Summary of how to transcribe text from recorded files using voice recognition using OpenAI's 'Whisper' for free
Introducing Whisper
https://openai.com/blog/whisper/
GitHub - openai/whisper
https://github.com/openai/whisper
○Table of contents
◆Try using the trial version of Hugging Face
◆Introduce it to Google Colab and try using it
◆Try implementing it in a Windows environment
・Python installation
・Installing CUDA
・Installing PyTorch
・Installing ffmpeg
・Installing Whisper
◆Try transcribing with Whisper installed on Windows
◆Try using the trial version of Hugging Face
You can quickly try transcribing recorded audio using Whisper using the online AI framework Hugging Face. However, since the model is the smallest, it also has the lowest accuracy.
Whisper - a Hugging Face Space by openai
https://huggingface.co/spaces/openai/whisper
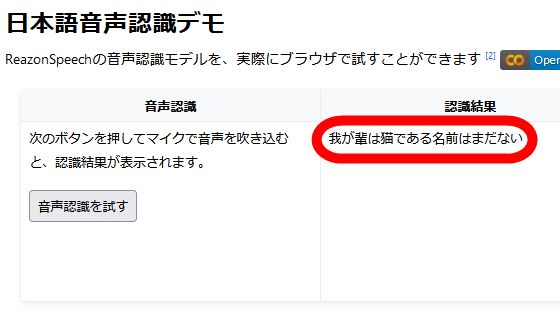
Access the above site. Click 'Record from microphone' on the left.
Your browser will ask you for permission to use the microphone, so click 'Allow'.
This time, I read out the opening part of Natsume Soseki's
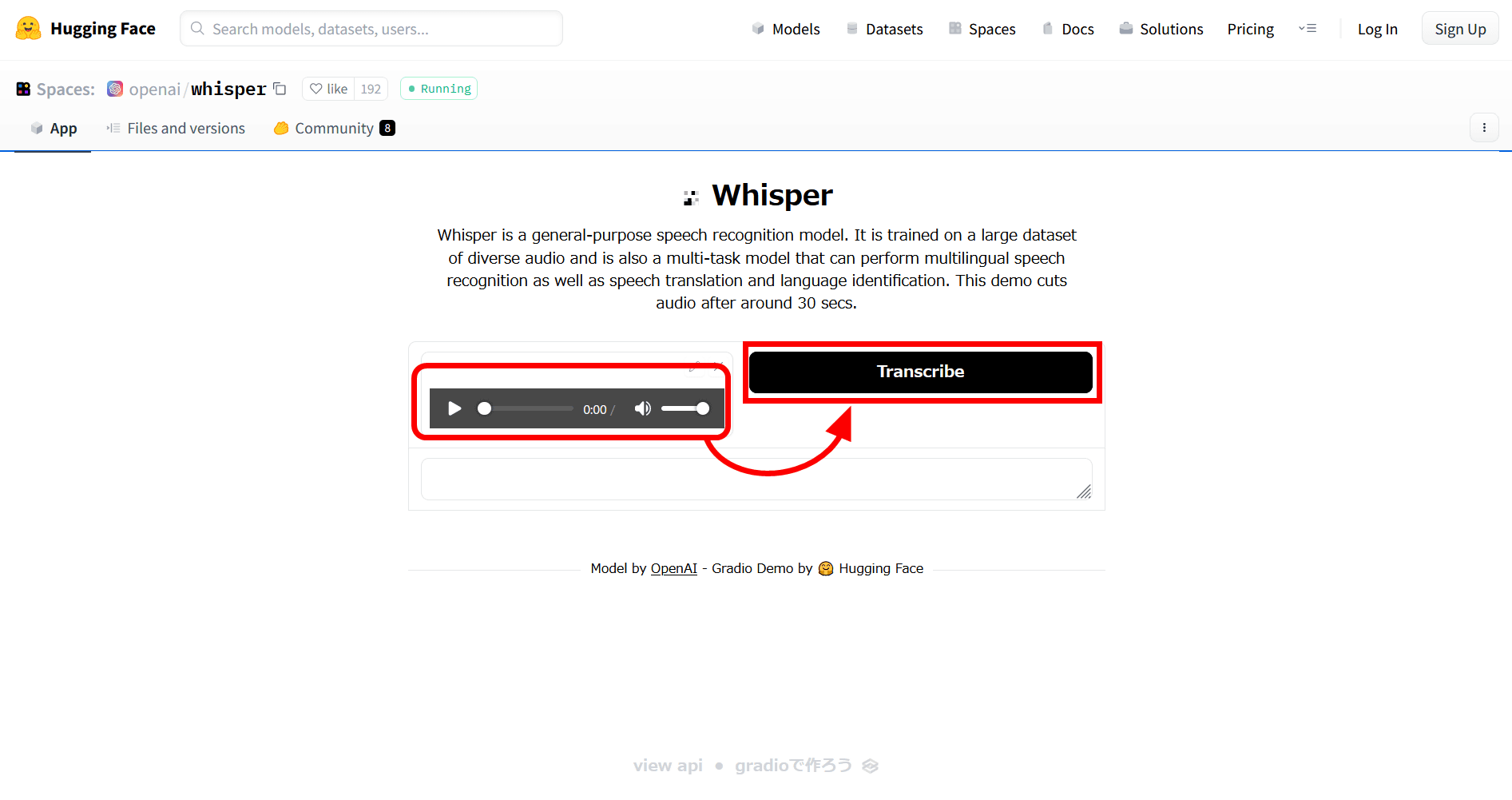
Then, the transcribed text was displayed below the player. ``Gaya'' is ``My Ash'', ``I can't consider it'' is ``I'm thinking about it'', and ``dim'' has become ``Sugari'', but the Japanese version, including the kanji conversion and onomatopoeic katakana notation, is You can see that the transcription is mostly accurate.
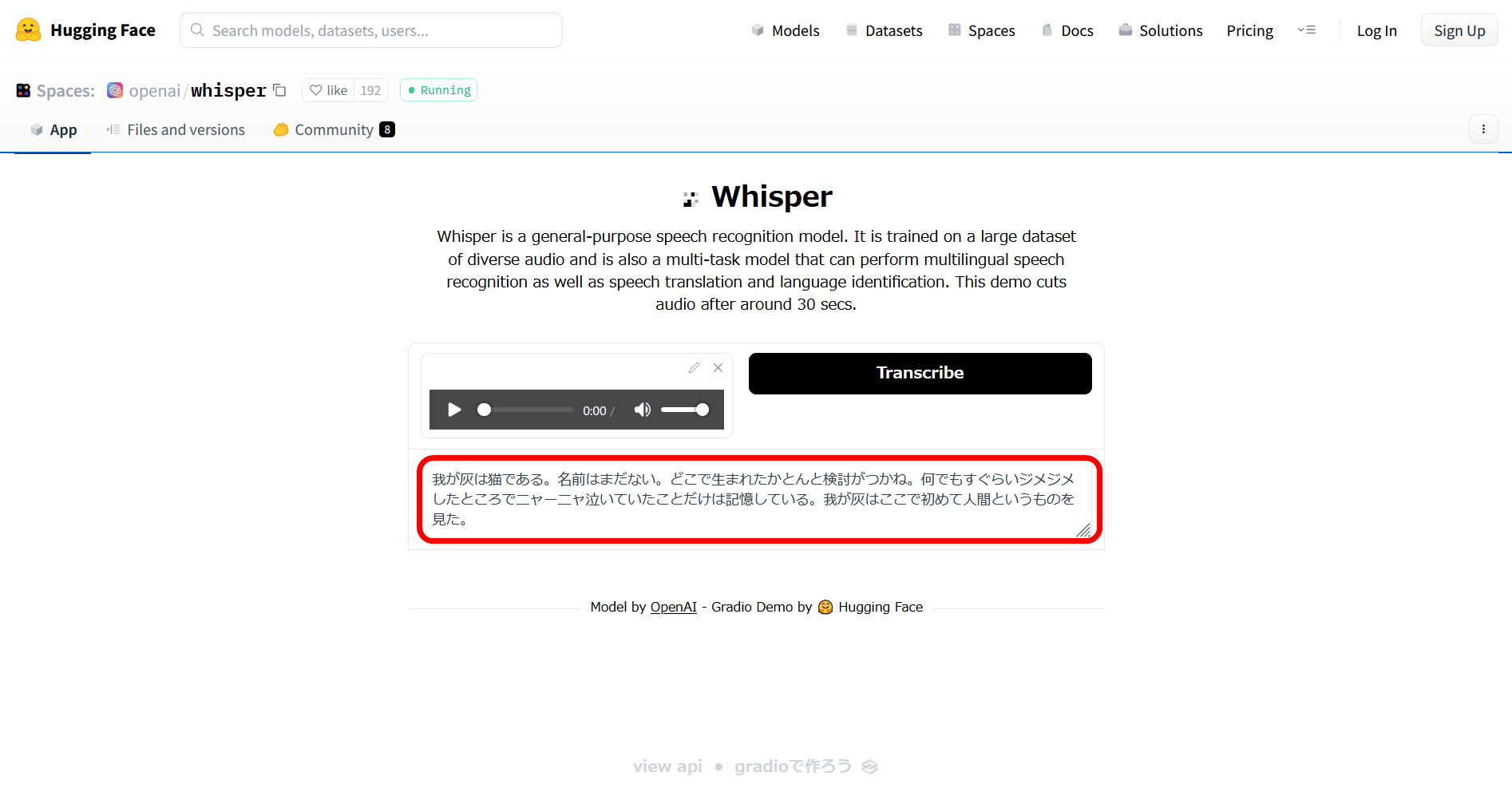
In addition, the Whisper model has parameter sizes of 'tiny' with 39 million, 'base' with 74 million, 'small' with 244 million, 'medium' with 769 million, and 'large' with 1.55 billion. There are 5 types. The required VRAM is up to 1GB for tiny and base, up to 2GB for small, up to 5GB for medium, and up to 10GB for large. There is also an en model that specializes in English, but the basics are compatible with other languages.
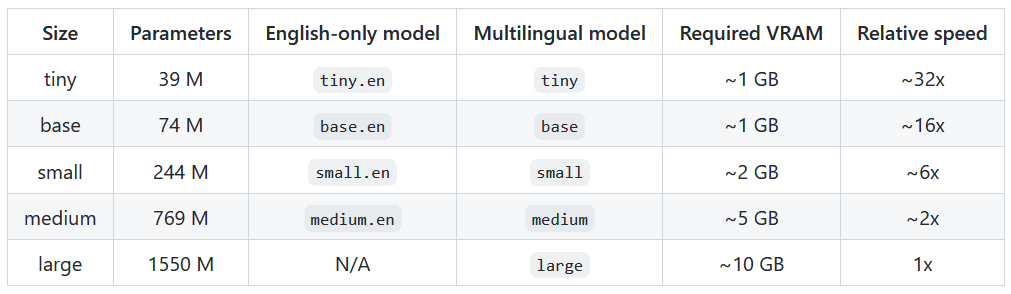
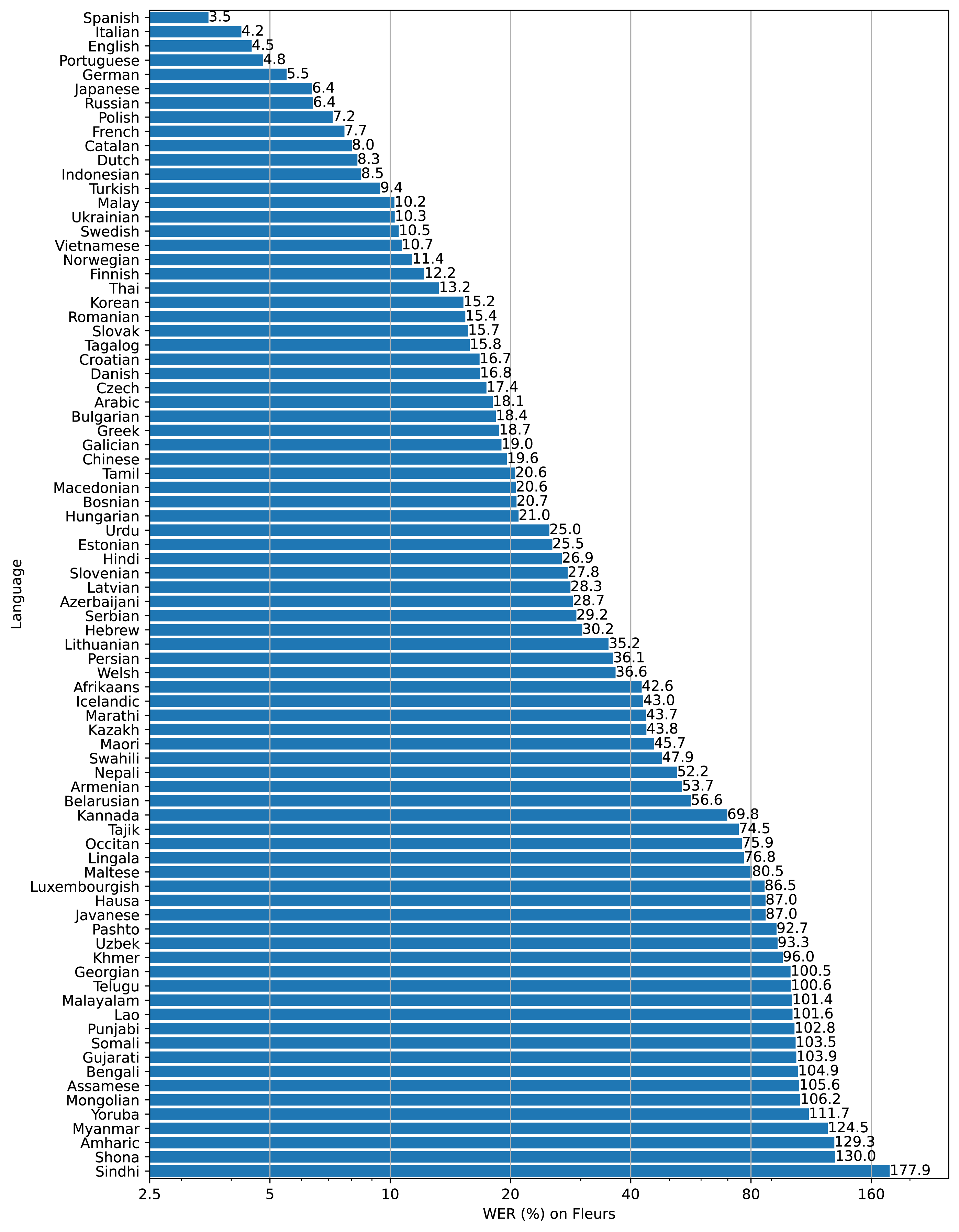
The following shows the error reporting rate (WER) for each language, and the lower the WER, the higher the accuracy of transcription. According to this, Japanese is in the top 6th place.
