




Cloudflareは海賊版サイトなどを特定の地域からアクセスできなくする「ジオブロック」対応を前年同期比で9倍に急増させていることが透明性レポートから判明

Cloudflareは2025年下半期の透明性レポートを公開しました。レポートによると、Cloudflareは海賊版サイトへの対応として特定の地域からアクセスできなくする「ジオブロック」を行うケースが急増しており、対応ケース数が前年同期比で9倍以上になっていることが判明しました。
Cloudflare Transparency Report | Cloudflare
https://www.cloudflare.com/transparency/
Cloudflare Reports Surge in Geo-Blocked Pirate Site Domains * TorrentFreak
https://torrentfreak.com/cloudflare-reports-surge-in-geo-blocked-pirate-site-domains/
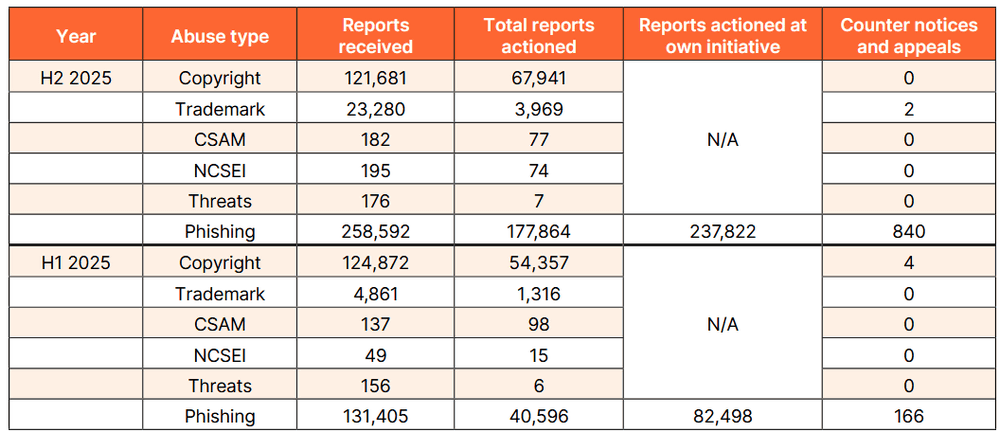
Cloudflareの透明性レポートによると、Cloudflareは2025年下半期にホスティング関連の著作権侵害の苦情を12万1681件受け取ったとのこと。そのほか商標侵害が2万3280件、児童性的虐待コンテンツ(CSAM)が182件、同意のない露骨な性的画像(NCSEI)が195件、爆破予告のような脅迫(Threats)が176件、フィッシング詐欺関連が25万8592件ありました。以下は2025年下半期と上半期を比較した表で、著作権侵害の苦情は上半期の方が3000件ほど多いですが対応したケース数は下半期の方が約1万3000件多くなっているほか、商標侵害やフィッシング詐欺関連のケースが急増していることがわかります。対応数の増加は、2025年後半に導入された自動処理によるものだとCloudflareは述べています。
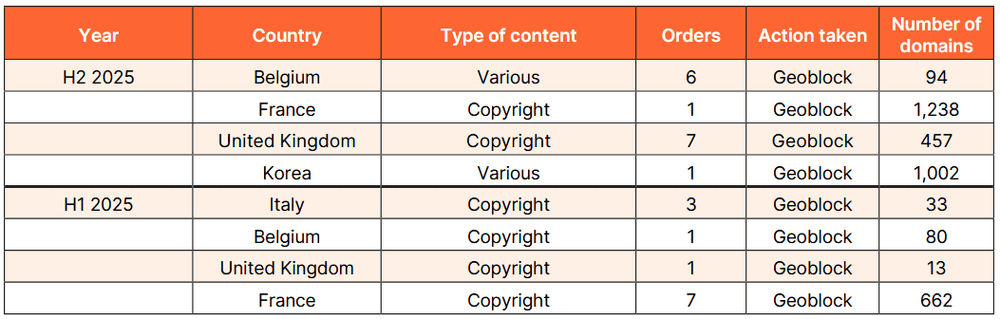
また、各国政府や裁判所の法的要請に基づき当該地域からのアクセスを禁止する「ジオブロック」の措置を講じる場合もあります。2025年上半期のジオブロックはイタリアで33のドメイン、ベルギーで80のドメイン、イギリスで13件のドメイン、フランスで662のドメインに対応しており、増加傾向を見せていました。
2025年下半期では、フランスで1238件、イギリスで457件、韓国で1002件と、ジオブロックの適用数が急増しています。2025年下半期にジオブロックの対象となったドメイン名の総数は2791件で、前年同期の308件と比較すると9倍近い大幅な増加となります。
Cloudflareは過去に、パブリックDNSリゾルバーの「1.1.1.1」から海賊版サービスへのアクセスをブロックする命令を受けましたが、「フィルタリングを行うことで世界中の正規ユーザーのサービス速度も低下させてしまう」として拒否しました。これによりCloudflareが必要な海賊版対策措置を順守していないとして、1424万7698ユーロ(約26億円)の罰金を科すことをイタリアの規制当局は決定しました。Cloudflareはこの判決に控訴していますが、世界の正規ユーザーに影響を与えることなく特定の国の規制当局による「1.1.1.1」のブロック命令に従うために、ジオブロックを用いる対応も示しています。
Cloudflareがイタリア規制当局による26億円相当の罰金に直面、パブリックDNSリゾルバー「1.1.1.1」で海賊版サイトのブロックを拒否したため - GIGAZINE

著作権に関するニュースを扱うTorrentfreakによると、ジオブロックの措置は国によって特色が大きく異なるそうです。例えばイギリスでは Cloudflareは自社が当事者ではない過去の高等法院によるISP向けのブロック命令を踏まえ、直接裁判所命令を下されたわけではないサイトについて任意で対応をしているため、数が多くなっている可能性が考えられます。ベルギーとフランスではCloudflareに下された命令に応じていますが、ベルギーでは海賊版サイトだけではなく違法ギャンブルサイトに対してもジオブロックを適用しています。
また、韓国では近年の法規制により、CDN事業者に対して国内サーバー経由で特定の違法サイトへのアクセスを制限する対応が求められており、2025年後半には数百件のサイトがブロックされました。ただし、韓国におけるブロックは従来の意味のブロックではなく、韓国国内に物理的に設置された機器を通して特定のサイトにアクセスすることを制限しているのだとCloudflareは説明しています。
・関連記事
Cloudflareの透明性レポートにより2025年上半期は著作権侵害報告件数が倍増したことが判明、対応数は50倍に - GIGAZINE
EUが禁じる「ジオブロッキング」を巡る映画、スポーツ配信、音楽業界の戦いとは? - GIGAZINE
Cloudflareがイタリア規制当局による26億円相当の罰金に直面、パブリックDNSリゾルバー「1.1.1.1」で海賊版サイトのブロックを拒否したため - GIGAZINE
Cloudflareが26億円相当の罰金判決を不服として控訴、イタリアの海賊版シールドを「オープンインターネットを危険にさらす」と批判 - GIGAZINE
・関連コンテンツ








in ネットサービス, Posted by log1e_dh
You can read the machine translated English article Cloudflare's Transparency Report rev….