OpenAI revamps the ``embedded model'' used for dialogue AI and image generation AI, and the price per performance is 99.8% cheaper
OpenAI, an AI development organization, has announced an embedding model `` text-embedding-ada-002 '' that converts text and images into numbers. The text-embedding-ada-002 has significantly improved functionality, higher cost performance, and is easier to use than the conventional model.
New and Improved Embedding Model
Embeddings - OpenAI API
https://beta.openai.com/docs/guides/embeddings
In order for algorithms to recognize text and images, they must be converted into numerical data. Embedding is the process of converting text and images into some kind of vector, and is an indispensable technology for recent natural language processing models and image generation AI.
To access text-embedding-ada-002, specify 'text-embedding-ada-002' as the model name in ' OpenAI Python Library ' that can hit OpenAI's API with Python OK. Below is the code for converting the string 'porcine pals say' to a numerical value.
[code]import openai
response = openai. Embedding. create(
input='porcine pals say',
model='text-embedding-ada-002'
)[/code]
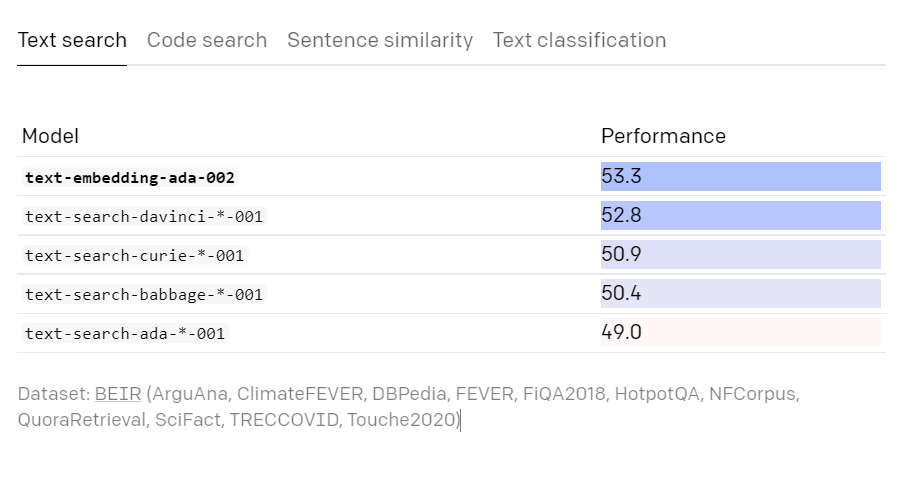
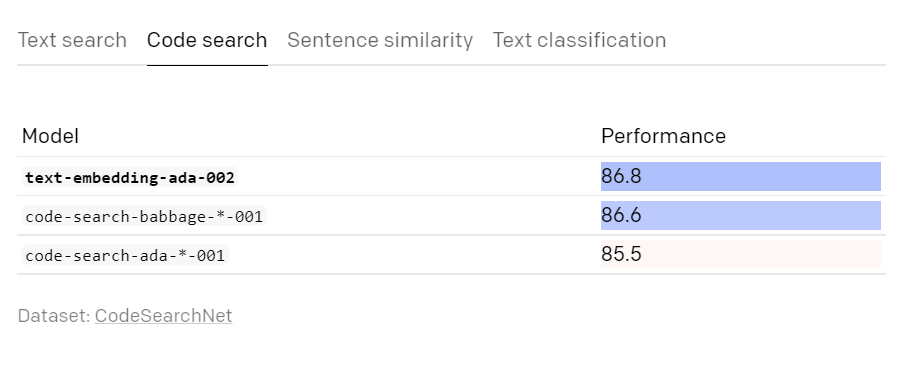
According to OpenAI, text-embedding-ada-002 outperformed the conventional model in terms of text search, code search, and sentence similarity, and demonstrated the same performance as before in text classification.