◆Introduce it to Google Colab and try using it
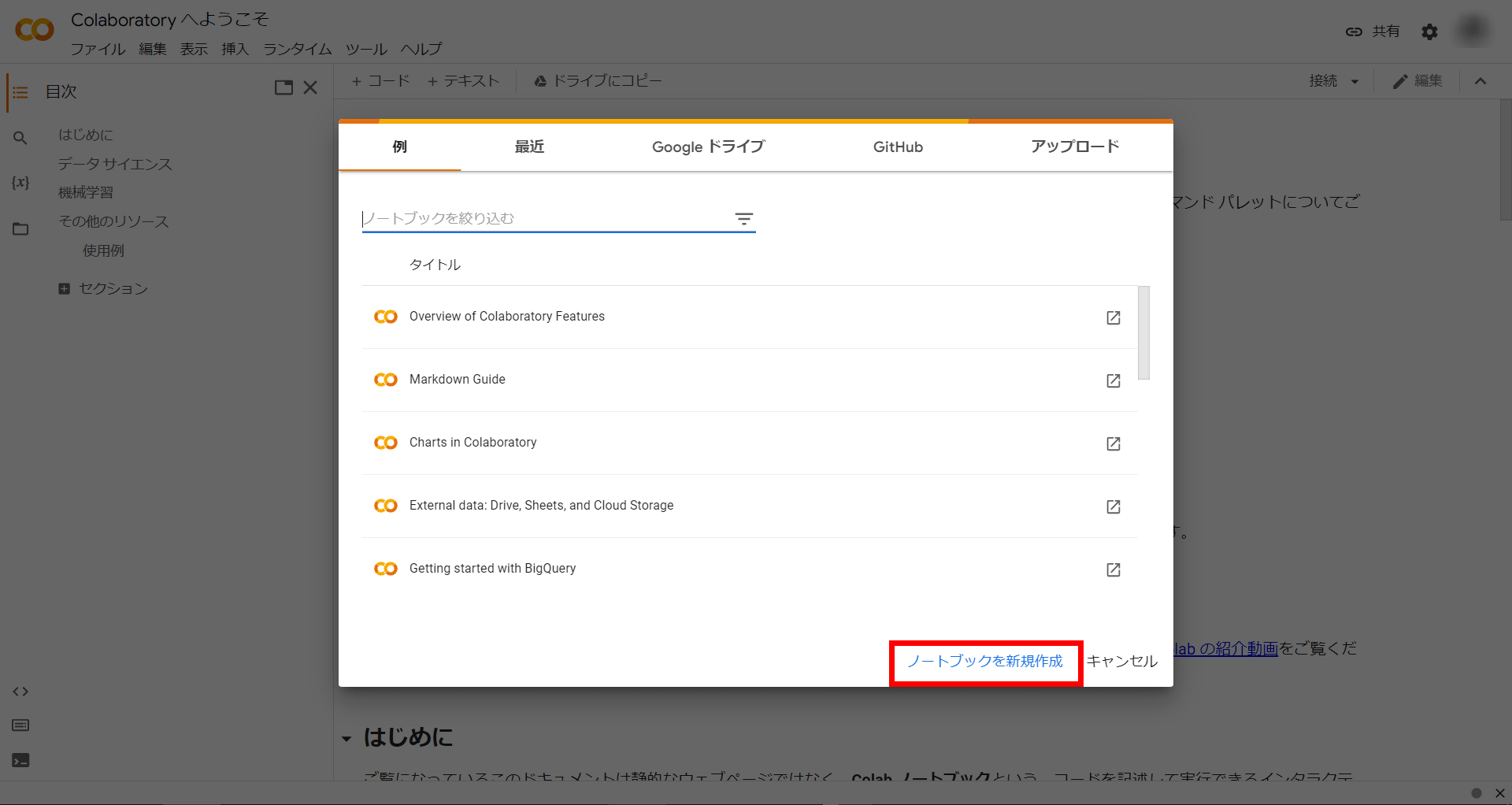
Whisper can be installed in Google Colab, an online execution environment. First, log in to your Google account, access Google Colab, and click 'Create new notebook'.
Click Connect in the top right to connect to the runtime.
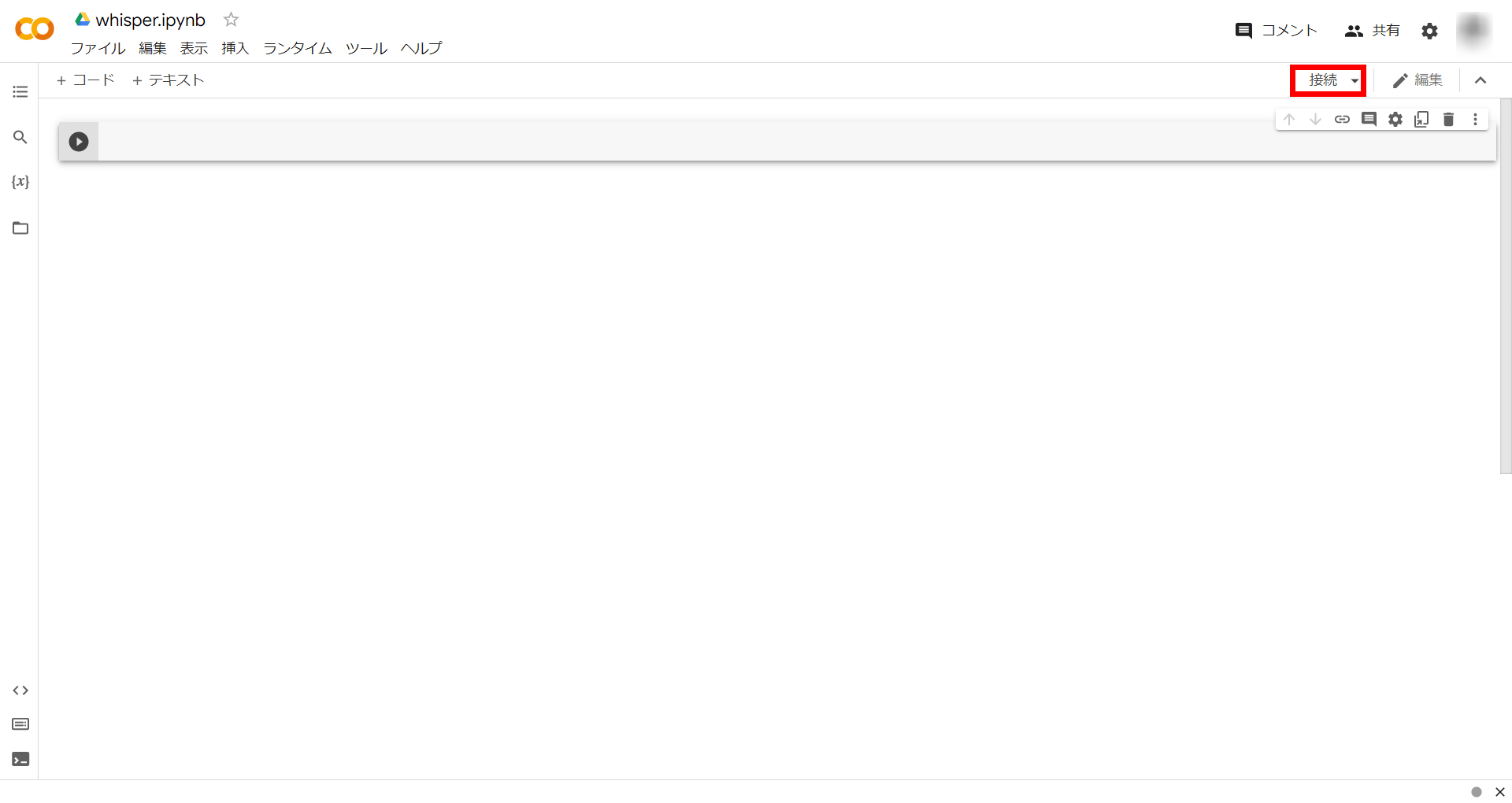
When the connection is complete, click on 'RAM' and 'Disk' and click 'Change runtime type' at the bottom.
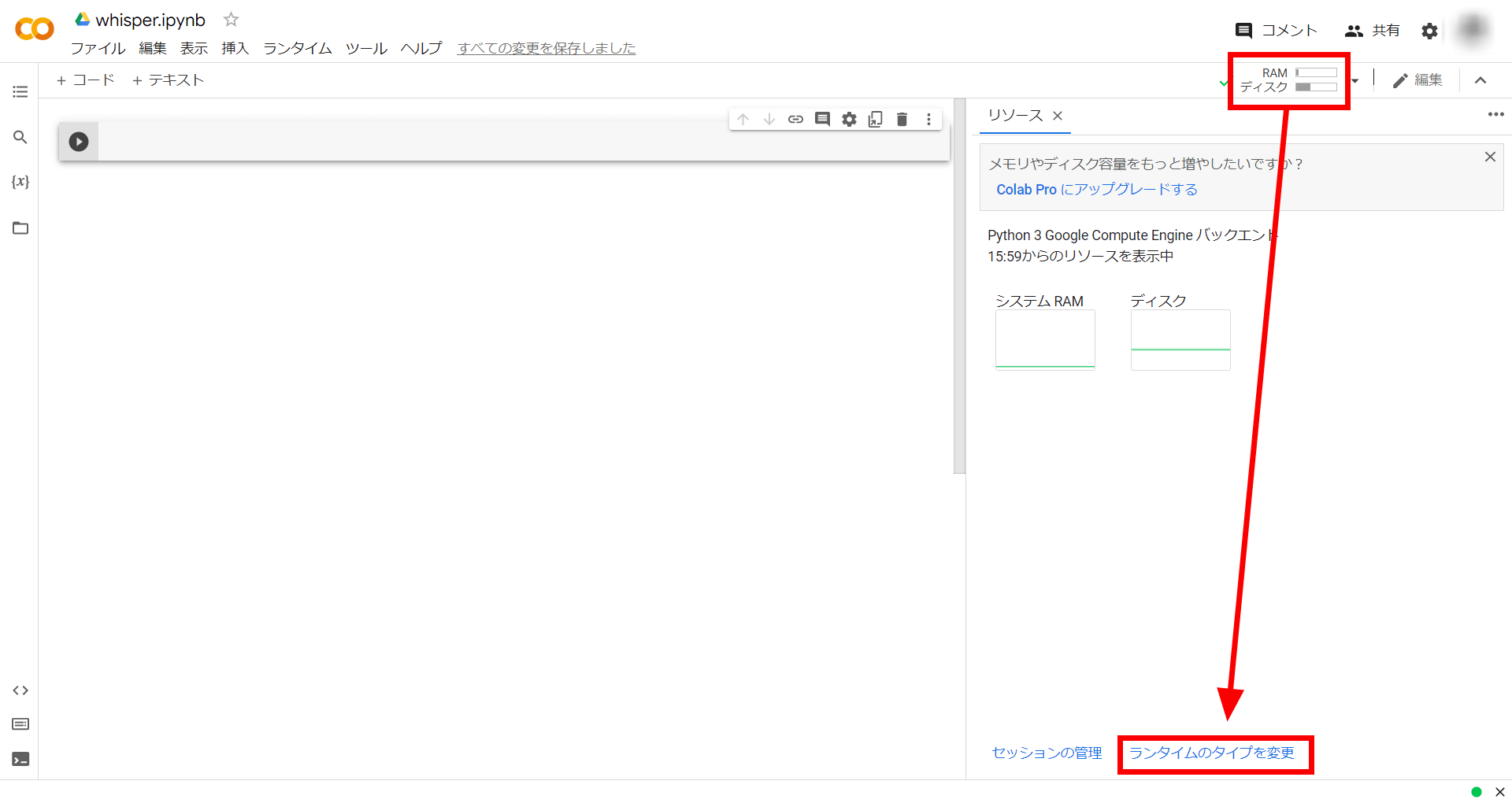
Change the hardware acceleration to 'GPU' and click 'Save'.
