




生成AIの4か月間に及ぶ画像・動画VAE実験から得られた教訓

動画生成技術は目覚ましい進化を遂げていますが、根幹を支えるVAE(Variational Autoencoder)の設計と訓練には依然として多くの困難が伴います。AIラボのLinumが画像と動画の両方に対応するVAEの開発に挑んだ過程で直面した課題や得られた貴重な知見について自社のブログにて詳細に解説していました。
Better Reconstruction ≠ Better Generation | Field Notes by Linum
https://www.linum.ai/field-notes/vae-reconstruction-vs-generation

動画生成の分野では拡散トランスフォーマーが主流となっているものの、計算コストが膨大でありピクセル空間で直接処理するのは現実的ではありません。例えば720✕1280pxの解像度を持つ動画を5秒間24fpsで撮影する場合、ピクセル空間で処理すると単純計算で以下のデータ量が必要になります。
$$720 \times 1280 \times 5 \times 24 = 110{,}592{,}000 \text{ raw pixels}$$ ごく短い動画で1億1000万トークンを処理するのは馬鹿げているため、動画をよりコンパクトな潜在空間に圧縮することのできるVAEの役割が不可欠となります。「エンコーダーによる入力データの圧縮」と「デコーダーによる元データの再構成」によりデータの本質的な特徴を捉えるのがオートエンコーダーの目的ですが、オートエンコーダーの一種であるVAEの特徴はエンコーダーが単一点$z$ではなく$z$の確率分布をパラメータとして出力する点にあり、VAEの出力を活用することにより潜在空間からのサンプリングが可能になります。
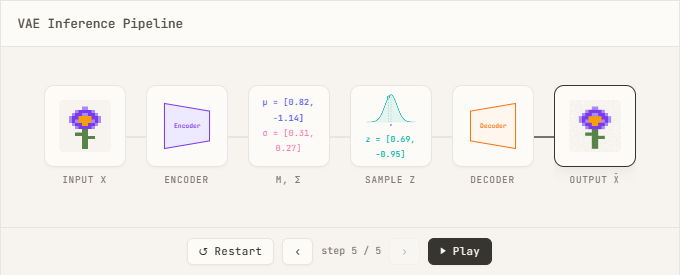
実際に行う演算としては、データサンプル$x$をエンコーダに通して各潜在次元に対する平均と標準偏差を求めることにより多変量ガウス分布が定義され、多変量ガウス分布から$z$をサンプリングしデコードすることで再構成値 $\hat{x}$ を得ます。したがって、VAEを訓練するということは以下の損失を最小化するということになります。
$$\mathcal{L}_{\text{modality}} = \lambda_1 \cdot \mathcal{L}_{\text{KL}} + \lambda_2 \cdot \mathcal{L}_{\text{recon}} + \lambda_3 \cdot \mathcal{L}_{\text{perceptual}} + \lambda_4 \cdot \mathcal{L}_{\text{adversarial}}$$