Below is a comparison of text searches. The higher the 'Performance' number, the better the performance.
code search
sentence similarity
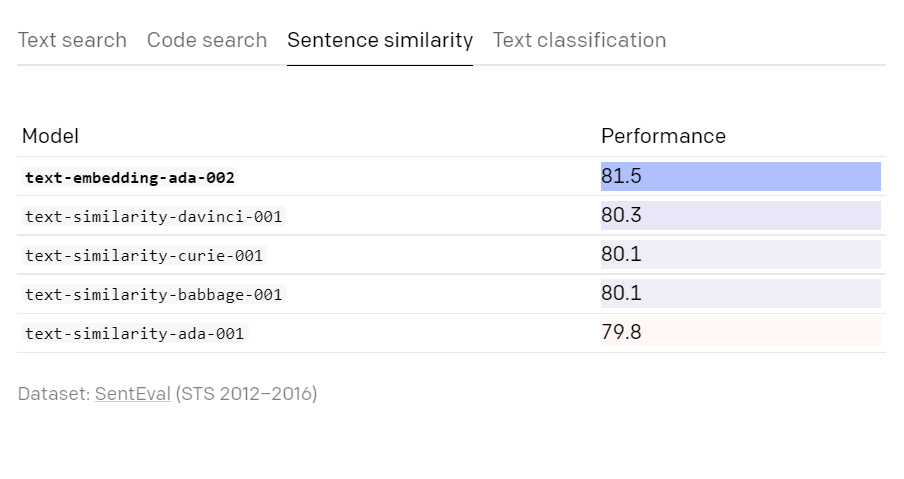
The performance of text classification is slightly lower than the previous model, but since it keeps 90 units, OpenAI says that it is performing almost the same.
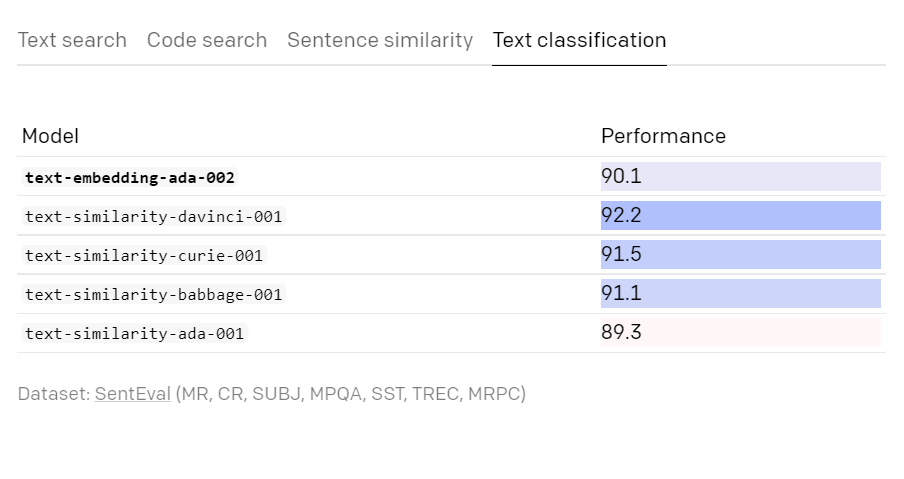
Conventional models had different models depending on their purpose, such as 'text-search-davinci-*-001' and 'text-similarity-davinci-001', but text-embedding-ada-002 combines text search, code search, sentence similarity, and text classification into a single model.
Also, text-embedding-ada-002 has increased the token length that can be entered from up to 2048 to 8192. This allows it to handle longer sentences. Furthermore, the dimension of the vector that drops the text has been reduced to 1536 dimensions, one eighth of the previous generation model. In addition, OpenAI claims that the usage fee for text-embedding-ada-002 has been reduced by 90% from the previous generation 'Davinci', making it 99.8% more profitable than before in terms of cost performance. increase.
OpenAI said, “The new embedded model is a much more powerful tool for natural language processing and code tasks. I am.”
Related Posts:







in Software, Posted by log1i_yk