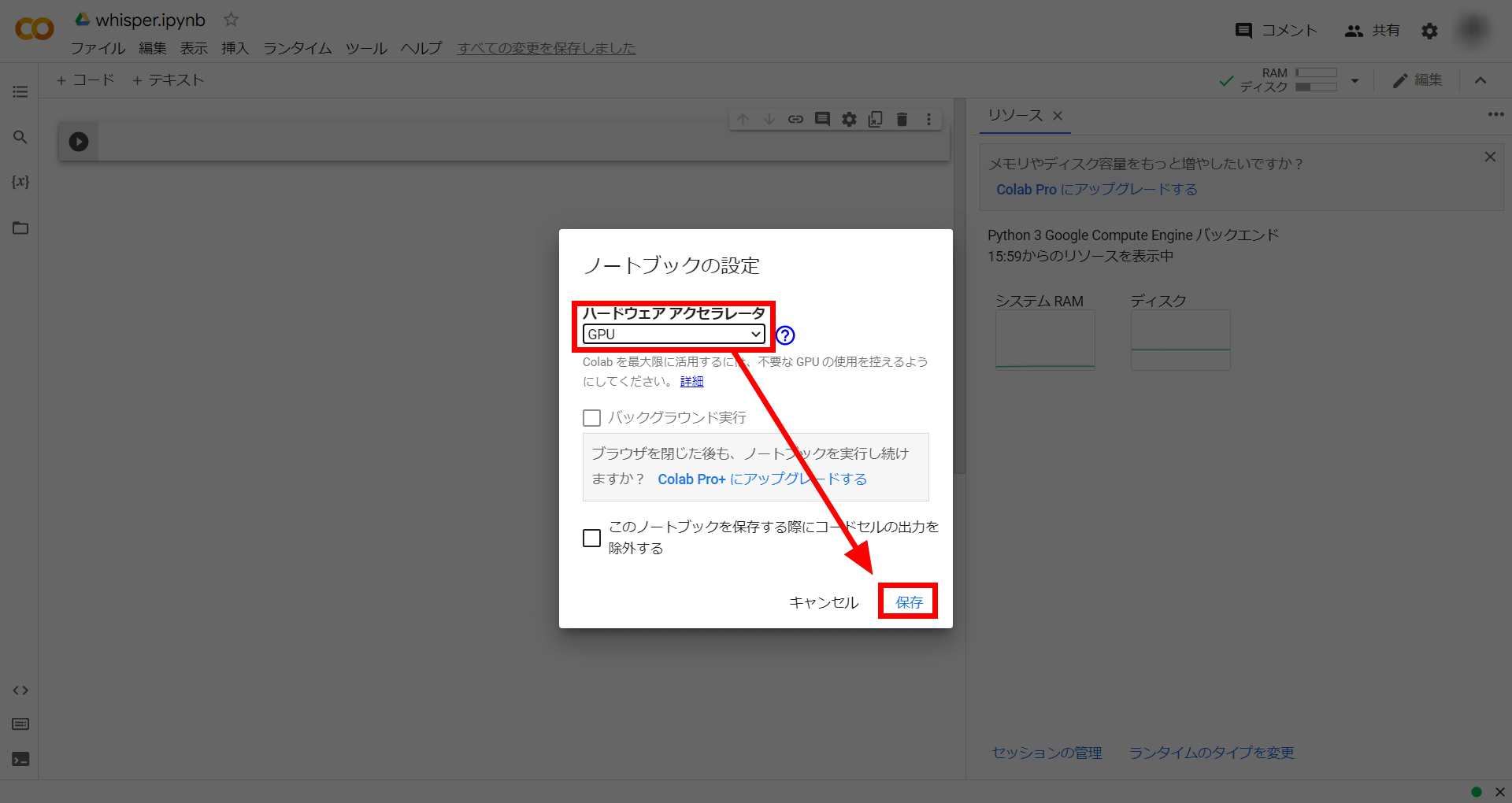
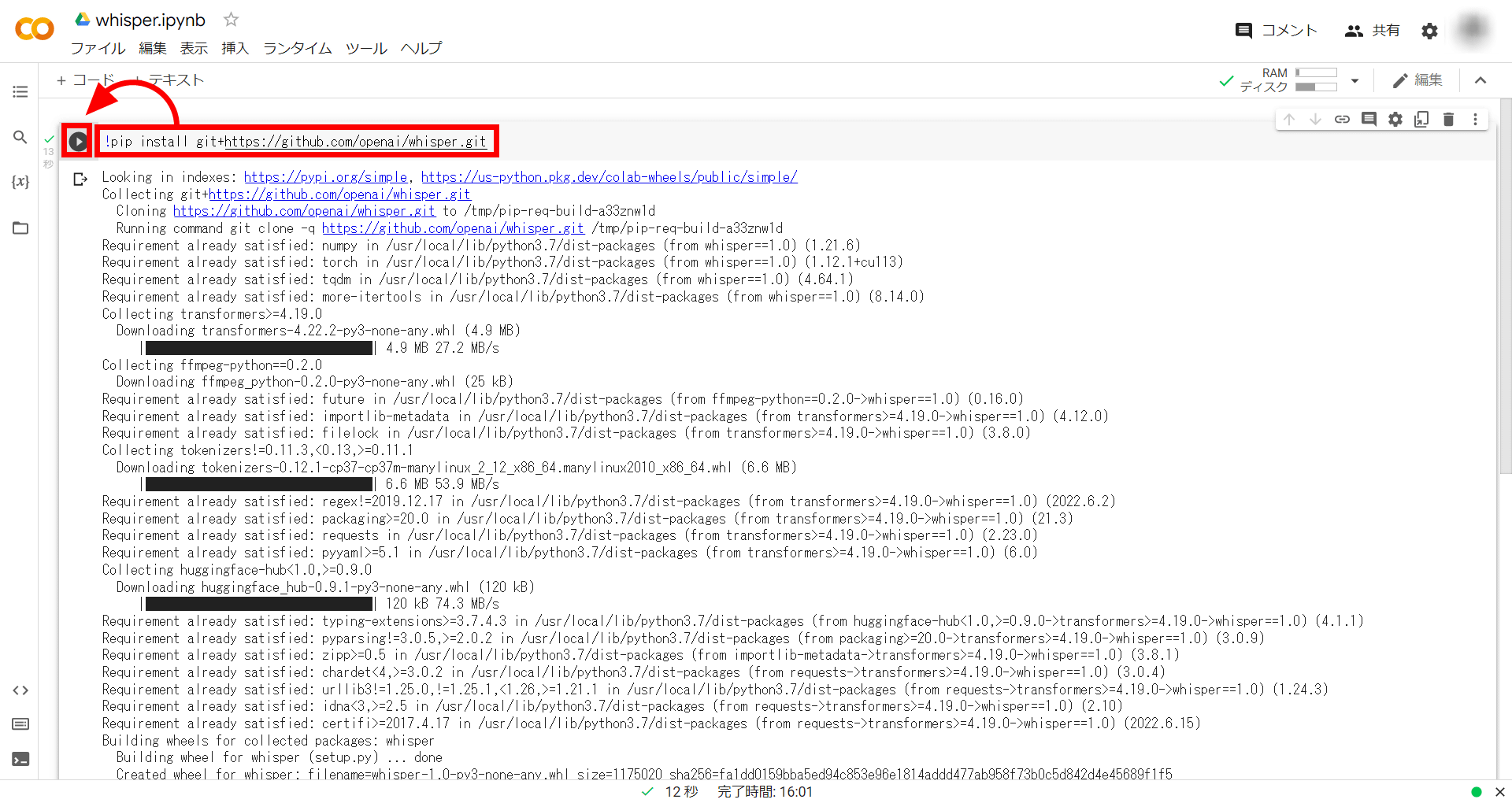
Next is the code. First, enter the following command to install the Whisper repository on Google Colab.
[code]!pip install git+https://github.com/openai/whisper.git[/code]
After entering the command, click the play icon to run it.
Then enter and execute the following command.
[code]import whisper[/code]
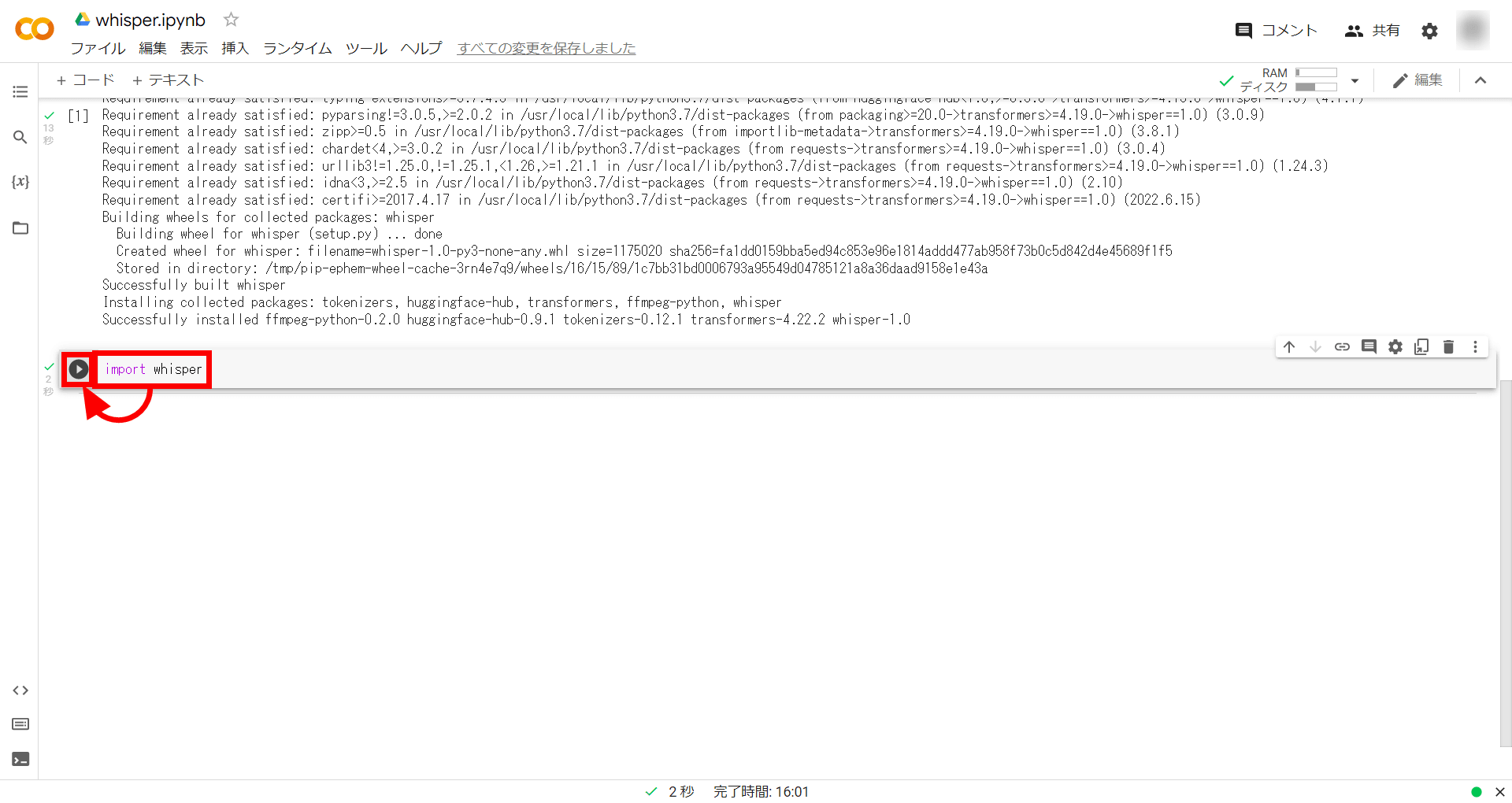
Next, upload the audio file you want to transcribe to Google Colab. Click the folder icon on the far left, then click the kebab icon to the left of the Content folder.
