機械学習の「Q学習」にベイズ推定を取り入れると一体何が起こるのか?
機械学習における強化学習の一種である「Q学習」は、行動主体となるエージェントが現在の状況と未来の状況、そして得られる報酬から最適な答えを学習する手法です。そんなQ学習にベイズ推定の要素を取り込む研究が機械学習エンジニアのBrandon Da Silva氏によって行われています。
brandinho.github.io/bayesian-perspective-q-learning/
https://brandinho.github.io/bayesian-perspective-q-learning/
Q学習の基本的な考え方は「ある状態の価値(Q値)は、得られる報酬と次の時点の状態の価値から決まる」というもので、以下の式で表されます。「q(s, a)」は現在の状態からある行動を取った時の価値、「r」は得られる報酬、「q(s', a')」は次の地点での状態からある行動を取った時の価値を表しており、「γ」は次の地点の価値を現在の価値に割り戻す割引率を表します。
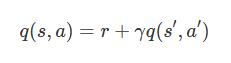
実際のQ学習では、Q値は「α」で示される学習率にも左右されます。学習率とは新しい情報が学習に及ぼす影響度のことで、外部であらかじめ固定しておくハイパーパラメータです。学習率も含めたQ学習の式は以下のようになります。
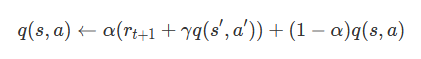
Q学習の「新しい情報をもとに現在の情報を更新していく」という構図は、ベイズ推定によく似ています。Q値が正規分布に従うと仮定すると、上記の数式はベイズ推定における事後確率を求める式に当てはめることができるとのこと。事後分布の平均μと分散σ^2は以下の式で表すことができます。
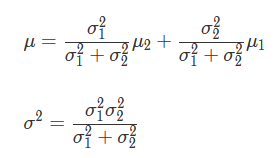
Q値の式とベイズ推定における事後分布の平均を求める式を比較すると、Q学習ではα、つまり学習率はハイパーパラメータであるため、黄色と紫色の値は固定値となることがわかります。Silva氏はQ学習について、ベイズ推定で事後確率を平均のみで更新していく操作と捉えられると解説。
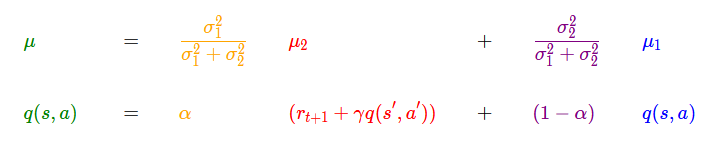
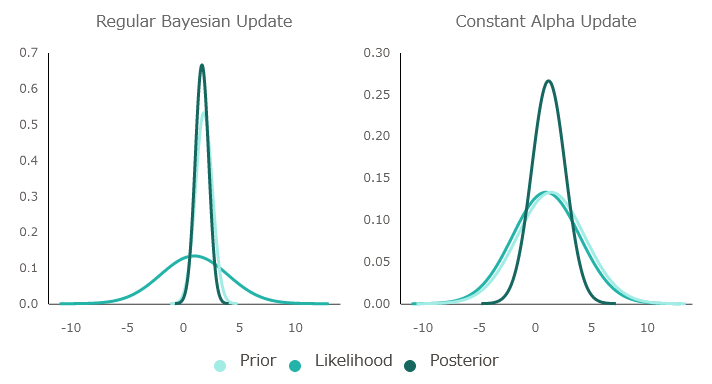
通常のベイズ推定とαを固定したベイズ推定について、情報が更新されていく様子を可視化するとこんな感じ。αを0.5として、最初のスタート地点はどちらも同じです。
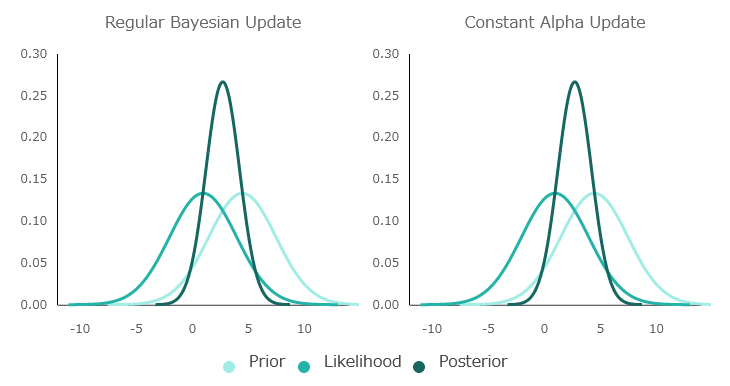
通常のベイズ推定では、αの値を操作して「現在の情報」を優先させることで情報を効率良く更新していますが、αを固定した場合では新しい情報と古い情報を等しく扱うため、更新が遅れます。

