




Windows標準機能より4倍高速な圧縮・解凍ソフト「CoZip」が登場したので使ってみた、GPUを駆使して爆速圧縮できる無料ソフト
GPUを用いて非常に高速な圧縮処理が可能な圧縮・解凍(展開)ソフト「CoZip」がべあ(bea4dev)氏によって公開されました。オープンソースで開発されていてWindows用のインストーラーも用意されていたので、実際に使ってWindows標準機能と速度を比べてみました。
GitHub - bea4dev/cozip: Cooperative CPU + GPU (WebGPU) compression library for Rust. · GitHub
https://github.com/bea4dev/cozip
🗜️GPUを利用する圧縮・解凍ソフトを公開します!📁
— 🦀ベあ | bea4dev🦀 (@_Be4_) March 13, 2026
GPU-accelerated compression/decompression software has been released!
名前はCoZipです!!!
非常に高速です!!!
Windows版をリリースします!!!
(MacOS & Linuxは後日)
ダウンロード & Discord
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ pic.twitter.com/WO4oFMFRFB
CoZipをインストールするために、まずの以下のリンクをクリックして配布ページにアクセスします。
Releases · bea4dev/cozip
https://github.com/bea4dev/cozip/releases
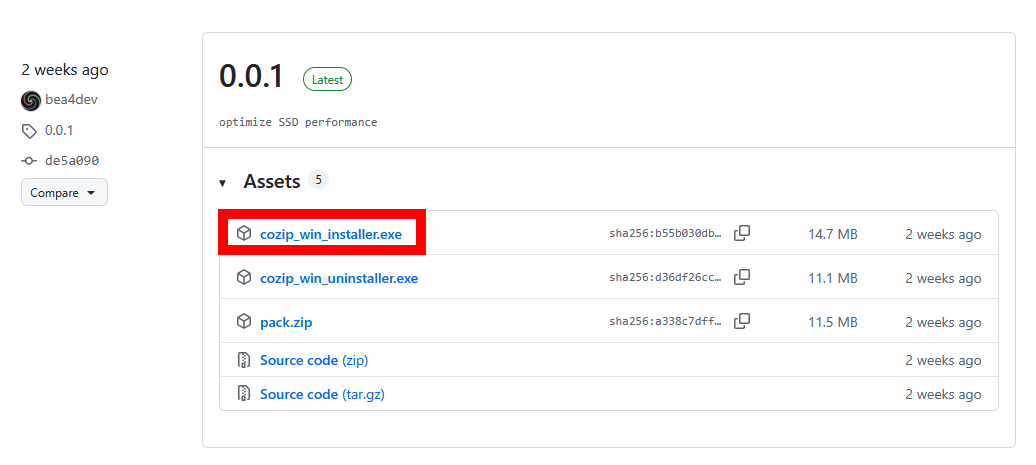
最新版のインストーラーをダウンロードします。今回は「cozip_win_installer.exe 」をクリックしてダウンロードしました。
ダウンロードしたインストーラーをダブルクリックして実行します。
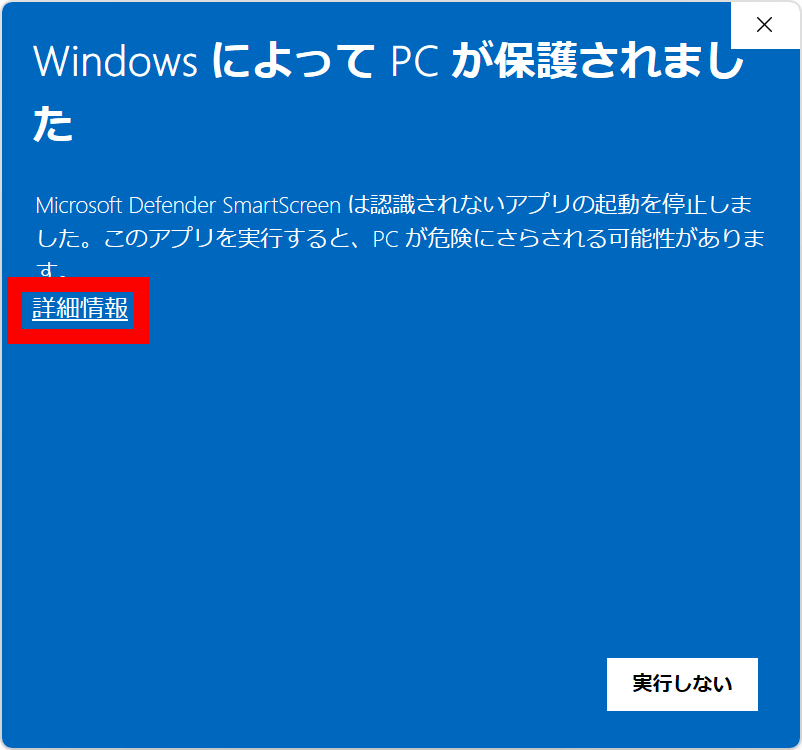
保護通知が表示されたら「詳細情報」をクリック。
「実行」をクリック。