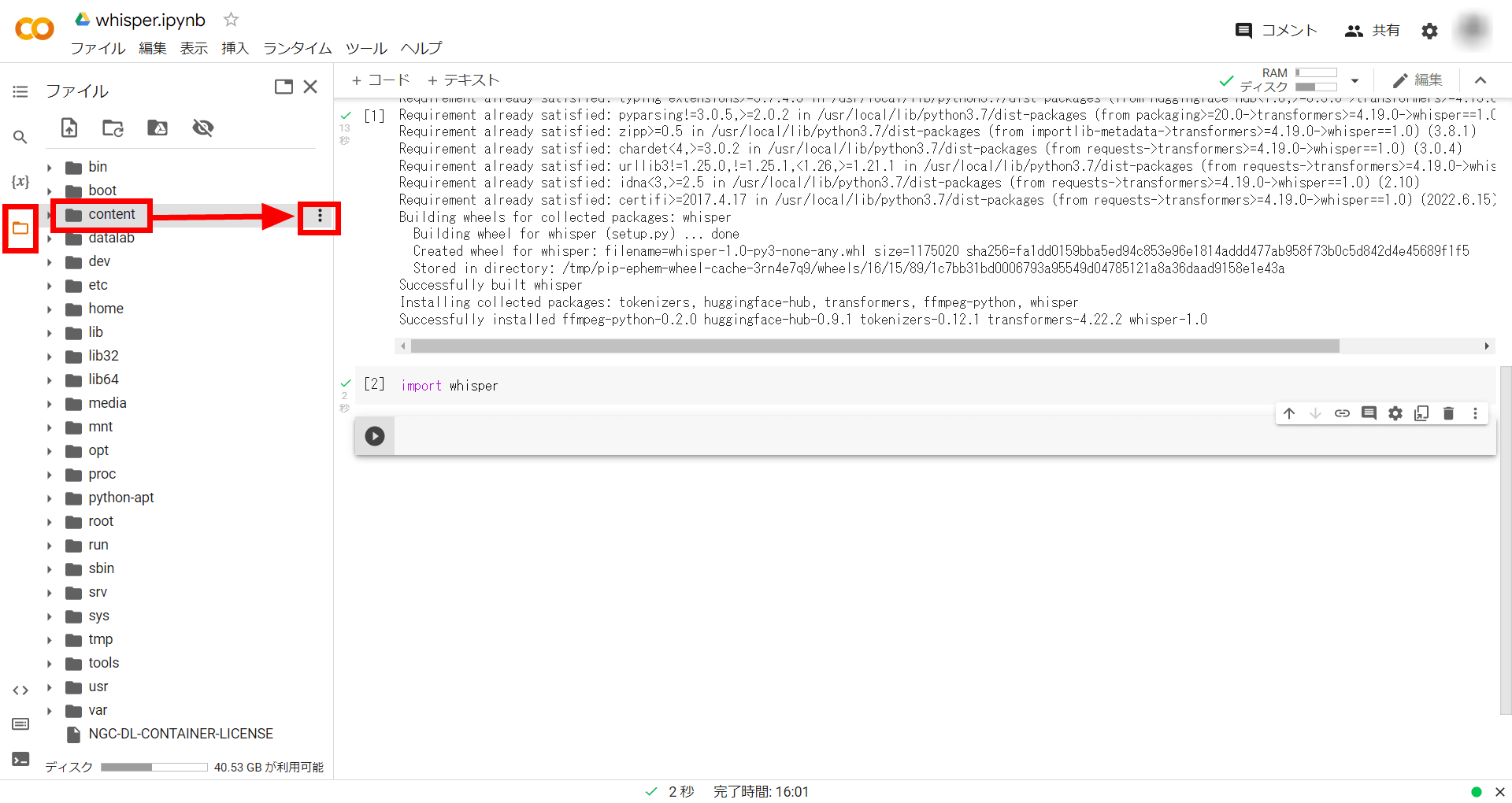
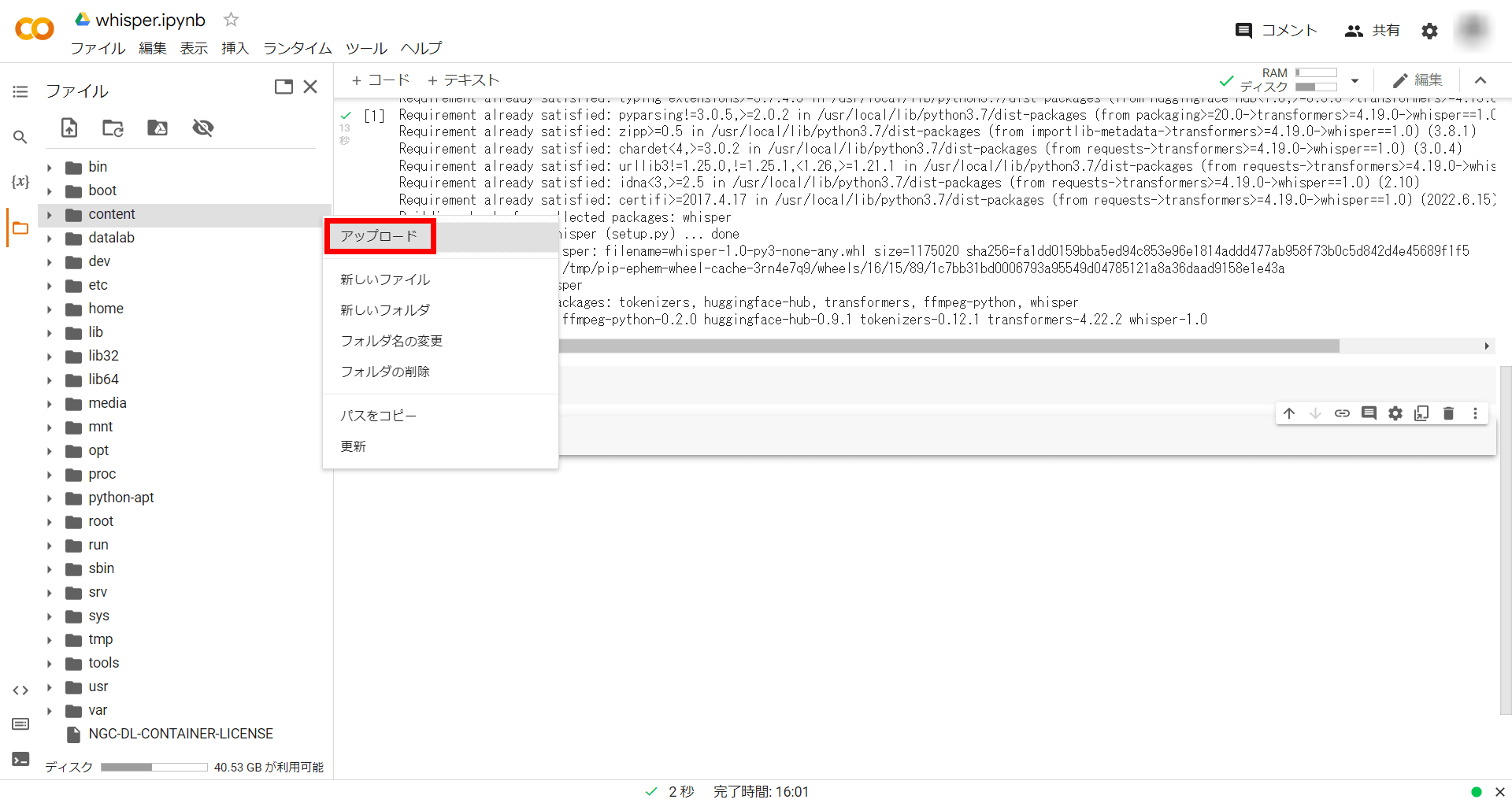
Select 'Upload' and specify the file to upload.
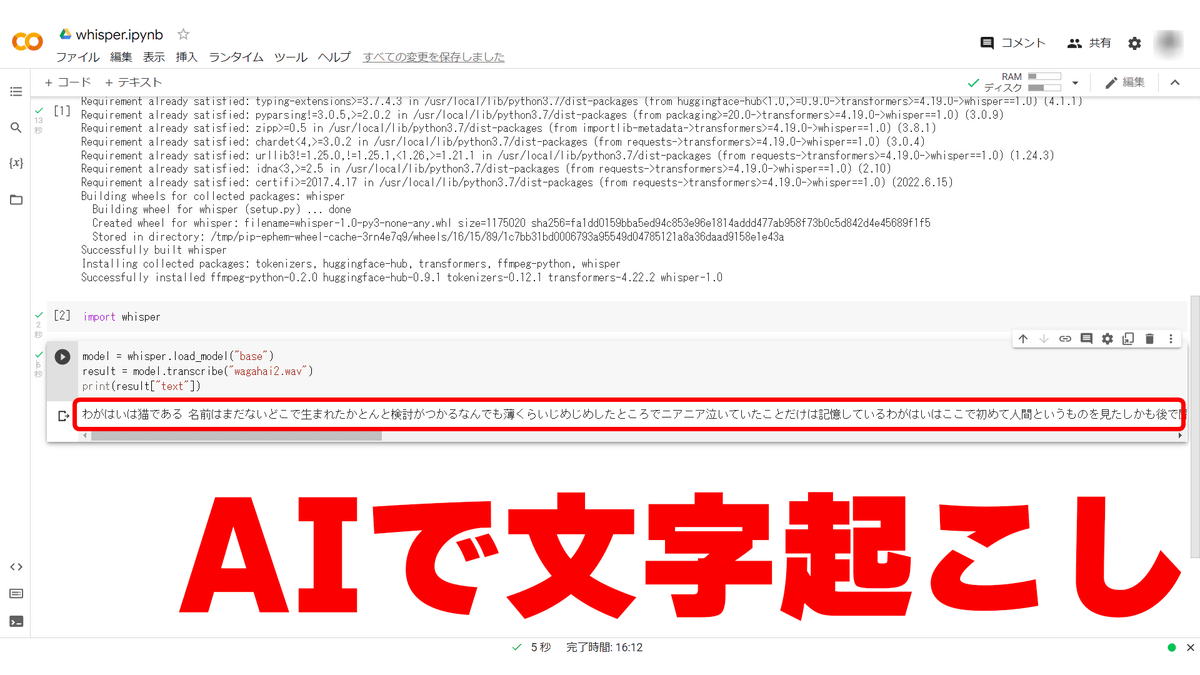
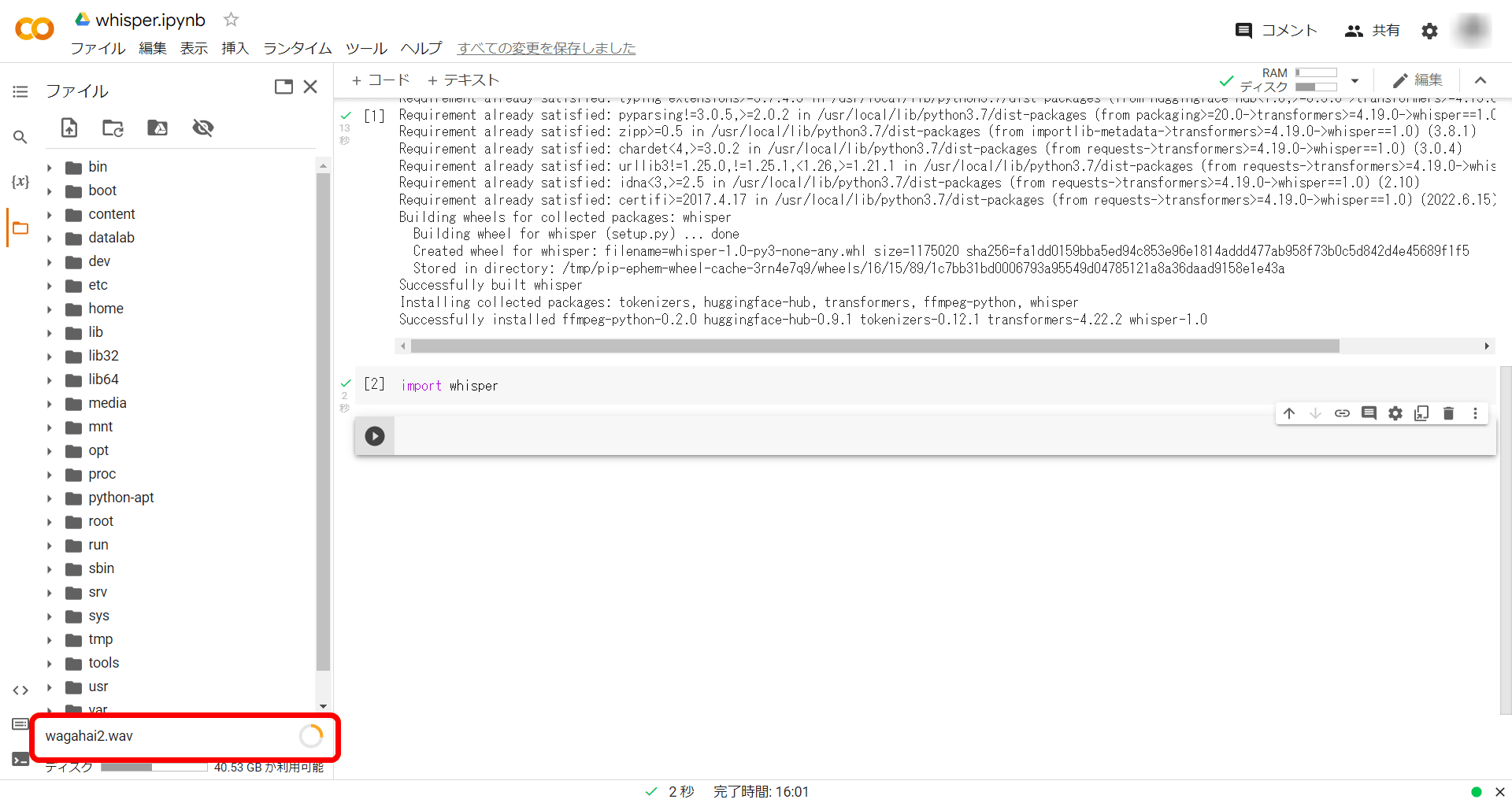
This time, I will transcribe 'wagahai2.wav', which is a recording of the beginning of 'I am a cat'.
