Ultra-high precision domestic speech recognition AI 'ReazonSpeech' was released free of charge, so I tried using the transcription function
Tokyo-based technology company 'Raazon Holdings' has released ' ReazonSpeech ', one of the largest Japanese speech corpus in Japan with 19,000 hours, for free. At the same time, a transcription service that appeals to performance comparable to the ultra-high-performance speech recognition AI '
Free release of 'ReazonSpeech', a purely domestic Japanese speech recognition model that can be used commercially with ultra-high accuracy - Reason Human Interaction Lab
https://research.reason.jp/news/reasonspeech.html
ReasonSpeech - Reason Human Interaction Lab
https://research.reason.jp/projects/ReasonSpeech/
As a product group of 'ReazonSpeech', Raazon Holdings has a ' ReazonSpeech speech recognition model ' that can be used for transcription, a ' ReazonSpeech corpus creation tool ' that can automatically extract a speech corpus from recorded TV data, etc., a total of 19,000 hours. Three types of high-quality Japanese speech recognition model training corpus ' ReazonSpeech speech corpus ' have been released free of charge. Among them, 'ReazonSpeech speech recognition model' has achieved accuracy comparable to Whisper. Raizon Holdings also released a transcription service using the 'ReazonSpeech speech recognition model' at the same time, so I actually checked the transcription accuracy.
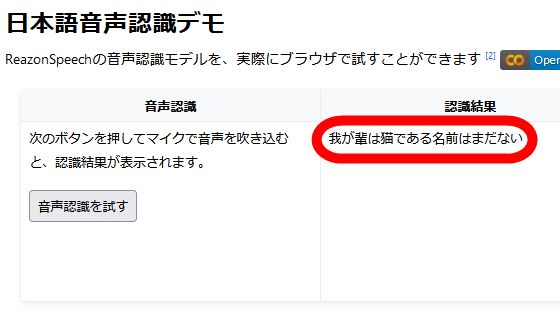
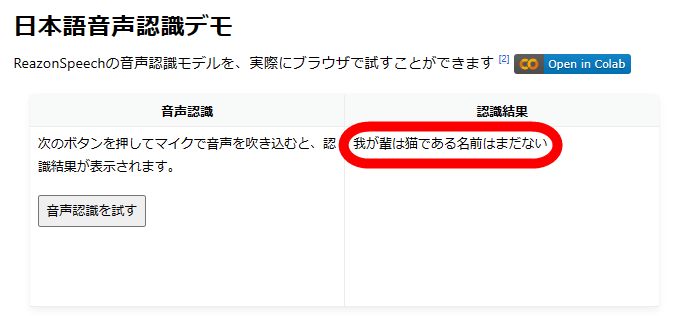
First, access the demo page of the transcription service and click 'Try speech recognition'.
When a pop-up requesting permission to use the microphone appears on the upper left of the screen, tap 'Allow'.
Then, 'Recording (5 seconds)' is displayed, so read the sentence you want to transcribe for 5 seconds.
