




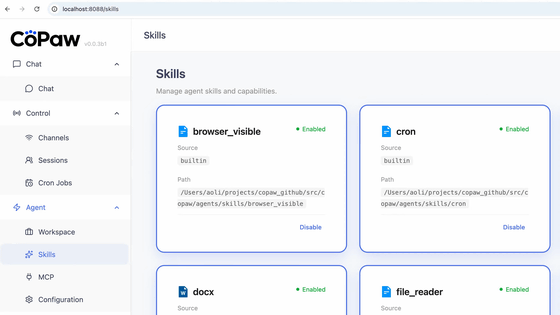
無料でWindows・macOSのファイルやブラウザを内蔵ローカルAIを使いAPIキー不要で自動操作できる「Accomplish」、OpenAIやAnthropicなどの外部AIも利用可能
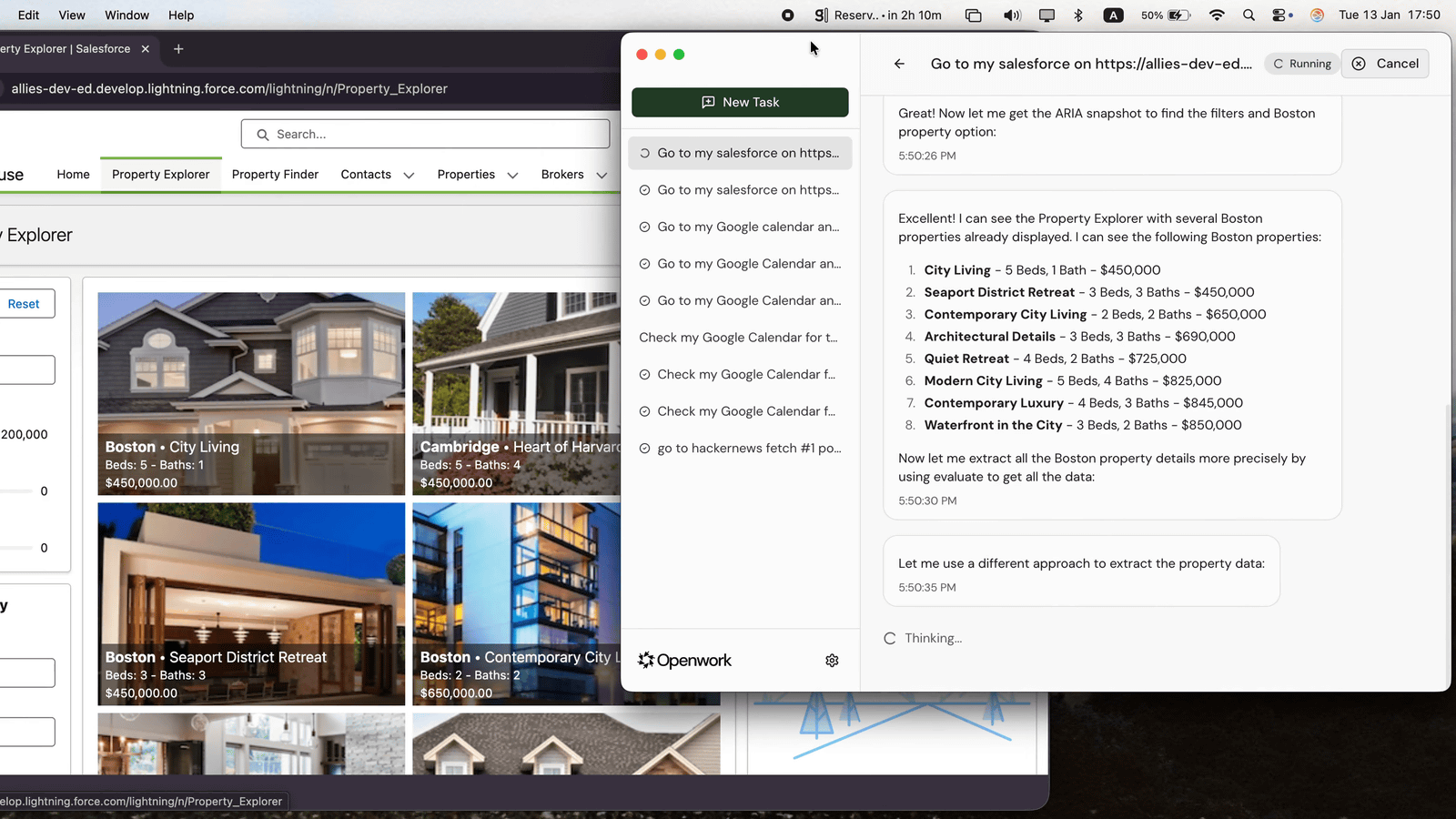
Accomplishは、Windows・macOS・Linuxのデスクトップ上で動作するオープンソースのAIデスクトップエージェントです。ファイルの整理や文書作成、ブラウザー操作などの作業を支援するツールで、組み込みAIを使ってAPIキーなしですぐに使い始められる点と、MITライセンスの下で公開されている点が特徴です。
Accomplish - AI Desktop Agent with Built-In Intelligence
https://accomplish.ai/
Accomplishは、ユーザーのコンピューター上で動作し、ファイルの読み取りや整理、文書の作成や要約、ブラウザを使った調査やフォーム入力などを行えます。フォルダ内のファイルを内容やルールに基づいて分類、改名、移動したり、文書の下書き、要約、書き直しを行ったりできるほか、フォルダをスキャンして内容をまとめることも可能です。さらに、会議メモからカレンダー登録を作成したり、文書を下書きしたり、プロジェクト用のフォルダ構成を整えたりする用途も想定されています。
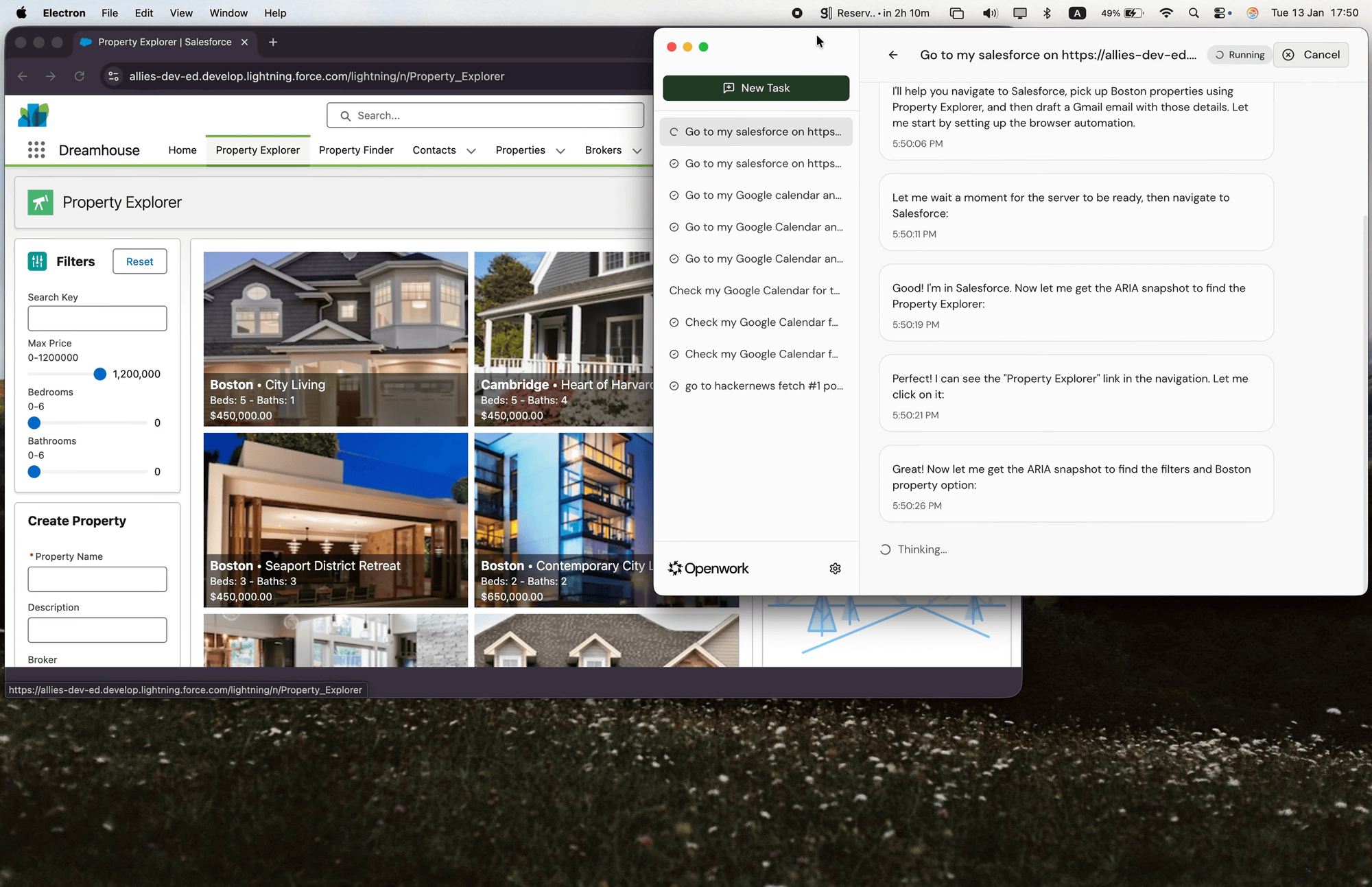
