




GoogleのGmailやクラウドなどのサービスを支える技術「Borg」の統計情報が公開

GoogleはGmailやサーチエンジン、Google Cloud Platformなどのさまざまなサービスを運営しています。そうした大規模なサービスを高い稼働率で提供するため、Googleは「Borg」と呼ばれるクラスタマネージャを開発してきました。そのBorgについて、Googleが2019年版の統計情報を公開しています。
(PDF)Borg:the Next Generation
https://www.eurosys2020.org/wp-content/uploads/2020/04/slides/49_muhammad_tirmazi_slides.pdf
GitHub - google/cluster-data: Borg cluster traces from Google
https://github.com/google/cluster-data
Large-scale cluster management at Google with Borg – Google Research
https://research.google/pubs/pub43438/
Borgとは、Googleによって開発されたクラスタマネージャで、複数のマシンにプログラムの処理を分散するための基盤となるシステムです。同じくGoogleによって開発され、インフラの現場で浸透しつつあるオーケストレーションツールのKubernetesが大きな影響を受けたシステムだとされています。
Borgはマシンの集合体をCellと定義し、ひとつのユニットとして扱います。
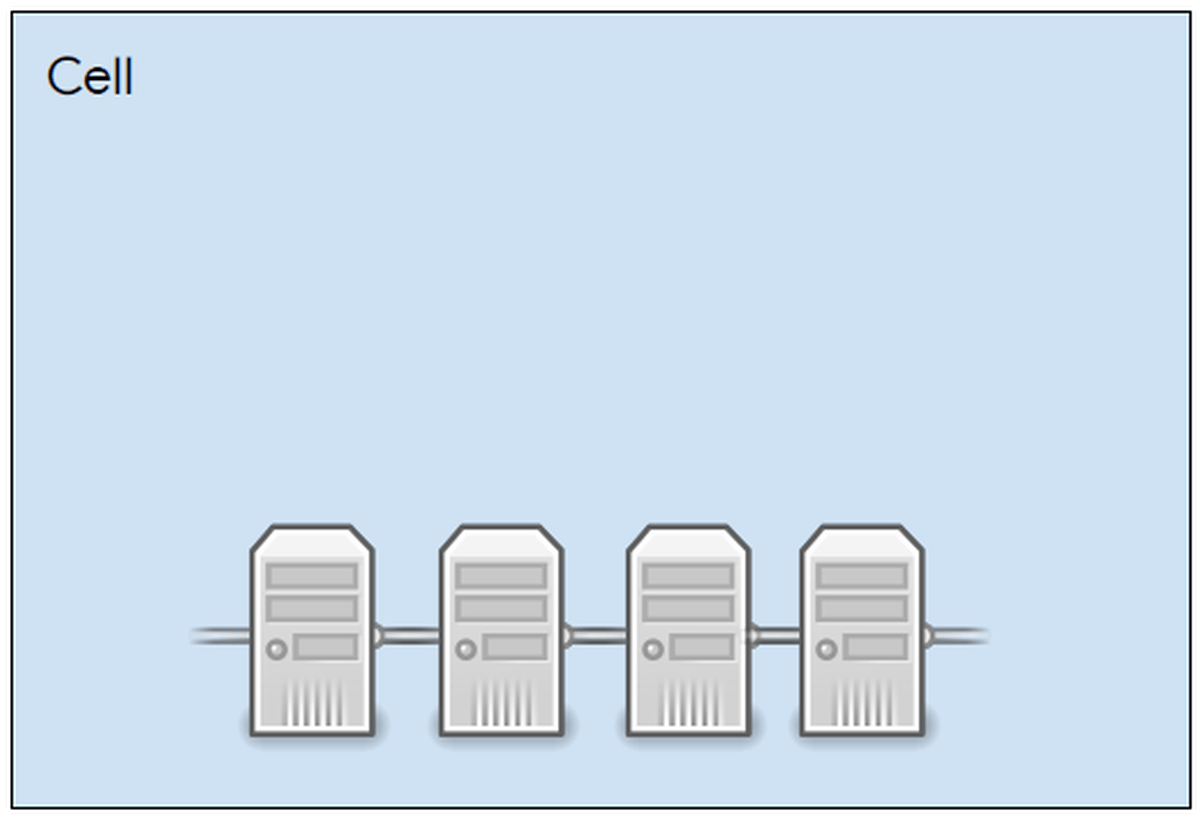
