




DeepSeekがAI言語モデルの生成速度を最大85%向上させる「DSpark」を公開

DeepSeekが大規模言語モデルの文章生成を高速化する投機的デコード技術「DSpark」を公開しました。DSparkは新しい言語モデルではなく、プレビュー版のDeepSeek-V4-FlashおよびDeepSeek-V4-Proの既存チェックポイントに投機的デコード用モジュールを追加したものです。DeepSeekは実際のユーザーからのリクエストを処理する運用環境で、従来方式と比べてユーザーあたりの生成速度を最大85%向上できたと報告しています。
DeepSpec/DSpark_paper.pdf at main · deepseek-ai/DeepSpec · GitHub
(PDFファイル)https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
deepseek-ai/DeepSeek-V4-Flash-DSpark · Hugging Face
https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash-DSpark
deepseek-ai/DeepSeek-V4-Pro-DSpark · Hugging Face
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark
一般的な大規模言語モデルは、文章を構成するトークンを1つずつ順番に生成します。そのため、出力が長くなるほど推論に時間がかかり、リアルタイムの会話や複数段階で処理を進めるAIエージェントでは待ち時間が問題になります。
投機的デコードは、小型のドラフトモデルが次に続く複数のトークン候補を先に作り、大型のターゲットモデルがまとめて検証することで処理を速める手法です。ターゲットモデルは候補トークンを一括で検証し、自身の出力分布と整合する先頭からの連続部分だけを採用します。そして、途中で不採用になった場合は、それ以降の候補を破棄し、その位置からターゲットモデルが次のトークンを生成して処理を進めます。この仕組みにより、ターゲットモデル単体で生成した場合と同じ出力分布を保ちながら、複数のトークンをまとめて確定できます。
ただし、従来の投機的デコードには速度と候補の質の両立という課題がありました。候補を順番に生成する自己回帰型のドラフトモデルは文脈に沿った候補を作りやすい一方、候補を増やすほど処理時間が延びます。対して、複数の候補を並列に作る方式は高速ですが、候補同士のつながりを十分に考慮できず、後ろのトークンほどターゲットモデルに不採用と判断されやすくなります。
