画像生成AI「Stable Diffusion」でたった1枚の画像から「特定の画像っぽい○○」をわずか数十秒で生成する方法が発表される
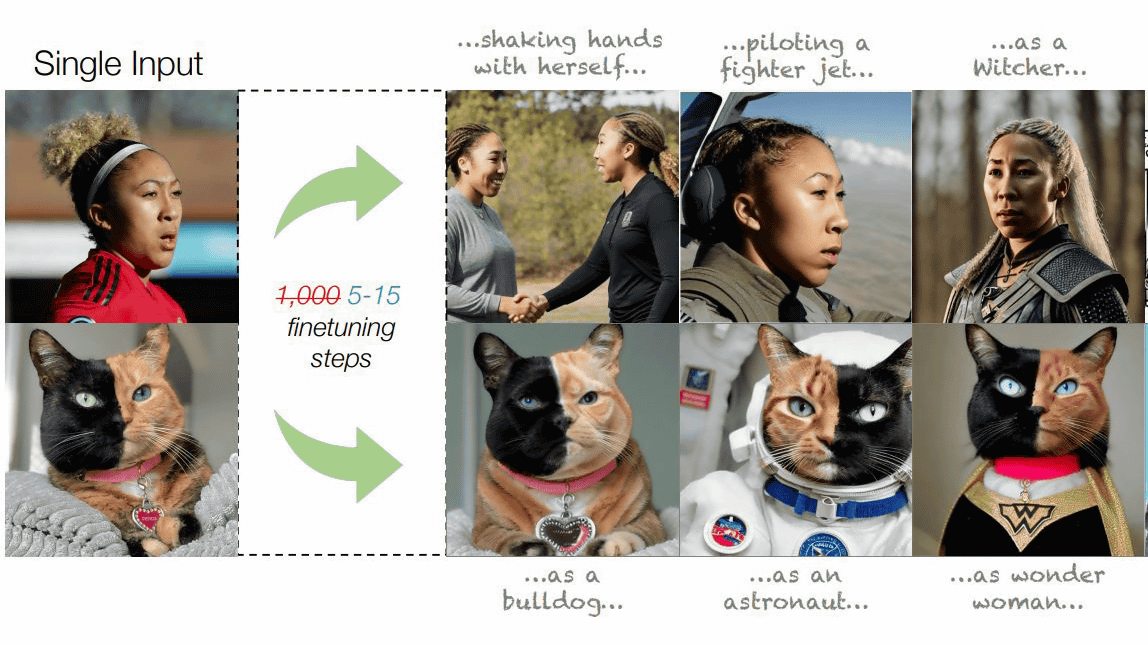
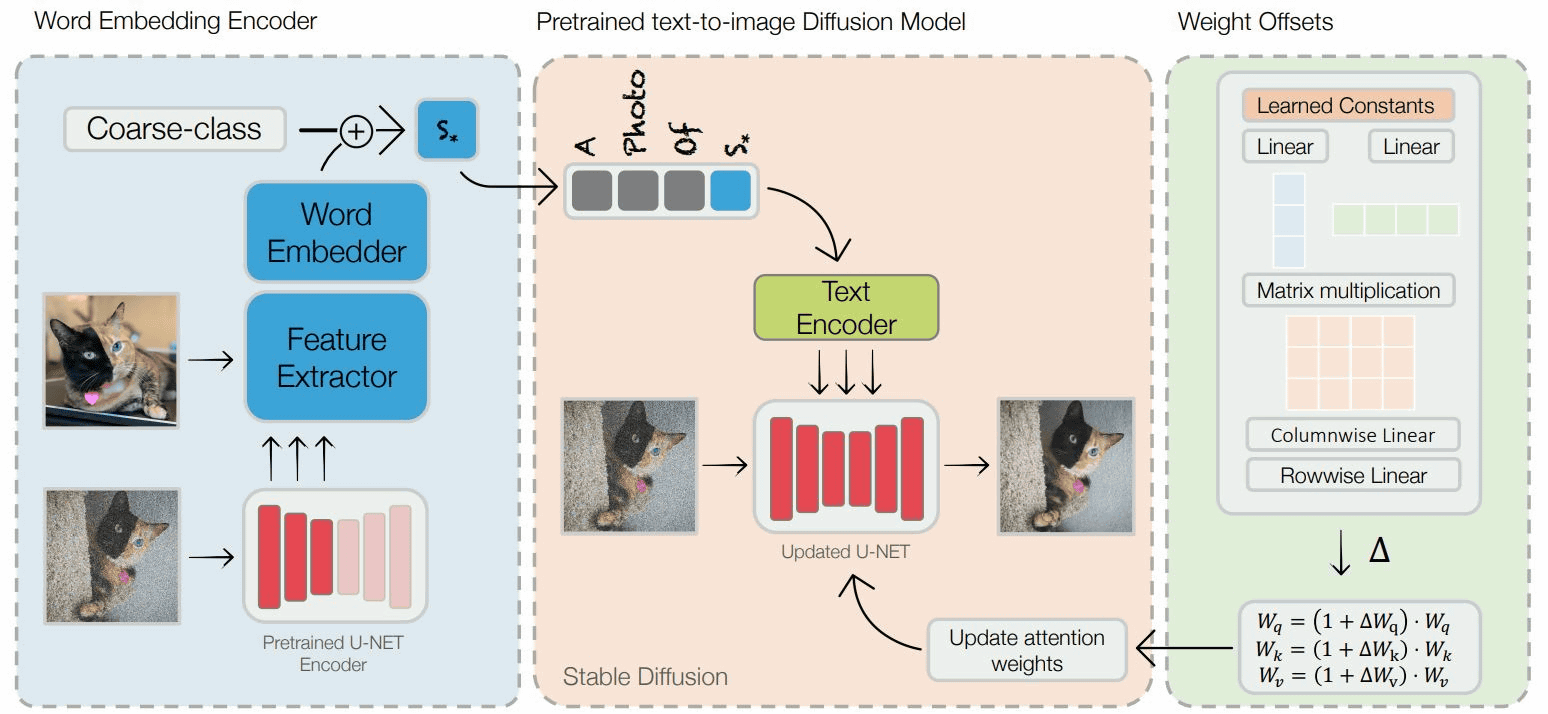
Stable Diffusionなどの画像生成AIに、特定の画像や画風を特定の単語に圧縮してAIに指示することで、自分の生成したい画像を任意の画像によく似せる「最適化」が可能です。テル・アビブ大学のコンピューター科学者であるリノン・ガル氏らのチームが、たった1枚の画像と5~15ステップの調整で画像の最適化を実現する方法を発表しました。
[2302.12228] Designing an Encoder for Fast Personalization of Text-to-Image Models
https://doi.org/10.48550/arXiv.2302.12228
Encoder-based Domain Tuning for Fast Personalization of Text-to-Image Models
https://tuning-encoder.github.io/





・関連記事
画像生成AI「Stable Diffusion」による画像生成や顔面高解像化などをコマンド一発で実行できる「ImaginAIry」 - GIGAZINE
画像生成AI「Stable Diffusion」を数枚の画像でファインチューニングする「Textual Inversion」のメリットとデメリットを実例と共に解説 - GIGAZINE
音声会話が可能で笑顔も見せるバーチャルな「俺の嫁」をChatGPTやStable Diffusionで構築して最終的に安楽死させるに至るまで - GIGAZINE
Stable Diffusionの18禁画像セーフティフィルターをだます「プロンプト希釈法」が発見される - GIGAZINE
Appleが画像生成AI「Stable Diffusion」にまさかの正式対応、開発者いわく「画像を1秒以内に生成可能」 - GIGAZINE
・関連コンテンツ