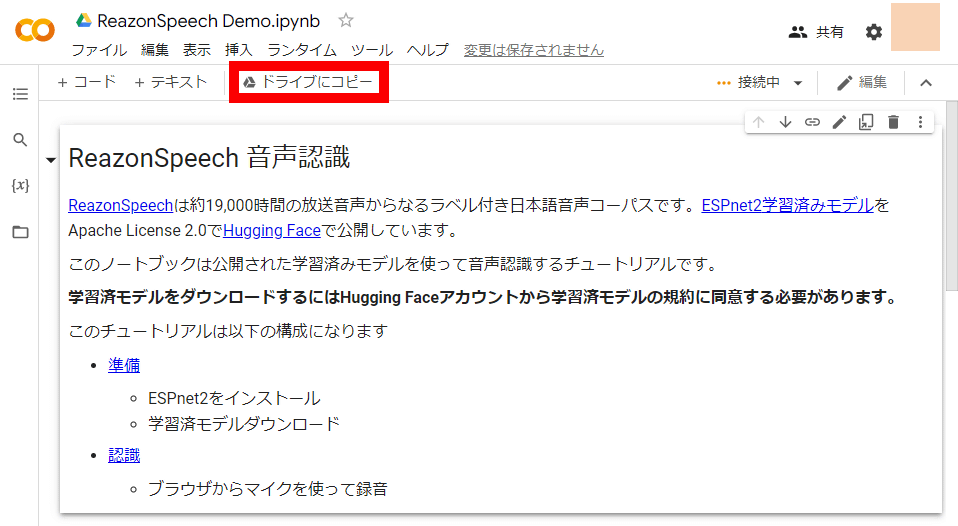
デモページでは最大5秒しか文字起こしできないので、Google製Python実行環境「Google Colab」上で公開されているノートブックを用いて長い文章の文字起こしを試してみます。まず、Googleにログインした状態で「Open in Colab」をクリック。
ノートブックが開いたら「ドライブにコピー」をクリックします。
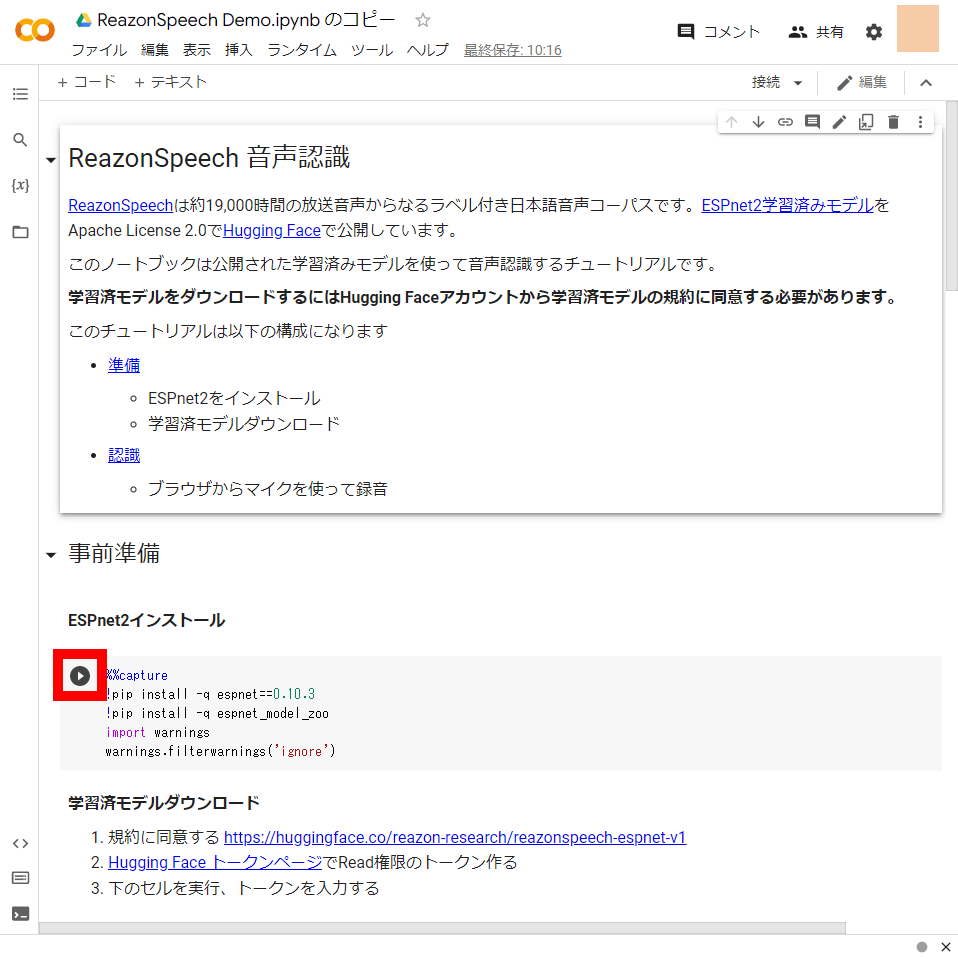
コピーが完了したら「ESPnet2インストール」と記された部分の再生ボタンをクリック。
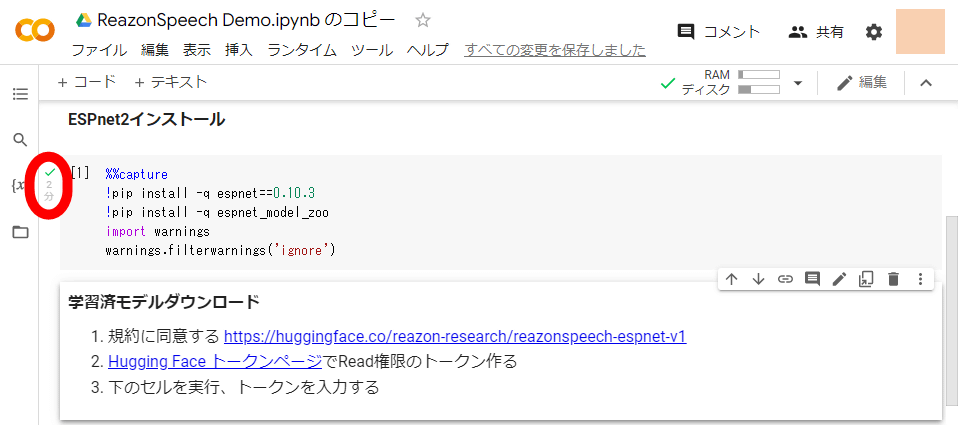
数分間待機して緑色のチェックマークが表示されたらOK。