Then enter and run the following command. This time we are using 'base' for the model.
[code]model = whisper.load_model('base')
result = model.transcribe('file name')
print(result['text'])[/code]
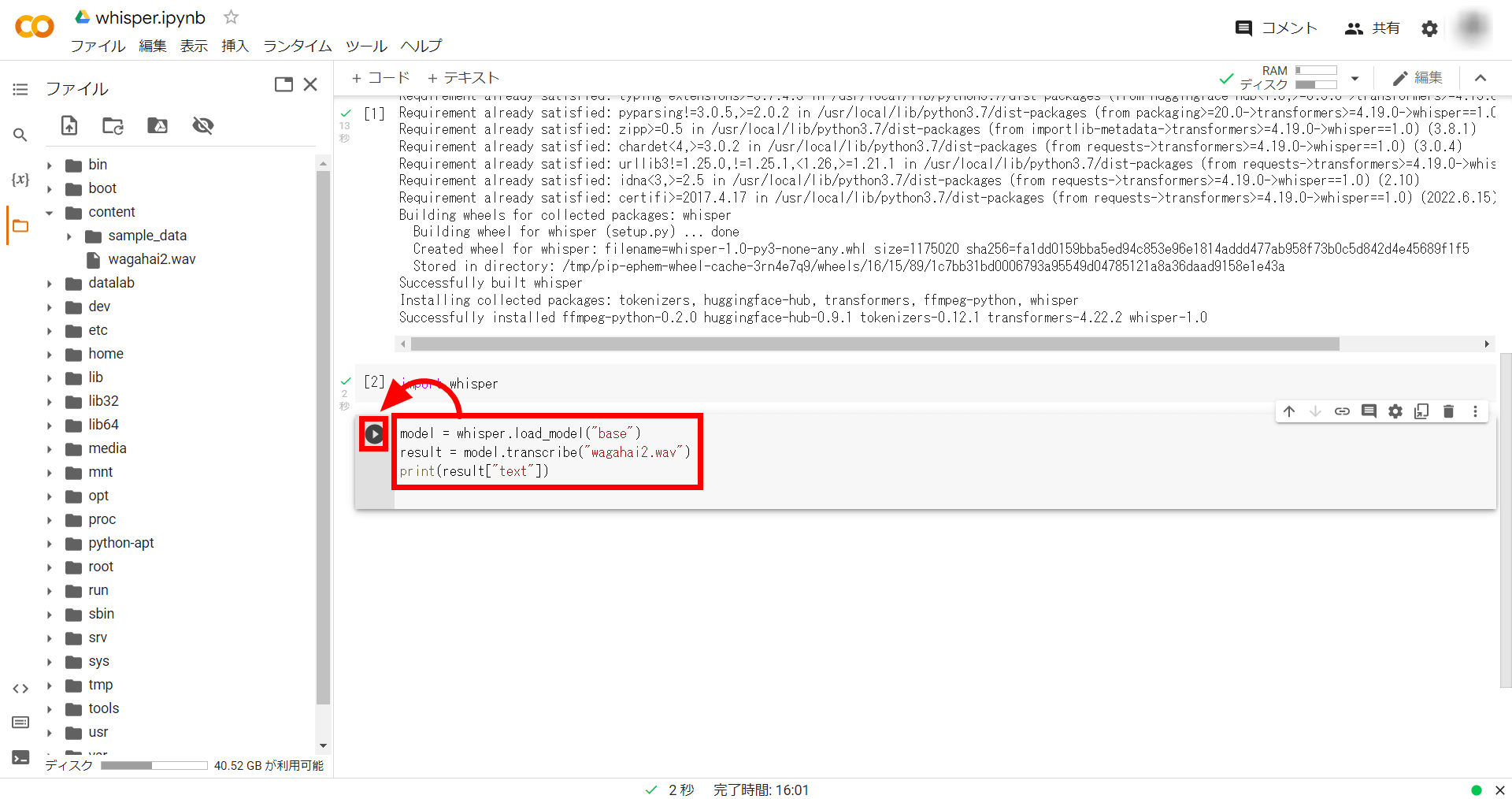
After waiting about 20 seconds, the transcribed text was output as shown below.
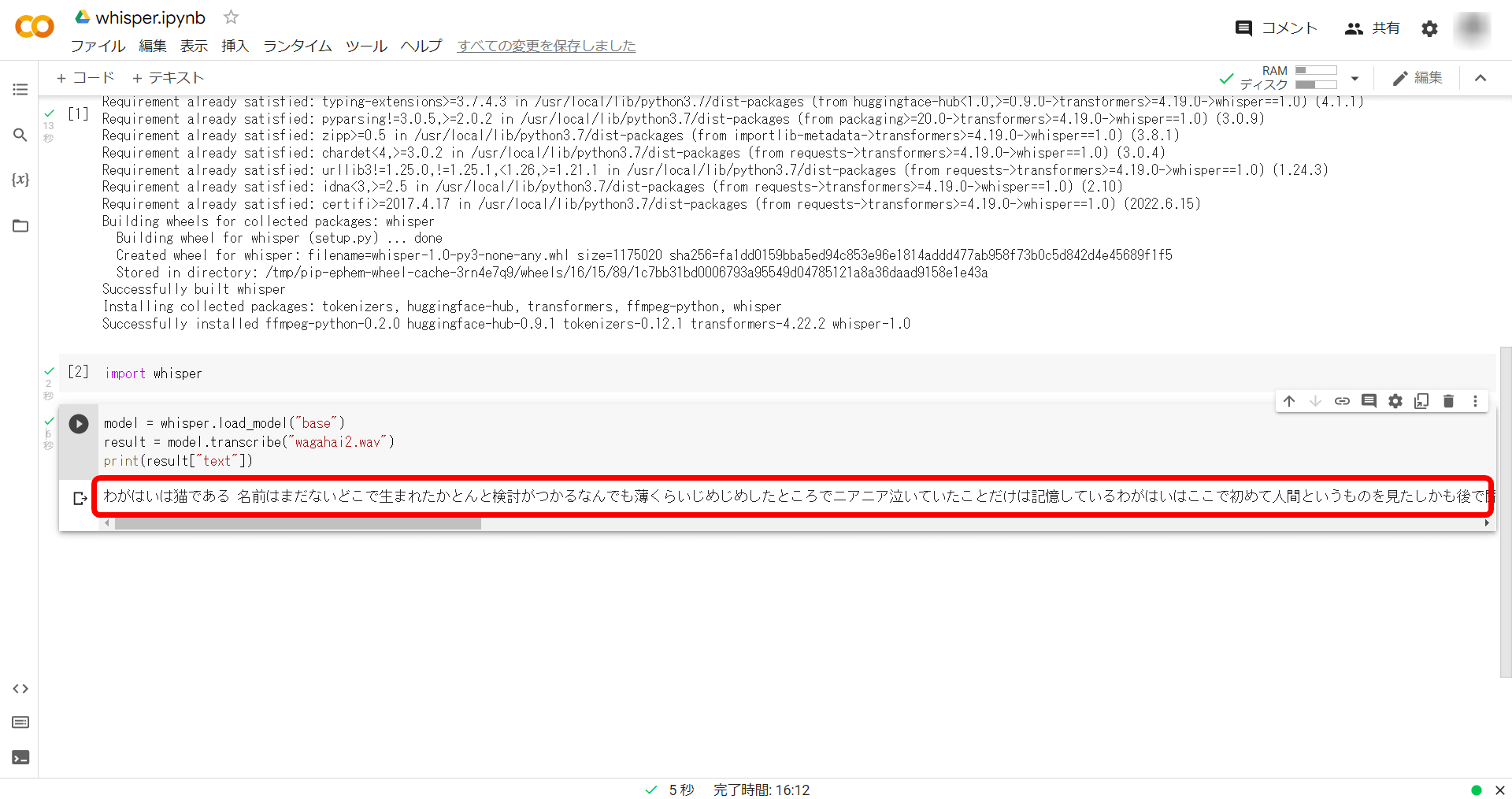
The output result of having Whisper transcribe it is as follows.
My baby is a cat. I don't have a name yet. I have no idea where I was born. All I remember is that I was crying in a slightly damp place. It was here that my baby saw a human for the first time, and later I heard that it was It is said that it was the work of a man called Toronari, who was the most similar to the human being.It is said that this Toronari sometimes catches us and starts to look like us, but at that time there was no idea what it was, so it wasn't particularly frightening. However, when I was placed in his palm and gently lifted up, I felt something fluffy.When I calmed down a little and looked at Tokinari's face, I guess that was when I first started to see what is called a human being. At first, I still feel that it was strange.The face, which should have been decorated with care, was so smooth that it looked like a kettle.After that, it happened to cats quite a bit, but I have never seen someone like this before. I've never broken it with
The original text read is below. Because I read it aloud a little too quickly, the punctuation marks got stuck, and there were also mistakes in the kanji conversion, such as ``kento'' being ``sakari'' and ``shosei'' being ``shosei.'' In addition, there are some misunderstandings such as ``boiled and eaten'' becomes ``similar'' and ``evil race'' is ``handmade by a fellow student,'' but other than that, there are few correction points, so it is quite good as a transcription. It can be said that the accuracy is high.
I am a cat. No name yet.
I have no idea where I was born. All I remember is that I was crying in a dark, damp place. It was here that I saw humans for the first time. Moreover, I heard later that it was the most vicious race of humans known as students. The story is that these students sometimes catch us and boil them. But at that time, I didn't think anything of it, so I didn't think it was particularly scary. However, when he placed me in his palm and lifted me up, I just felt something fluffy. The moment I calmed down a little on the palm of my hand and looked at the student's face was probably the beginning of what I would call a human being. I still have the feeling that I thought was strange at the time. The face, which should have been decorated with first hair, was smooth and looked like a medicine kettle. I've met many cats since then, but I've never met one with a single face like this.
◆Try implementing it in a Windows environment
・Python installation
Download and install the latest version (3.10.7 at the time of writing this article) from the official Python website. The installation method is explained in ' ◆3-1: Installing Python ' in the article below.
Summary of how to install the definitive version 'Stable Diffusion web UI (AUTOMATIC 1111 version)' that allows you to easily run various functions such as image generation AI 'Stable Diffusion' on 4GB GPU & learning your own patterns on Google Colabo and Windows - GIGAZINE

・Installing CUDA
Download and install 'CUDA Tool 11.3' from NVIDIA's developer site. The installation method is summarized in '
Summary of how to install the definitive version 'Stable Diffusion web UI (AUTOMATIC 1111 version)' that allows you to easily run various functions such as image generation AI 'Stable Diffusion' on 4GB GPU & learning your own patterns on Google Colabo and Windows - GIGAZINE

・Installing PyTorch
Install PyTorch, a Python AI framework. First, access the website below.
