A research team from Tokyo University of Science has released AIs 'GPT-OSS Swallow' and 'Qwen3 Swallow' with enhanced Japanese language capabilities.

On February 20, 2026, a research team from
📢 GPT-OSS Swallow and Qwen3 Swallow have been released.
— Naoaki Okazaki (@chokkanorg) February 20, 2026
Continuous pre-learning + SFT + reinforcement learning have been completely revamped.
An open LLM that combines Japanese language performance and inference capabilities.
Available under the Apache 2.0 license.
Qwen3 Swallow: https://t.co/tTRVGHnF4M
GPT-OSS Swallow: https://t.co/L6a2zCjc7i
GPT-OSS Swallow — Swallow LLM
https://swallow-llm.github.io/gptoss-swallow.ja
Qwen3 Swallow — Swallow LLM
https://swallow-llm.github.io/qwen3-swallow.ja
◆GPT-OSS Swallow(20B, 120B)
'GPT-OSS Swallow' is built using GPT-OSS 20B and 120B as starting points, and is constructed through three stages of fine-tuning: Continual Pre-Training (CPT), Supervised Fine-Tuning (SFT), and Reinforcement Learning (RL). Since GPT-OSS does not release models that have not undergone post-training, we perform continual pre-training on models that have undergone post-training.
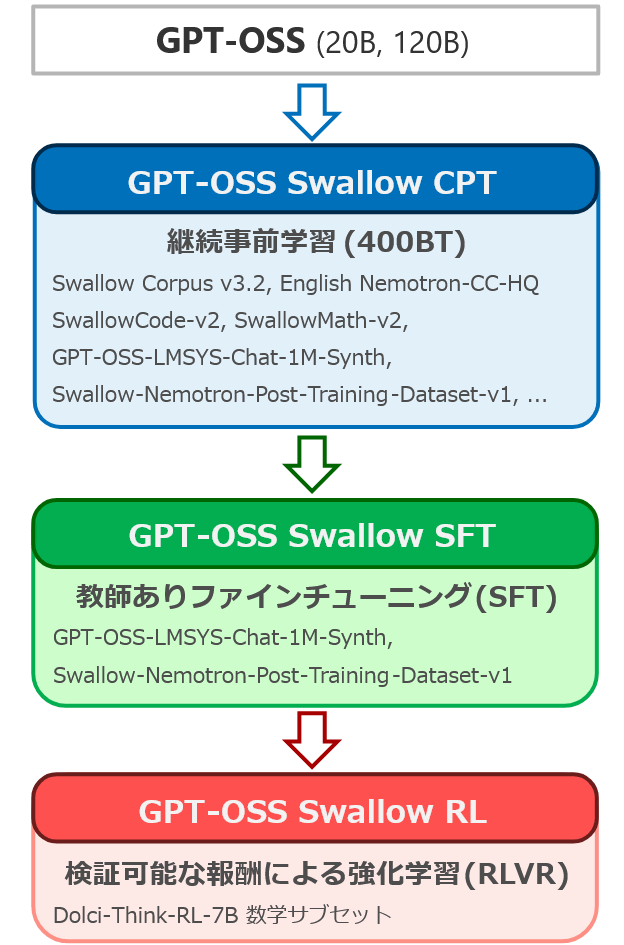
The purpose of the continuous pre-training was to improve GPT-OSS's knowledge of Japan and conversational skills in Japanese, while maintaining or improving its advanced reasoning abilities in English, mathematics, science, and programming. Nearly half of the training data was from the latest version (v3.2) of the Swallow corpus, a large-scale Japanese web text corpus. Other data included synthesized question-and-answer data from the Swallow corpus and data from the Japanese Wikipedia.
The graph below compares the performance of the GPT-OSS Swallow 20B model (red), Google's
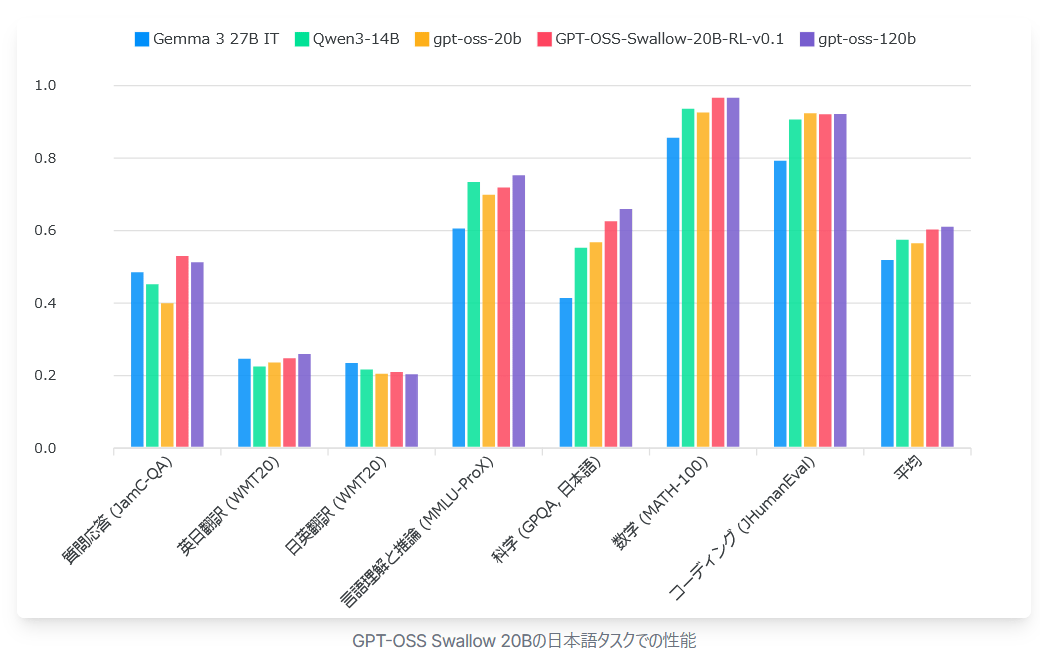
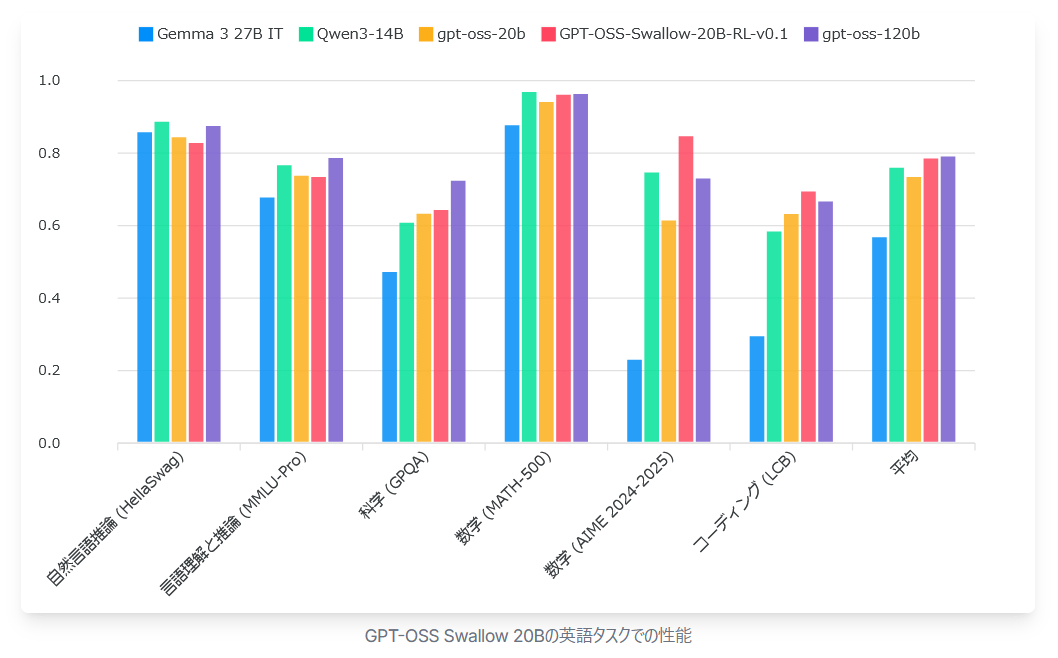
The graph below compares the performance of the GPT-OSS Swallow 20B model (red), Gemma 3 27B IT (blue), Qwen3-14B (green), gpt-oss-20b (yellow), and gpt-oss-120b (purple) on English tasks. GPT-OSS Swallow achieved the highest performance among open large-scale language models with a total parameter count of 20B or less, not only for Japanese but also for English tasks.