次に、Hugging Faceにログインした状態でReazonSpeechの公開ページにアクセスし、「Agree and access repository」をクリックします。Hugging Faceのアカウントを持っていない場合は、過去の記事を参考に作成してください。
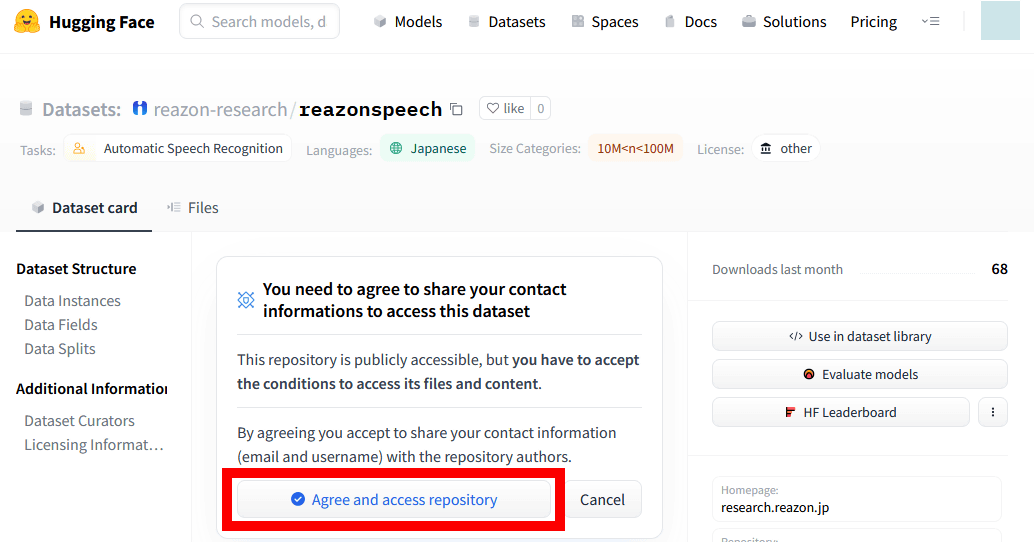
続いて、Hugging Faceのアクセストークン管理画面にアクセスして「New token」をクリック。
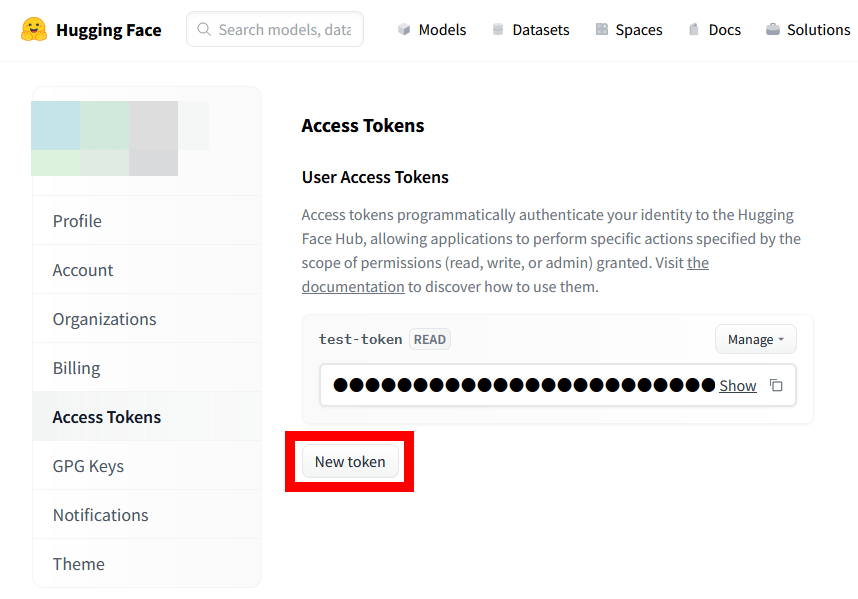
トークン作成画面が表示されたら好みの名前を入力して「Generate a token」をクリックします。
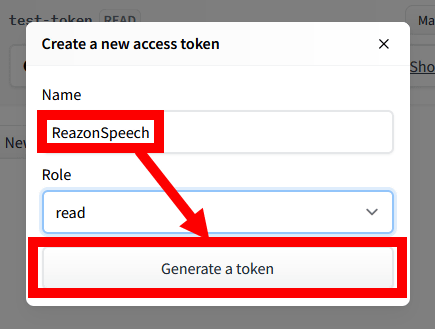