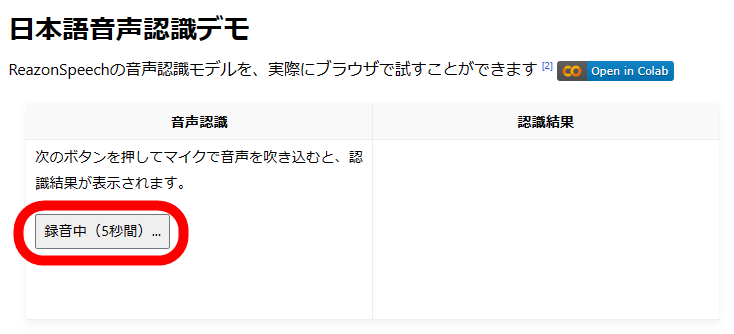
Speech recognition ends automatically in 5 seconds, and the transcription result is displayed on the right side of the screen. As a result of reading the beginning of 'I am a
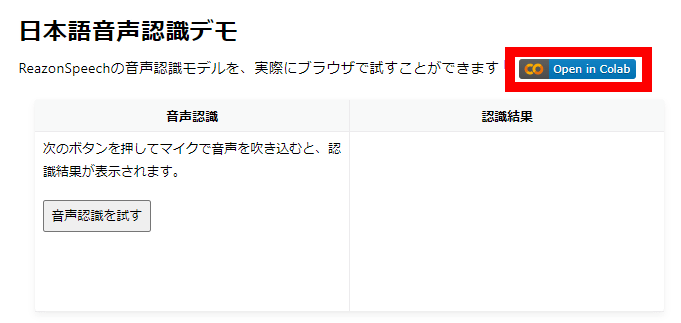
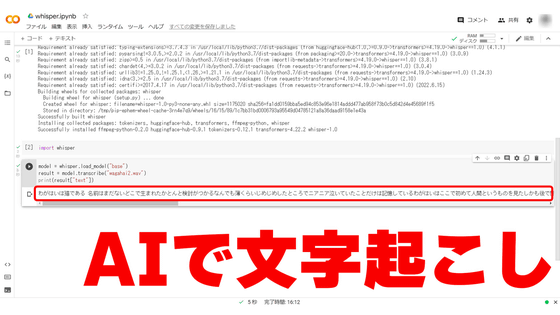
Since the demo page can only transcribe for a maximum of 5 seconds, I will try to transcribe a long sentence using a notebook published on Google's Python execution environment 'Google Colab'. First, click 'Open in Colab' while logged in to Google.
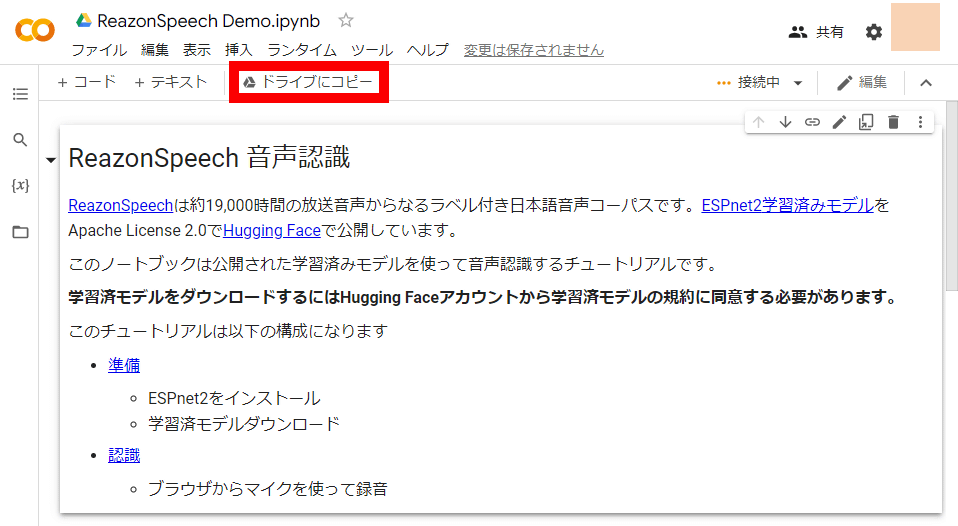
After the notebook opens, click Copy to Drive.