・$\mathcal{L}_{\text{KL}}$: 潜在変数$z$の確率分布と正規分布とのKLダイバージェンス(潜在分布を単純な分布に近づける)
・$\mathcal{L}_{\text{recon}}$: 再構成損失(元のデータと再構成されたデータの差を最小化する)
・$\mathcal{L}_{\text{perceptual}}$: 知覚的損失(再構成されたデータと元のデータの知覚的な違いを最小化する)
・$\mathcal{L}_{\text{adversarial}}$: 敵対的損失(生成器が本物のように見えるようにする)
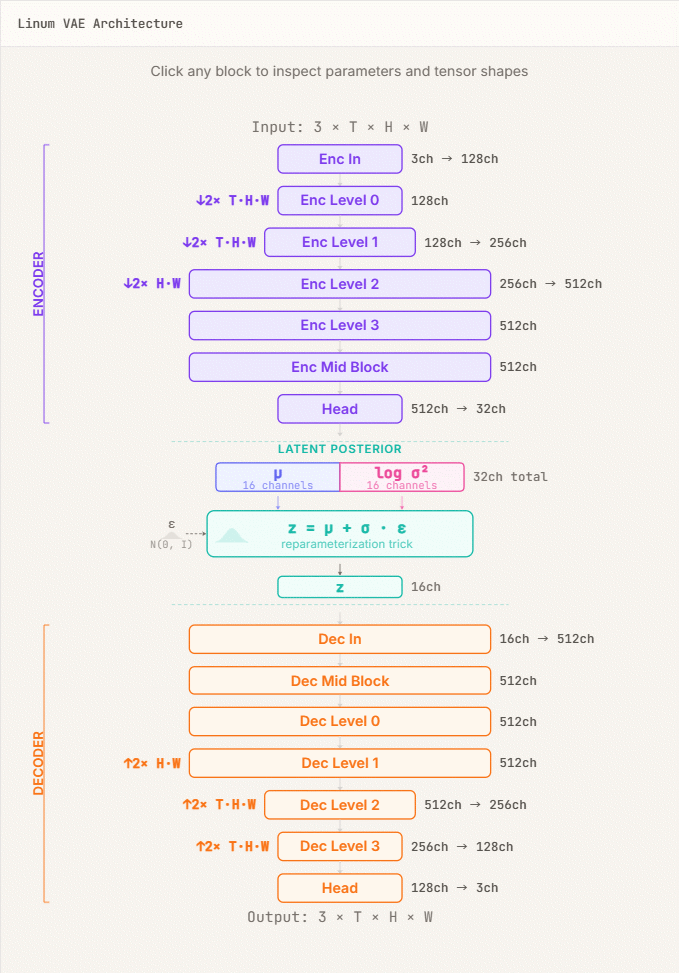
Linumはまず動画のみを対象としたVAEの構築に着手し、畳み込みニューラルネットワーク(CNN)ベースのエンコーダー・デコーダーアーキテクチャを採用しました。
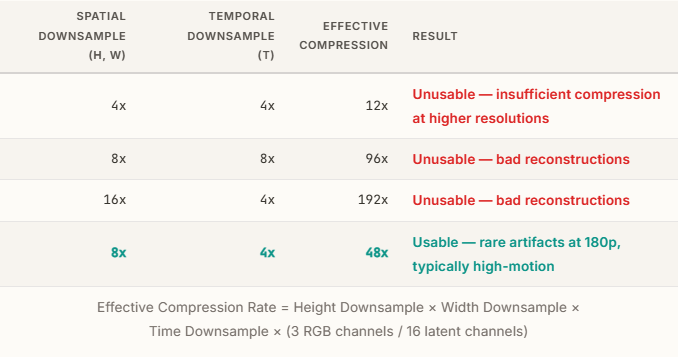
メモリ使用量の最適値を探るため、まずは4倍の空間圧縮と4倍の時間圧縮から始めてより高い圧縮率の実験を行った結果、8倍の空間圧縮と4倍の時間圧縮(合計48倍の圧縮)で実用的なレベルに達することが判明しました。
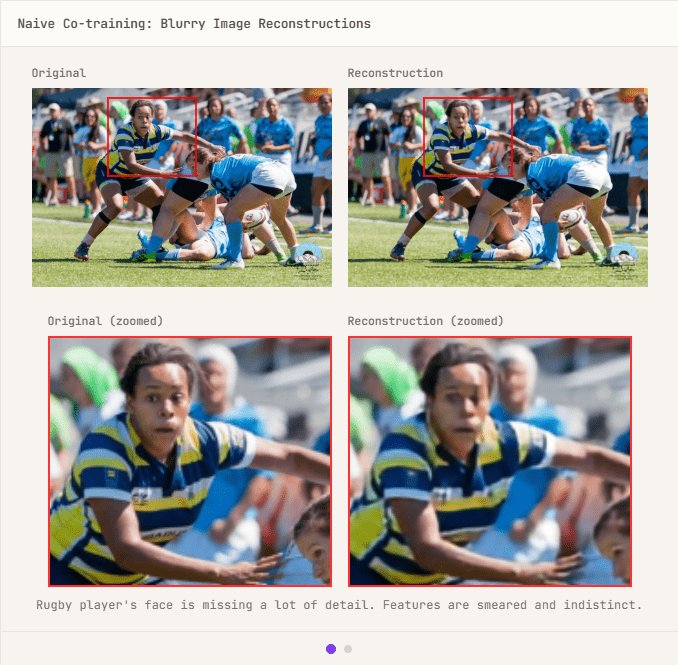
動画のみを対象とするVAE構築については所要時間がたったの1週間と非常に順調であったものの、静止画像を対象に含めたところ「画像再構成の品質低下」という問題が発生しました。
まずは画像の再構成について「静止画」のアプローチが不安定である可能性があると考え静止画像のみを用いてネットワークの再学習をおこなったところ、動画のみを用いたVAEと同等の性能が得られるようになったので、損失関数を詳しく調べ「静止画像+動画」で学習を行った場合に再構成結果が劣化する原因を探ることにしました。すべての次元の再構成損失の総和($C × T × H × W$)をバッチサイズ($B$)で割る定形式は以下の通りとなります。
$$\mathcal{L}_{\text{recon}} = \frac{1}{B} \sum_{i=1}^{B} \sum_{c,t,h,w} \text{NLL}(x_i, \hat{x}_i)$$上の式を精査することにより「損失の大きさ」がテンソルサイズに比例するという問題があることが判明しました。何故テンソルサイズに比例することが問題かというと、静止画像と動画ではテンソルサイズが大きく異なるからです。単純に修正するならばサンプルごとの平均値を取得する以下の定型式を適用することになります。
$$\mathcal{L}_{\text{recon}} = \frac{1}{B} \sum_{i=1}^{B} \frac{1}{C \cdot T \cdot H \cdot W} \sum_{c,t,h,w} \text{NLL}(x_i, \hat{x}_i)$$しかし今度はピクセルあたりの勾配がテンソルサイズに反比例するようになるため、静止画像の復元に対して過度に重点を置くことになってしまいます。解決策として参照形状($S_{\text{ref}}$)に対する相対的な正規化が導入されました。
