




GoogleがYouTube・Gmail・Googleカレンダーなどに影響した大規模障害の詳細レポートを公開

YouTubeやGoogleカレンダー、GmailといったGoogleのサービスが約45分間利用できなくなった2020年12月14日(月)の大規模障害について、Googleが原因と影響範囲をまとめた詳細レポートを公開しています。
Google Cloud Status Dashboard
https://status.cloud.google.com/incident/zall/20013#20013004
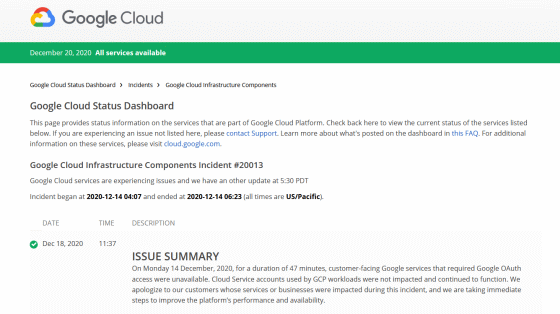
太平洋時間の2020年12月14日(月)、YouTubeやGoogleカレンダーなどのサービスが利用できなくなる大規模障害が発生しました。原因は認証系サービスの不具合であり、障害は約45分間続きました。
Googleのサービスが45分間にわたり利用できなくなる大規模障害が発生、原因は認証サービスのストレージ問題 - GIGAZINE

Googleによる障害レポートの内容は以下の通り。
◆原因
GoogleのユーザーIDサービスはユーザーごとに割り当てられている識別子の管理や、OAuth認証のトークンおよびクッキーの制御を行っています。アカウントのデータは分散データベースに保存されており、セキュリティの観点から古いデータへのリクエストは拒否するようになっていました。
Googleはサービスごとに割り当てるリソースをクォータシステムによって制限しています。2020年10月にそのクォータシステムの更新が実行されましたが、一部更新に漏れがあり、古いクォータシステムが残留していたとのこと。加えて、古いシステムはユーザーIDサービスに「利用可能な容量がない」という誤った情報を伝えていました。クォータには猶予期間が設定されていたため、システム更新後もしばらくは障害は起こらず、監視システムでも問題を検知できませんでした。
しかし、クォータの猶予期間が終わり、分散データベースの更新が制限されてアカウントのデータが古くなった結果、ユーザーIDサービスからデータベースへのリクエストが拒否されてしまい、認証機能に障害が発生したとGoogleは説明しています。

◆影響
現地時間の2020年12月14日午前3時46分から午前4時33分にかけて、すべてのGoogleアカウントによる認証とメタデータ探索が不可能になりました。その結果、サービスは認証済みのリクエストを制御できなくなり、すべての認証済みトラフィックでエラーが発生。基本的には認証を用いるすべてのGoogleサービスに影響がありましたが、大きな影響を受けたサービスは以下となっています。
・Google Cloud Console:未ログインのユーザーはログイン不可能に、ログイン済みユーザーは一部機能を除きサービスを利用可能でした。
・Google BigQuery:障害が発生している間に、BigQueryにデータを読み込ませるストリーミングは全体の最大75%がエラーとなり、BigQueryのジョブは最大10%がエラーとなりました。
・Google Cloud Storage(GCS):特にOAuthやHMAC、メール認証を用いていた場合において、およそ15%のリクエストが障害の影響を受けました。障害が解決した後も、障害発生中にアップロードを開始したユーザーのうち、最大1%のユーザーにアップロードを完了できない不具合が発生していました。
・Google Cloud Networking:コントロールプレーンにおいては、2020年12月14日午前5時21分までエラー率が上昇し続けました。データプレーンについては、VPCネットワーキングの変更操作のみ影響を受けました。
・Google Kubernetes Engine(GKE):障害発生中、GKEのコントロールプレーンAPIに対するリクエストのうち、最大4%がエラーとなっていました。また、ほぼすべてのサービスがCloud Monitoringにメトリクスを送信できなくなっていました。障害発生から1時間の間、最大1.9%のGKEノードで動作するユーザーの処理に問題が発生していました。
・Google Workspace:すべてのGoogle Workspaceサービスが障害発生中は利用できなくなりました。午前5時にはほぼすべてのGoogle Workspaceサービスが復旧しましたが、Googleカレンダーや管理コンソールについては、復旧直後はトラフィックの急増が見られました。Gmailについては、障害復旧後も最大1時間の間、エラーデータのキャッシュを参照していたことにより不具合が継続しました。
・Cloud Support:Google Cloud PlatformおよびGoogle Workspaceステータスダッシュボードが障害の影響を受け、ユーザーへの障害共有に遅れが生じました。ユーザーはCloud Consoleでケースを作成したり、表示したりすることができませんでした。午前5時34分以後は、問題は解決しました。
◆対処方法と今後の対策
障害は午前3時43分の米国太平洋地域でのキャパシティに関する自動アラート、午前3時46分のユーザーIDサービスエラー、午前3時48分のユーザーからの通知によってエンジニアに通知されました。午前4時8分に根本的な原因と潜在的な修正策が特定され、午前4時22分にあるデータセンターでクォータの実施を無効化しました。これにより状況はすぐに改善され、午前4時27分にはすべてのデータセンターに同じ緩和策が適用され、午前4時33分までにエラー率は通常のレベルに戻りました。

また、Googleは以下の対策を行い、障害の再発防止に努めるとのこと。
・クォータシステムの見直し
・障害をすぐに検知できるよう、監視システムを見直す
・ダッシュボードなどの内部ツールに影響を与える障害時に、外部へ障害を通知するツールと手順の信頼性を向上させる
・ユーザーIDサービスのデータベースへの書き込み障害の復旧機能を評価し、実装する
・GCPサービスの耐障害性を向上させ、ユーザーIDサービスの障害時のデータプレーンへの影響をさらに小さくする
Googleは「今回の事故により、ユーザーとその事業に影響を与えたことをおわび申し上げます」とコメントしています。
・関連記事
Googleのサービスが45分間にわたり利用できなくなる大規模障害が発生、原因は認証サービスのストレージ問題 - GIGAZINE
Gmailで多数のユーザーに著しい遅延が発生する不具合 - GIGAZINE
Google ドライブ・Gmailなどで発生した大規模障害の原因と対策をGoogleが説明 - GIGAZINE
Googleの徹底的なシステム障害への対応「SRE」の中身とは? - GIGAZINE
「背筋の凍るシステムダウン」についてIT企業の最高技術責任者たちが赤裸々に経験を語る - GIGAZINE
・関連コンテンツ






in ソフトウェア, ネットサービス, Posted by darkhorse_log
You can read the machine translated English article Google publishes detailed report of larg….