こんな感じにトークンを作成できたらOK。
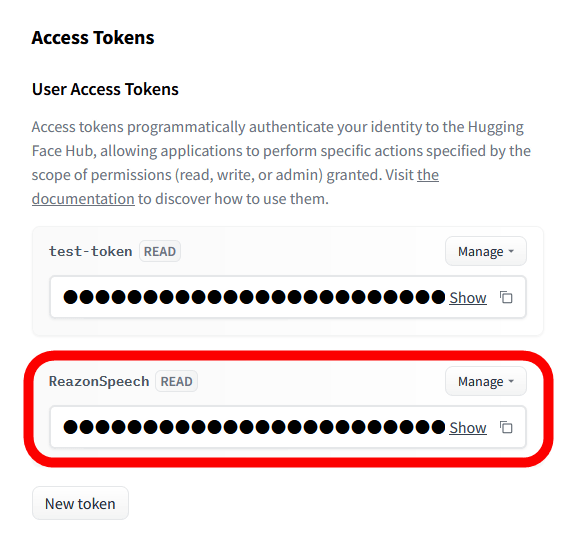
Google Colabの画面に戻って「from huggingface_hub Import notebook_login」と記された部分の再生ボタンをクリックします。
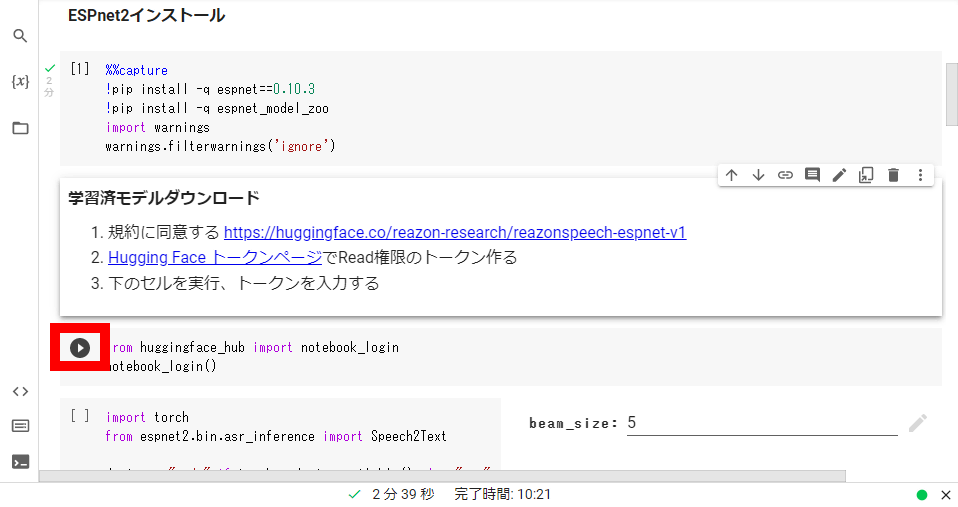
以下の画面が表示されたら、作成したトークンを入力して「Login」をクリック。
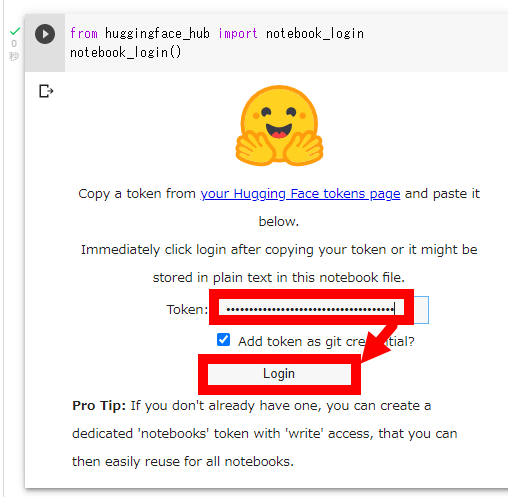
次に、「Import torch」と記された部分の再生ボタンをクリックします。
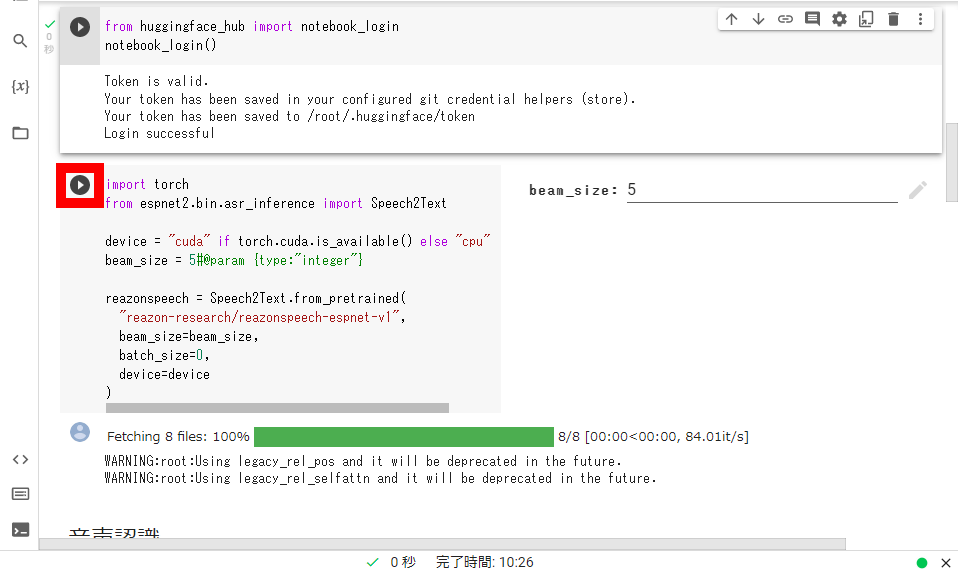
緑色のチェックマークが表示されたら下方向にスクロール。