$$\text{scale} = \frac{|S_{\text{ref}}|}{C \cdot T \cdot H \cdot W}$$ $$\mathcal{L}_{\text{recon}} = \text{scale} \cdot \frac{1}{B} \sum_{i=1}^{B} \sum_{c,t,h,w} \text{NLL}(x_i, \hat{x}_i)$$上の式を適用することにより解像度に関わらず損失の大きさを一定に保ちつつ異なる解像度やモダリティの重要性を再評価できるようになったため、試しに静止画像と動画に同じ重み付けを行ってみたところ、今度は計算結果がNaNになってしまう「NaN地獄」とLinumが呼ぶ問題が発生しました。当初はモデルが静止画像と動画を識別し辛いことによる現象ではないかと疑い対策としてFiLM(Feature-wise Linear Modulation)レイヤーを導入したりしたものの効果はなく、正攻法を諦めトレーニング安定化の「ハック」としてAdaptive Gradient Clipping(AGC)を導入したところトレーニングは安定するようになりました。ただし今度は再構成画像に変色した斑点が発生するようになってしまいました。
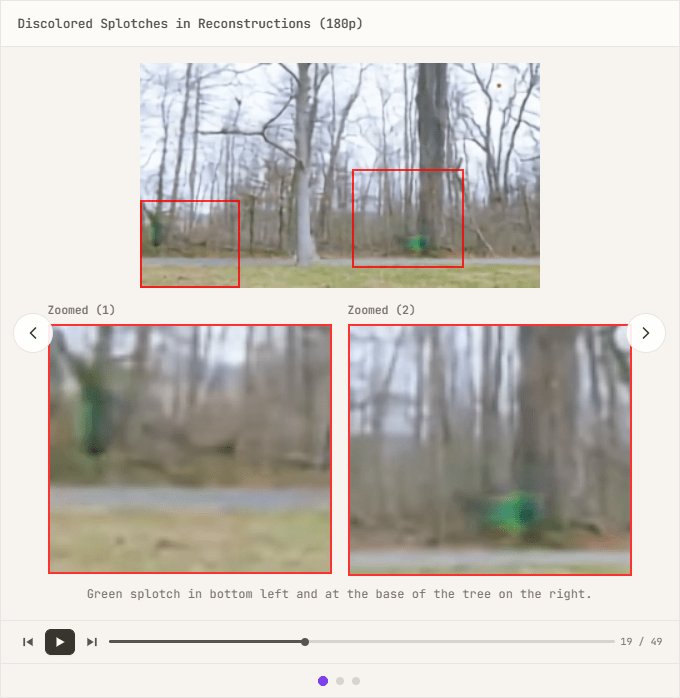
過去に同様の事例が報告されていないかを調査したところLiteVAEの開発者が同様の問題に直面していたことがわかったため、彼らの解決策である Self-Modulated Convolution(SMC)を導入することにしました。SMCは出力アクティベーションの代わりに「畳み込み重み」を正規化する手法であり、各重みは入力チャンネルごとに学習されたパラメータ$s_i$によってスケーリングされ各入力チャンネルが出力にどれだけ寄与するかを制御できるというものです。
$$w'_{ijk} = \frac{s_i \cdot w_{ijk}}{\sqrt{\sum_{i,k}(s_i \cdot w_{ijk})^2 + \epsilon}}$$SMCはネットワークが各チャンネルを独立して変調できかつ活性化の異常な増大を防ぐことができるため、モデルは大きな振幅の信号をより柔軟に扱えるようになりひいては斑点の発生を回避するのに役立ちます。3か月間に及ぶ試行錯誤を経てVAEは正常に動作するようになりましたが、最終チェックポイントである720pxのデータに最適化してしまい低解像度の画像や動画の再構成が疎かにされてしまったため、さらに2週間を費やして様々な解像度のデータを同時にトレーニングすることになりました。