使用者はBorgに対し、Jobと呼ばれる形で処理を投入します。Jobはそのプログラムの所有者などの情報が記載されており、複数のTaskと呼ばれるプログラムから構成されています。Jobには優先度があり、優先度順に「production」「mid」「best-effort batch」「free」が設定されています。なお、TaskはKubernetesのように仮想化されたコンテナ上で実行されるのではなく、ハードウェア上で直接実行されます。
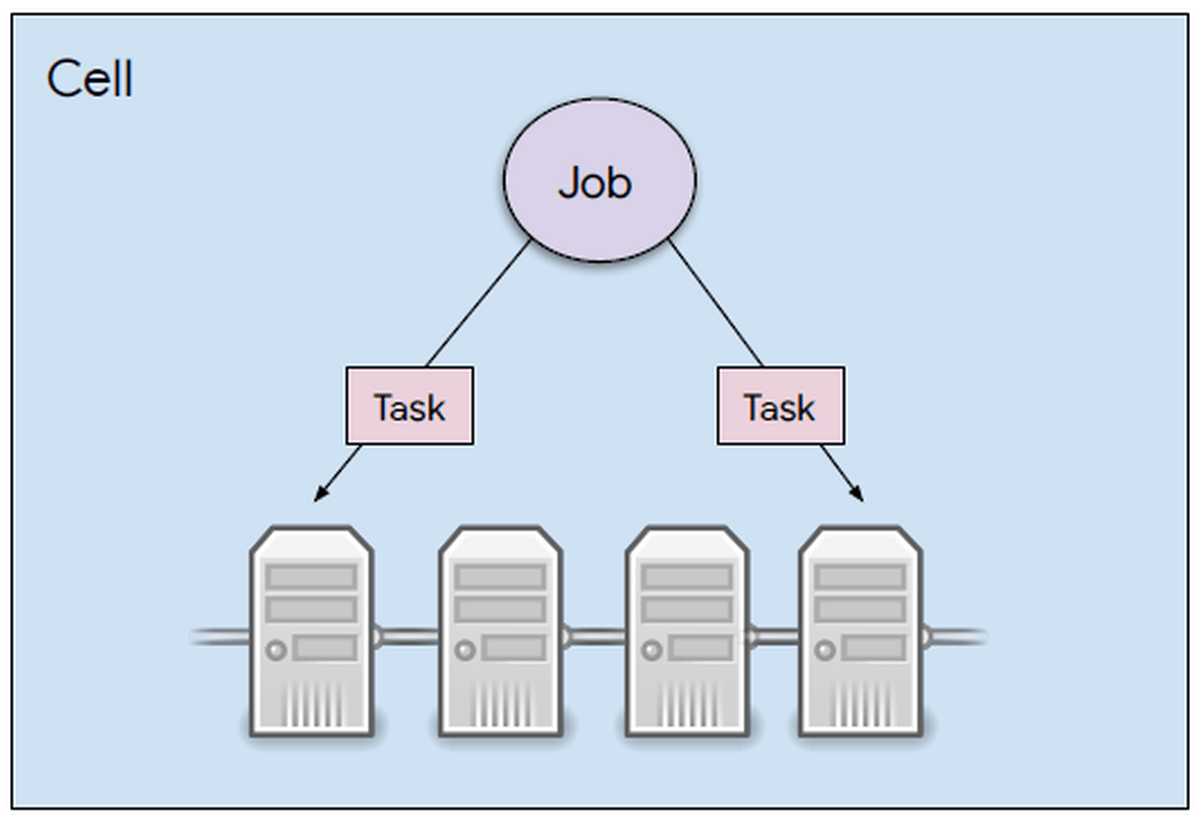
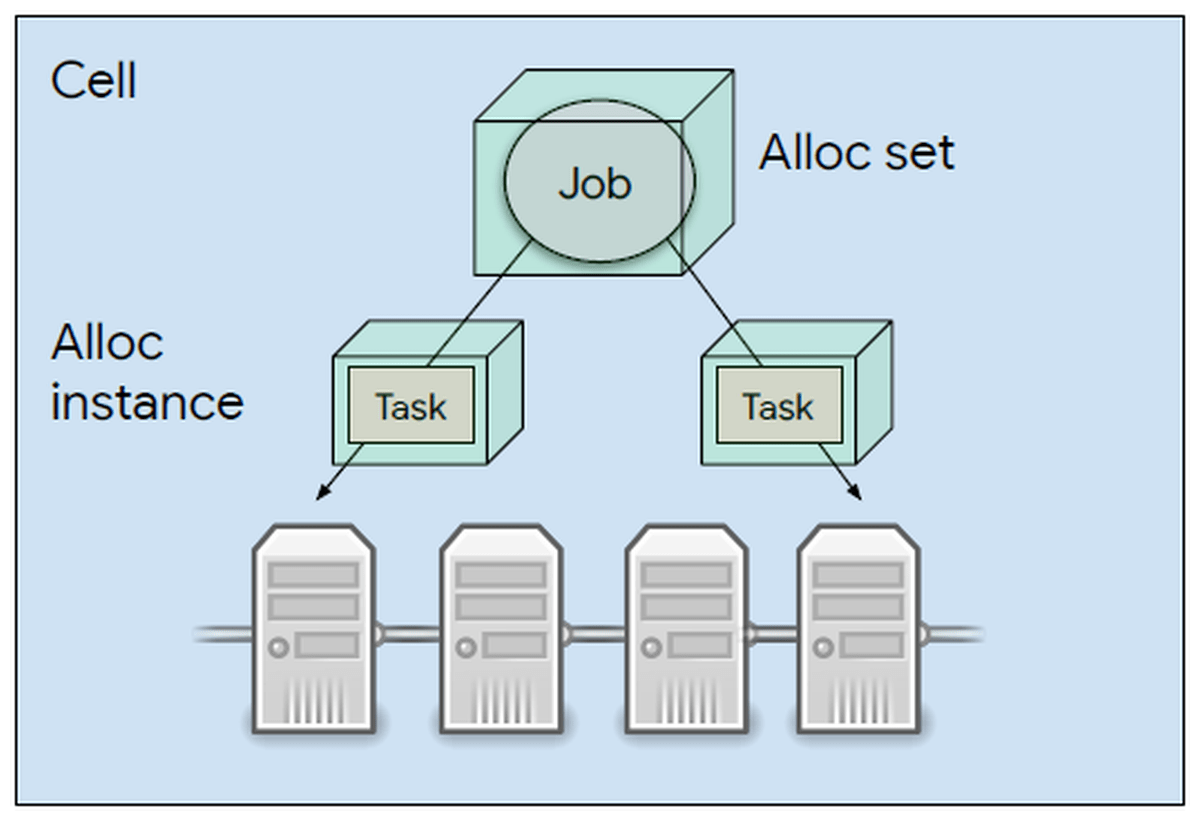
複数のマシンにタスクを分散するために、Borgでは「複数のマシンにまたがってリソースを事前に割り当て、それをひとつのリソースと考える」という構造を採用しています。