Google Research reports that repeating a prompt twice increases the accuracy rate of AI

[2512.14982] Prompt Repetition Improves Non-Reasoning LLMs
https://arxiv.org/abs/2512.14982
This technique, called 'Prompt Repetition,' simply converts the input from '[Instruction]' to '[Instruction][Instruction].' In other words, all you have to do is copy the instruction or question and paste it twice in a row. While this may seem like an easy way to say the same thing twice, the research team's goal is not persuasion, but to reduce the amount of information lost due to the way LLMs are read.

Many LLMs process text from left to right. Unlike humans, they do not scan the entire text before comprehending it, so they are unable to check the information that follows while reading from the beginning. Therefore, even a change in the order of 'background information → question' or 'question → background information' can leave room for overlooking necessary conditions or misreading the correct reference.

So if the prompt is repeated twice, the entire text of the first prompt will already be present as input when the second prompt is processed. In this state, it becomes easier for each part of the second prompt to refer to the entire content of the first prompt. It's like artificially creating a situation where two pages of the same instruction manual are posted in a row, and by the time the second page is read, the first page has definitely been 'read.' The research team explains that this structure reduces oversight of instructions and conditions, which may result in a higher rate of correct answers.
To verify this effect, the research team evaluated seven models, including
The research team distinguishes between 'whether or not the LLM is prompted to make inferences.' LLMs have inference models or modes that require more 'thinking time' by increasing the number of intermediate steps before producing an answer, while others have settings closer to an 'immediate answer mode' that produces an answer relatively quickly after reading the input without using many additional thought steps. According to the research team, their method showed significant effects in the latter mode, where inferences were not prompted.
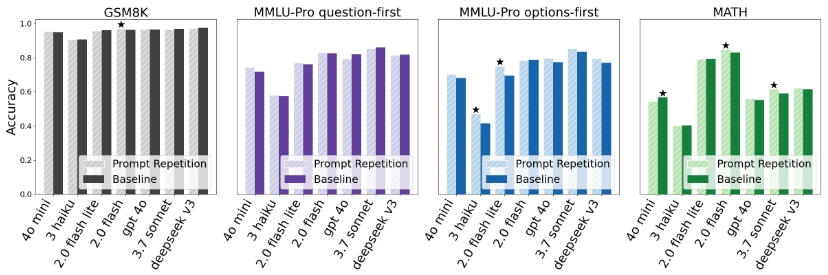
The research team conducted a McNemar test to examine whether success and failure rates changed before and after specific conditions. They reported that in 47 out of 70 cases, prompt repetition resulted in a statistically significant increase in correct answer rates, while not a single case was observed in which prompt repetition resulted in a decrease in correct answer rates. This finding was particularly strong in multiple-choice questions, where the context is difficult to align on the first reading, such as with 'options-first' ordering, where the options are presented before the question. This suggests that errors due to incompatibility of the ordering method are corrected on the second reading. The graph below compares correct answer rates for baseline (where the prompt is written only once) and prompt repetition for each benchmark, revealing the tendency for 'options-first' to produce significant differences.
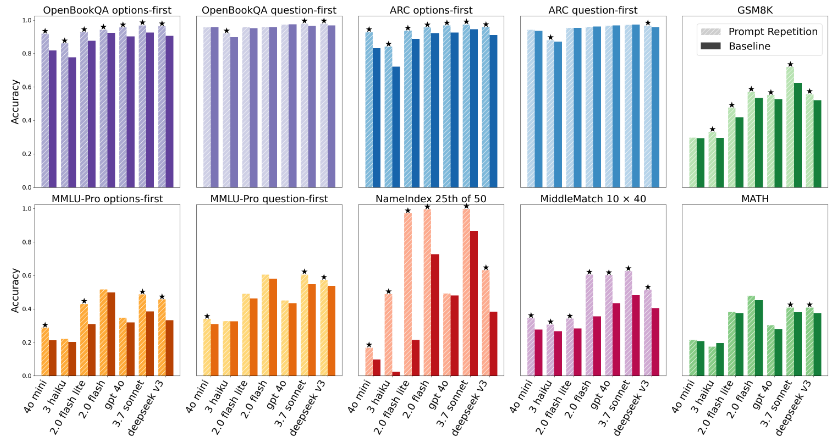
One example of extreme improvement is the original task 'NameIndex,' which the research team cited. In 'NameIndex,' participants are given a list of 50 names and asked to identify elements in a specified position, such as 'What is the 25th name?' In Gemini 2.0 Flash Lite, the correct answer rate was 21.33% when a single prompt was presented, but rose to 97.33% when the prompt was presented twice. This result suggests that repetition reduces errors where participants lose track of where they should look in a long input.
While doubling the input volume might seem like it would increase latency and costs, the research team states, 'The number of tokens generated does not increase, and the actual latency does not increase under most conditions.' The LLM process can be roughly divided into a 'prefill' stage, which reads the input, and a 'decoding' stage, which generates answers one token at a time. The research team explains that while 'decoding' is likely to affect latency, 'prefill' is easily parallelized. However, the Anthropic model did experience increased latency when the input was very long.
The research team also reported that conditions that encouraged inference, such as 'Think step by step,' showed either no effect or only small improvements. The research team explained that in conditions that encouraged inference, participants were more likely to rephrase the question or repeat key points while generating an answer, which can make the repetition on the input side redundant and less effective. The figure below summarizes the results under conditions that encouraged inference, and shows that in many cases, the improvement was not as significant as under conditions that did not encourage inference.
The research team also tested variants of prompt repetition, such as repeating the prompt three times ('x3') or explicitly stating the repetition ('Let me repeat that:'), and found that, depending on the task, 'x3' could produce even better results. Furthermore, to confirm that simply lengthening the input would not improve accuracy, the research team also tried padding the input with '.' to ensure the same length, but this did not improve performance. The research team concluded that it is possible that the mere act of 'requiring participants to read the same content again' itself is effective, rather than simply lengthening the input.
Related Posts: