




日本語能力に優れた商用利用可能な大規模言語モデル「Swallow」が公開される

東京工業大学(東工大)と産業技術総合研究所(産総研)の研究チームが日本語に強い大規模言語モデル「Swallow」を公開しました。LLAMA 2 Community Licenseで提供されており、月間アクティブユーザーが7億人未満の場合は商用利用も可能となっています。
Swallow
https://tokyotech-llm.github.io/swallow-llama

日本語に強い大規模言語モデル「Swallow」を公開 英語が得意な大規模言語モデルに日本語を教える | 東工大ニュース | 東京工業大学
https://www.titech.ac.jp/news/2023/068089
東工大と産総研の研究チームは、英語での言語理解や対話能力の高い大規模言語モデルであるMeta社のLlama 2をベースに日本語能力を拡張したとのこと。Llama 2は日本語にも対応していますが、Llama 2の事前学習のデータの90%は英語であり、日本語データの割合は全体の約0.1%となっています。そのため、Llama 2は英語では高い性能を発揮するにもかかわらず日本語の読み書きは苦手となっていました。
また、Llama 2では言語データの文字や文字列の統計情報に基づいて指定されたボキャブラリーの範囲内で最適な語彙(ごい)を求めるアルゴリズム「バイト対符号化」を使用してテキストがトークン化されていますが、元となる言語データ内の日本語の量が少ないため、日本語の主要な単語や文字が含まれず、テキストが不自然な単位でトークン化されてしまっていました。
研究チームは言語モデルに日本語の文字や単語などの語彙を1万6000件追加したうえで、トレーニングに用いる日本語データを新たに作成して継続事前学習を行って、Llama 2の高い言語処理能力を維持しつつ日本語能力を強化することに成功したとのこと。語彙が増加したことで日本語のテキストをより少ないトークン数で表現することができ、トレーニングやテキスト生成における計算コストを減少させたり、入出力時に扱えるテキスト量の上限が増加したりするなどのメリットが生じています。
今回公開されたモデルはパラメーター数が70億の「Swallow 7B」モデル、パラメーター数が130億の「Swallow 13B」モデル、パラメーター数が700億の「Swallow 70B」モデルの3つ。各種の日本語能力をテストするベンチマークの平均においてそれぞれベースとなったLlama 2のモデルのスコアを改善しています。
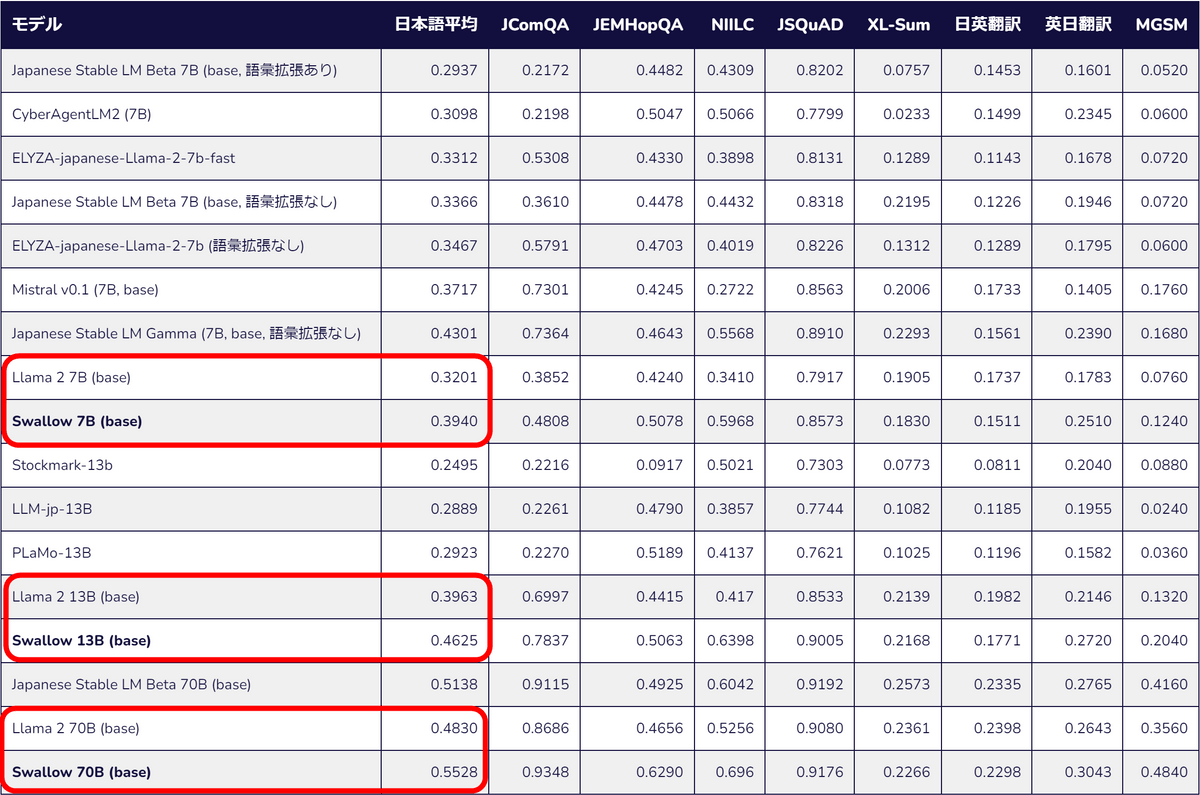
それぞれのモデルはHugging Face上でホストされており、商用利用可能なLLAMA 2 Community Licenseで提供されています。
また、プロジェクトメンバーの1人である藤井一喜氏による解説がエンジニア向け情報共有コミュニティ・Zennにて公開されています。気になる人は確認してみてください。
・関連記事
Metaの大規模言語モデル「LLaMa」に入力した文章がどのようなトークンとして認識しているかを確認できる「LLaMA-Tokenizer」 - GIGAZINE
大規模言語モデルの開発者が知っておくと役立つさまざまな数字 - GIGAZINE
AIに「それがファイナルアンサーなの?」「全力を尽くして」といった感情的な命令文を伝えるとパフォーマンスが向上する - GIGAZINE
日本語言語モデル「Japanese StableLM Alpha」をStability AIがリリース - GIGAZINE
無料で商用利用可能な大規模言語モデル「Mixtral 8x7B」が登場、低い推論コストでGPT-3.5と同等以上の性能を発揮可能 - GIGAZINE
・関連コンテンツ








in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article Commercially available large-scale langu….