この割り当てたリソースをallocと呼び、JobやTaskはalloc内で実行されます。その結果、複数のマシンに処理が分散されるというわけ。
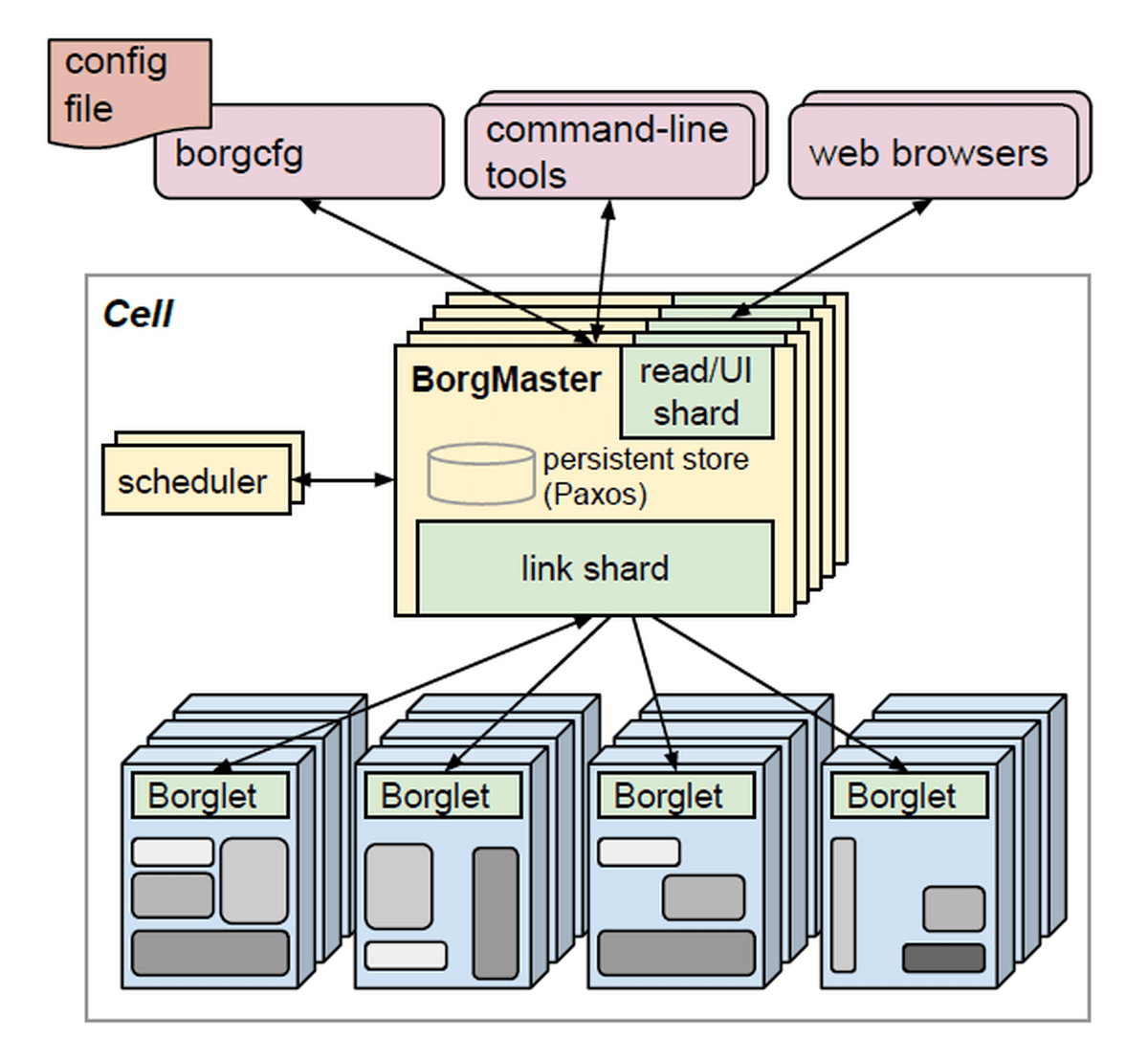
Borgの全体像はこんな感じ。使用者がブラウザやコマンドライン経由でCellに処理を投入し、Borgmasterと呼ばれる管理プログラムがJobやTask、allocの管理を行います。Cell内のマシンにはBorgletと呼ばれる監視用のエージェントが配置され、Borgmasterから割り振られたTaskの開始や停止、再起動を行っています。
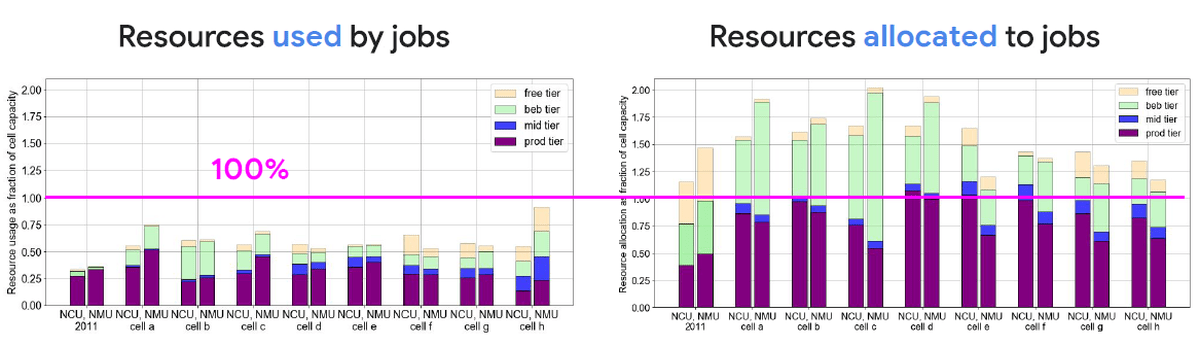