PyTorch
https://pytorch.org/
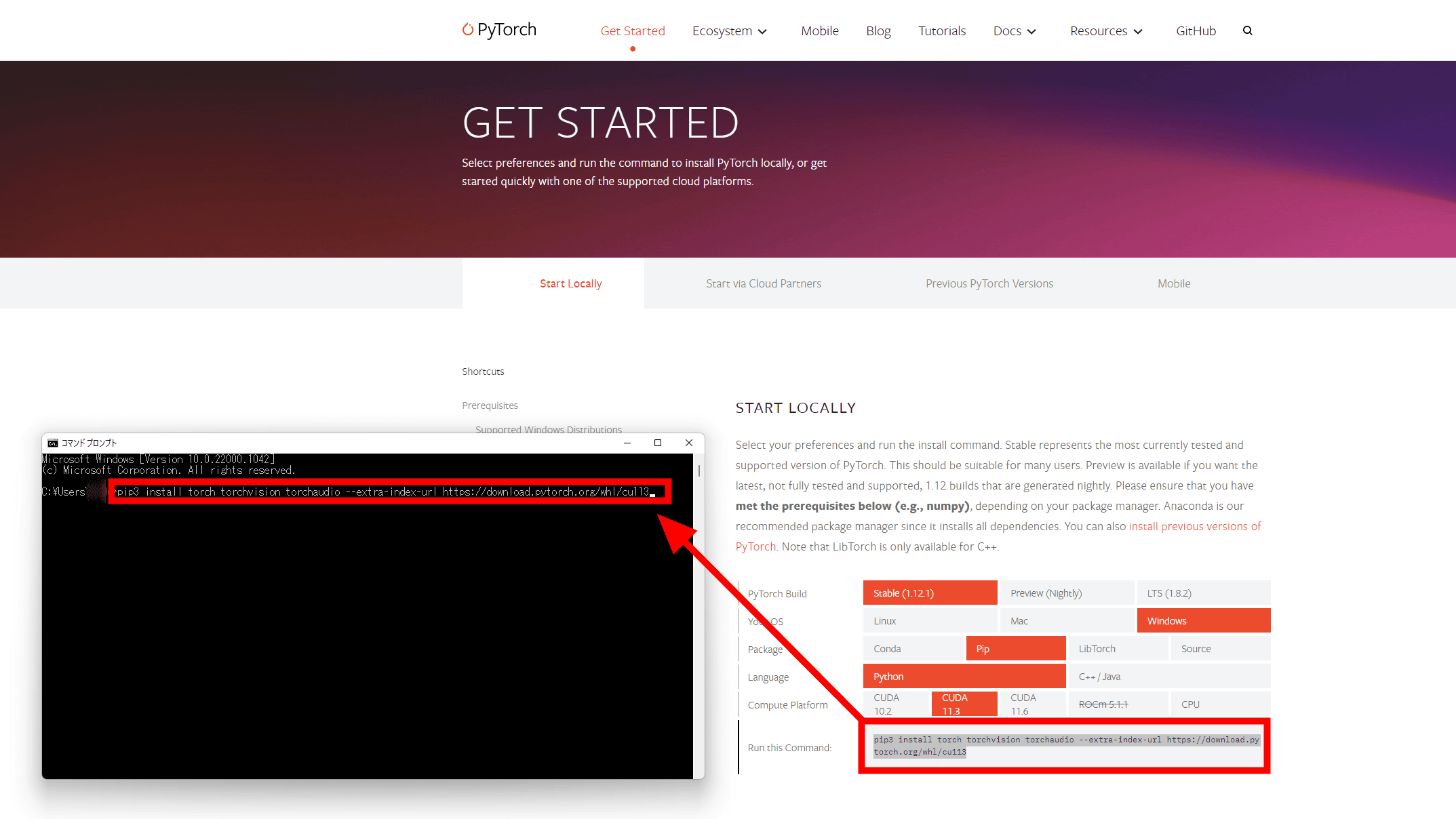
Click 'Install'.
In 'START LOCALLY', set PyTorch Build to the stable version 'Stable(1.12.1)', OS to 'Windows', Package to 'Pip' to use the command prompt, Language to 'Python', Compute Platform to 'CUDA'. 11.3”.
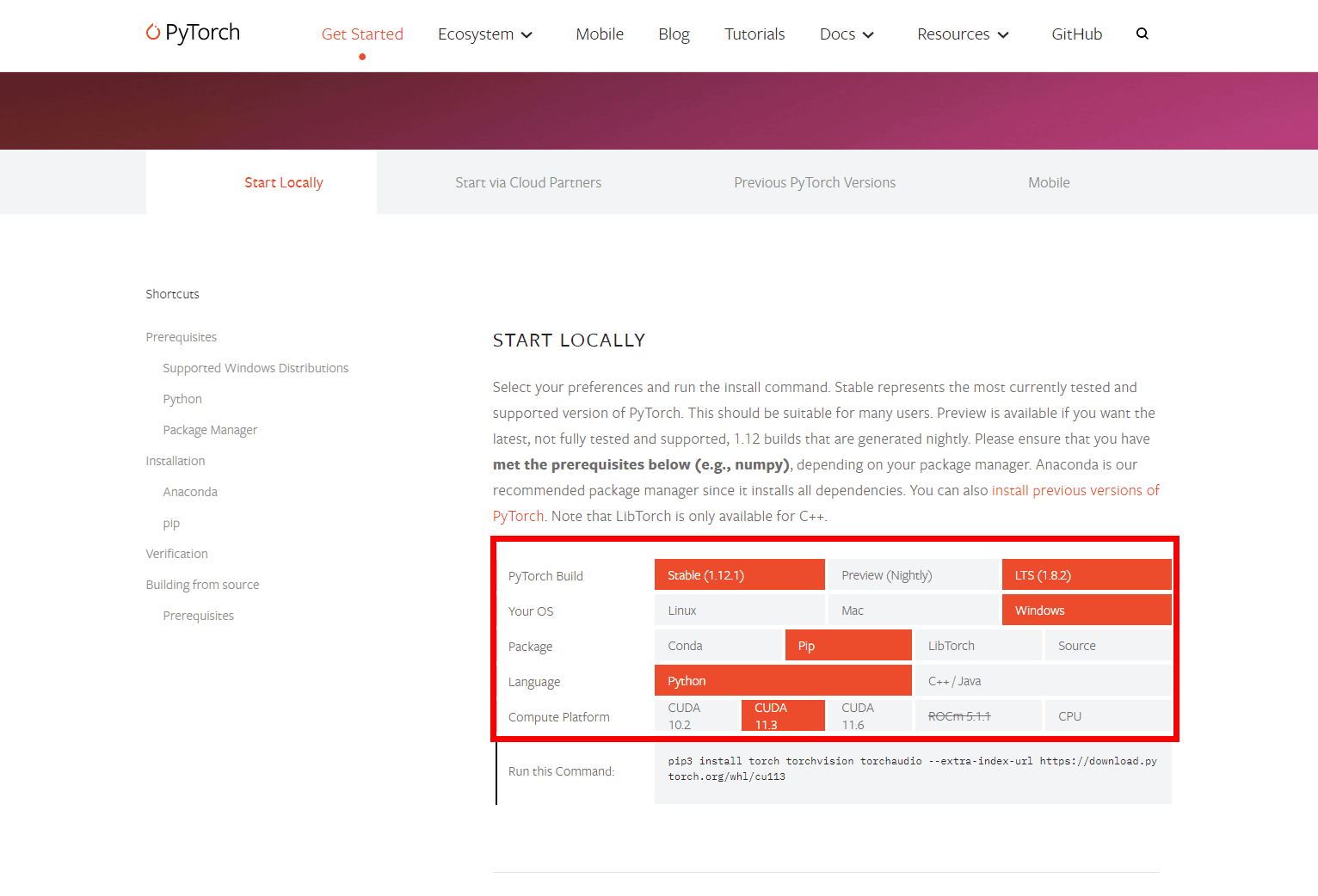
You can install PyTorch by copying the command displayed in 'Run this Command:' at the bottom and running it at the command prompt.
・Installing ffmpeg
Install ffmpeg to process audio and video. ffmpeg is installed using the package management software Chocotray.
Chocolatey Software | Chocolatey - The package manager for Windows
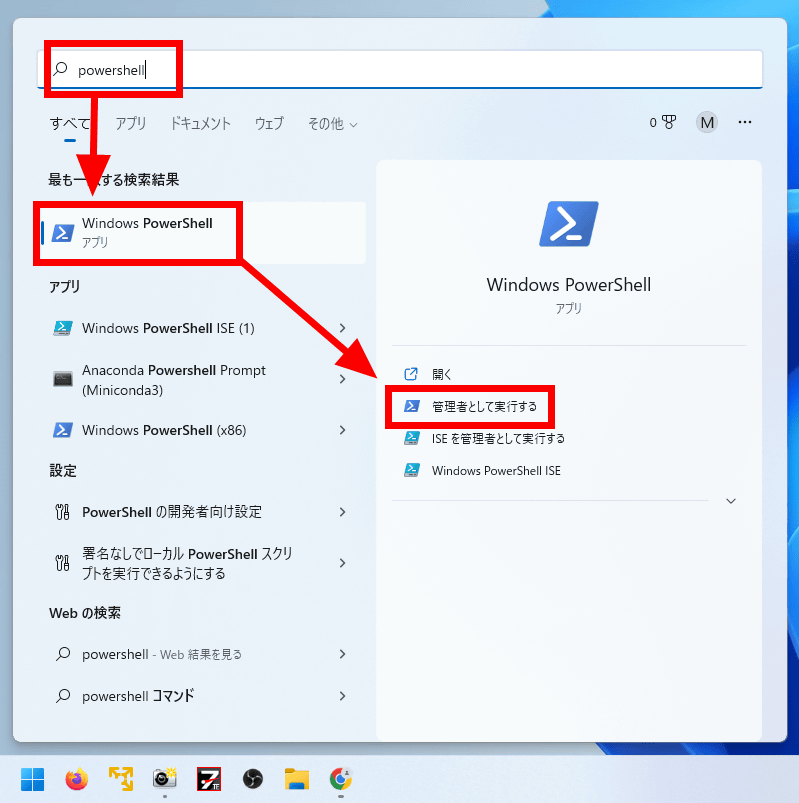
Install Chocotray from Windows PowerShell. If you type 'powershell' in the Windows start menu, it will appear, so run it as an administrator.
Then, enter the following command in Windows Powershell.
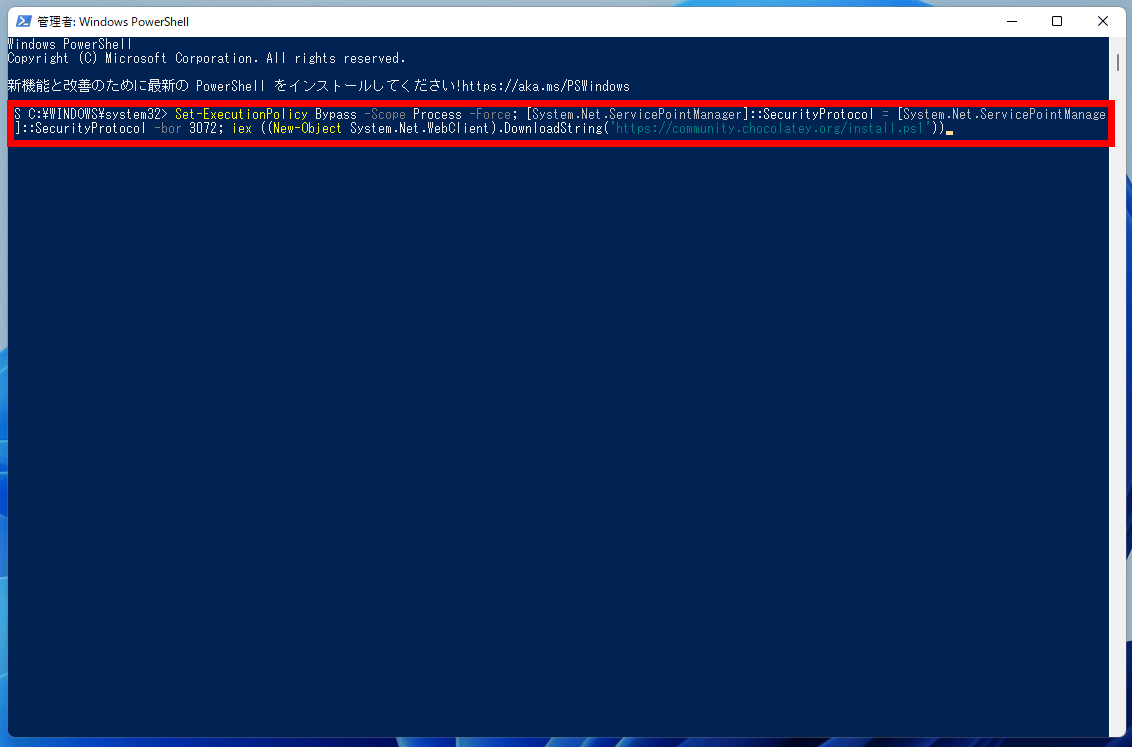
[code]Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient). DownloadString('https://community.chocolatey.org/install.ps1'))[/code]
It looks like this when you input it. Press Enter to run.