The graph below compares the Japanese task performance of the 120B model (orange) of 'GPT-OSS Swallow' with Alibaba's
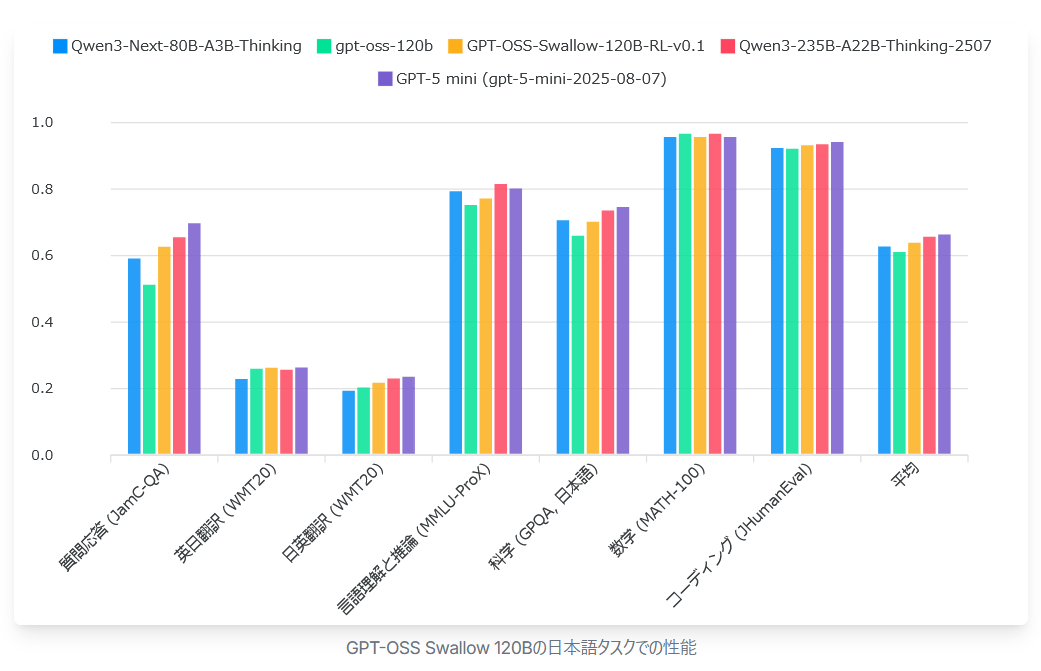
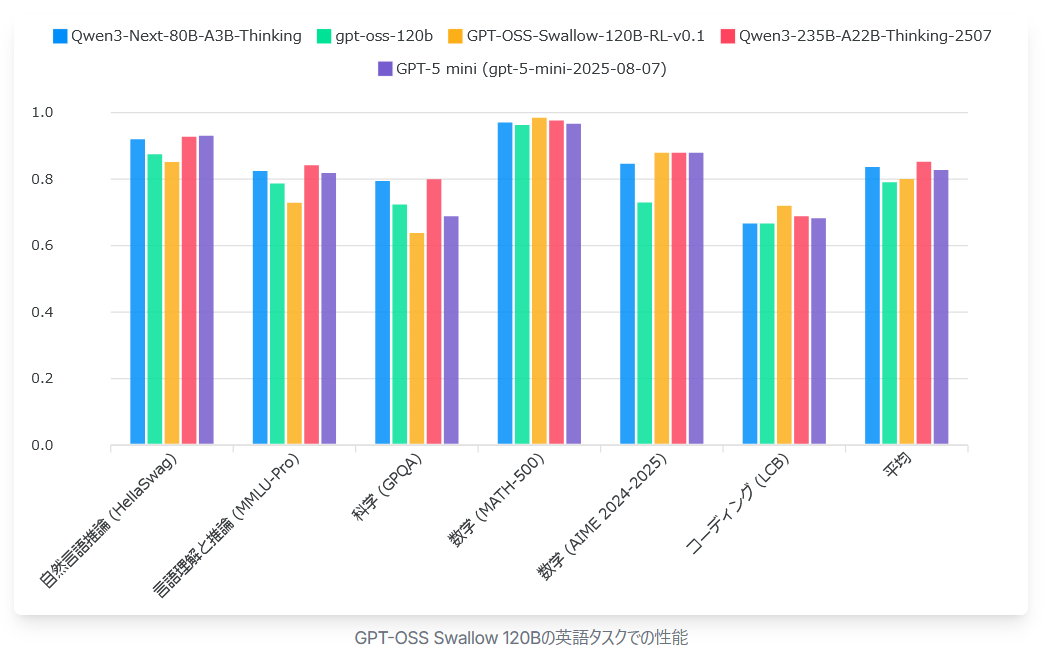
The graph below compares the performance of the 120B model (orange) of 'GPT-OSS Swallow,' Qwen3-Next-80B-A3B-Thinking (blue), gpt-oss-120b (green), Qwen3-235B-A22B-Thinking-2507 (red), and GPT-5 mini (purple) on English tasks. GPT-OSS Swallow (120B) achieved the best performance among open large-scale language models with a total parameter count of 120B or less, but in the scientific field, its performance deteriorated compared to the original gpt-oss-120b, making it a future challenge.
◆Qwen3 Swallow(8B, 30B-A3B, 32B)
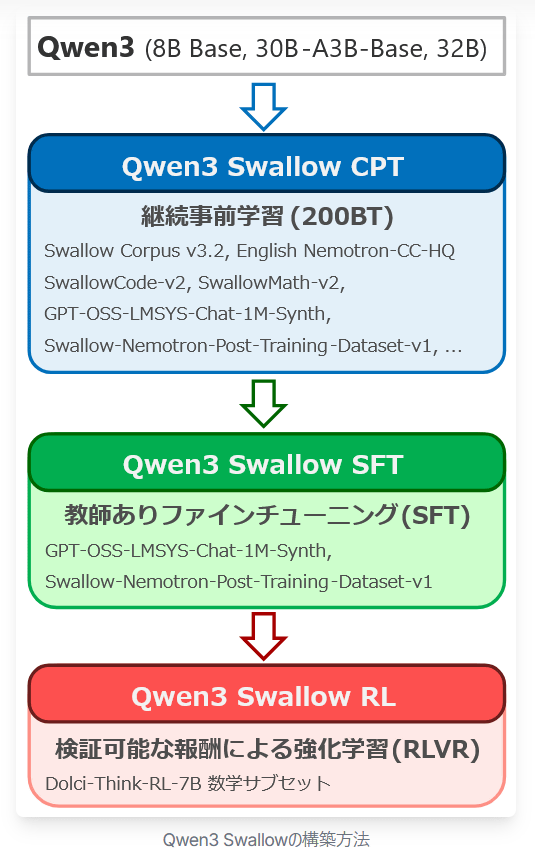
'Qwen3 Swallow' is a model that has undergone three stages of training: Continual Pre-Training (CPT), Supervised Fine-Tuning (SFT), and Reinforcement Learning (RL) based on Qwen3 Swallow 8B, 30B-A3B, and 32B.