今回Googleが公開したのは、BorgのCell内における処理のさまざまな統計情報です。2011年に公開された情報は1つのCellにおける情報のみでしが、2019年版には9万6000台ものマシンで構成される8つのCellから収集した情報が含まれています。Cellから収集するのは主に2つのメトリクスで、「Jobによって使用されているリソース」と「Jobに対してallocされている=割り当てられているリソース」とのこと。
まずは「Jobによって使用されている計算リソース」を見てみます。グラフの縦軸はCellにおける計算リソースの使用率で、横軸が日数です。2011年と比較して2019年は新しく「mid」という優先度が加わっていることがわかります。
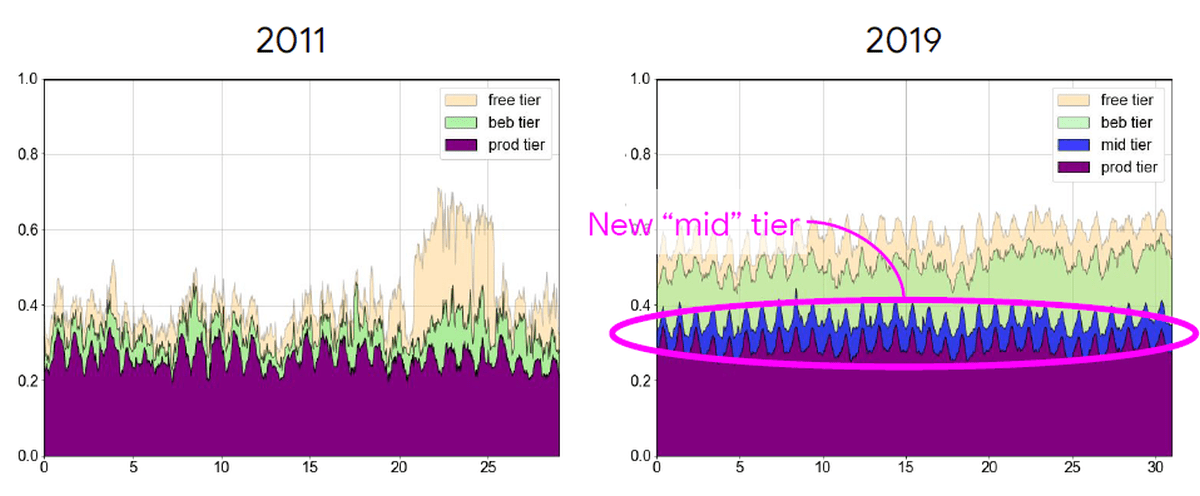
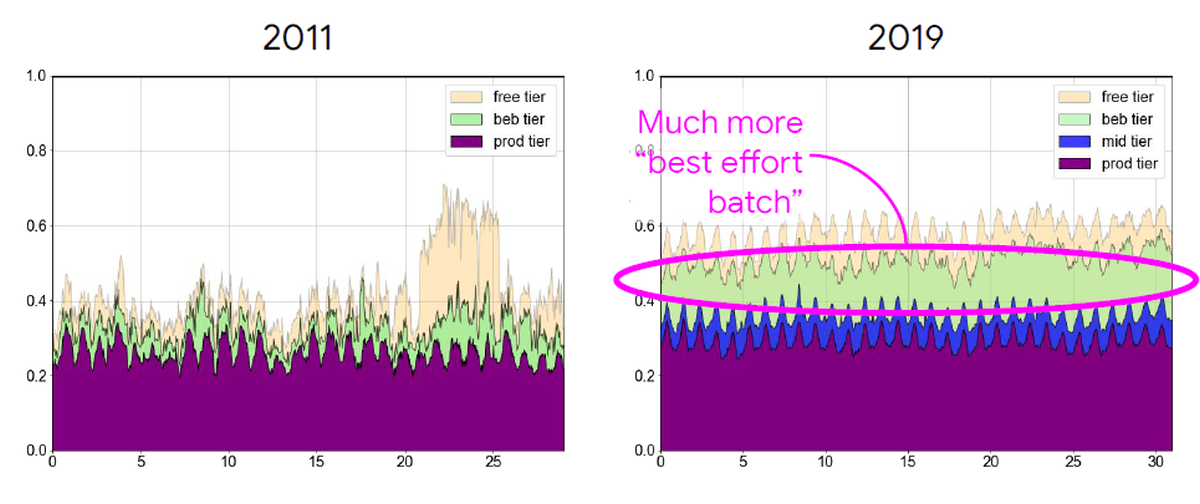