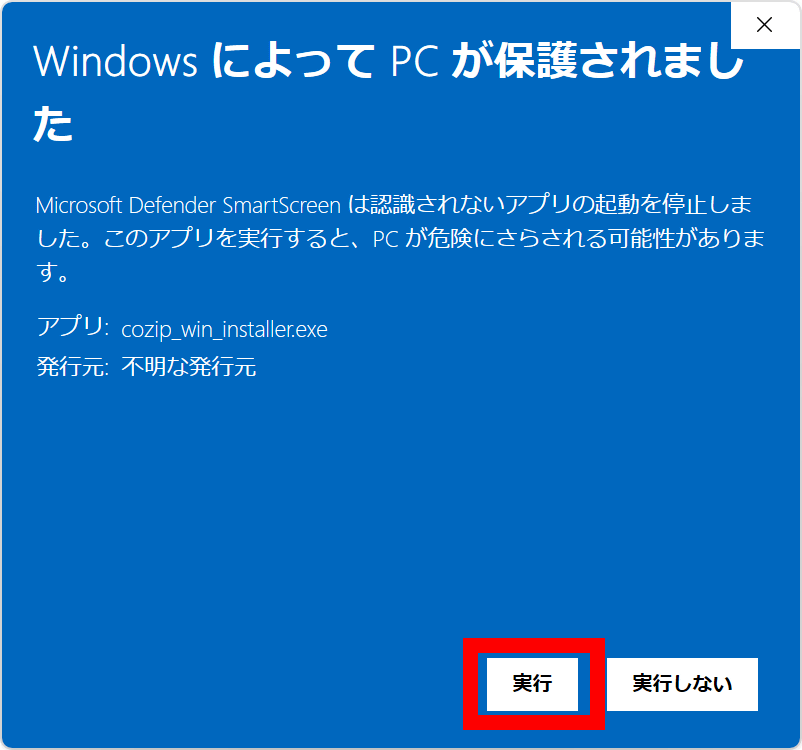
ライセンス規約をよく読んでから同意のチェックを入れて「次へ」をクリック。
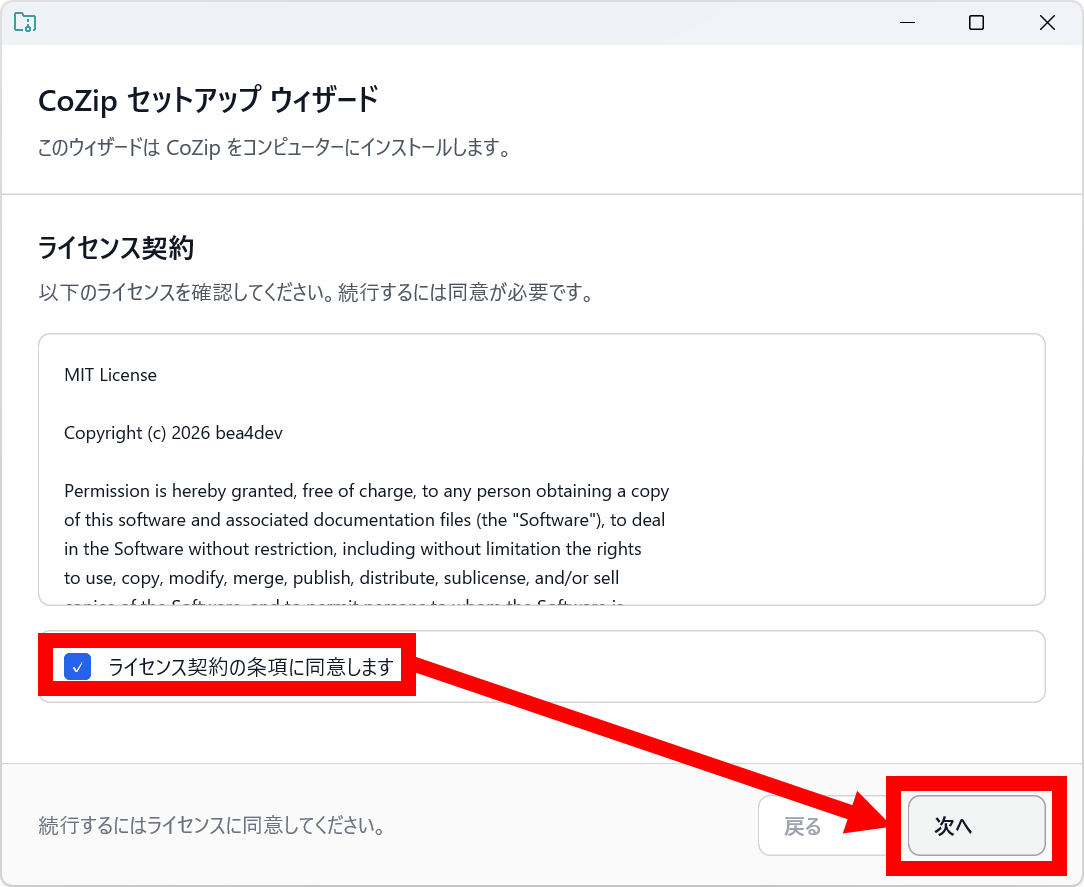
特に設定は変更せずに「インストール」をクリック。
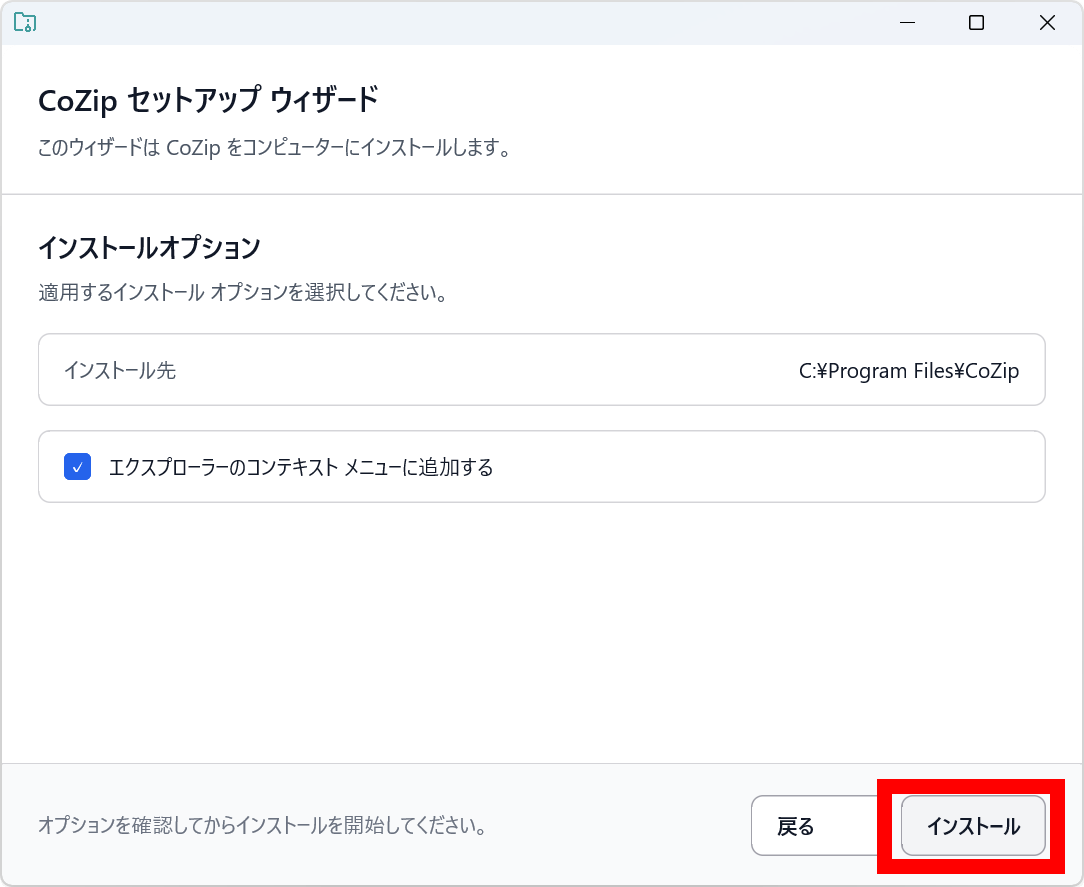
「完了」をクリックすればインストール完了です。
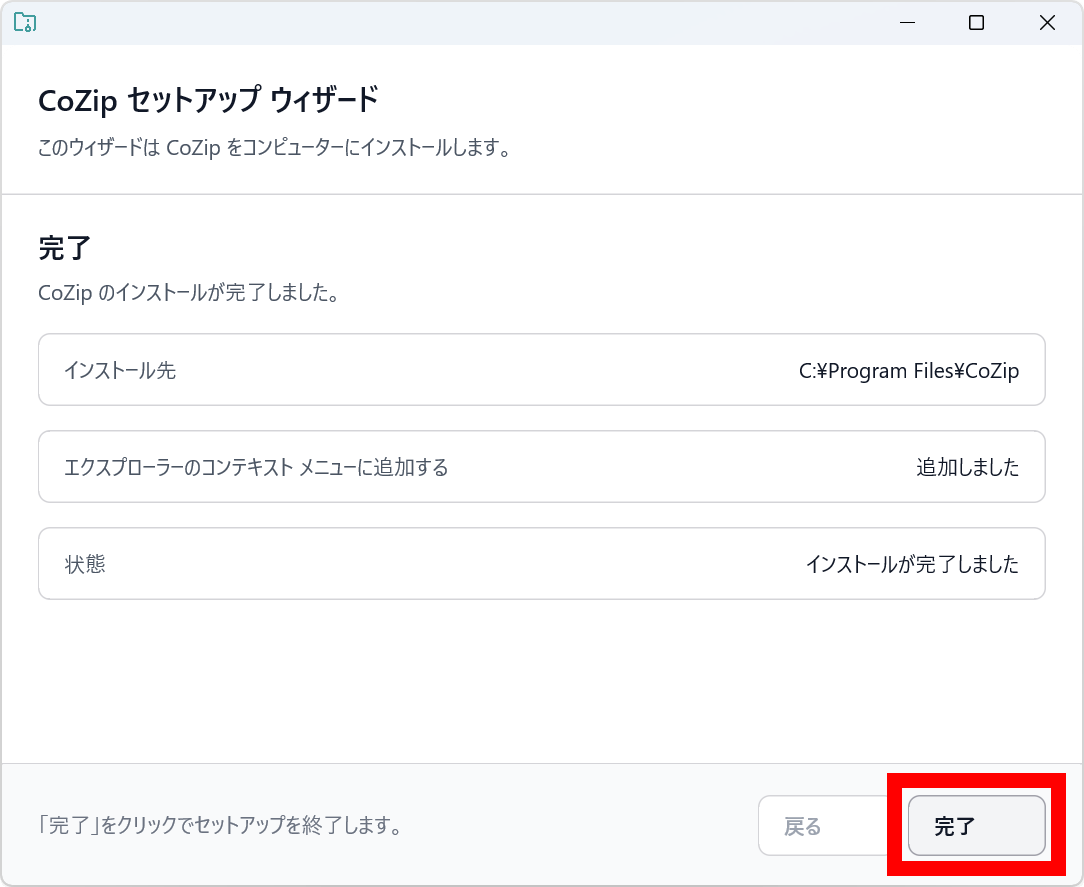
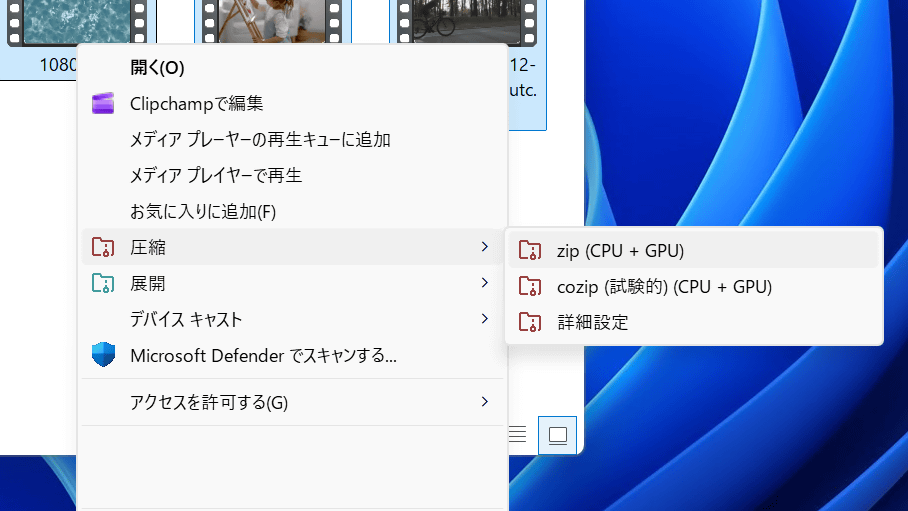
CoZipを使って圧縮・展開を実行するには、まず対象のファイルを選択してから右クリックメニュー内の「その他のオプションを確認」をクリック。
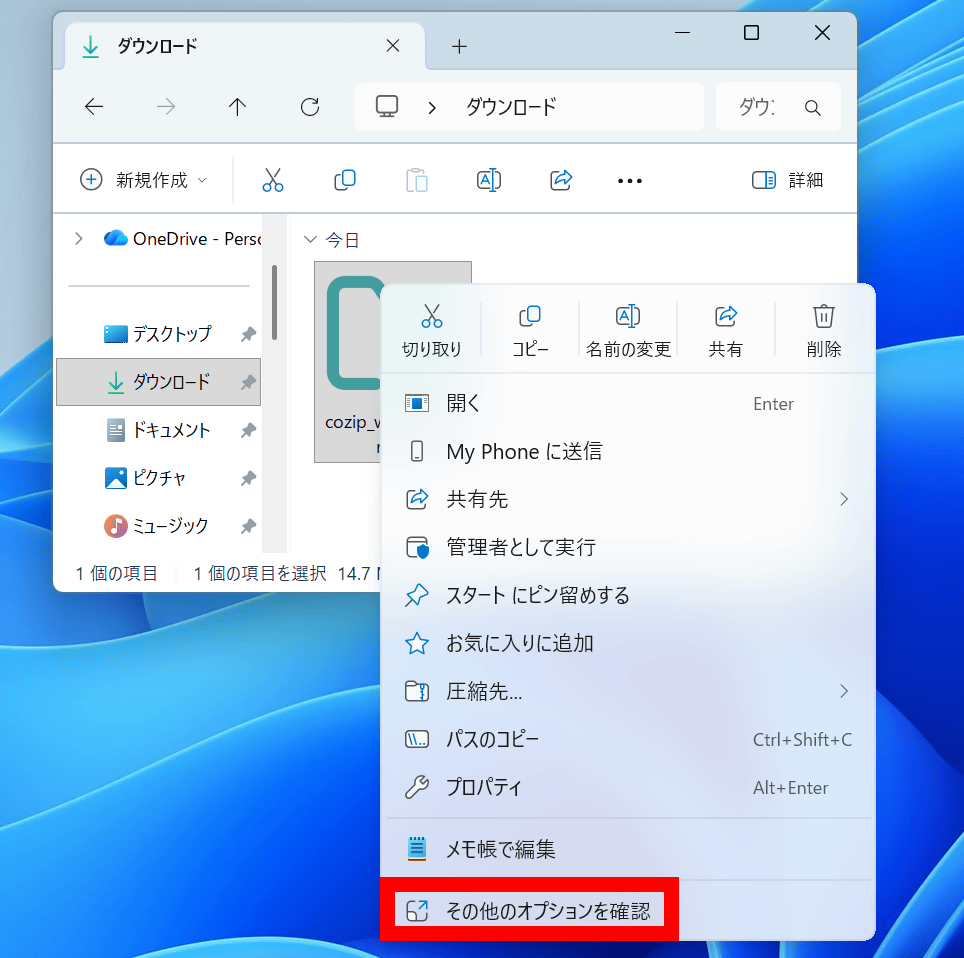
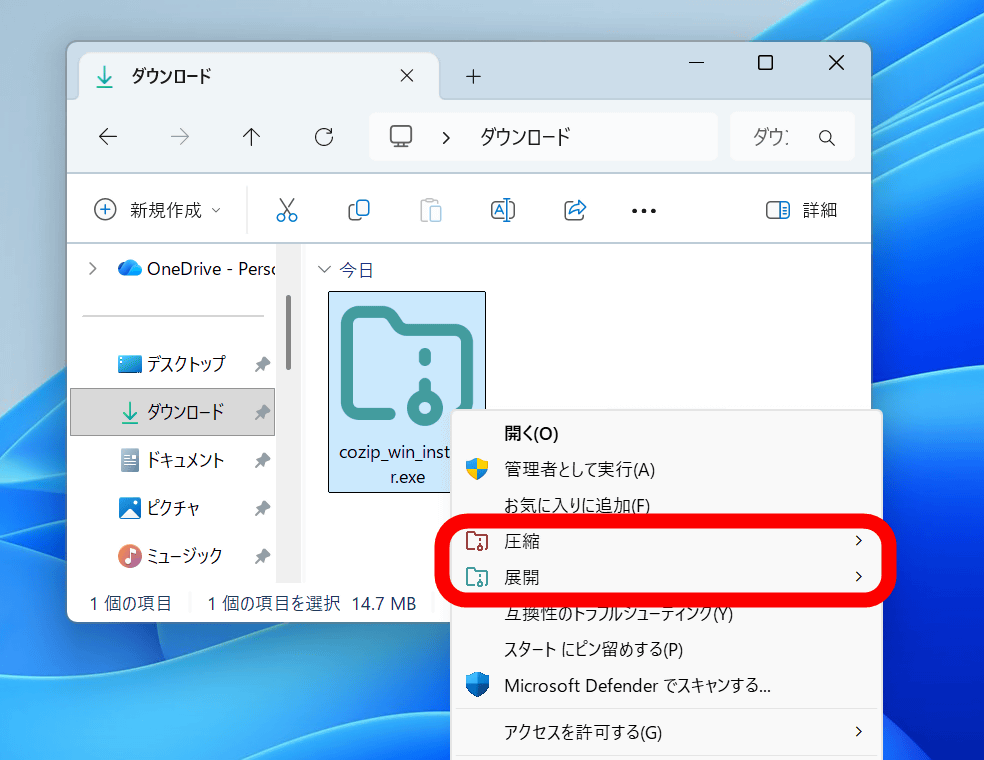
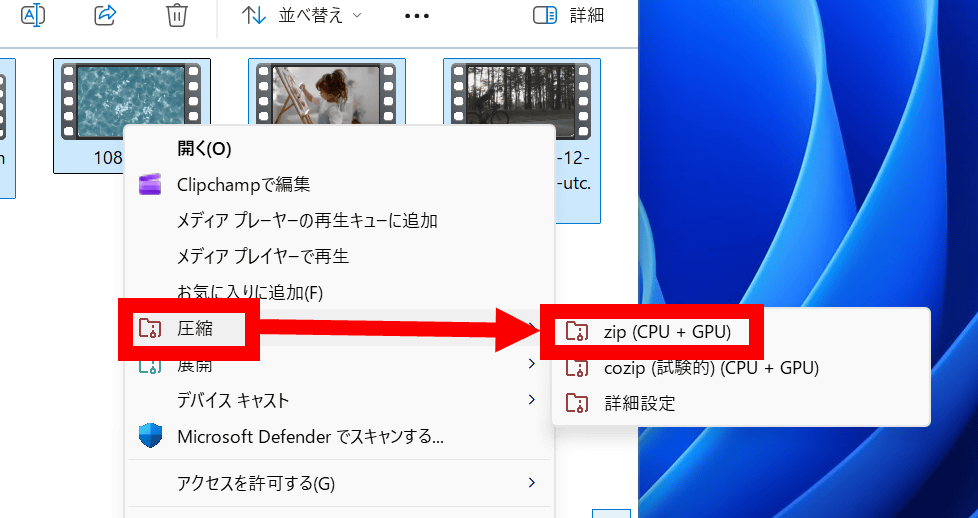