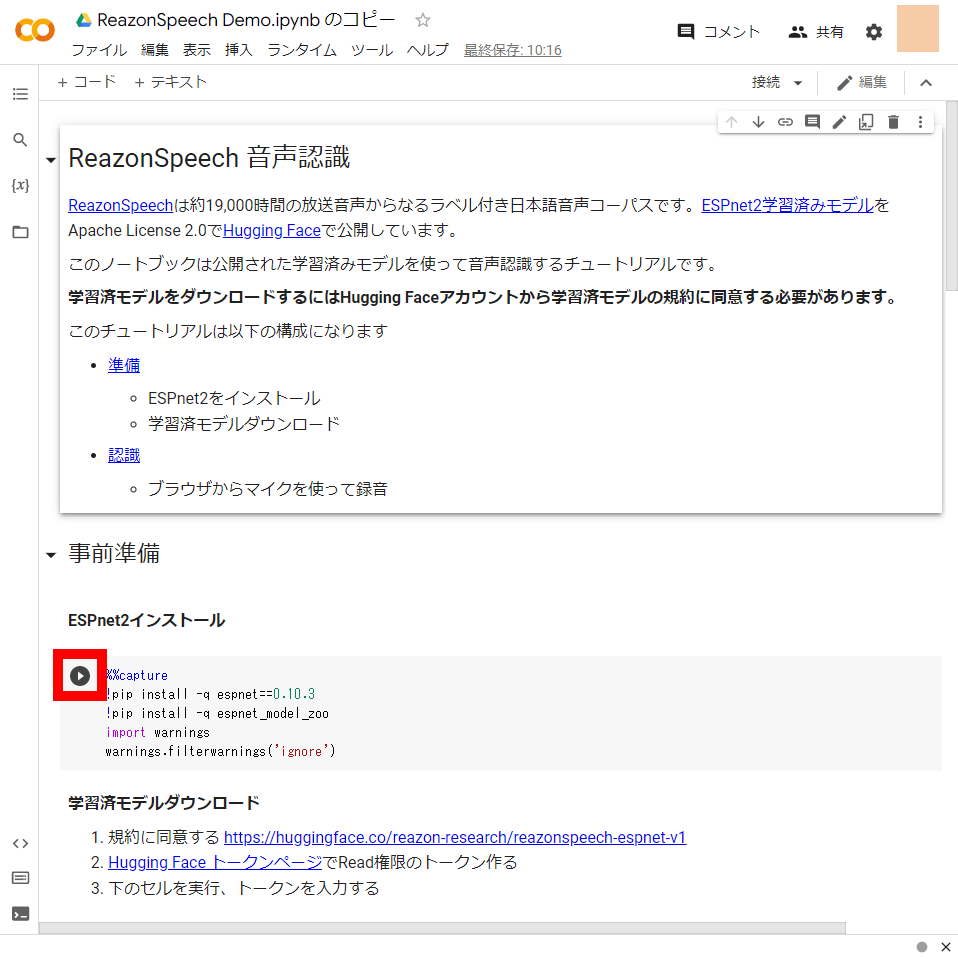
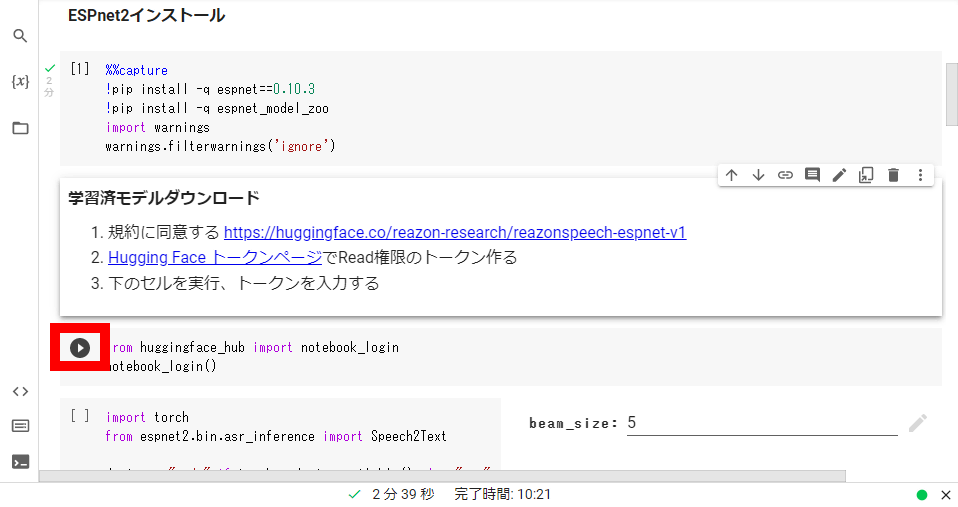
When copying is completed, click the play button in the part marked 'ESPnet2 installation'.