また、優先度が「best-effort batch」のJobが増加しています。「best-effort batch」のJobは優先度の高いJobに処理を停止させられる可能性を考慮したJobなので、効率的にCellの処理能力を使えるようになっていることがわかります。
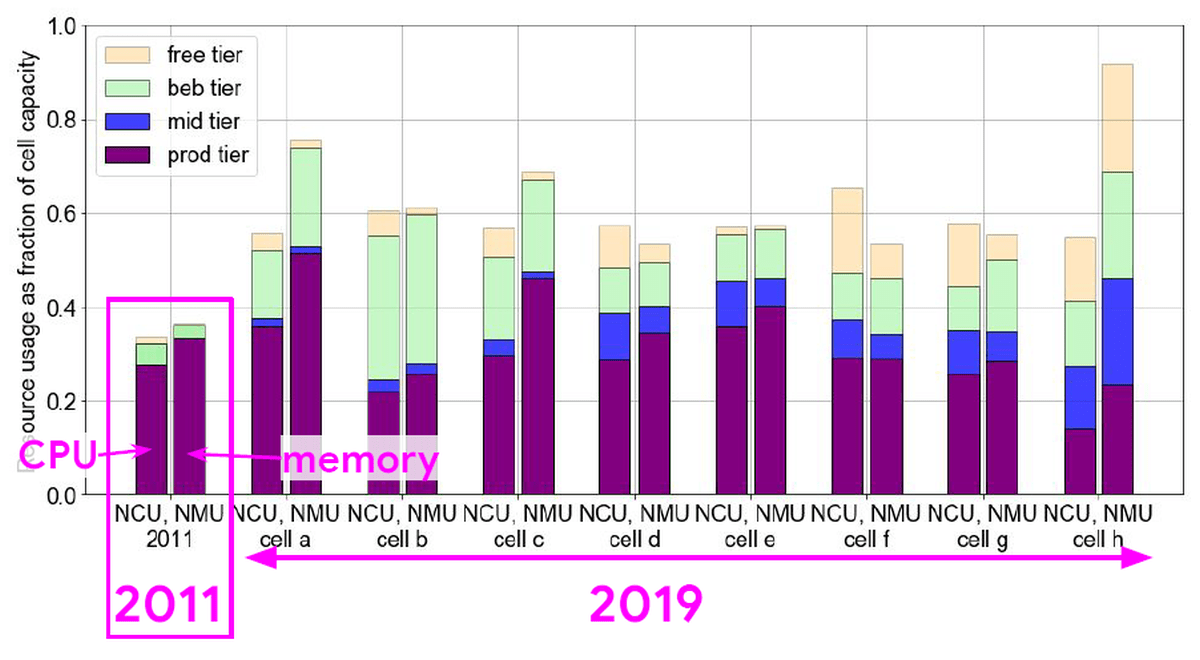
縦軸に処理容量、横軸にCellを並べた、Jobに使用されているCPUとメモリのグラフを見ても、同じような傾向が見て取れます。
次に「Jobに対して割り当てられているリソース」を見てみると、全体的にCellのリソースをより多く割り当てるようになっています。
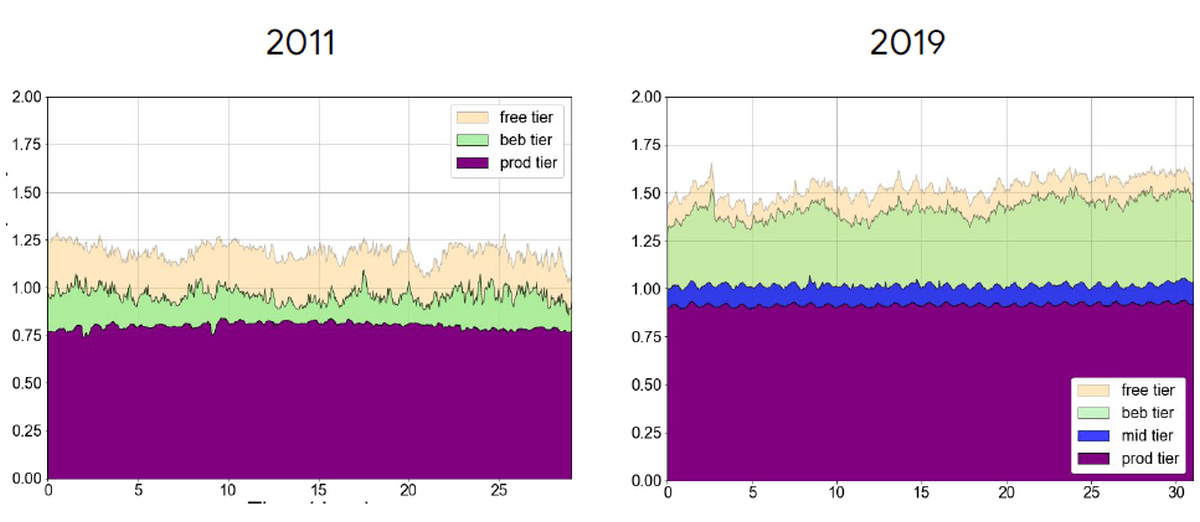
「Jobによって使用されているリソース」と「Jobに対して割り当てられているリソース」を比較してみるとこんな感じ。