コンテキストメニューに「圧縮」「展開」という項目が追加されています。このボタンから圧縮・展開処理が可能です。
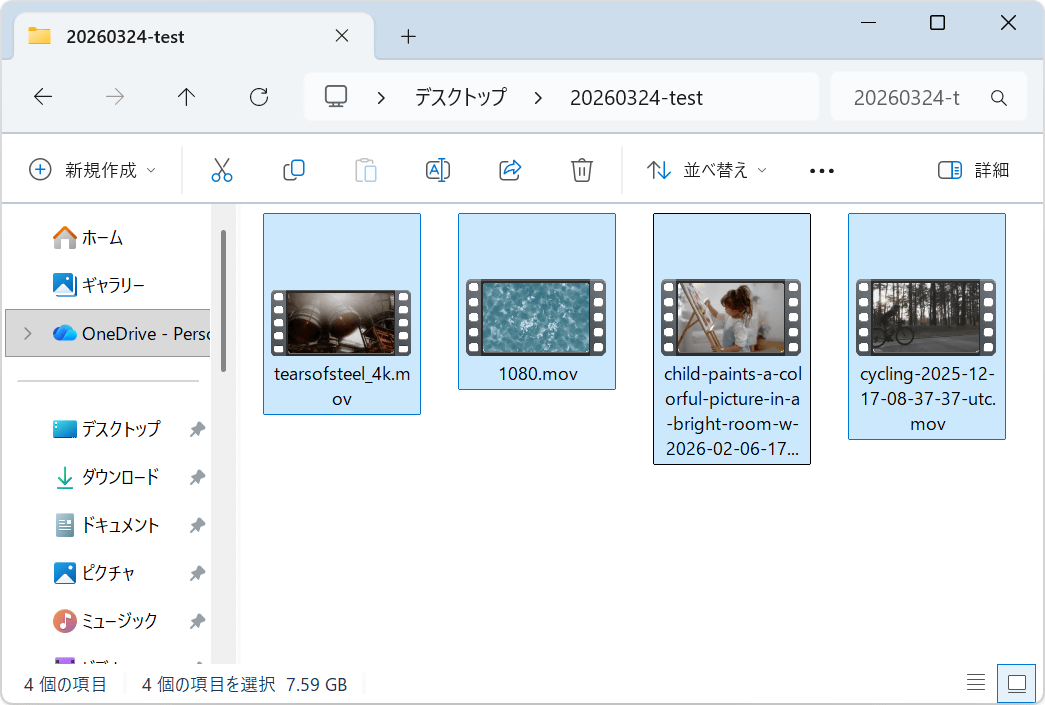
というわけで、Windows標準機能とCoZipの処理速度を比べてみます。まず、4本の動画を1個のZIPファイルに圧縮する速度を測定します。動画ファイルの合計サイズは7.59GBです。なお、今回使っているPCのCPUは「AMD Ryzen 5 7600X」で、GPUは「NVIDIA GeForce RTX 5070Ti」です。
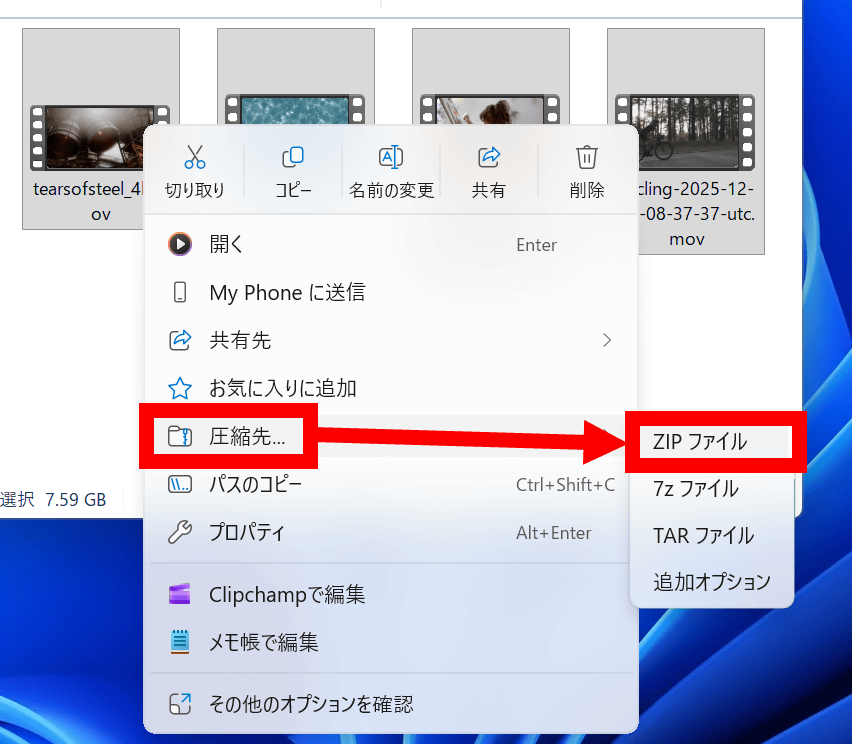
Windows標準機能で圧縮します。右クリックメニュー内の「圧縮先」をクリックしてから「ZIPファイル」をクリック。
圧縮完了までにかかった時間は2分6秒でした。

続いて、CoZipで圧縮します。右クリックメニュー内の「その他のオプションを確認」をクリック。
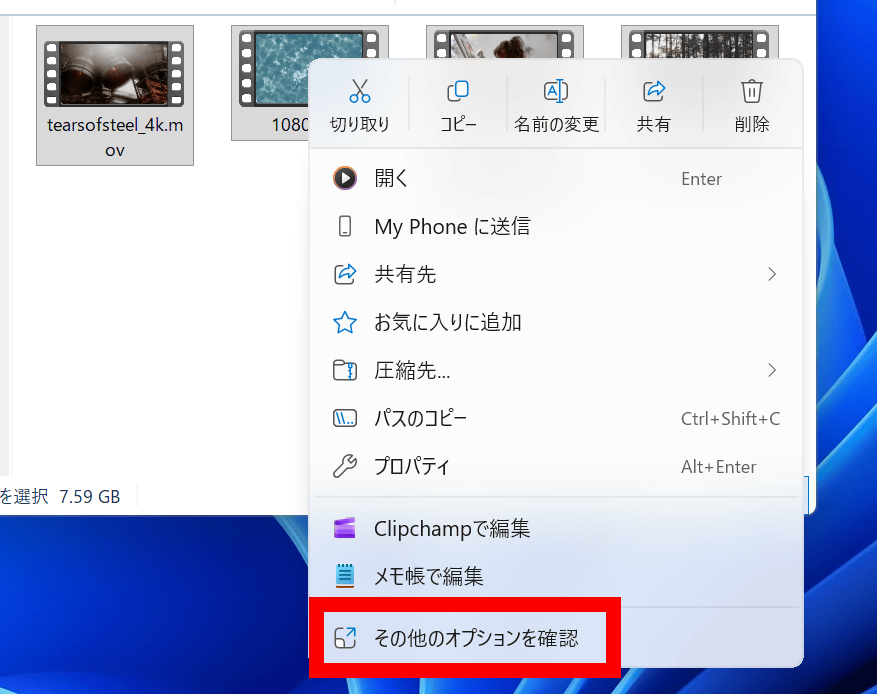
「圧縮」をクリックしてから「zip(CPU + GPU)」をクリック。