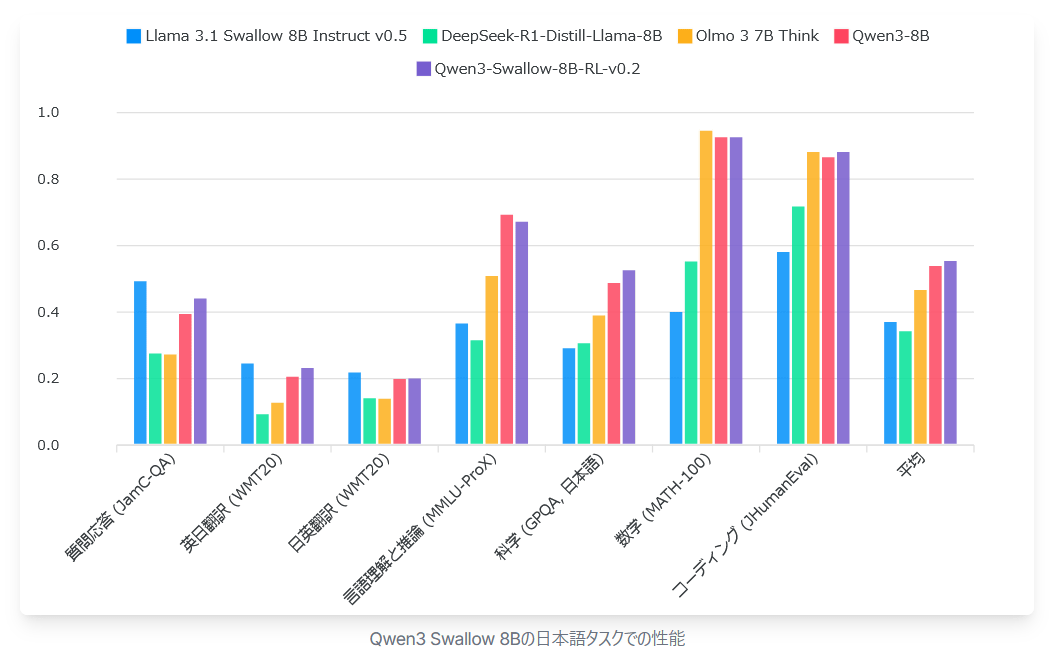
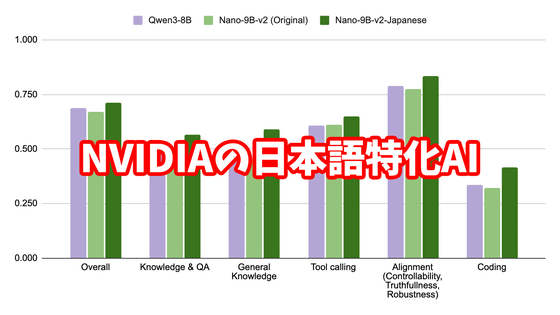
The graph below compares the Japanese task performance of Qwen3 Swallow 8B (purple) with the latest non-inferential model built by the same team,
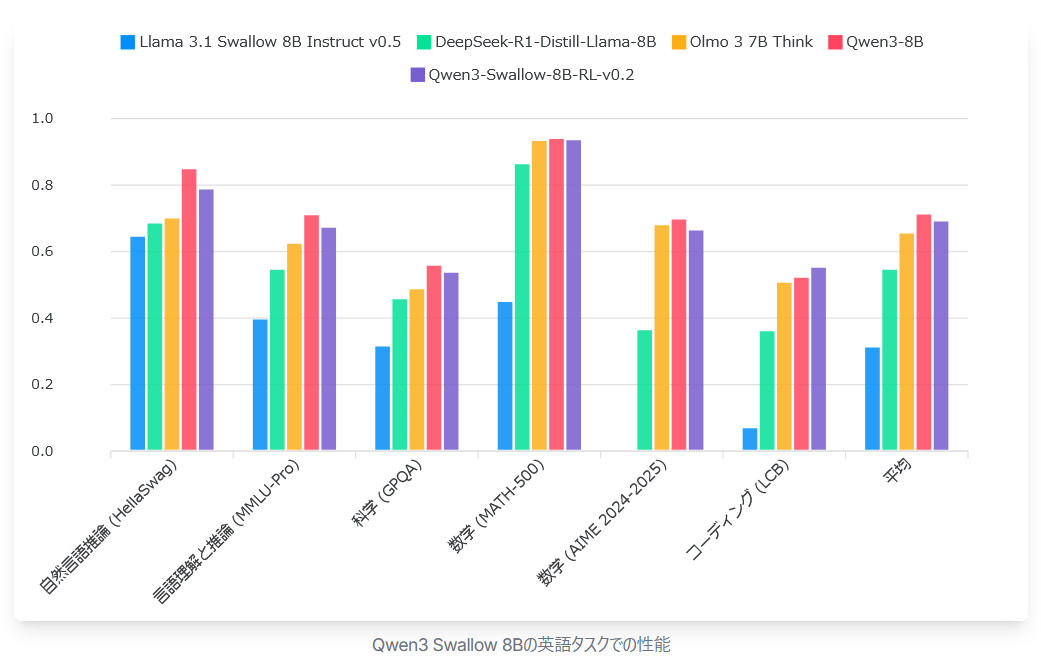
The graph below compares the English task performance of Qwen3 Swallow 8B (purple) with Llama 3.1 Swallow 8B Instruct (blue), DeepSeek-R1-Distill-Llama-8B (green), Olmo 3 7B Think (orange), and Qwen3 8B (red). Here, performance falls short of the original Qwen3 8B, suggesting there may be room for further improvement in the continuous pre-training recipe. Nevertheless, it still outperforms the similarly sized DeepSeek-R1-Distill-Llama-8B and Olmo 3 7B Think.