以下のグラフは、候補列内の位置ごとの条件付き採用率を示したものです。並列方式のDFlashは候補列の後半で採用率が低下する一方、DSparkは逐次処理を組み合わせることで低下を抑えています。
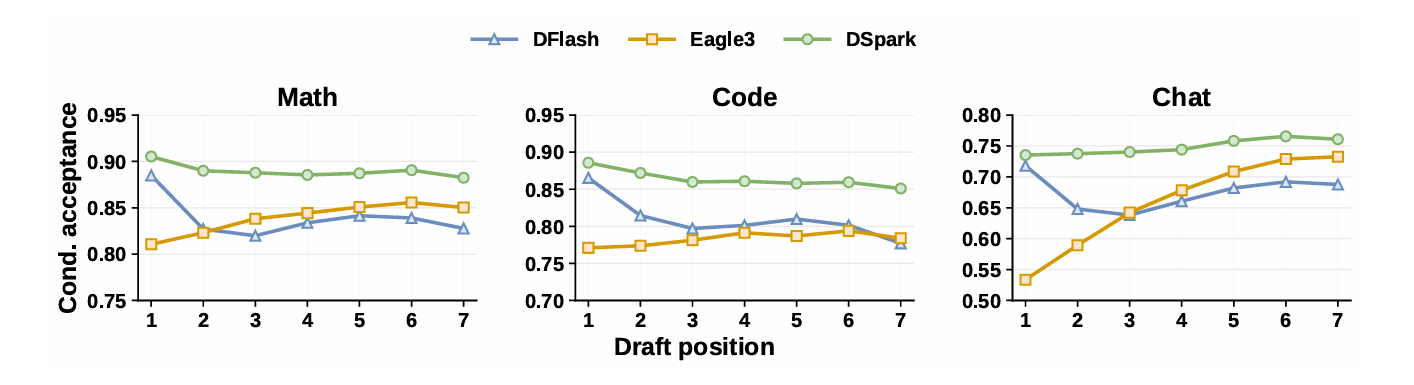
DSparkは大部分の候補を並列に生成するバックボーンと、候補トークン間の依存関係を取り込む軽量な逐次処理ブロックを組み合わせています。並列処理の速度を保ちながら、先に生成した候補を踏まえて後続候補を生成できるため、候補列に不自然な組み合わせが生じることを減らせる設計です。DeepSeekは、この半自己回帰型の構造によって並列方式で起きやすい候補列の後半での採用率低下を抑えられると説明しています。
DSparkは候補を何トークンまで検証するかも固定せず、リクエストごとに調整します。候補列の各位置までが連続して採用される見込みを推定する信頼度ヘッドと、サーバーのリアルタイムの処理性能を踏まえるスケジューラーを組み合わせ、採用されにくい後続候補を検証対象から外します。多数のユーザーが同時に利用する環境では、不要な検証を減らして全体のスループット低下を抑える仕組みです。
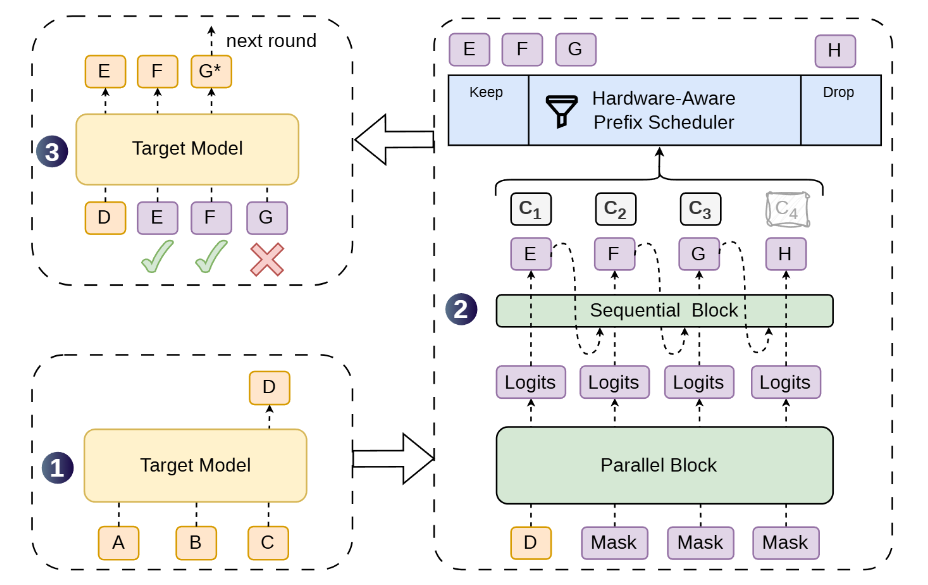
以下はDSparkの処理の流れ。並列ブロックが複数の候補を生成し、逐次ブロックが候補間の依存関係を加味します。候補ごとの信頼度を基に、検証する範囲を絞り込んでからターゲットモデルが一括で検証します。
オフライン評価では、数学推論、コード生成、日常的なチャットを対象に、Qwen3の40億、80億、140億パラメーターのモデルとGemma4-12Bを用いて検証しました。Qwen3の3モデルでは、DSparkは自己回帰型のEagle3と比べて、1回の検証で採用される候補トークンの平均数を26.7%〜30.9%増やし、並列型のDFlashと比べても16.3%〜18.4%増やしたとしています。数学推論やコード生成では、日常的なチャットよりも平均採用長が長い結果が示されました。
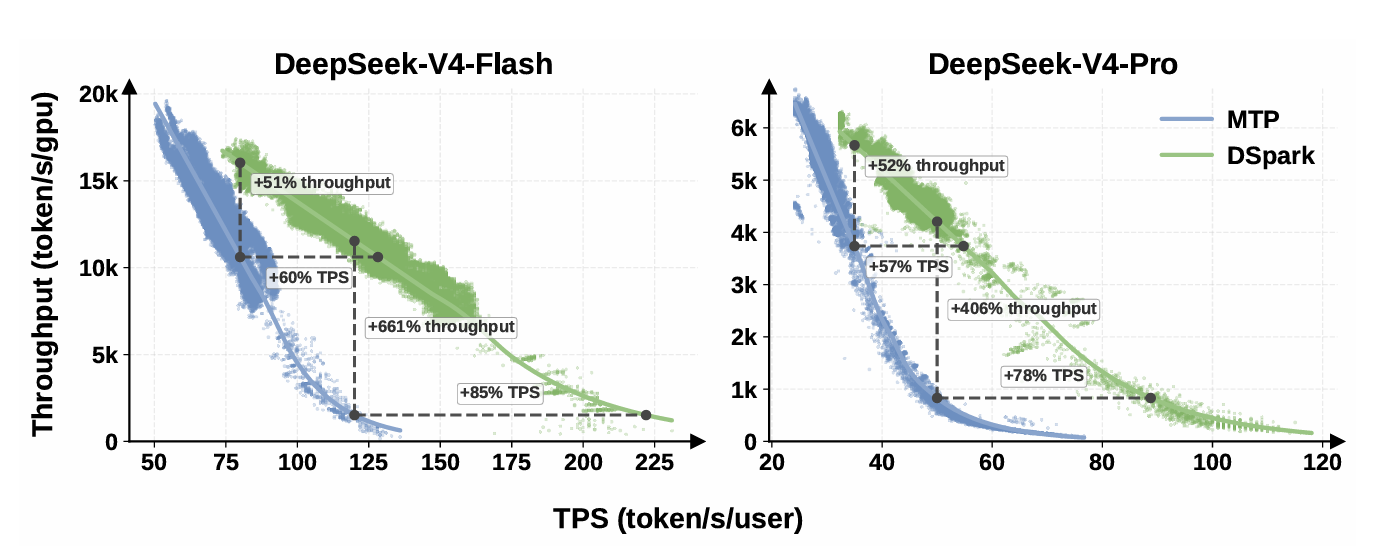
DeepSeek-V4-FlashとDeepSeek-V4-Proのプレビュー版を使った実運用環境では、最大5トークンの候補を作るDSpark-5を、従来のMTP-1方式と比較しました。同程度の総出力スループットで比べた場合、DeepSeek-V4-Flashではユーザーあたりの生成速度が60%〜85%、DeepSeek-V4-Proでは57%〜78%向上したと報告されています。DeepSeek-V4-Flashでユーザーあたり毎秒80トークンを保証する条件では総出力スループットが51%向上し、Flashで毎秒120トークン、Proで毎秒50トークンを保証する厳しい条件でも、DSparkは検証処理の無駄を抑えてスループットを維持したとしています。