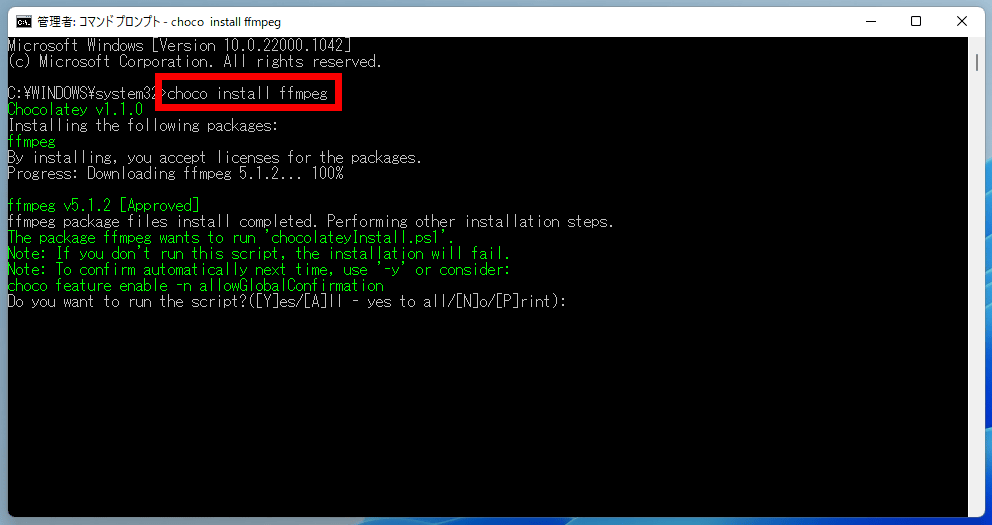
After installing Chocotray, enter the following command at the command prompt and execute it.
[code]choco install ffmpeg[/code]
ffmpeg will now be installed.
Next, turn on Windows developer mode. Launch Windows Settings.
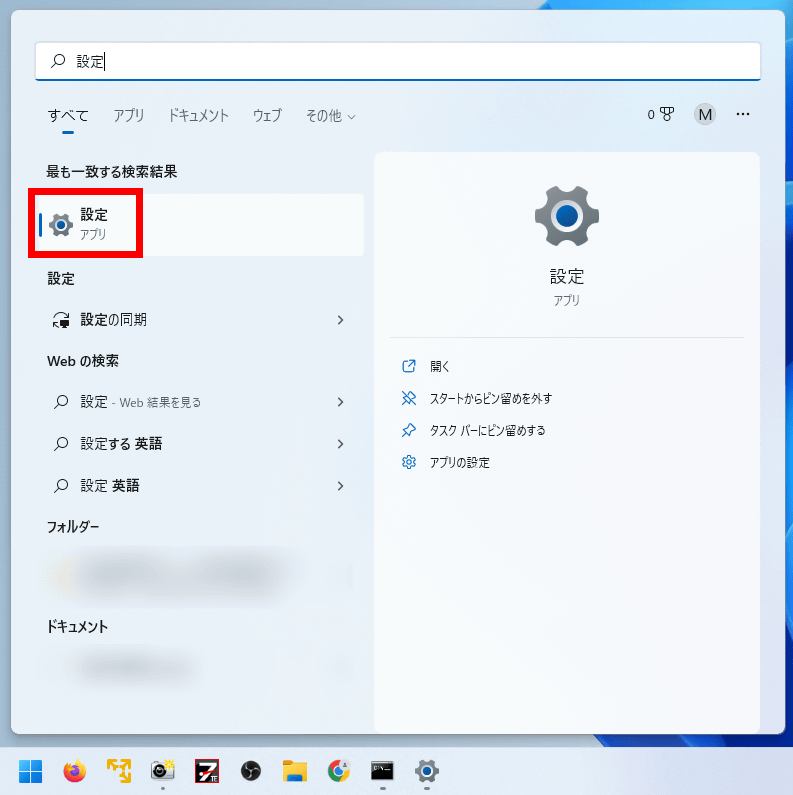
Click 'For developers' under 'Privacy and Security'.
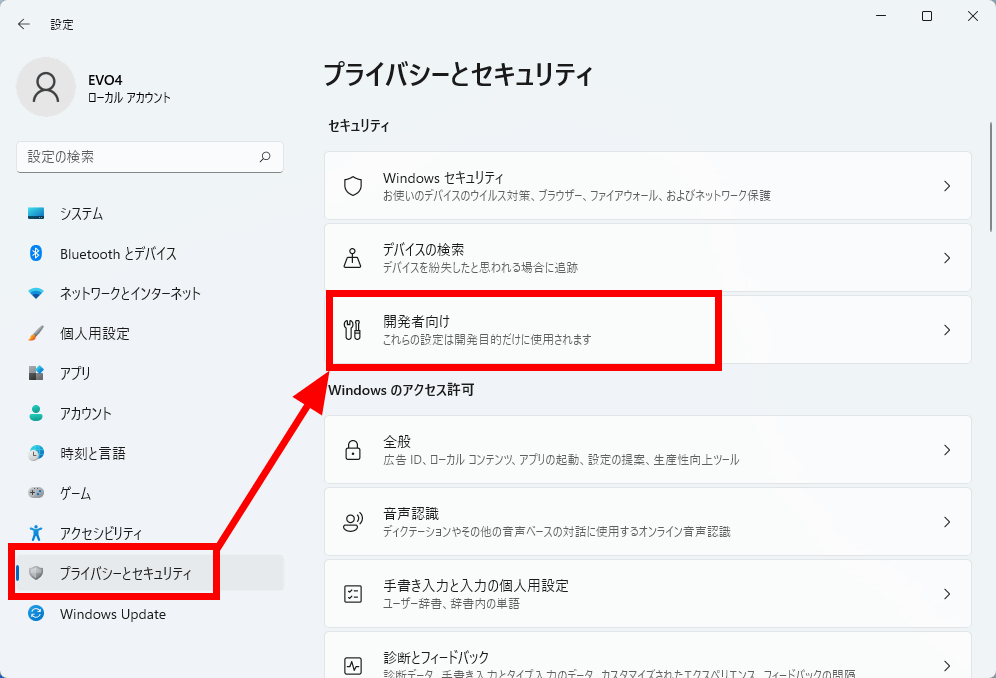
Toggle the 'Developer Mode' switch on.
・Installing Whisper
Finally, type the following at the command prompt and run it.
[code]pip install git+https://github.com/openai/whisper.git[/code]
This is what it looks like when you enter it
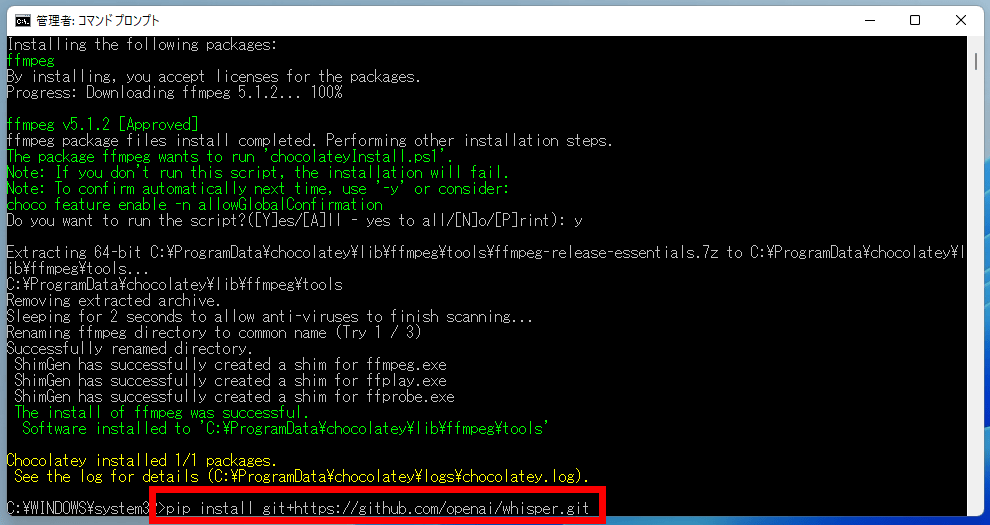
The installation of Whisper is now complete.
◆Try transcribing with Whisper installed on Windows
First, prepare the audio file you want to transcribe. This time, I created a folder called 'whisper-sound' on the desktop and placed wagahai2.wav.
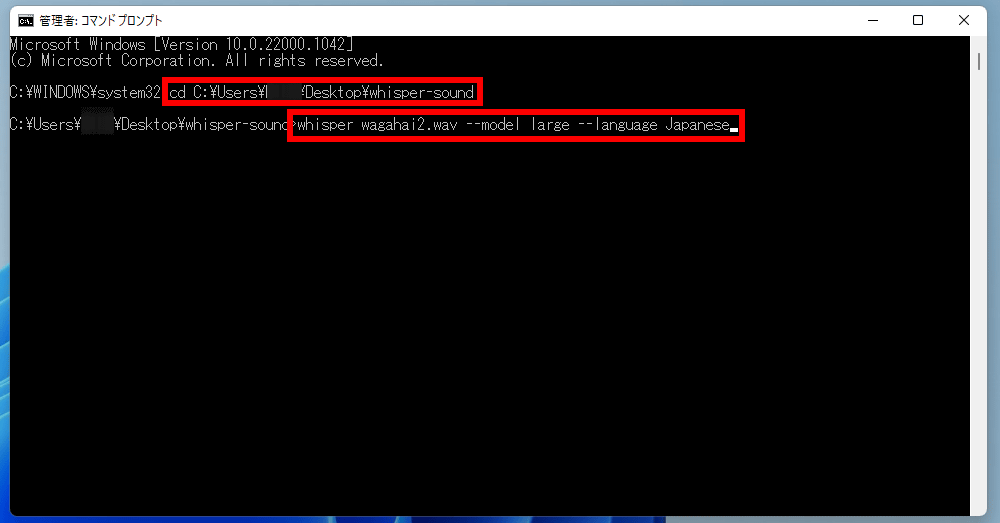
Run the command prompt as administrator,
cd C:\Users\(username)\Desktop\whisper-sound
Type this to change the directory to the folder you created earlier. Then enter the following command.
[code]whisper (file name) --model (model name) --language Japanese[/code]
When I used Google Colab, I used the base model to transcribe, but this time I'm using the local Windows environment, so I'll transcribe using the largest model, large. Enter ' whisper wagahai2.wav --model large --language Japanese ' and execute.
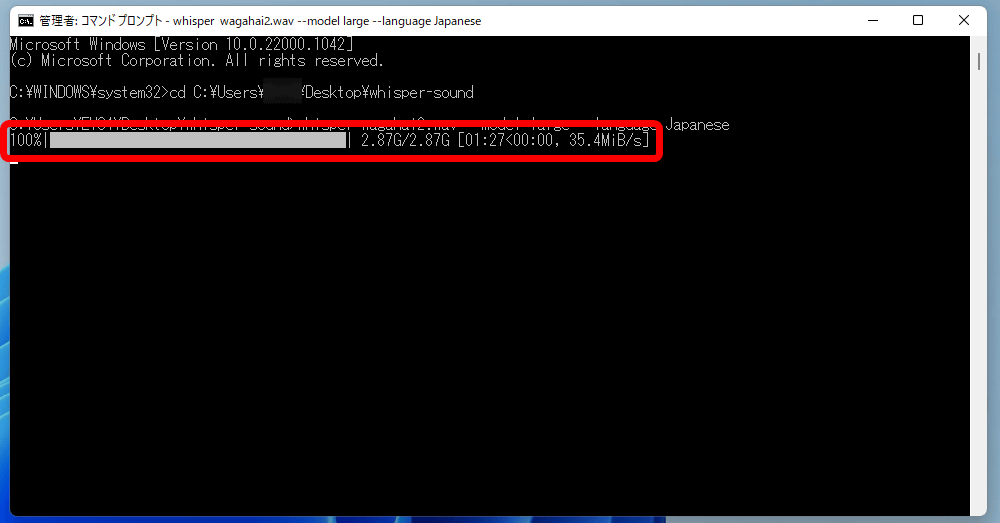
First the model data is loaded. The largest model, Large, is 2.87GB.