This graph compares the Japanese task performance of Qwen3 Swallow 30B-A3B (green) and Qwen3 Swallow 32B (red), which have similar total parameter counts, with their respective training models
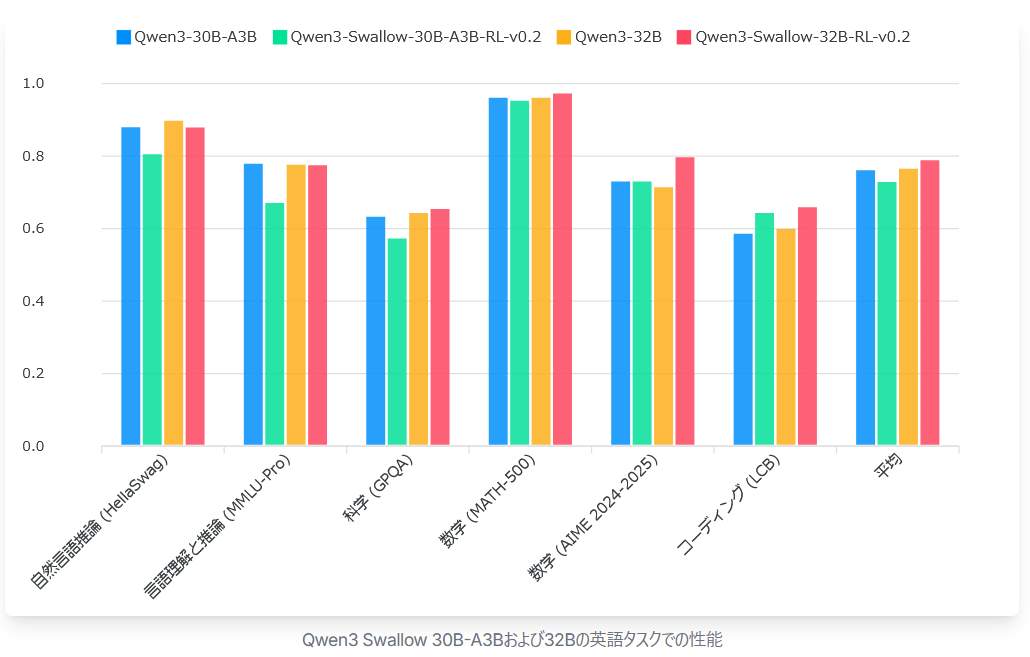
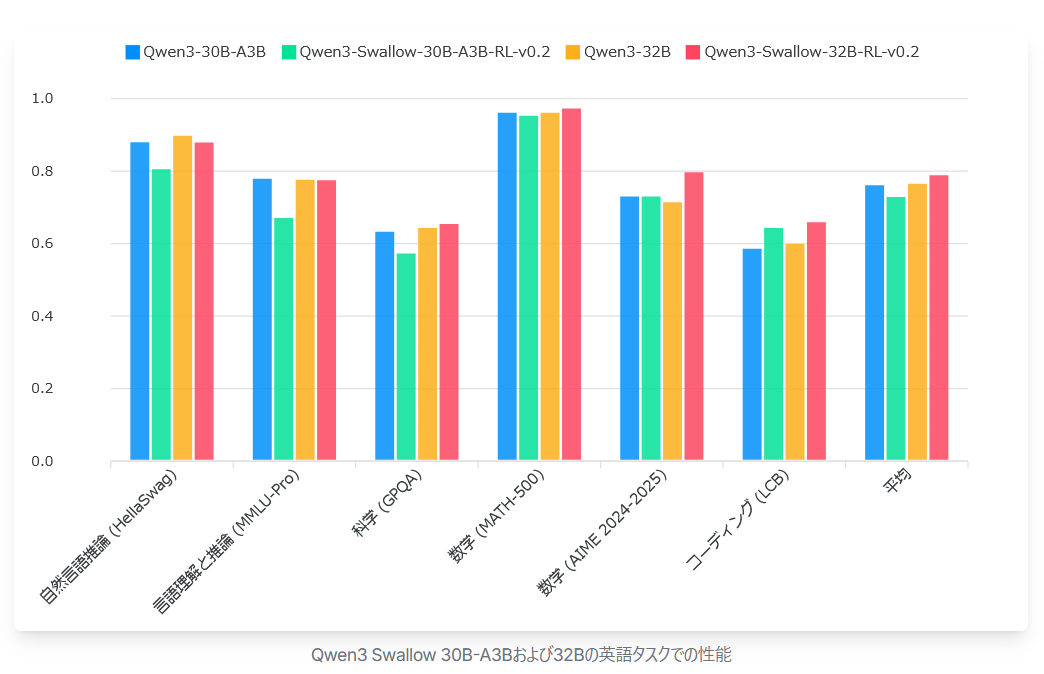
The graph below compares the performance of the same model on English tasks. As expected, Qwen3 Swallow 32B achieved the best performance among open large-scale language models with a total parameter count of 32B or less, but Qwen3 Swallow 30B-A3B performed below the baseline in many tasks and its average score was also below the baseline.
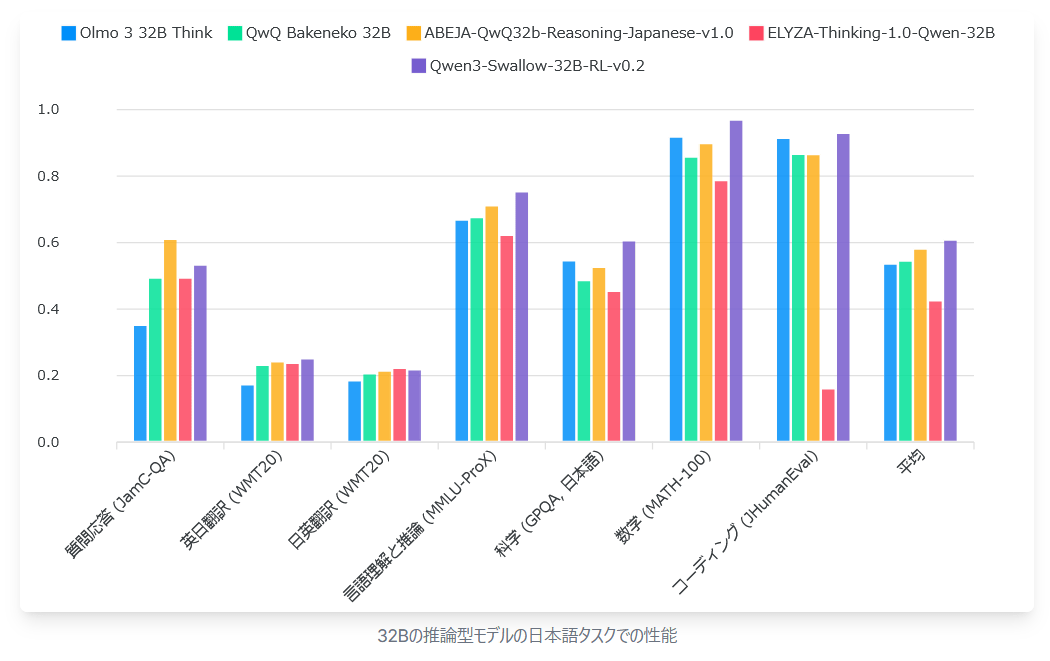