Wait for a few minutes and OK when a green check mark is displayed.
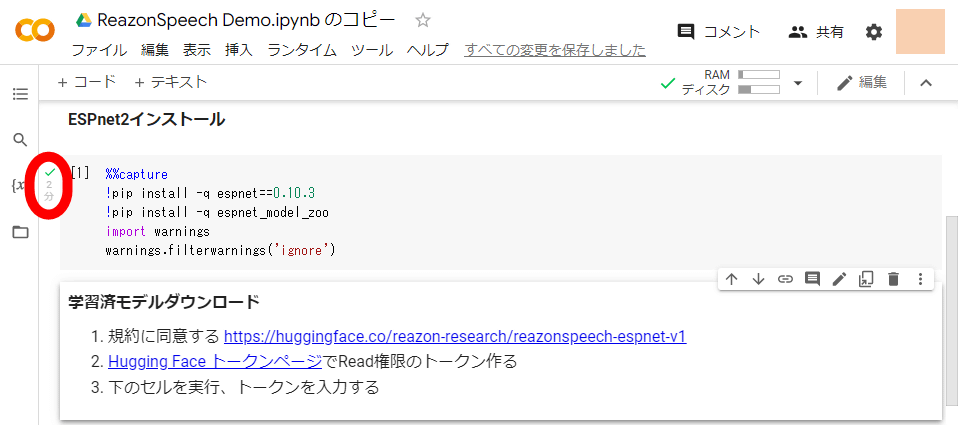
Next, while logged in to Hugging Face, access the ReasonSpeech
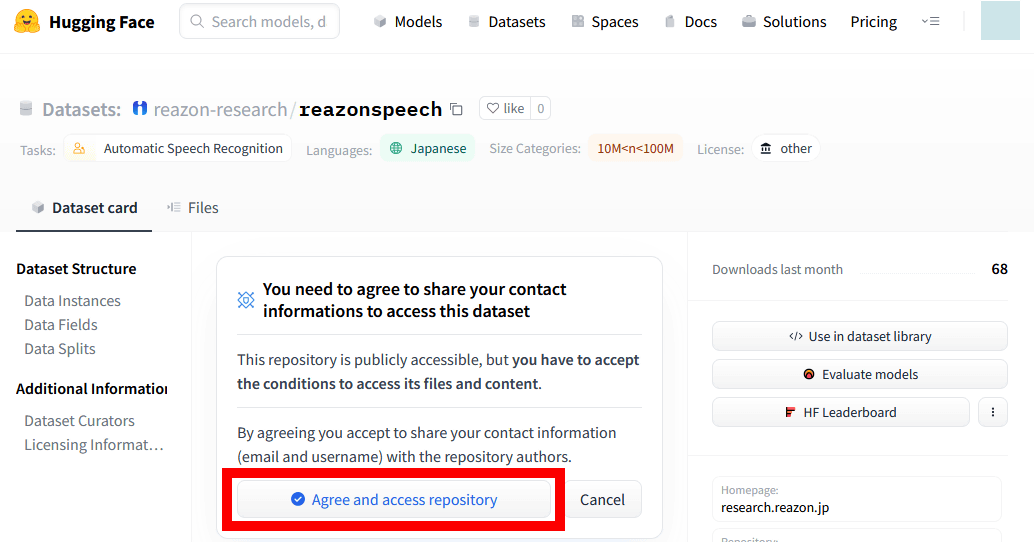
Next, access Hugging Face's
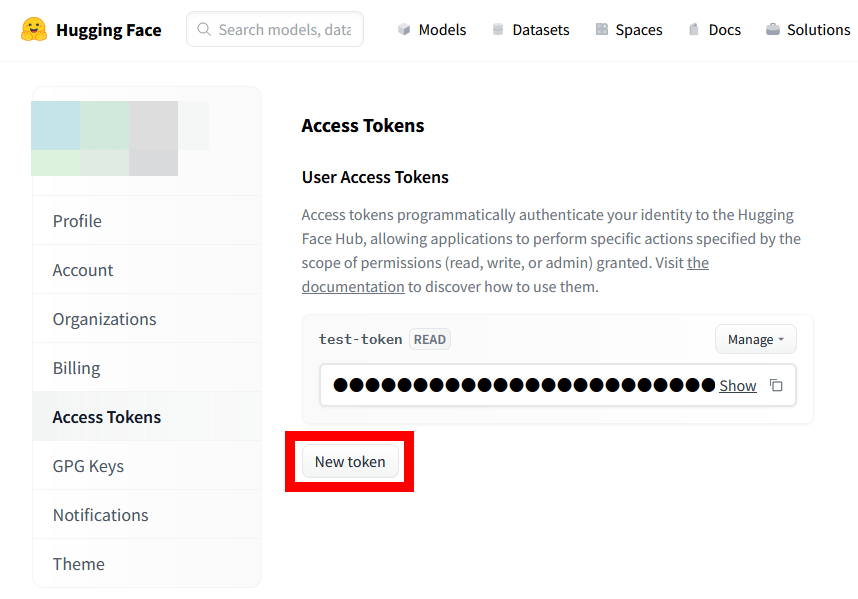
When the token creation screen is displayed, enter a name of your choice and click 'Generate a token'.