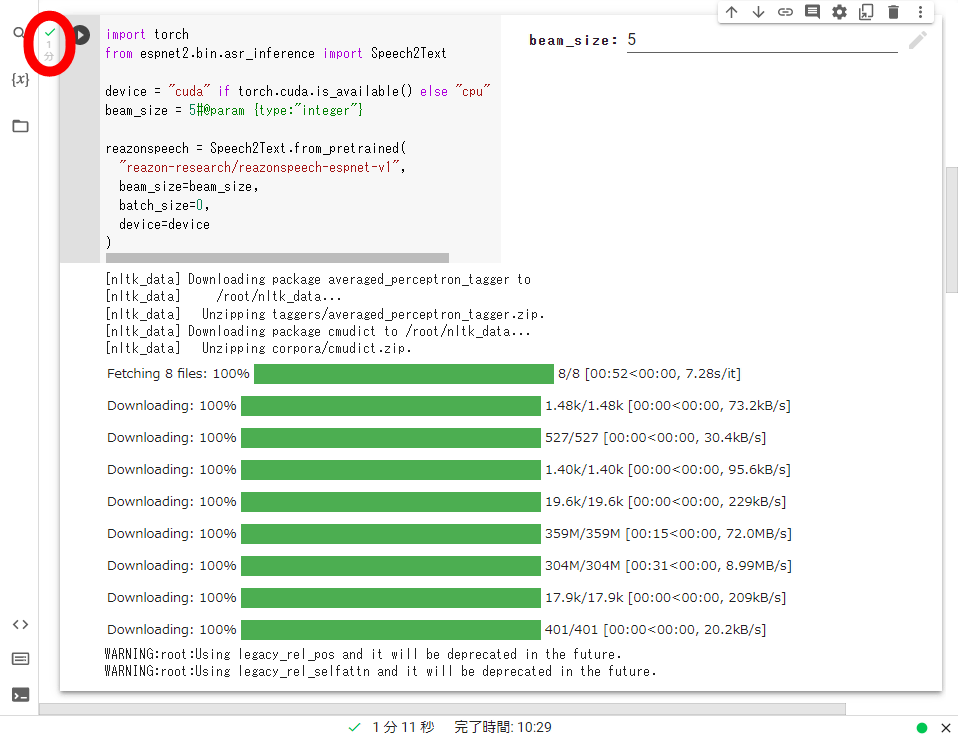
「音声認識」と記された部分の再生ボタンをクリック。
緑色のチェックマークが表示されたら「レコーディング」と記された部分の再生ボタンをクリック。

緑色のチェックマークが表示されたら下準備は完了です。

最下部までスクロールすると、「seconds:5」と記されたセルに到達します。この「seconds:5」の部分を書き換えれば、文字起こしの認識秒数を指定できます。
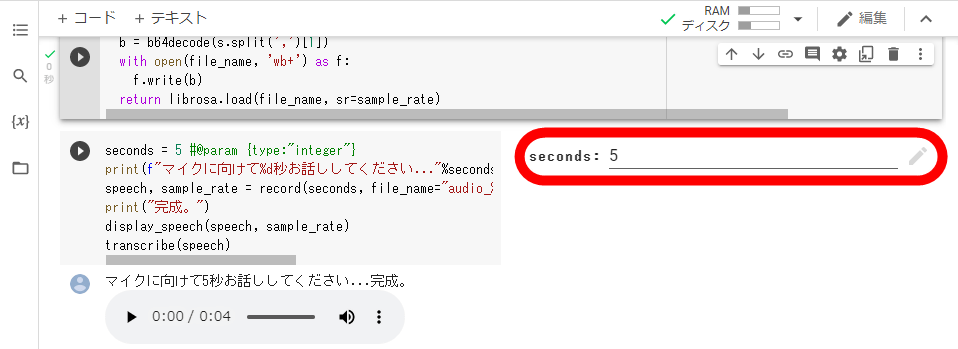
試しに認識秒数を30秒に指定して再生ボタンをクリックしました。
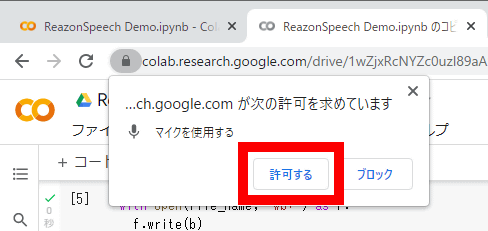
マイクの使用許可を求められたら「許可する」をクリック。