当初LinumはVAEを構築する過程においてピクセル単位で完璧に画像を再構成することを目指していましたが、研究が進むにつれて再構成の品質が高いからといって必ずしも下流の拡散モデルの生成品質向上に繋がらないことが明らかになってきました。例えばJPEG圧縮が過剰に行われているような低品質な画像データを使用するとノイズとして認識されてしまうため実際のディテールよりも復元が困難であり、VAEに無理やり完璧に復元させようとするとディテールを捉えようとするあまり潜在空間が歪められてしまいます。つまり再構成の品質に過度にこだわるとVAEは単にノイズを吐き出すようにしかならないということです。
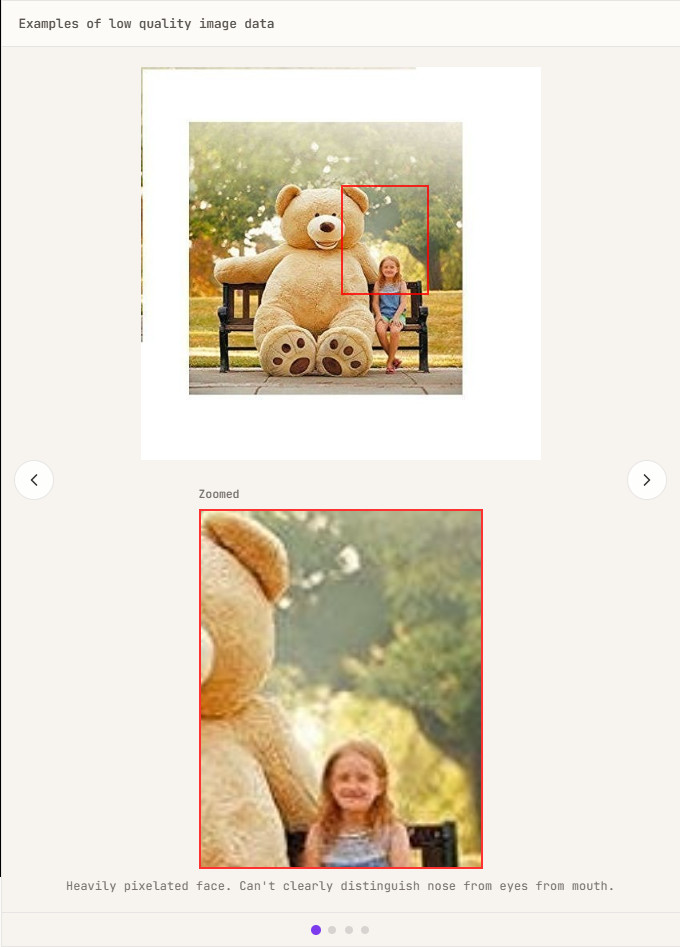
解像度を跨いだ同時学習が非常に不安定だったのは再構成の品質にこだわりすぎたことが原因であるとわかったことから、より高品質な再構成を行うVAEがより劣った拡散モデルを生成する場合があり、ひいては拡散モデルの視覚概念の学習能力を損なってしまう可能性に気付くこととなりました。再構成の品質を追求することは必ずしも生成品質の向上にはつながらないという事実は4か月間に及んだ今回の実験から得られた重要な教訓である、とLinumのブログには記されています。
・関連記事
生成AIツール「ComfyUI」の複雑怪奇なUIをスッキリ分かりやすくできる公式機能「App Mode」が登場 - GIGAZINE
Luma AIの新型画像生成モデル「Uni-1」がベンチマークでNano Banana 2・GPT Image 1.5を凌駕する性能を発揮 - GIGAZINE
ローカルで動作する動画生成AI「LTX-2.3」が登場&無料のPCアプリ「LTX Desktop」も公開される - GIGAZINE
Googleが画像生成AI「Nano Banana 2」をリリース、より高速に正確な画像を生成可能に - GIGAZINE
オープンソースの画像生成AI「GLM-Image」を中国企業のZ.aiが発表、自己回帰モデルと拡散モデルのハイブリッド - GIGAZINE
画像生成&編集AI「Qwen-Image-Edit-2511」登場、人物やオブジェクトの一貫性が向上&人気LoRAを内蔵してさらに高品質化 - GIGAZINE
Stable Diffusion 3 Mediumがオープンリリースされる、比較的小型で個人利用に最適なモデルに - GIGAZINE
グラボを買い替えずとも画像生成AIの実行速度を高速化できる「Stable Diffusion WebUI Forge」を実際にインストールして生成速度を比較してみた - GIGAZINE
・関連コンテンツ



in 教育, AI, サイエンス, Posted by log1c_sh
You can read the machine translated English article Lessons learned from a 4-month image and….