学習を重ねていくごとにその差はどんどん拡大。つまり、Q学習でもベイズ推定と同じように学習率を動的に変更した方が早く学習できる、というのがSilva氏の意見です。実際のQ学習の研究でも、学習を重ねるごとに学習率を低減させていく手法は存在するとのこと。Q学習にベイズ推定の要素を取り込むと、エージェントは学習を重ねるごとに「今の情報を重んじるのか、新しい情報を重んじるのか」を柔軟に変えながら行動していくことになります。
Q学習を実感してもらうため、Silva氏はエージェントを用いたゲームを用意しています。ゲームのフィールドは「ゴール」「崖」「危険地帯」「ローミング状態」に分かれており、報酬はそれぞれゴールは「50」、崖は「-50」、危険地帯は期待値「-15」分散「1」の確率分布、ローミングステートは期待値「-2」の確率分布となっています。

まずは学習回数を「40」に設定して「Play」をクリック。

エージェントが動き始めました。

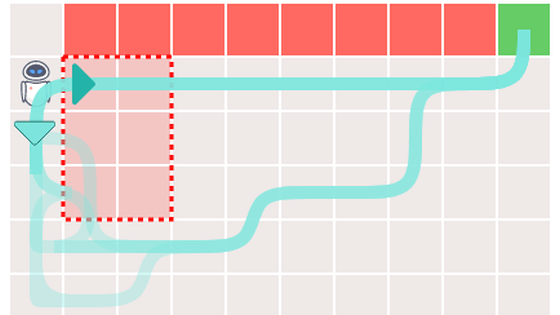
緑色のマスはQ値が高く、赤色のマスはQ値が低いことを表しています。エージェントはマスと進む方向ごとにQ値を持っており、行動する際はQ値が高いマスへと進みます。

学習回数が40回では、タイムアウトとなりゴールすることができませんでした。

学習回数を5000回にすると、無事ゴールに到達することができました。学習回数を増やせば増やすほど、エージェントが迷わずゴールへと進む様子を観察することができます。

ベイズ推定を用いたQ学習では、十分に学習回数が大きければ、エージェントは崖から落ちずにゴールへの道を見つけることができるとのこと。

しかし、ベイズ推定を用いたQ学習には問題もあるとSilva氏は説明。本来は緑色の経路が最適な経路ですが、状況によっては危険地帯を通る最適ではない経路(下図の赤色)を学習してしまうことがあるそうです。

この現象は、Q値が発散する前にエージェントが最適な経路を探索できなかった場合に生じるとのこと。Q値が発散すると学習が止まってしまうため、その前に最適な経路を見つける必要があるとSilva氏は説明しています。
最適ではない経路を学習したエージェントの動作を詳しく見てみます。最適な経路を探索する前にQ値が発散してしまった場合、エージェントは「右」よりもQ値の高い「下」の経路を学習することはありません。
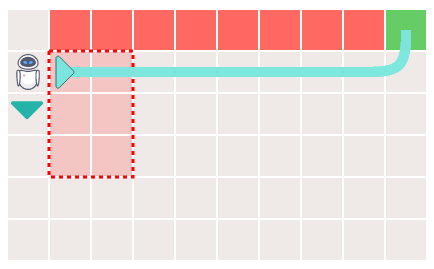
ここでエージェントを強制的に「下」に移動させてみると、危険地帯を回避してゴールへと到達する場合があることがわかります。この理由について、エージェントを強制的に最適な経路へと移動させたことが、エージェントが過去に学んだ「悪い記憶」を切り離し、最適な経路を選択する手助けとなっているとSilva氏は説明しています。

Silva氏はQ学習にベイズ推定を取り入れる試みの結論として、理論的には素晴らしいものの、実際の環境に適用するのは難しいかもしれないと指摘。しかし、研究分野そのものはエキサイティングであり、最先端の研究を期待するとコメントしています。
・関連記事
ディープラーニングの手法「CNN」の画像識別処理がアニメーションで理解できる「CNN Explainer」 - GIGAZINE
ビッグデータ解析・機械学習・人工知能の発展に伴って「パレートの法則(80:20の法則)」が進化している - GIGAZINE
Microsoftがオープンソースの機械学習セキュリティフレームワークをリリース - GIGAZINE
成功した機械学習モデル150個を分析してわかったことまとめ、Booking.comの場合 - GIGAZINE
初心者向け「機械学習とディープラーニングの違い」をシンプルに解説 - GIGAZINE
・関連コンテンツ