







突飛なテキストからも高精度な画像を自動生成できるAIシステム「Imagen」

突飛なテキストからでも自然に高解像度な画像を生成することができるAIモデルの「Imagen」が発表されました。言語モデルのサイズを大きくすることでサンプルの忠実度と画像とテキストの整合性の両方が大幅に向上するそうです。
Imagen: Text-to-Image Diffusion Models
https://gweb-research-imagen.appspot.com/
「Imagen」の仕組みは以下の通り。まずはテキストエンコーダーのT5-XXLを用いることで単語の埋め込みを実行。続いてディフュージョンモデルを用いてテキストを64×64ピクセルの画像に変換。さらに、これを2度にわたり高解像度化のためのディフュージョンモデルにかけることで、最終的に1024×1024ピクセルの高解像度な画像を生成することができるようになっています。
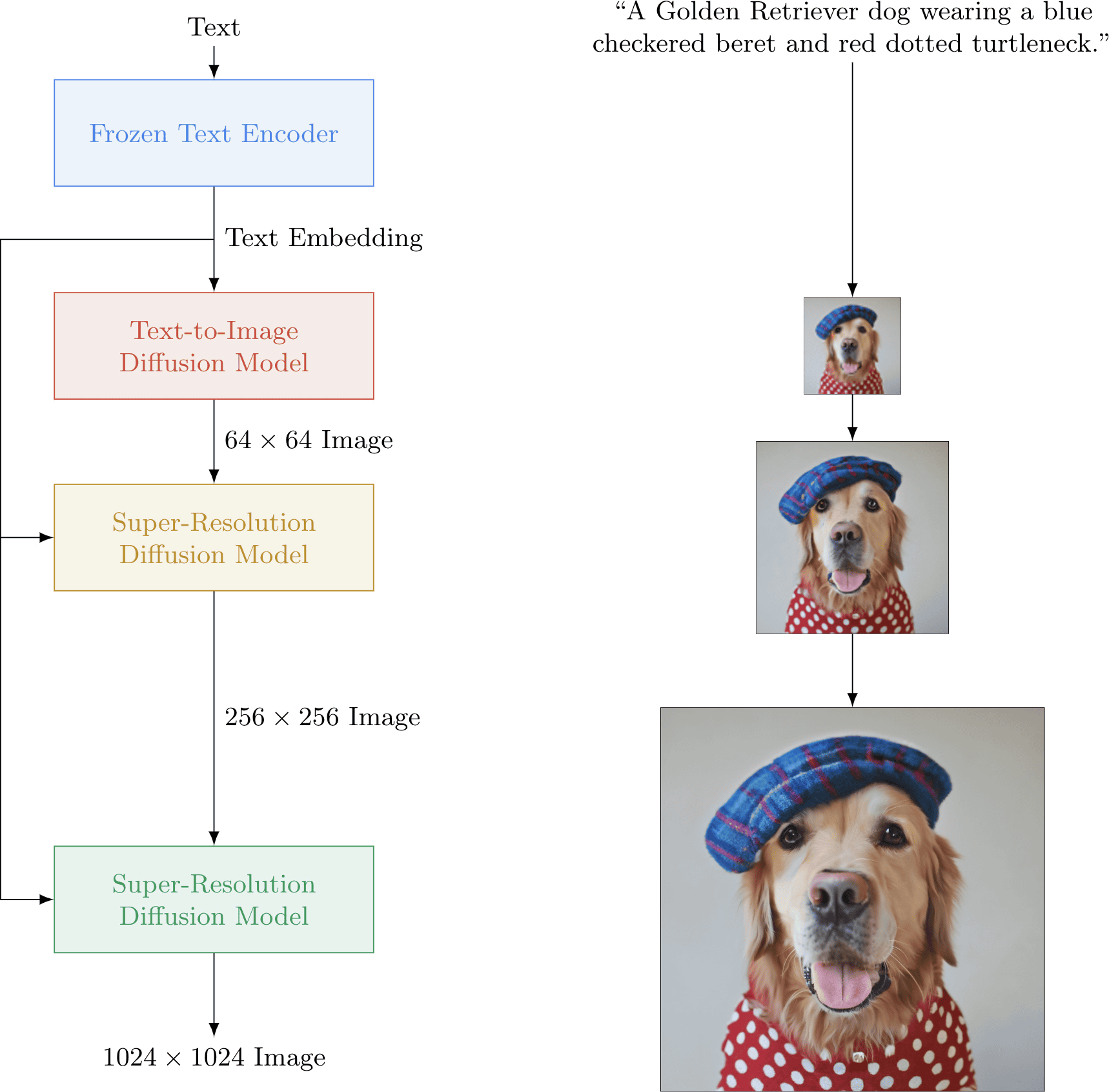
実際にImagenがどのようなテキストからどのような画像を生成できるのかは、以下の通り。
「宇宙飛行士のヘルメットをかぶったアライグマが窓から夜景を眺める様子」