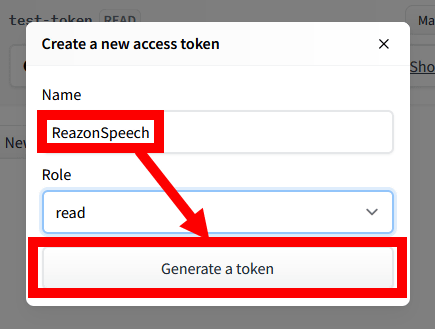
It is OK if you can create a token like this.
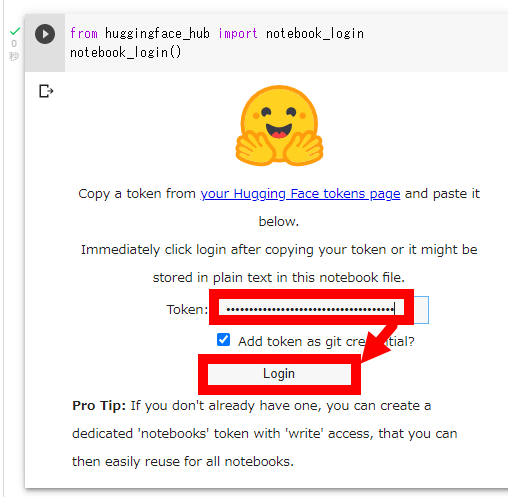
Return to the Google Colab screen and click the play button on the part marked 'from huggingface_hub Import notebook_login'.
When the following screen is displayed, enter the created token and click 'Login'.
Then click the play button in the part marked 'Import torch'.
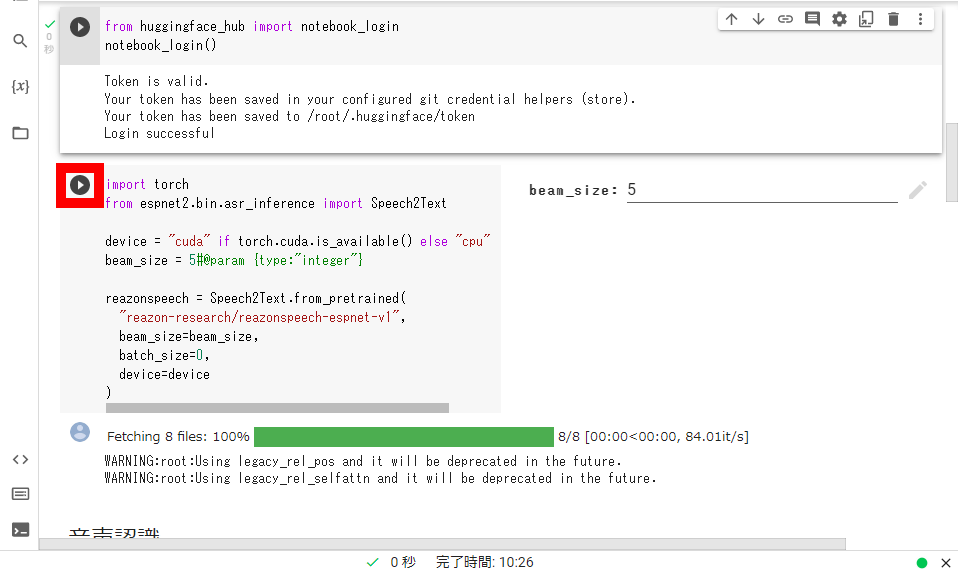
Scroll down when you see a green check mark.
Click the play button in the part marked 'Voice Recognition'.
When the green check mark is displayed, click the play button of the part marked 'Recording'.

Preparations are complete when a green check mark appears.

Scroll to the bottom until you reach the cell marked 'seconds: 5'. By rewriting this 'seconds: 5' part, you can specify the number of seconds for transcription recognition.
As a trial, I specified the number of seconds for recognition to be 30 seconds and clicked the play button.
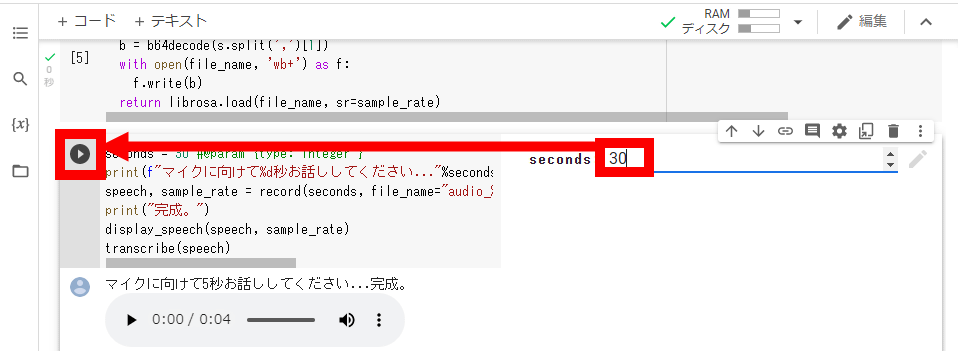
When asked for permission to use the microphone, click 'Allow'.
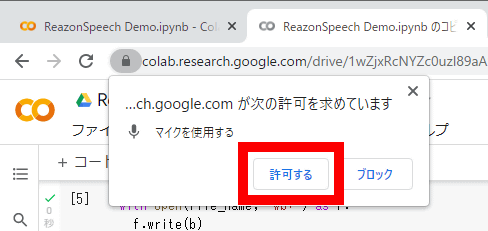
The screen will display 'Please talk into the microphone for 30 seconds', so continue talking for 30 seconds.