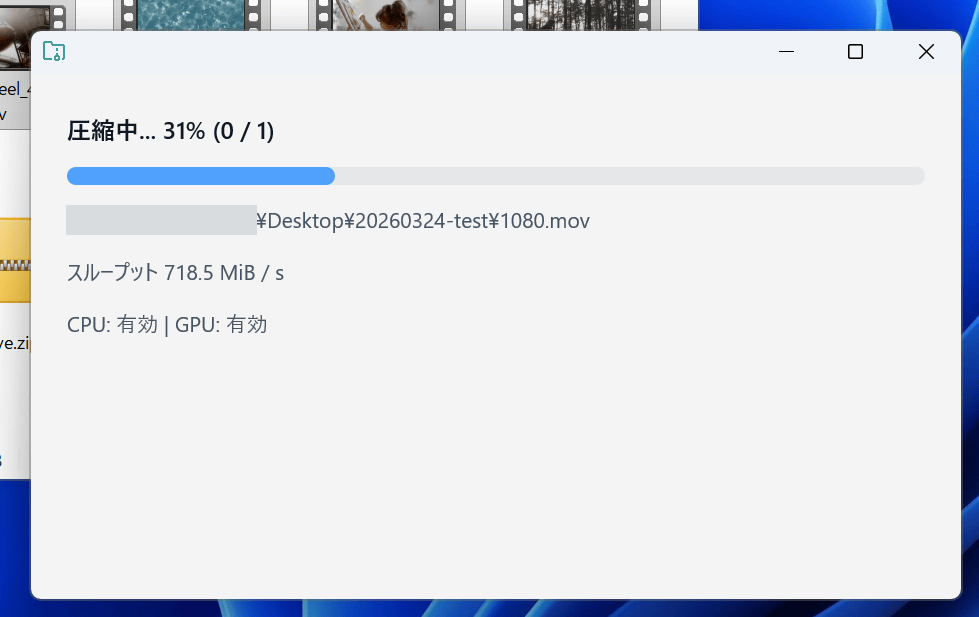
処理状況は以下のような画面で表示されます。
処理完了。
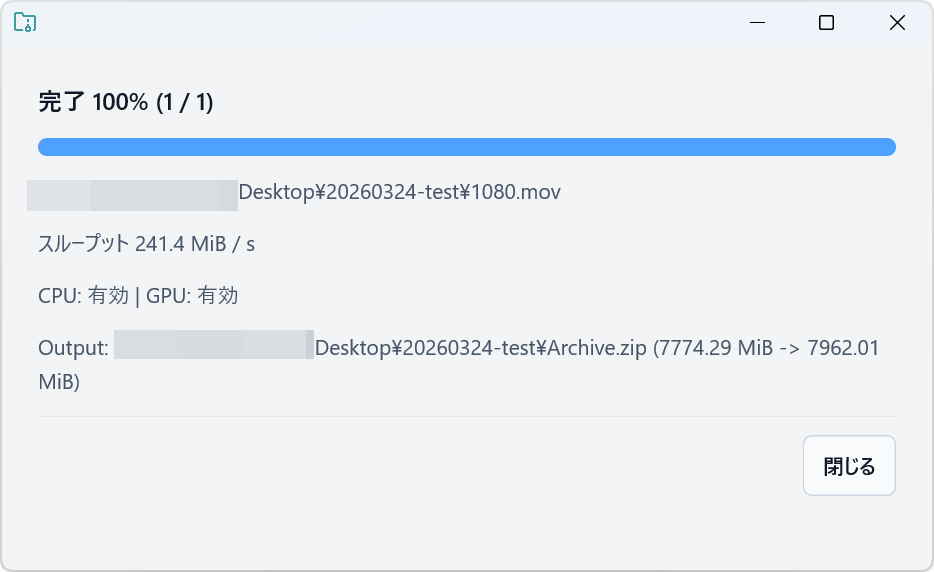
圧縮に要した時間はわずか34秒でした。Windows標準機能と比べて約4倍高速です。

圧縮後のZIPファイルは「Archive.zip」という名前になっていました。
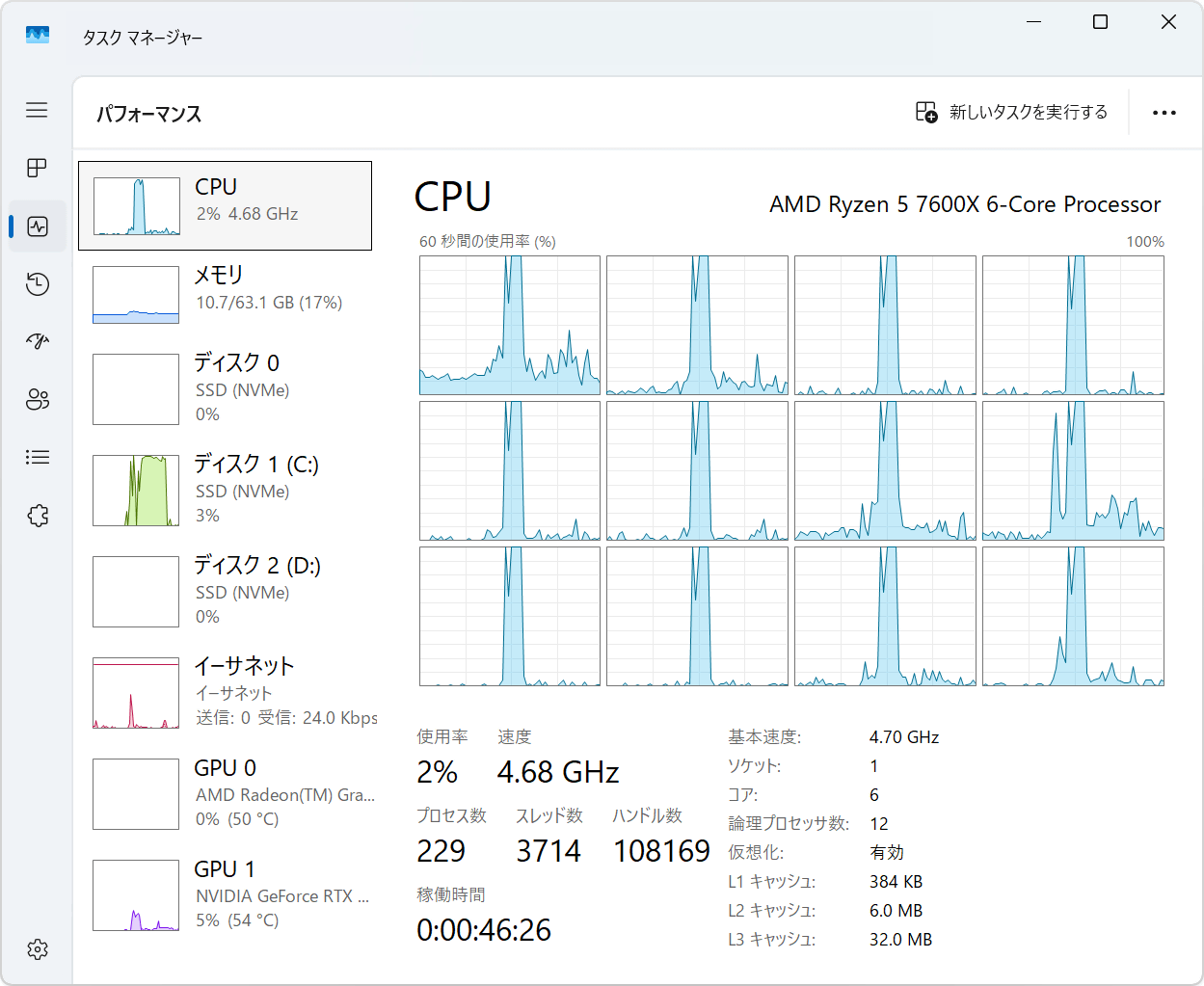
CoZipで圧縮処理中の負荷をタスクマネージャーで確認。圧縮開始と同時にCPUの全スレッドを使って処理しています。
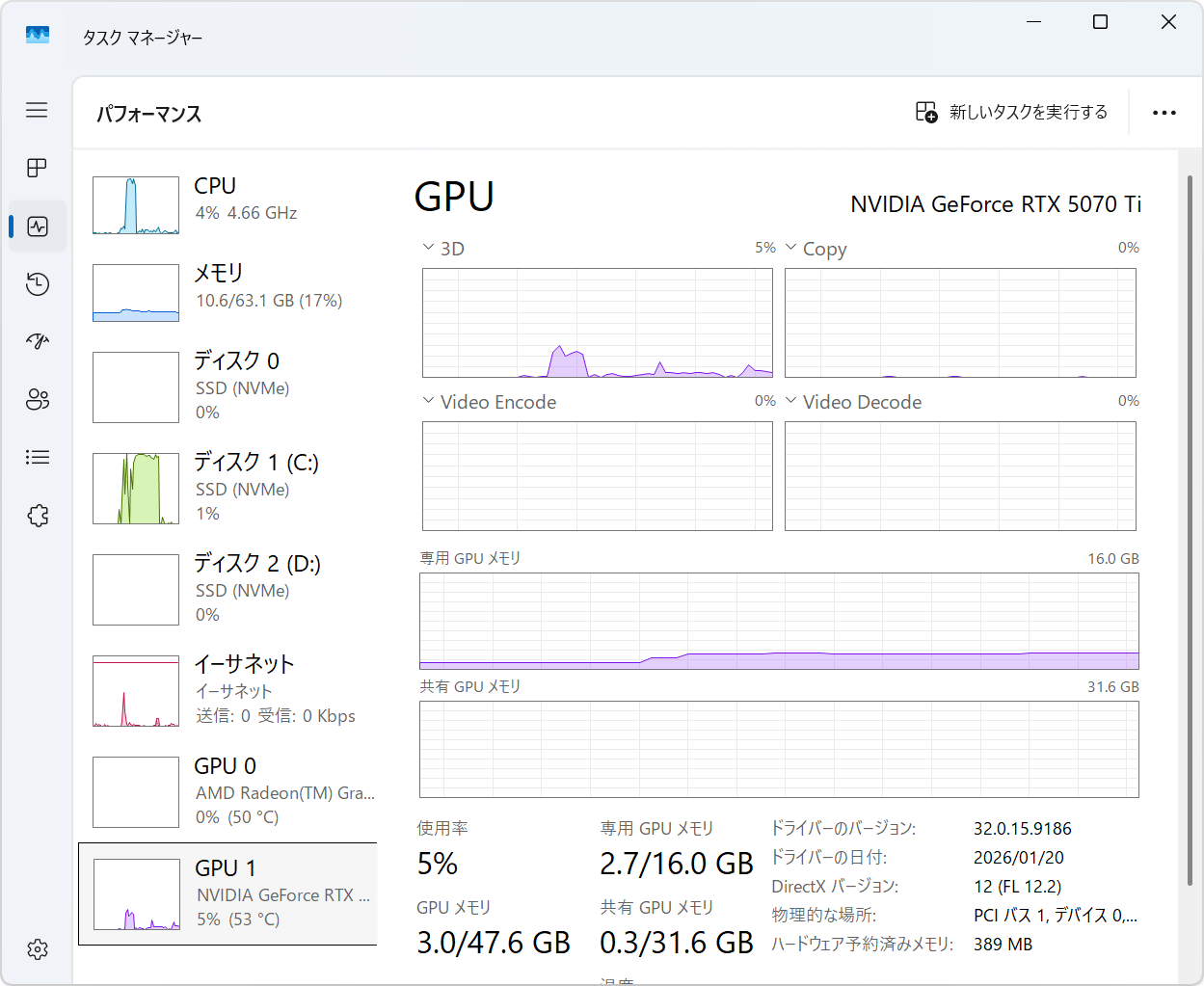
GPUもしっかり有効活用されていました。
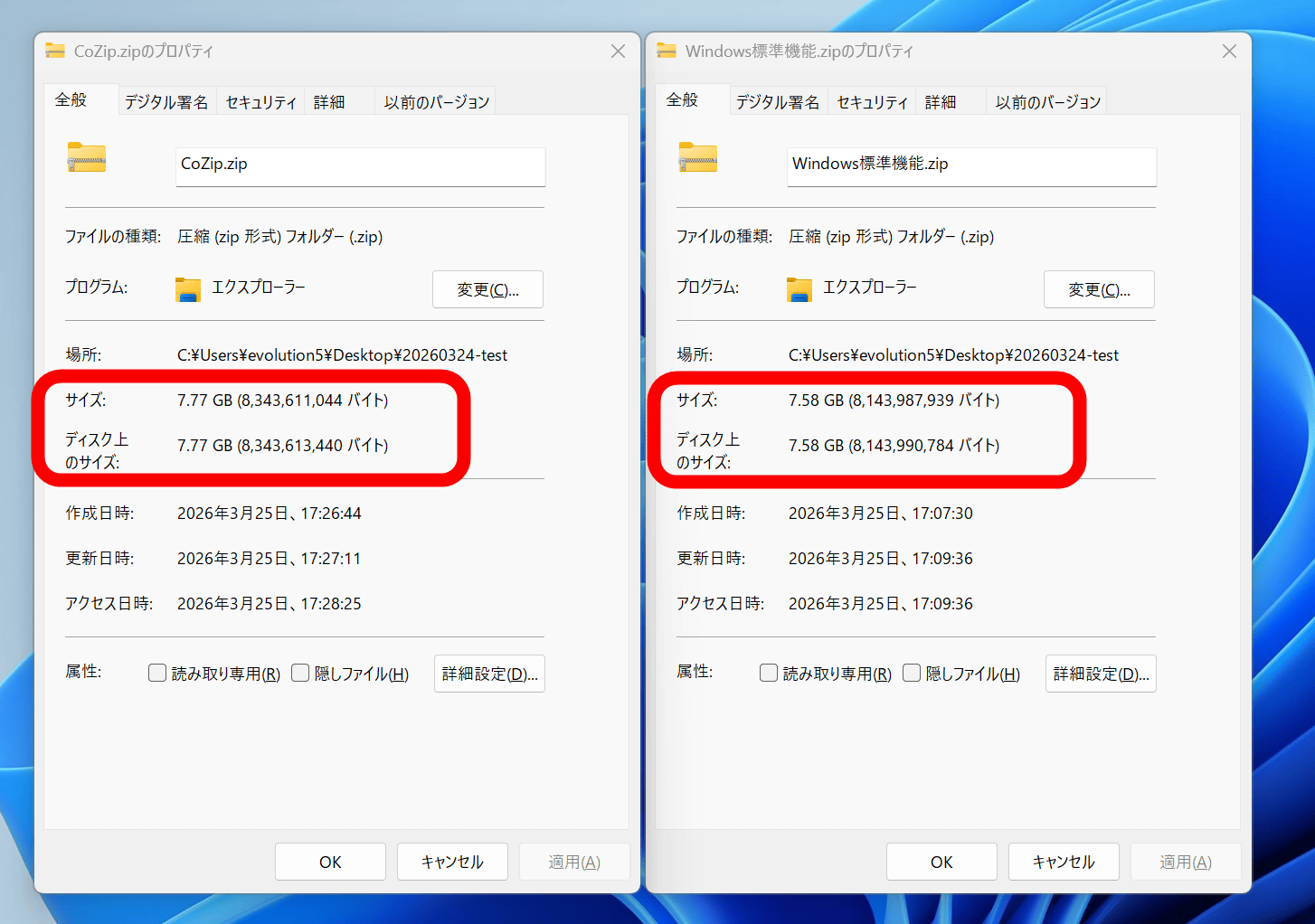
CoZipで圧縮したZIPファイル(左)とWindows標準機能で圧縮したZIPファイル(右)のプロパティを並べてみました。CoZipだとファイルサイズが圧縮前の合計ファイルサイズより増えて7.77GBになっています。