「ロボットのカップルがエッフェル塔を背景に高級レストランで食事を食べている様子」

「タイムズスクエアで自転車に乗っているサングラスとビーチハットをかぶったコーギーの写真」

「花火で書かれたGoogleブレインのロゴとトロントのスカイライン」

「寿司の家に入ったコーギー」

さらに、Imagenの公式ページ上では条件をクリックして生成画像を変更することができるエリアも用意されています。

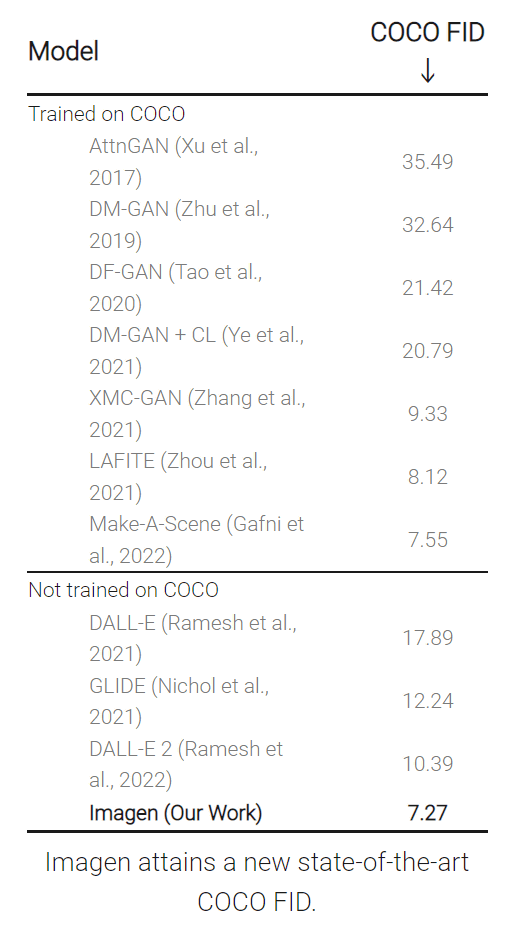
GANが生成した画像の品質を評価する指標のFréchet Inception Distance(FID)で、画像データセットのCOCOを使ってトレーニングされた画像生成モデル(Trained on COCO)と、トレーニングにCOCOを利用していない画像生成モデル(Not trained on COCO)のスコアを比較したのが以下の数値。FIDは数値が低いほど「生成した画像の品質が高い」ということを意味しており、Imagenは最もスコアが高い「7.27」を記録しています。
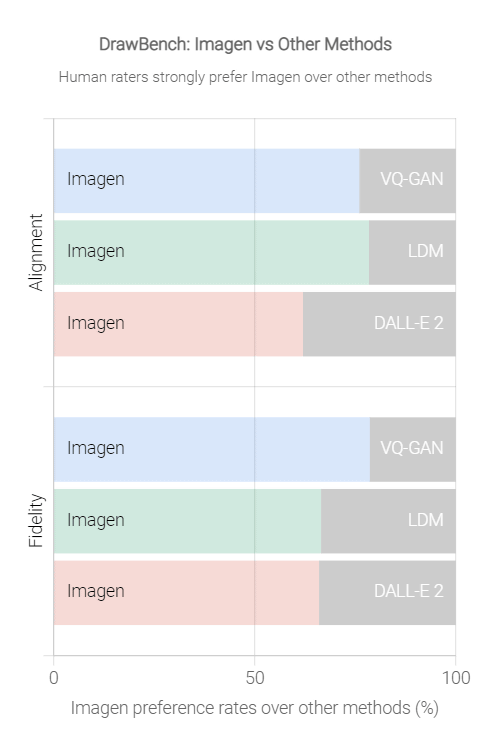
さらに、テキストから画像に変換するモデルの精度を評価するための人間の評価者を用いたベンチマークである「DrawBench」を使い、ImagenとVQ-GAN+CLIP、Latent Diffusion Models(LDM)、DALL-E 2という3つのモデルを比較したのが以下のグラフ。スコアは「整合性(Alignment)」と「忠実性(Fidelity)」に分かれており、どちらの尺度でもすべてのモデルにImagenが勝利しています。
なお、Imagenに関する研究論文も公開されており、以下からチェック可能です。
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
(PDFファイル)https://gweb-research-imagen.appspot.com/paper.pdf
・関連記事
文章から高クオリティな画像を生成できるAI「DALL・E 2」を使ってTwitterのプロフィールから絵を生成してみるとこんな感じ - GIGAZINE
入力した文字情報から画像を生み出す「DALL・E」の高解像度・低レイテンシ版「DALL・E 2」登場 - GIGAZINE
AIが入力したキーワードからイメージしたイラストを描いてくれる「Hypnogram」 - GIGAZINE
高度な画像認識AIは手書きの文字やステッカーなどの「敵対的な画像」で簡単にだまされてしまう危険性 - GIGAZINE
最先端のAI画像認識モデルでも正しく認識できない画像まとめ - GIGAZINE
・関連コンテンツ