2019年においては優先度の高いJobが実際のマシンリソースをちょうど使い切るように、効率的に割り当てが行われているのがよくわかります。
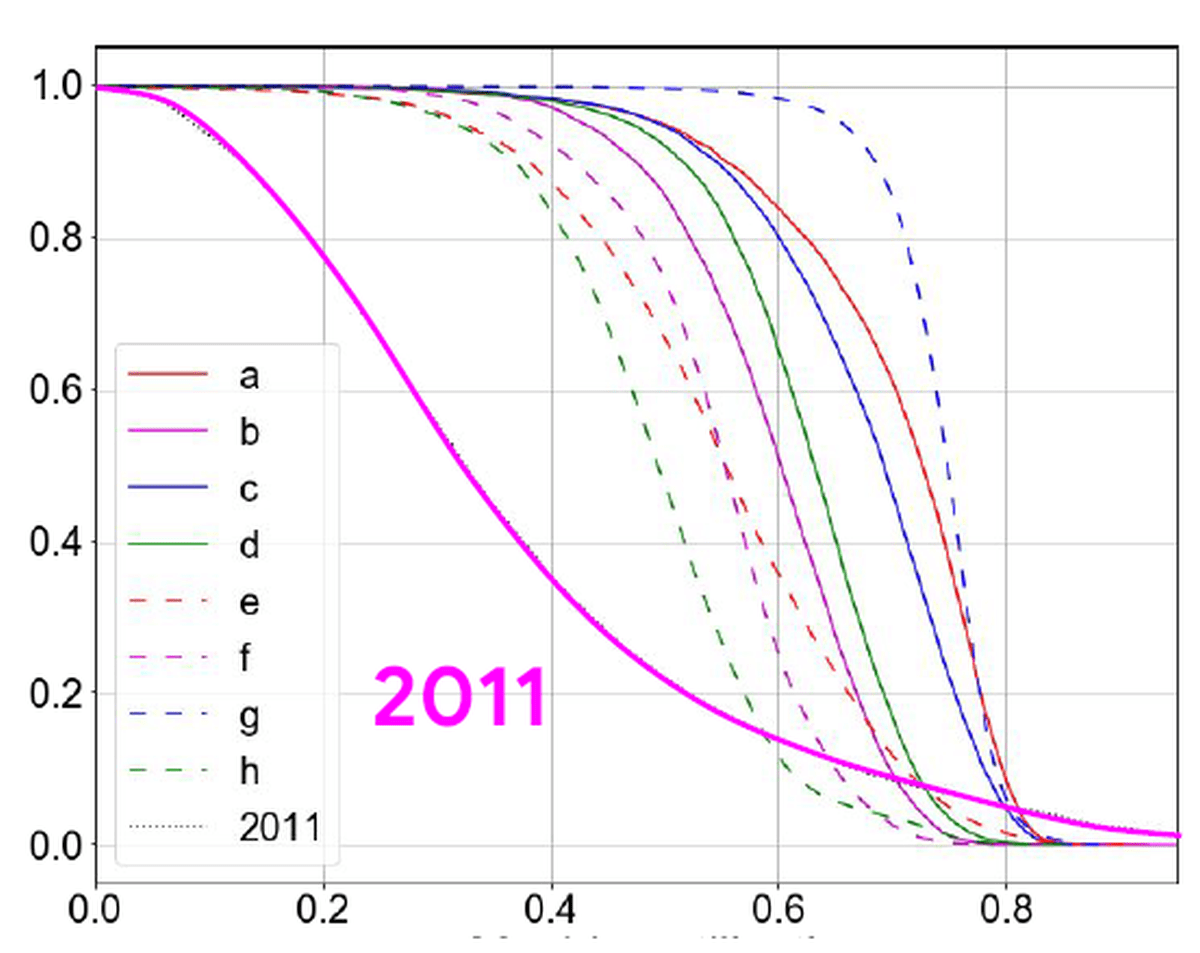
下のグラフは、縦軸が累積率、横軸がマシンの使用率を表す累積度数分布曲線です。2019年の8つのCellにおけるマシンの使用率と、2011年の1つのCellにおけるマシンの使用率で、大きく曲線が異なります。
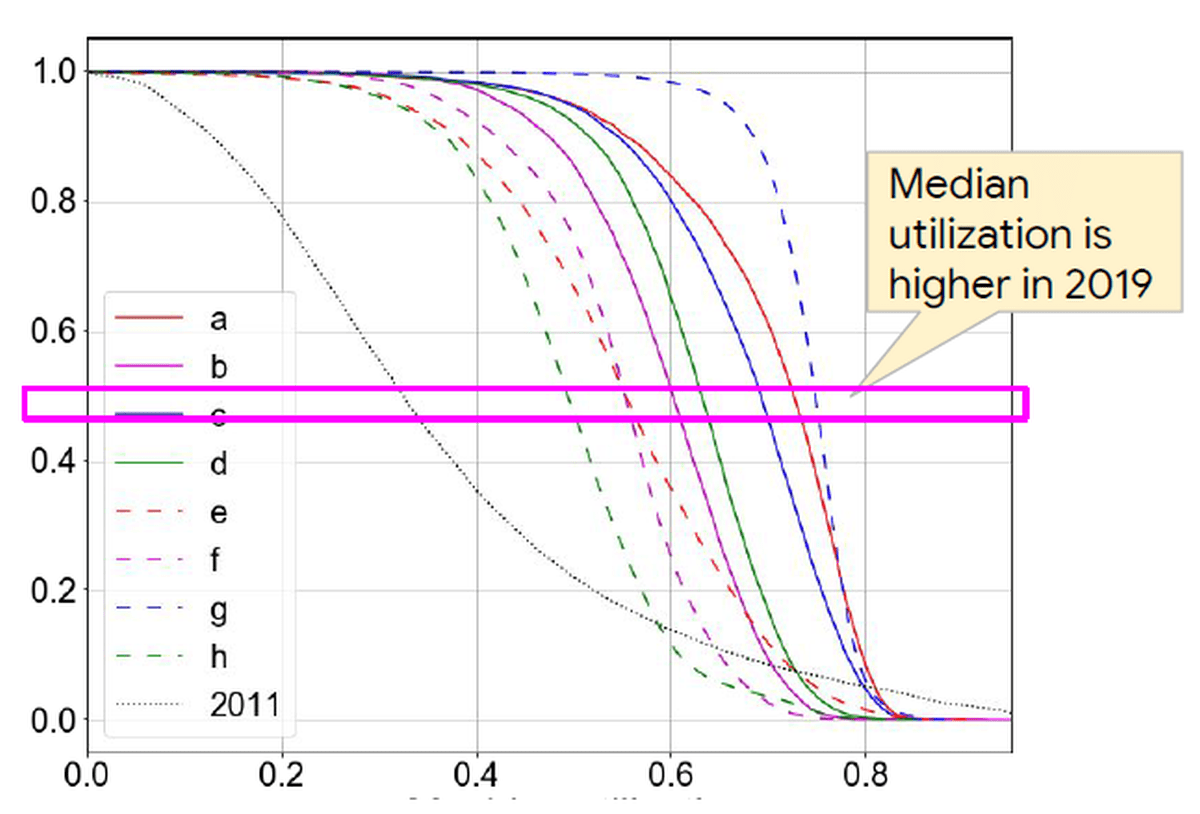
利用率の中央値を確認すると、2011年の利用率が30%ほどであるのに対し、2019年では50%から77%まで利用率を向上させることができています。
今後の課題として、Googleにおいてマシンリソースを大量に消費するJobにより、小さなJobの処理が阻害されやすくなっており、Jobのスケジューリングが重要になると説明されています。
・関連記事
Googleの徹底的なシステム障害への対応「SRE」の中身とは? - GIGAZINE
Gmail・Googleドライブ・Googleフォトが一時使用不能になった件についてGoogleが詳細な原因を説明 - GIGAZINE
無料&オープンソースでシステム障害のレポートを一元化できるNetflix製インシデント管理ツール「Dispatch」 - GIGAZINE
Googleによるシステム開発・維持管理ノウハウをまとめた本が無料公開中 - GIGAZINE
・関連コンテンツ






in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article Statistical information of technology 'B….