続いて、圧縮対決で作った「Archive.zip」をWindows標準機能とCoZipで展開して速度を比べてみます。まずWindows標準機能で展開するべく右クリックメニュー内の「すべて展開」をクリック。
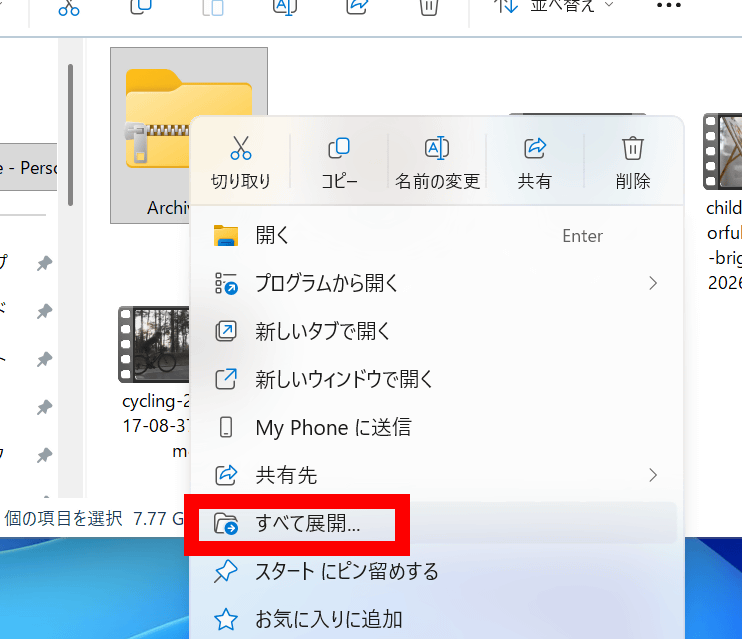
「展開」をクリック。
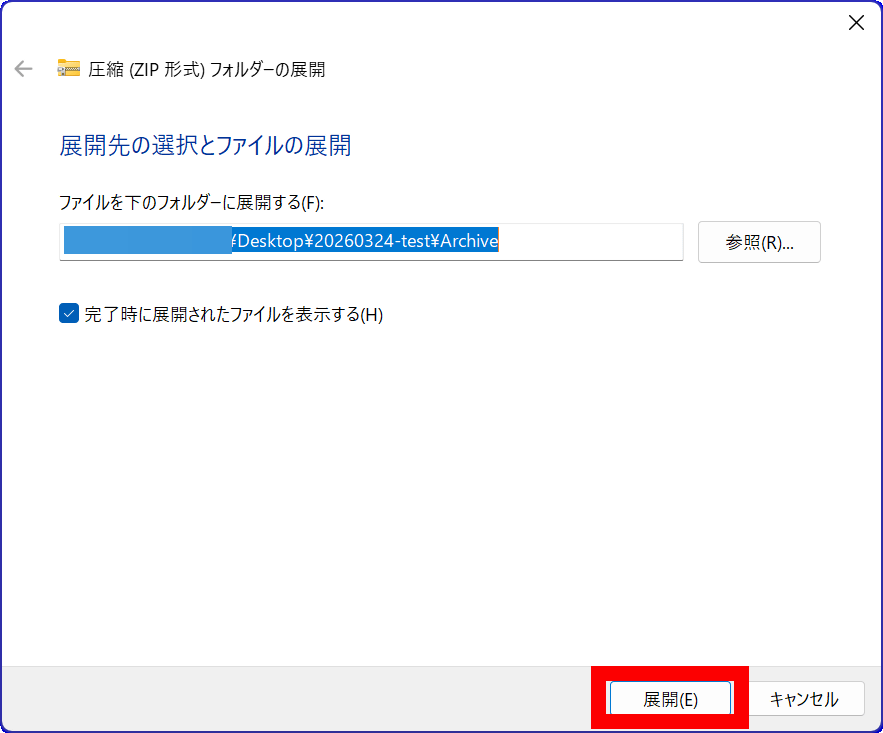
58秒で展開できました。

CoZipでも展開します。右クリックメニュー内の「その他のオプションを確認」をクリック。
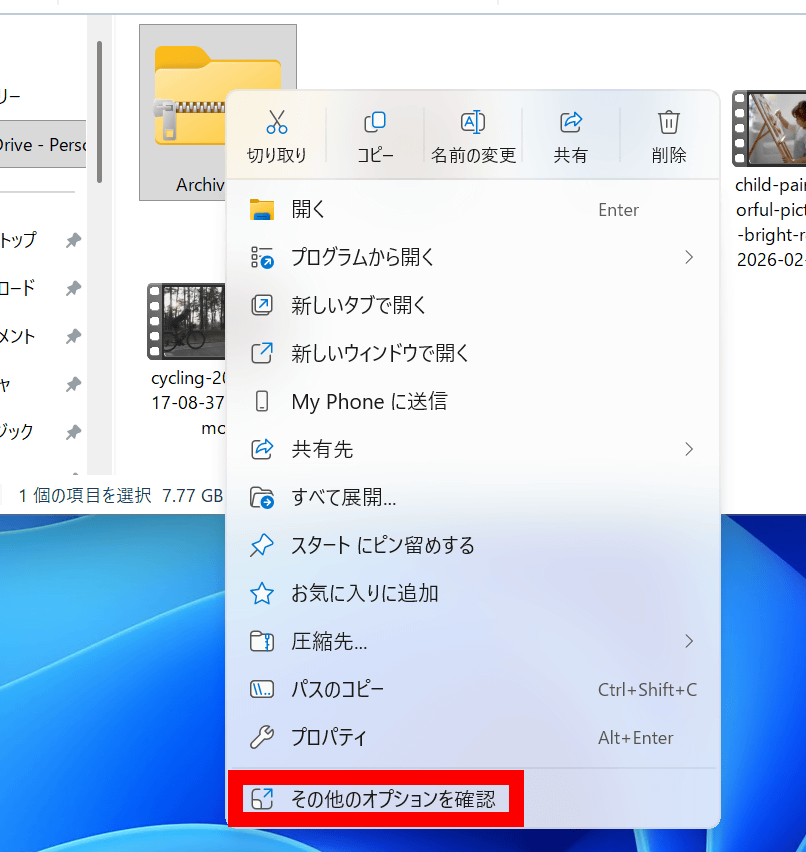
「展開」をクリックしてから「ここに展開」をクリック。
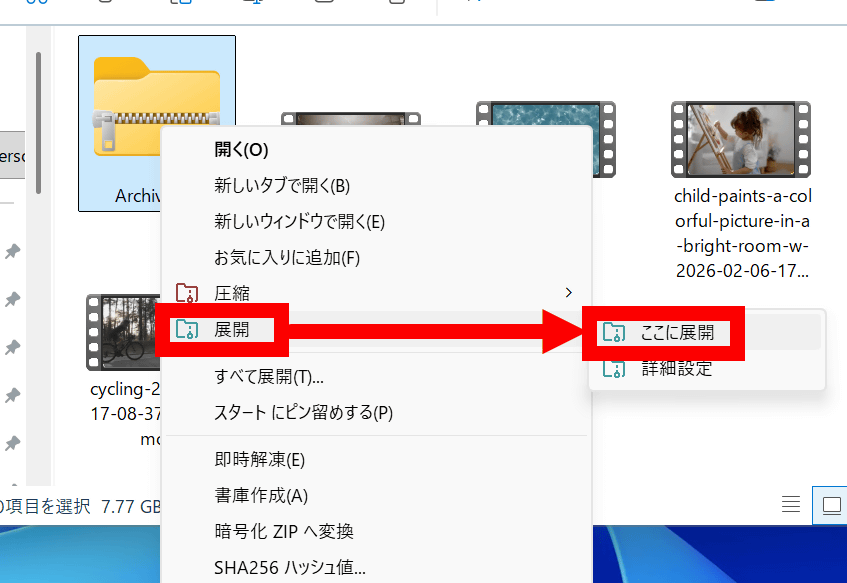
展開中の画面はこんな感じ。展開処理はCPUのみで実行されます。
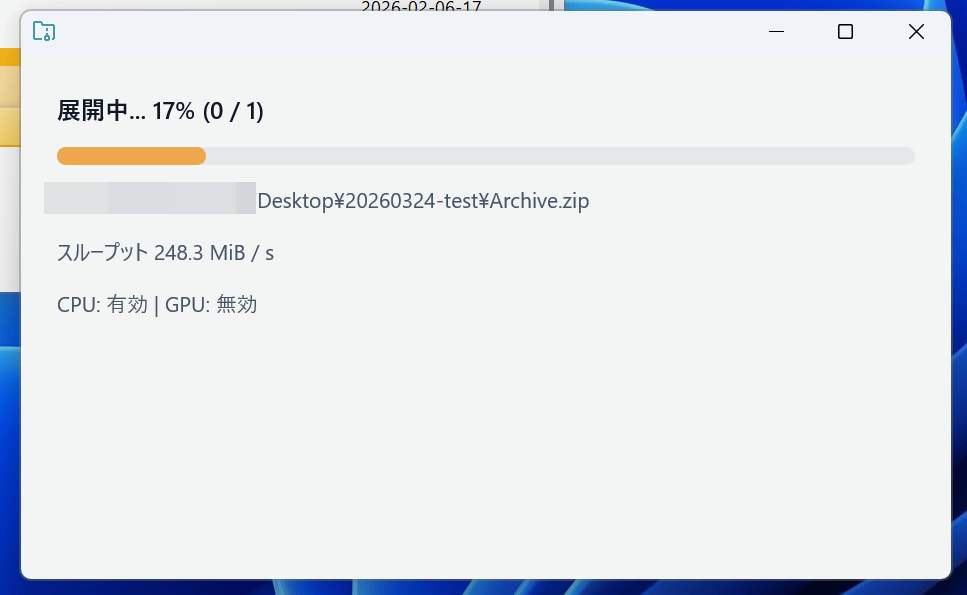
完了しました。
