




「背筋の凍るシステムダウン」についてIT企業の最高技術責任者たちが赤裸々に経験を語る

ウェブサイトやアプリケーションは「常に稼働していること」が望ましく、大規模なサービスになればなるほど停止した際の損害は大きくなります。しかし、人的ミスやハードウェアの故障、予期せぬバグによるシステムダウンはいかなる時でも起こりうるもの。そんな恐ろしいシステムダウンの経験談を6人の最高技術責任者(CTO)が赤裸々に語っています。
6 Scary Outage Stories from CTOs – The New Stack
https://thenewstack.io/6-scary-outage-stories-from-ctos/
◆Honeycomb CTO:Charity Majors氏
Majors氏が語る障害は「プッシュ通知のシステムダウン」です。システムの状態は正常でMajors氏自身も通知を受信できており、テスト通知も成功していたため、最初は何が起きているのかわからなかったとMajors氏は語っています。
Honeycombではプッシュ通知システムをAWSのAuto Scalingで構築し、負荷に応じてAuto Scalingグループの容量を変化させていました。また、Auto Scaling間のロードバランスはRoute 53でDNSラウンドロビンによって行っていたとのこと。
「最後にAuto Scalingグループの容量を増加させてから、障害が報告されるようになった」「障害はすべて東ヨーロッパから報告されている」という手がかりをもとにチームが調査したところ、Auto Scalingグループがある一定以上の容量になると、DNSレコードがUDPパケットのサイズを超えてしまうことが判明。

サイズオーバーが生じた場合、通常はTCPへの切り替えが行われます。しかし、ルーマニアの大手ネットワーク会社のルーターは切り替えを行っていなかったため、その下流に存在するユーザーはプッシュ通知を利用できなくなっていました。最終的に、特定のDNSをRoute 53からローカルのPython製DNSサーバーに移行することで、問題を解決できたとのこと。
◆Gremlin CTO:Matthew Fornaciari氏
Fornaciari氏がシステムダウンを経験したのは、ハロウィンパーティーを楽しんでいた金曜日の午後のことでした。サーバーのディスク容量がいっぱいでログを書き込めなくなっていたため、ウェブサイトが大量の500エラーを返答していたとのこと。Fornaciari氏はログローテーションやディスク容量の警告を設定し、再発防止に努めていると語っています。
◆Rookout CTO:Liran Haimovitch氏
Haimovitch氏が経験したシステムトラブルは、「週に何回か、システムの応答速度が極端に遅くなる」というもの。データベース上の特定のテーブルがロックされ、クエリがタイムオーバーになっていたそうです。応答速度を改善するためにいくつかのクエリを修正しましたが、根本の原因となるクエリは見つけることができませんでした。
ある日Haimovitch氏が週次で開かれているカスタマーサクセス会議に参加したところ、まさにその会議中にシステムの遅延が発生。遅延の原因はカスタマーサクセスマネージャーが会議で実行していた「バックオフィスでごくまれに使用しているクエリ」だったとのこと。後の調査により、カスタマーサクセス会議が開かれていた時間帯と遅延が発生した時間が完全に一致することが判明しました。
◆Lightstep CTO:Daniel "Spoons" Spoonhower氏
Spoonhower氏が小規模なインターネット企業で仕事をしていた時、突然アプリケーションがすべてダウンしてしまったとのこと。同僚も同じ状況でしたが、なぜか外部ユーザーからは障害報告がありませんでした。その日はアプリケーションのデプロイも、インフラの更新も行われておらず、Spoonhower氏はなぜ障害が起こったのか疑問に思ったそうです。

障害の原因は、メンテナンスされていないAPIがエラー出力の際に「社内ユーザー向けの余分なデータ」を返していたためだと判明。社内ユーザーが対象であるため社外への影響はありませんでしたが、社内ユーザーに対する余分なデータは数週間のうちに増加していき、最終的にはシステムダウンを招く事態となったと。Spoonhower氏は語っています。
◆LogDNA CTO:Lee Liu氏
2020年5月30日で、ルート証明書のひとつだったAddTrust External CA Rootがで期限切れを迎えました。ルート証明書はインターネットで広く利用されているため、さまざまなシステムで証明書の入れ替えが必要になりました。Liu氏がCTOを務めるLogDNAも、そうしたサービスのひとつだったとのこと。
LogDNAはアプリケーションから内部のシステムまで、すべて単一の認証チェーンで管理していたのこと。認証チェーンは以下のようになっており、これらの証明書のうち失効するのは最上位の証明書でした。
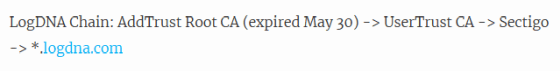
最近のブラウザは「UserTrust CA」もルート証明書としているため、最上位の証明書が期限切れとなっても、「UserTrust CA」証明書が有効なので問題ないと思っていたLiu氏。

しかし、古いシステムは最上位の証明書まで確認し、どれかひとつでも失効していれば認証チェーンは無効であると判断していたとのこと。これにより、古いログ収集システムなどが動作しなくなってしまったそうです。
◆Transposit CTO:Tina Huang氏
Huang氏がモバイル版Twitterの開発に従事していた時、一部のユーザーからページが表示されないという報告を受けたとのこと。最初は少数だった報告が、時間がたつにつれて危機的なレベルにまで増加。調査の結果、新しいライブラリが特定の文字を含むセッションCookieの解析に失敗していたのが原因だったとのこと。
最終的にはライブラリを修正することで問題を解決できましたが、Huang氏は「サイトが完全に停止してしまうのは恐ろしいものですが、それは前触れ無く突然起こります」と語っています。
システムダウンの発生は仕方ない面がありますが、それを共有して将来に役立てる姿勢が大切なのかもしれません。
・関連記事
Googleの徹底的なシステム障害への対応「SRE」の中身とは? - GIGAZINE
Amazon・Microsoft・PSNなどを巻き込む大規模なネットワーク障害が発生、原因はBGPの設定ミスか - GIGAZINE
無料でWindowsの多すぎるルート証明書をスリム化してセキュリティを高められる「RootIQ」レビュー - GIGAZINE
Googleによるシステム開発・維持管理ノウハウをまとめた本が無料公開中 - GIGAZINE
・関連コンテンツ







in ソフトウェア, ネットサービス, Posted by darkhorse_log
You can read the machine translated English article Chief technology officers of IT companie….