画面に「マイクに向けて30秒お話ししてください」と表示されるので、30秒間話し続けます。
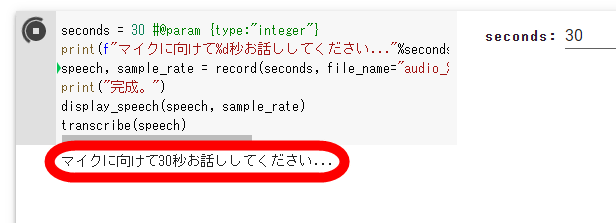
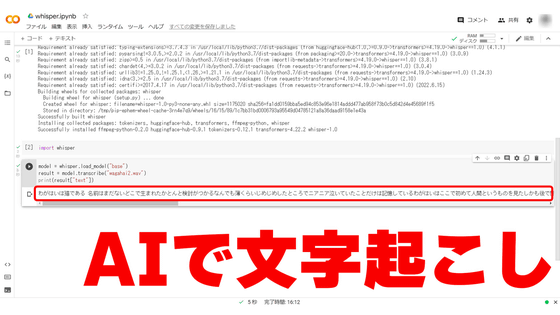
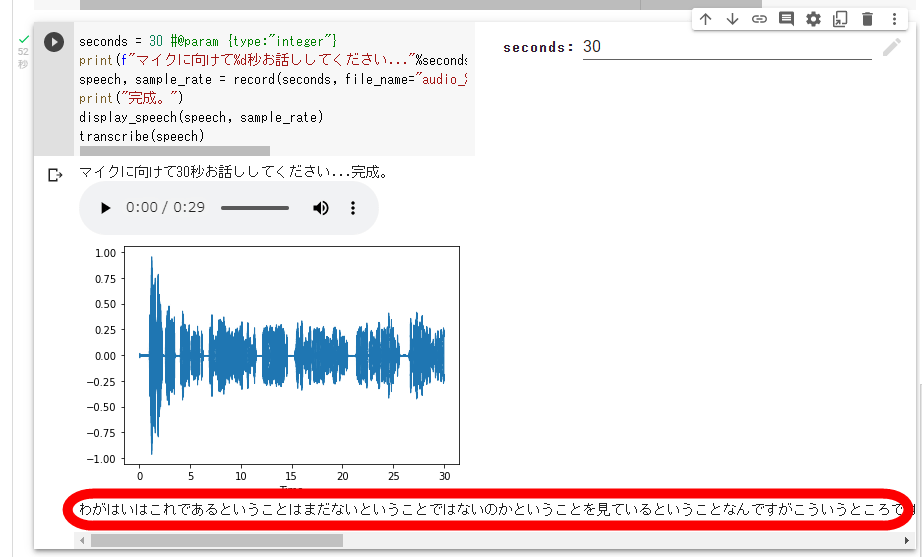
30秒話し続けてから少し待つと、画面下部に文字起こし結果が表示されます。しかし、「吾輩は猫である」の冒頭部分を読み上げたにもかかわらず「わがはいはこれであるということはまだないということではないのかということを見ているということなんですがこういうところではないということだけではなくしているということではないということを言ったということでしたがそれはないということなのではないかということであったということだと思いますがこのあとはどういうことなんでしょうということでありましたからそのことはなんということもなかったんです」という支離滅裂な文章が出来上がってしまいました。
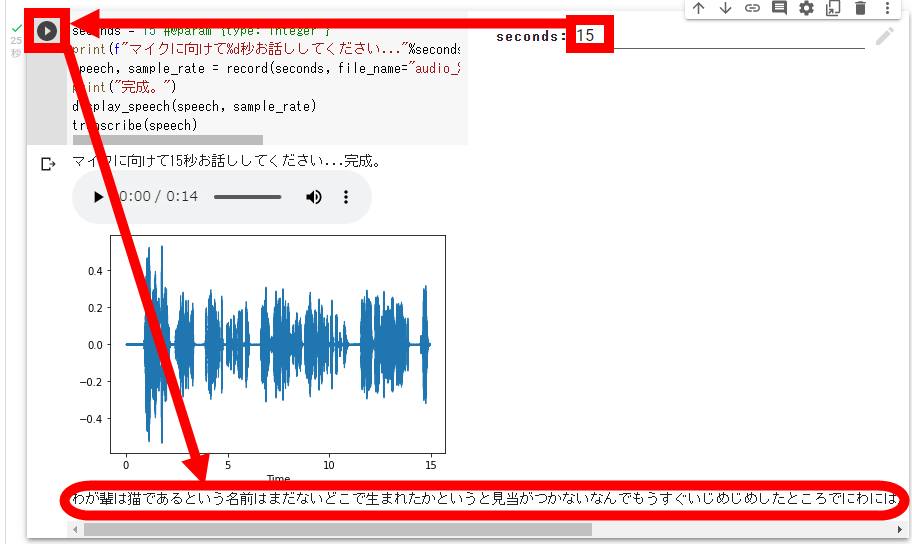
文字起こしが正常に動作しなかったのは認識秒数を長くしたのが原因と考え、認識秒数を15秒にした結果「わが輩は猫であるという名前はまだないどこで生まれたかというと見当がつかないなんでもうすぐいじめじめしたところでにわには泣いていたことだけは記憶しているわが輩はここで初めて人間というものを見た」という比較的まともな文字起こし結果を得られました。記事作成時点では、ReazonSpeechのデモ版は文章の区切りをうまく認識できないようです。
・関連記事
無料でOpenAIの「Whisper」を使って録音ファイルから音声認識で文字おこしする方法まとめ - GIGAZINE
面倒な文字起こし作業を一瞬で実行可能なLINE製AI音声認識アプリ「CLOVA Note」の使い方まとめ - GIGAZINE
無料で自動文字起こししてくれるMicrosoft製アプリ「Group Transcribe」を使ってみた - GIGAZINE
Google Chrome上でマイクから録音した声をリアルタイムで文字に書き起こしてくれる「The Recording Studio」 - GIGAZINE
Googleの音声認識エンジンを使って音声ファイルから文字起こししてみた - GIGAZINE
無料で使える音声の文字起こしに便利な機能を搭載したツール「テープ起こしプレーヤー」 - GIGAZINE
・関連コンテンツ