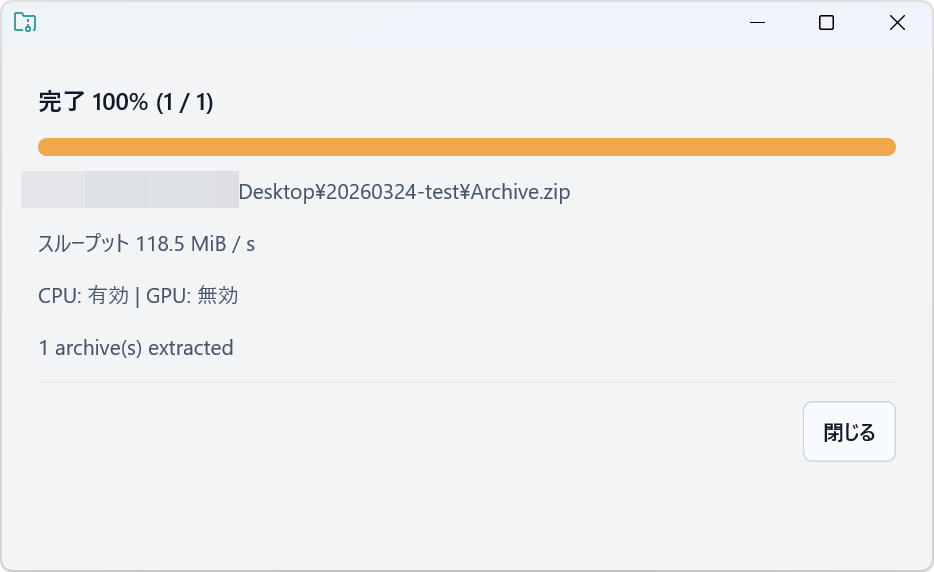
展開にかかった時間は1分6秒。CoZipは圧縮は爆速ですが、展開速度はWindows標準機能と同程度です。

なお、べあ氏によると、記事作成時点のバージョンは「大きいファイル」が得意で、「細かいファイルが大量にあるフォルダ」の圧縮はそれほど高速ではないそうです。
せっかく紹介していただいたので少し補足
— 🦀ベあ | bea4dev🦀 (@_Be4_) March 16, 2026
現状の実装だと細かいファイルが大量にあるフォルダの圧縮はあまり早くならない(スケジューラーの問題)
なので今試すなら大きいファイルをお試しください
面白いほど爆速で動作します https://t.co/cybPASIbbj
CoZipのソースコードは以下のリンク先で確認できます。
GitHub - bea4dev/cozip: Cooperative CPU + GPU (WebGPU) compression library for Rust. · GitHub
https://github.com/bea4dev/cozip
・関連記事
ZIP/RAR/LZH/ISOなどあらゆるファイルの解凍・圧縮が一発でできるようになるフリーソフト「Explzh」 - GIGAZINE
「ウィンドウを常に最上部に表示」「ウィンドウレイアウトをカスタマイズ」「行方不明のマウスポインターを強調表示」などMicrosoft公式の小技アプリ集「PowerToys」を使ってみた - GIGAZINE
無料で間違って削除した写真・動画・ファイルを復元・復旧できる「RescuePRO DELUXE」レビュー、サンディスクのSDカードを買うと無料で付いてくるアレはちゃんと使えるのかを検証 - GIGAZINE
警察庁がランサムウェア「Phobos」「8Base」による暗号化を解除するツールを開発、使い方はこんな感じ - GIGAZINE
・関連コンテンツ




in ソフトウェア, レビュー, Posted by log1o_hf
You can read the machine translated English article I tried out 'CoZip,' a free compression/….