Chief technology officers of IT companies talk about 'system down that freezes the spine' nakedly

Websites and applications should be 'always running', and the larger the service, the greater the damage caused by the outage. However, system down due to human error, hardware failure, or unexpected bug can occur at any time. Six
6 Scary Outage Stories from CTOs – The New Stack
https://thenewstack.io/6-scary-outage-stories-from-ctos/
◆
The obstacle that Majors talks about is 'push notification system down.' Majors said he didn't know what was happening at first because the system was in good condition, Majors himself was able to receive notifications, and the test notifications were successful.
Honeycomb built a push notification system with AWS Auto Scaling and changed the capacity of the Auto Scaling group according to the load. In addition, load balancing between Auto Scaling was done by DNS round robin on Route 53 .
According to the team's investigation based on the clues that 'the failure has been reported since the last increase in the capacity of the Auto Scaling group' and 'all failures have been reported from Eastern Europe', Auto Scaling It turns out that the DNS record exceeds the size of the UDP packet when the group exceeds a certain capacity.

In the event of an oversize, a switch to TCP is usually done. However, the routers of the major Romanian network companies did not switch, making push notifications unavailable to users downstream of them. Eventually, migrating a specific DNS from
◆ Gremlin CTO: Matthew Fornaciari
Fornaciari experienced a system down on Friday afternoon, enjoying a Halloween party. The website was returning a large number of 500 errors because the server was full of disk space and could not write logs. Fornaciari says he is working to prevent recurrence by setting log rotation and disk space warnings.
◆ Rookout CTO: Liran Haimovitch
The system trouble that Haimovitch experienced is that 'the response speed of the system becomes extremely slow several times a week'. It seems that a specific table on the database was locked and the query was timed out. I modified some queries to improve the response speed, but couldn't find the underlying query.
One day, Haimovitch attended a weekly customer success meeting, and there was a system delay during that very meeting. The cause of the delay was the 'very rare query used in the back office' that the customer success manager was executing at the meeting. Later investigations found that the time of day the customer success meeting was held and the time of the delay exactly matched.
◆ Lightstep CTO: Daniel 'Spoons' Spoonhower
When Spoonhower was working for a small internet company, all of his applications suddenly went down. My colleague was in the same situation, but for some reason there were no reports of problems from external users. No applications were deployed or infrastructure was updated that day, and Spoonhower wondered why the failure happened.

It turned out that the cause of the failure was that the unmaintained API returned 'extra data for internal users' when outputting the error. Since it was targeted at internal users, there was no impact on the outside, but the extra data for internal users increased within a few weeks, eventually leading to a system down. Spoonhower says.
◆ LogDNA CTO: Lee Liu
On May 30, 2020, one of the root certificates, AddTrust External CA Root , expired at. Due to the widespread use of root certificates on the Internet, it has become necessary to replace certificates on various systems. LogDNA, for which Liu is the CTO, was one such service.
LogDNA was managed by a single authentication chain, from applications to internal systems. The authentication chain looks like this, with the highest-level certificate revoking among these certificates.
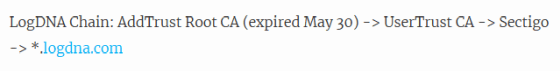
Recent browsers also use 'UserTrust CA' as the root certificate, so even if the top-level certificate expires, Liu thought that there would be no problem because the 'UserTrust CA' certificate is valid.

However, the old system checked up to the highest certificate and decided that the authentication chain was invalid if any one of them had expired. As a result, the old log collection system etc. has stopped working.
◆ Transposit CTO: Mr. Tina Huang
When Mr. Huang was engaged in the development of the mobile version of Twitter, he received a report from some users that the page was not displayed. Initially few reports increased to critical levels over time. As a result of the investigation, it was said that the cause was that the new library failed to parse session cookies containing specific characters.
In the end, fixing the library solved the problem, but Huang said, 'It's scary that the site goes down completely, but it happens suddenly without warning.'
There is no choice but to cause a system down, but it may be important to share it and make use of it in the future.
Related Posts:







in Software, Web Service, Posted by darkhorse_log