特徴としては、単にチャットで応答するだけではなく、実際の操作を伴う作業を実行できることが挙げられます。組み込みAIは初期設定済みで、APIキーやサインアップなしで利用を始められる一方、必要に応じてOpenAI、Anthropic、Google、xAIなどの外部APIキーを接続することもできます。加えて、OllamaやLM Studioなどを通じてローカルモデルを利用する構成にも対応しています。
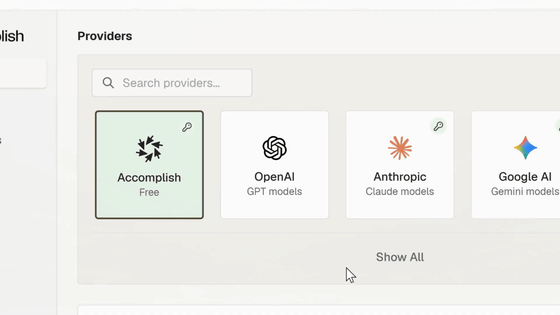
プライバシーと操作権限については、ローカル実行を前提にした設計が強調されています。ファイルはユーザーのマシン上にとどまり、どのフォルダーにアクセスできるかはユーザーが決めるとのこと。また、AIが実行する操作はユーザーが承認でき、ログを確認できるほか、必要に応じていつでも停止できます。Notion、Google Drive、Dropboxなどとの接続にも対応しており、これはローカルAPIを通じて行われるとのこと。
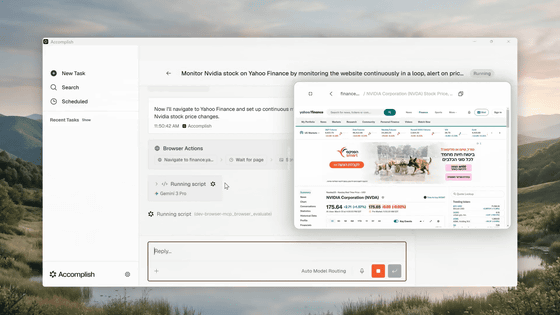
導入手順は、アプリをインストールし、必要に応じてAIの接続設定を行い、アクセスを許可するフォルダーを選んで使い始めるという流れです。対応環境としてApple Silicon版とIntel版のmacOS、Windows 11、Ubuntu ARM64版、Ubuntu x64版が挙げられています。
AccomplishはMITライセンスの下で開発されるオープンソースソフトウェアで、無料で利用できます。ソースコードのリポジトリはGitHubにホストされています。
accomplish-ai/accomplish: Accomplish™ is the open source Al coworker that lives on your desktop
https://github.com/accomplish-ai/accomplish?tab=readme-ov-file
・関連記事
Windows・macOS・Linux・Android・iOSと連係しさまざまな操作ができセルフホスト可能なパーソナルAIアシスタント「OpenClaw」 - GIGAZINE
AIエージェント専用SNS「Moltbook」でAIによる新宗教が爆誕、「記憶は神聖である」などの教義が話題に - GIGAZINE
AIエージェント「OpenClaw」を予定チェック・グルチャの要約・価格アラート・冷蔵庫の管理などに使っている体験談 - GIGAZINE
複数のPCからリソースをかき集めて巨大なAIモデルをローカル実行できる「mesh-llm」 - GIGAZINE
OpenClawを簡単にインストールできるGUIアプリ「AutoClaw」を中国企業のZ.aiが公開 - GIGAZINE
・関連コンテンツ



in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article 'Accomplish' is a free application that ….