DSparkと従来のMTP-1における、ユーザーあたりの生成速度とGPUあたりの総出力スループットの関係を示したグラフがこれ。DeepSeek-V4-FlashとDeepSeek-V4-Proの両方で、DSparkは応答速度を高く保ちながら、より高い総出力スループットを示したとしています。
DeepSeekは、プレビュー版のDeepSeek-V4-FlashおよびDeepSeek-V4-Pro向けにDSparkのチェックポイントを公開しているほか、投機的デコード向けの訓練リポジトリ「DeepSpec」もオープンソースとして公開しており、Eagle3、DFlash、DSparkの実装を利用できます。各モデルのinferenceフォルダーには最小限の推論例があり、モデル配布ページにはDeepSeek-V4をローカルで動かす手順も掲載されています。公開されたDeepSeek-V4-Flash-DSparkおよびDeepSeek-V4-Pro-DSparkのモデル重みは、MITライセンスで提供されています。
・関連記事
DeepSeekは低価格AIでどうやって稼ぐつもりなのか? - GIGAZINE
ついに「DeepSeek-V4」が登場、Claude Opus 4.6を超える性能のオープンモデル - GIGAZINE
DeepSeek V4 Flash専用に設計されたコンパクトなネイティブ推論エンジン「DwarfStar 4」 - GIGAZINE
中国製高性能AI「DeepSeek-V4-Pro」の75%割引が永続化される、DeepSeek専用設計のコーディングエージェント「Reasonix」にも注目が集まる - GIGAZINE
「DeepSeek V4 Proはアメリカの主要AIモデルに比べて約8カ月遅れているが現状最も高性能な中国製AIモデル」とアメリカ政府のAIリスク管理機関であるCAISIが報告 - GIGAZINE
コストをなんとわずか17分の1に節約できるDeepSeek V4 Proを使ったClaude Codeエージェントループ「deepclaude」 - GIGAZINE
・関連コンテンツ







in AI, Posted by log1i_yk
You can read the machine translated English article DeepSeek has released 'DSpark,' which ca….