After that, the transcribed content will be displayed in the command prompt. Although the sound source is 1 minute and 6 seconds long, it took about 30 to 40 seconds to transcribe it, excluding the loading time of the model.
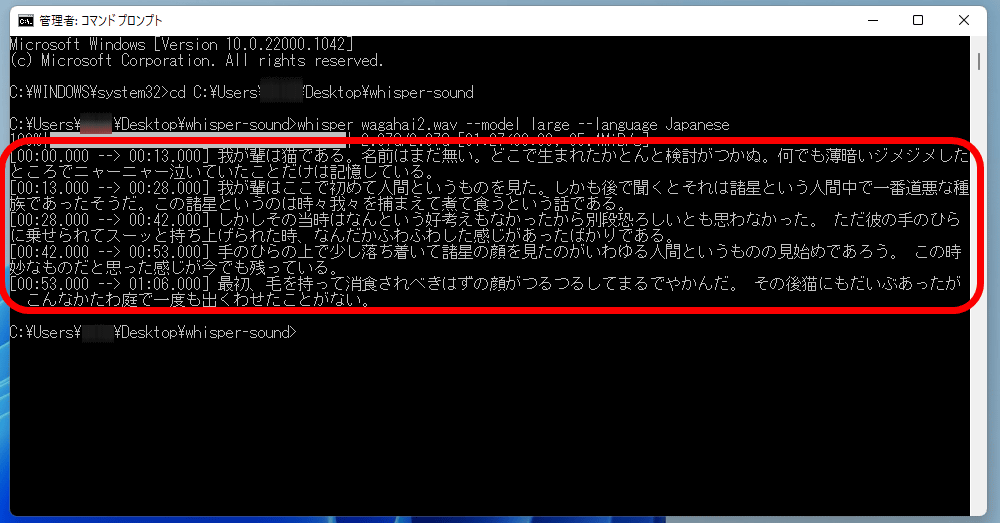
Once completed, a transcription text file will be output to the same directory as the audio source.
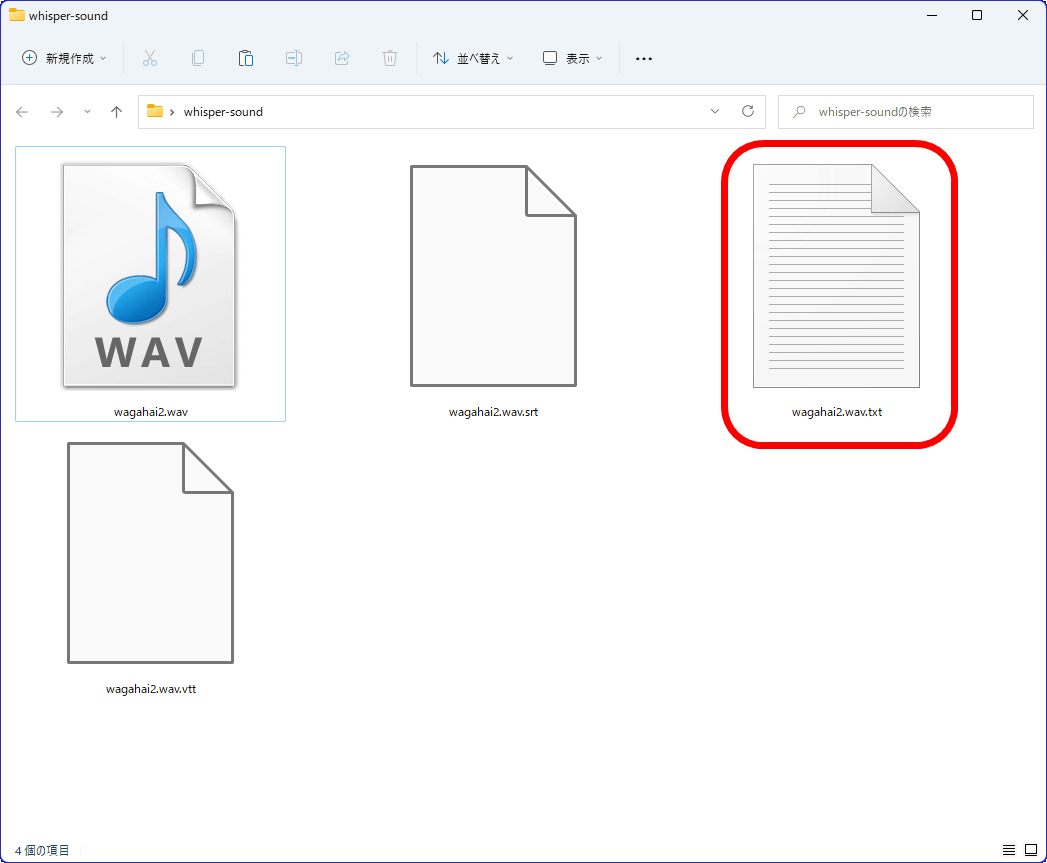
The transcript is as follows. Compared to the original text, although there were some kanji conversion errors, there were very few parts that needed to be revised, the transcription was smooth, and I felt that the accuracy was high. Although the large model has a large workload and takes time to process transcription, it has the highest transcription accuracy.
My cousin is a cat. No name yet. I have no idea where it was born. All I remember is that I was crying in a dark, damp place.
It was here that my class saw humans for the first time. Moreover, I heard later that it was Moroboshi, the most evil race of humans. The story goes that these Moroboshi sometimes catch us, boil them, and eat us.
But at the time, I didn't have any good ideas, so I didn't think it was particularly scary. However, when he placed it in his palm and lifted it up, it just felt fluffy.
When I calmed down a little and looked at Moroboshi's face on the palm of my hand, I guess that was when I first began to see what is called a human being. I still have the feeling that I thought was strange at the time.
At first, the face, which should have been eaten away with hair, was so smooth that it looked like a kettle. I've had many cats since then, but I've never encountered one in a garden like this.
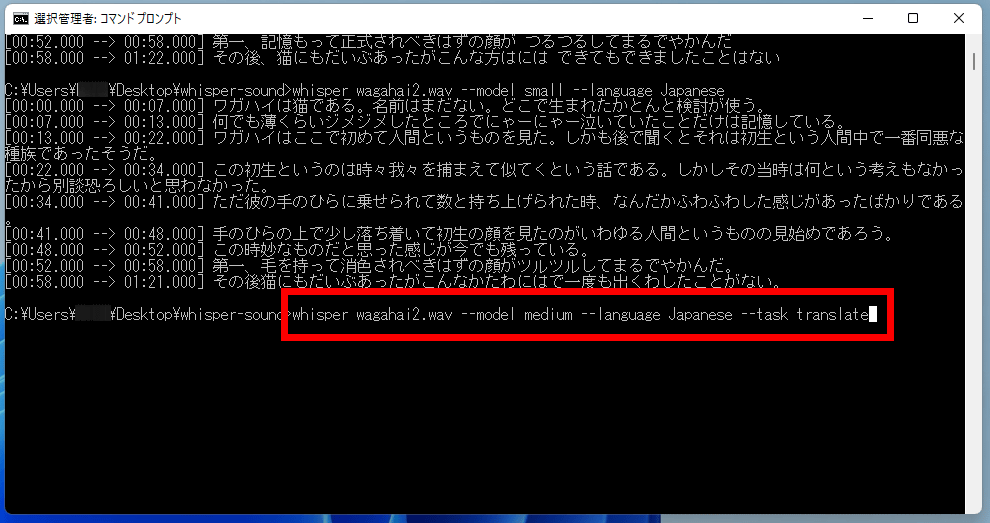
In addition, when you transcribe the same wagahai2.wav with the small model, which is the middle size among the five models, it looks like this. Although there are some mistakes here and there, it is transcribed to a level that allows it to be read as Japanese. However, the accuracy seems to be poor compared to the large model.
Wagahai is a cat. there is no name yet. It is used to consider where you were born.
All I remember is that I was crying when everything got slightly damp.
It was here that Wagahai saw humans for the first time. What's more, I heard later that it was the first generation, the most evil race among humans.
This first generation is a story that sometimes catches us and resembles us. However, at that time I had no idea what was going on, so I didn't think it was scary.
However, when he placed it in his palm and lifted it up, it just felt fluffy.
When I calmed down a little and looked at the face of the first generation in the palm of my hand, it was probably the first time I saw what we call a human being.
I still have the feeling that I thought was strange at the time.
First, his face, which should have been completely bleached with hair, was so smooth it looked like a kettle.
I've had a lot of cats since then, but I've never come across one like this.
Below is the result of transcription using the smallest tiny model. In addition to ignoring punctuation marks, the accuracy of kanji conversion is also quite low.
I'm fast as a cat. I don't have a name yet.
It's easy to think about where it was born, and it's always a damp place.
All I remember is that it was meowing. This was the first time my son saw a human being.
What's more, I heard later that it was a first-time work, and it was the handiwork of someone from the same school as most of all humans.
This first nature is a story that sometimes catches hold of us and makes us resemble each other.
But at that time, I had no idea what it was, so it wasn't all that scary.
However, when I was placed on his palm and lifted up, I just felt a fluffy feeling.
When I calmed down a little and looked at the first person's face in the palm of my hand, that's when I began to see what we call humans.
I still have the feeling that I thought it was something to see at that time.
First, my face, which should have been formalized with memory, was so smooth it looked like a kettle.
After that, I had a lot of problems with cats, but I've never been able to do it with someone like this.
Whisper can not only transcribe, but also translate. For example, the command to transcribe Japanese audio into Japanese and then translate it into English is as follows.
[code]whisper (file name) --model (model name) --language Japanese --task translate[/code]
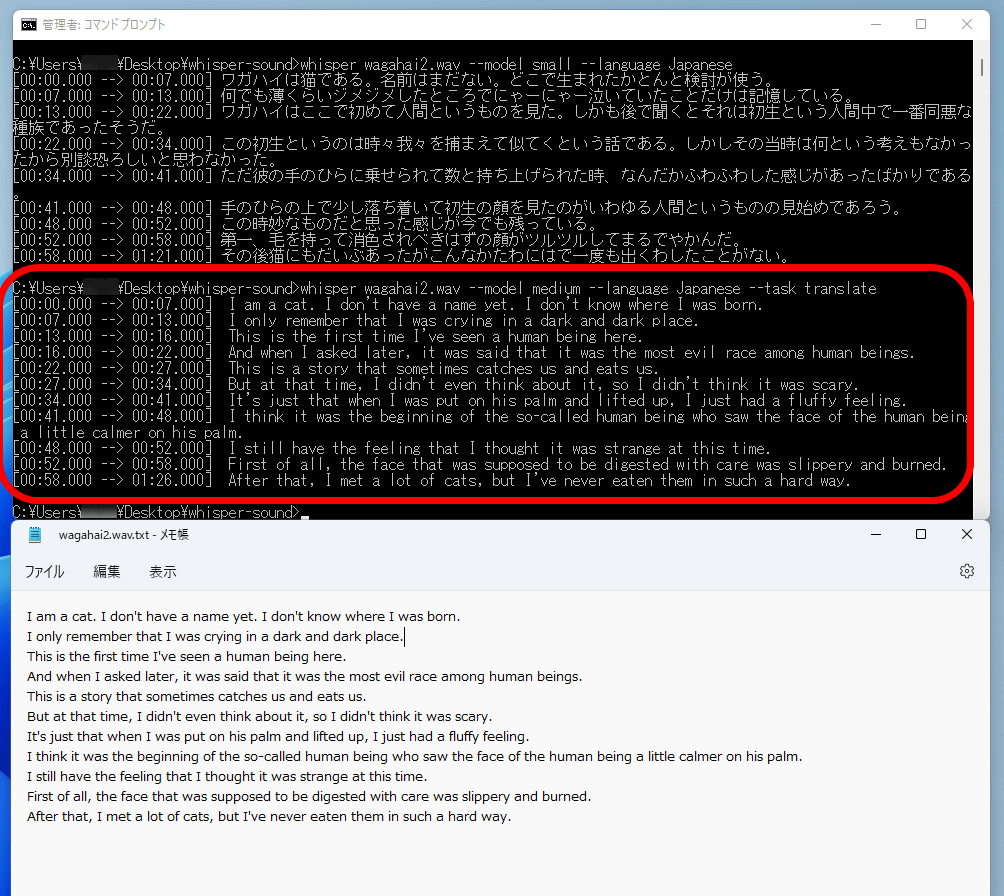
For example, if you enter ' whisper wagahai2.wav --model medium --language Japanese --task translate ' and run it...
Like this, after being transcribed into Japanese, it was automatically translated into English. Only the English translation remains in the output text.
Related Posts:


in Free Member, Software, Web Service, Review, Web Application, Posted by log1i_yk