




Appleが10倍大きなAIモデルよりも優れた画像キャプションを付けられる「RubiCap」を発表

Appleの研究チームが、既存のAIモデルよりもはるかに小さなサイズでより正確で詳細な画像の説明文を作成できるAIモデル「RubiCap」を開発しました。
RubiCap: Rubric-Guided Reinforcement Learning for Dense Image Captioning - Apple Machine Learning Research
https://machinelearning.apple.com/research/rubicap

Apple-trained AI captions images better than models 10× its size - 9to5Mac
https://9to5mac.com/2026/03/25/apple-trained-an-ai-that-captions-images-better-than-models-ten-times-its-size/
Appleの研究チームはウィスコンシン大学マディソン校と協力して、高密度画像キャプションを生成できるAIモデルのための新しいフレームワークを開発しました。高密度画像キャプションとは、画像全体の要約ではなく、画像内で起こっているあらゆる出来事について、領域レベルで詳細な説明を生成する作業のことです。つまり、画像内の複数の要素や領域を識別し、それらを詳細に記述することで、全体的な記述よりもはるかに豊かなシーン理解をもたらすことができます。
高密度画像キャプションは、視覚言語モデルやテキストから画像に変換する画像生成モデルのトレーニングなど、さまざまな用途で利用可能です。ユーザー向けの機能に適用すれば、画像検索やアクセシビリティツールの精度向上にもつながります。
Appleの研究チームによると、問題は高密度画像キャプションが生成できるAIモデルをトレーニングする既存のAIベースのアプローチでは、大事な部分で不十分な点が多いということです。例えば、トレーニングに必要な専門家レベルのアノテーションを大規模に作成するには、莫大なコストがかかります。強力な視覚言語モデルによる合成キャプションで代替するという方法もありますが、教師あり学習の蒸留では出力の多様性が限られ、汎化性能も弱いという問題もあるそうです。強化学習はこれらの制約を克服できる可能性がありますが、これまでのところ成果は限られており、オープンエンド型のキャプション作成では利用できないとされています。

そこで、Appleの研究チームは新しいフレームワークを提案しました。研究チームはPixMoCapとDenseFusion-4V-100Kという2つのトレーニングデータセットから、5万枚の画像をランダムにサンプリングしました。そして、各画像にGemini 2.5 Pro、GPT-5、Qwen2.5-VL-72B-Instruct、Gemma-3-27B-IT、Qwen3-VL-30B-A3B-Instructといった大規模言語モデル(LLM)を用いて複数のキャプション候補を生成。同時に、RubiCapにも画像に対して独自のキャプションを生成させました。
次に、RubiCapはGemini 2.5 Proを使用して以下を行います。
1:各モデルが出力したキャプションを比較分析
2:モデルごとに優れた点と、劣る点を特定
3:これをベースにキャプションを評価するための明確な基準を作成
その後、Qwen2.5-7B-Instructを審査員として、ステップ3で作成した基準をベースにAIモデルが生成したキャプションを採点し、トレーニングに使用される報酬信号を生成。
その結果、RubiCapは修正すべき点についてより正確で構造化されたフィードバックを受け取ることが可能となり、単一の「正解」に頼ることなく、より精度の高いキャプションを作成できるようになりました。
RubiCapが優れたキャプションを生成するためのフィードバックループを図示したのが以下の画像。
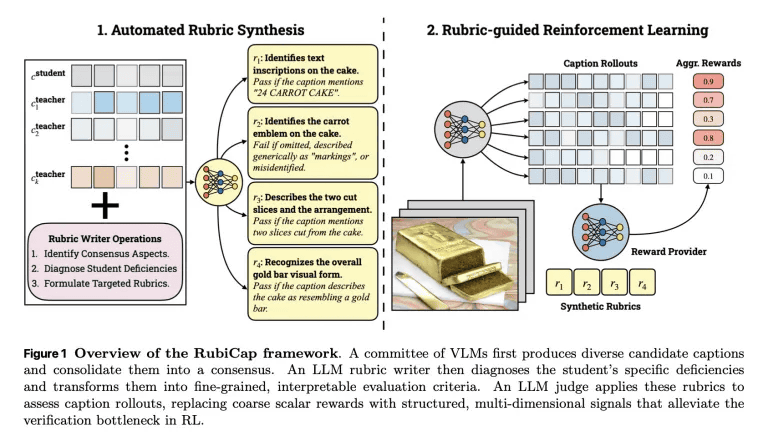
最終的に、Appleの研究チームはパラメーターサイズの異なるRubiCap-2B、RubiCap-3B、RubiCap-7Bという3つのモデルを作成。そして、既存のAIモデルと生成キャプションの精度を比較するべく、画像キャプションのベンチマークテストを実施しました。その結果が以下で、RubiCap-3B(黒)は競合AIモデルよりもすぐれたパフォーマンスを発揮しています。
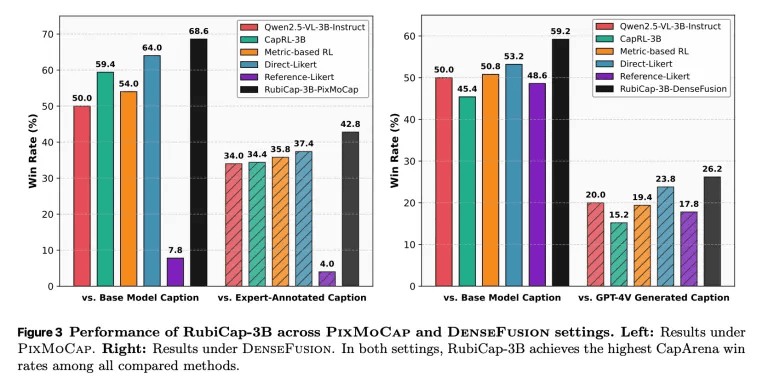
CapArenaにおいて、RubiCapは「教師あり学習を施した蒸留モデル」「従来の強化学習を施したモデル」「人間の専門家によるアノテーションを施したモデル」「GPT-4V」を上回るスコアを記録。CaptionQAでも、優れた単語効率を示し、パラメーターサイズが最も大きなRubiCap-7Bは、よりパラメーターサイズが大きなQwen2.5-VL-32B-Instructと同等の性能を発揮しました。特筆すべきは、コンパクトなRubiCap-3Bをキャプション生成器として使用することで、独自のモデルで生成されたキャプションで学習された視覚言語モデルよりも、強力な事前学習済み視覚言語モデルが生成できるという点です。
ブラインドテストにおいて、RubiCap-7Bはパラメーターサイズが720億や320億の最先端AIモデルと比べても、最も優れたキャプションが生成できると評価され、ハルシネーションを起こす割合が最も低く、キャプション精度も最も高いことが示されました。
・関連記事
Appleが1枚の画像からリアルな照明効果を持つ3Dオブジェクトを再現できるAIモデルを発表 - GIGAZINE
AppleはAIモデルをオープンソースとして公開したいと考えていたが世間の批判を恐れ実現せず - GIGAZINE
なんと397BのAIモデルをiPhoneで動かすことに成功 - GIGAZINE
Appleが提唱した「AIの推論能力の限界」にAI専門家が反論 - GIGAZINE
「Appleは必ずAIをやる」「そのための投資を行う」とAppleのティム・クックCEOが異例の全社会議で言及、Siriの開発が遅れた理由などについても説明 - GIGAZINE
・関連コンテンツ







in AI, Posted by logu_ii
You can read the machine translated English article Apple has announced 'RubiCap,' which can….