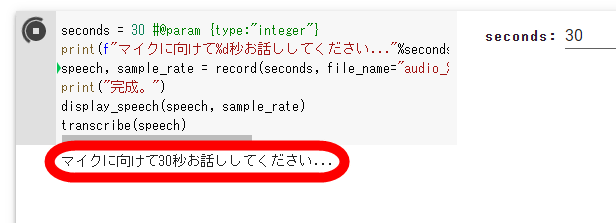
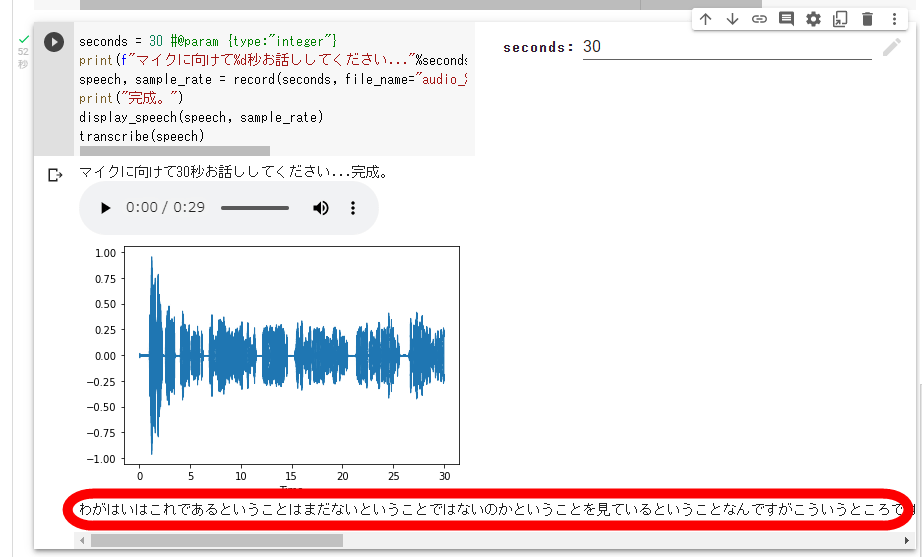
After speaking for 30 seconds, wait for a while, and the transcription result will be displayed at the bottom of the screen. However, despite reading the opening part of ``I am a cat'', ``I am looking at whether it is not yet possible to say that this is what I am, but it is not like this. I think he said that he didn't just say that he was doing it, but I think he said that he wasn't doing it, but I wonder what he meant after this. It was there, so there was nothing to worry about.'
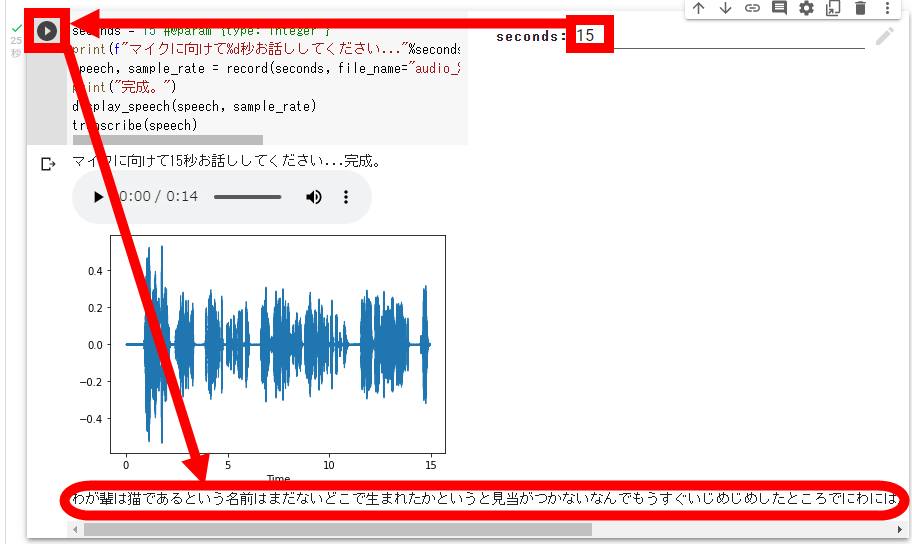
I thought that the reason why the transcription didn't work properly was that the number of seconds for recognition was lengthened . I can't get it, so I remember crying when I was about to be bullied. ' I got a relatively decent transcription result. At the time of writing the article, the demo version of ReasonSpeech does not seem to recognize sentence breaks well.
Related Posts:

in Software, Review, Web Application, Posted by log1o_hf