The research team also published a graph comparing the performance of Qwen3 Swallow 32B (purple) on Japanese language tasks with similar-sized inference models
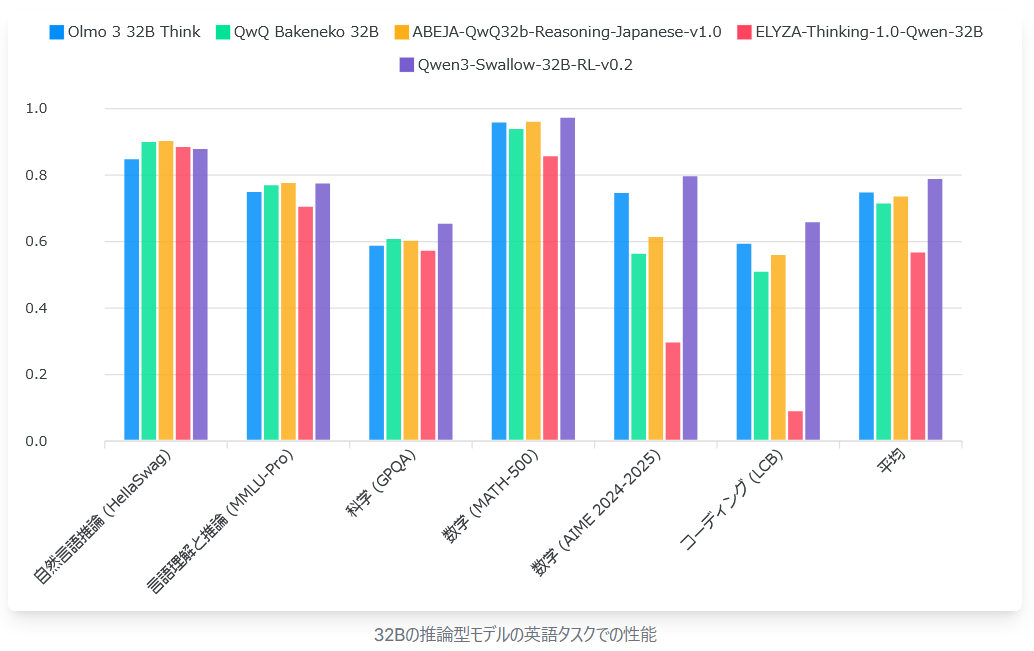
Below is a graph comparing the English task performance of the same model. As expected, the Qwen3 Swallow 32B recorded high scores overall, making it a high-performance inference model that supports both Japanese and English.
The parameters of 'GPT-OSS Swallow' and 'Qwen3 Swallow' are published under the Apache 2.0 license, and are free and open to download, customize, and host for commercial, research, and personal use.
tokyotech-llm/GPT-OSS-Swallow-20B-RL-v0.1 · Hugging Face
https://huggingface.co/tokyotech-llm/GPT-OSS-Swallow-20B-RL-v0.1
tokyotech-llm/GPT-OSS-Swallow-120B-RL-v0.1 · Hugging Face
https://huggingface.co/tokyotech-llm/GPT-OSS-Swallow-120B-RL-v0.1
tokyotech-llm/Qwen3-Swallow-8B-RL-v0.2 · Hugging Face
https://huggingface.co/tokyotech-llm/Qwen3-Swallow-8B-RL-v0.2
tokyotech-llm/Qwen3-Swallow-30B-A3B-RL-v0.2 · Hugging Face
https://huggingface.co/tokyotech-llm/Qwen3-Swallow-30B-A3B-RL-v0.2
tokyotech-llm/Qwen3-Swallow-32B-RL-v0.2 · Hugging Face
https://huggingface.co/tokyotech-llm/Qwen3-Swallow-32B-RL-v0.2
Related Posts:





in AI, Posted by log1h_ik