




機械学習のアルゴリズムはドーパミン神経によって脳にも実装されていることが判明

決まった時間にブザーを鳴らし餌をやることでブザーが鳴るだけで唾液が出るようになったパブロフの犬のように、生物の脳や神経構造は長い間科学者の研究対象となっています。また、脳の仕組みを参考にしたニューラルネットワークなど、人工知能の開発に脳神経の研究が用いられることもあります。そんな中、世界最強の囲碁プログラム「AlphaGo」を開発したDeepMindが、機械学習のアルゴリズムがドーパミン神経によって脳にも備わっていることを発見しました。
A distributional code for value in dopamine-based reinforcement learning | Nature
https://www.nature.com/articles/s41586-019-1924-6
Dopamine and temporal difference learning: A fruitful relationship between neuroscience and AI | DeepMind
https://deepmind.com/blog/article/Dopamine-and-temporal-difference-learning-A-fruitful-relationship-between-neuroscience-and-AI
強化学習は神経科学と人工知能を結びつける最も古典的な考えであり、1980年代でも報酬と罰を用いて自ら判断し複雑な行動を取ることができる人工知能の開発が試みられていました。そうした強化学習にブレイクスルーを起こしたのがTD学習(時間的差分学習)と呼ばれるもの。従来の学習方法がもらえる報酬の予測と実際にもらえた報酬の結果との差分から人工知能に学習させていたのに対し、TD学習は時間的に連続している予測同士の差分から学習させる方法です。
それに対して、生物の脳もTD学習を行っていることが判明しています。1990年代中頃、生物のドーパミン神経は報酬予測に誤差が生じた時に発火することが判明。脳はドーパミンを信号として予測の誤差情報を脳内に発信し、学習することが明らかになっています。脳がTD学習していることは何千回もの実験により検証されており、神経科学で最も成功した定量的な理論として知られるようになっています。
近年、人工知能分野ではニューラルネットワークを用いたディープラーニングによる強化学習の研究が進んでいますが、強化学習の発展に大きく寄与したのは「distributional reinforcement learning(分布強化学習)」と呼ばれる手法。特定の行動の帰結としてもたらされる報酬の量は完全に定量的に表すことは難しく、ランダム性があります。例えば、コンピューターが操作するアバターが崖をジャンプするといった状況で、報酬は崖をジャンプできるかできないかの二択で確率分布として表されます。しかし、従来のTD学習では報酬の期待値を予測しようしていたため、確率分布のピークや偏りを内在することができませんでした。そうした問題を解決するため、分布強化学習では確率分布全体を予測します。
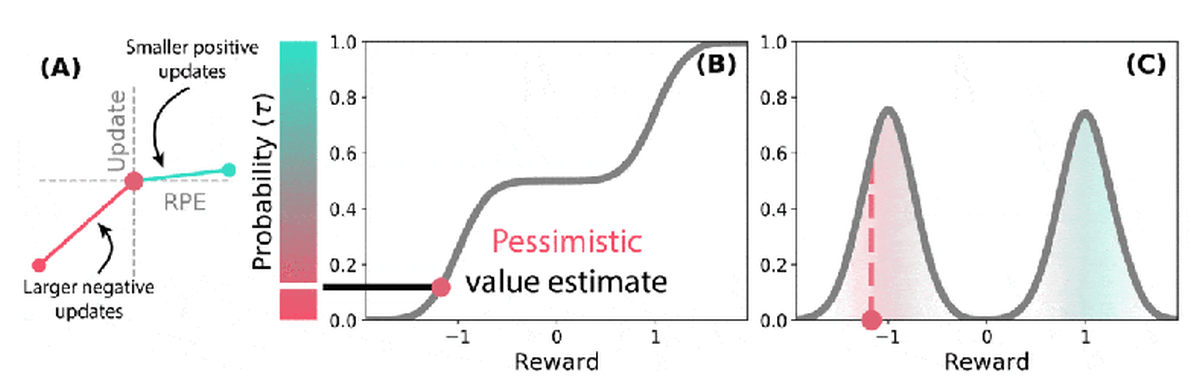
分布強化学習とTD学習を合わせた分布型TD学習では確率分布全体を予測するため、異なる複数の予測子のセットを学習します。学習方法はTD学習と同じく報酬予測の誤差を元にしていますが、分布型TD学習では予測子ごとに報酬予測の誤差への反応が異なります。報酬予測の誤差に対して楽観的な報酬予測をする予測子もあれば、悲観的な報酬予測をする予測子もあり、それらをセットで学習していくのが分布型TD学習とのこと。左側の赤と青の棒が示すグラフは赤色が長い場合は悲観的な報酬予測をした予測子が優勢であることを示し、反対に青色が長い場合は楽観的な報酬予測をした予測子が優勢であることを指します。予測子のマトリックスが変わるにつれて、BやCで表された報酬予測も変化していきます。
分布型のTDアルゴリズムは人工知能のニューラルネットワークと非常に相性が良いことが知られているため、生物の脳で分布型のTDアルゴリズムが使われていると推論し、DeepMindとハーバード大学の研究室が共同で研究を行いました。過去の研究から、ドーパミン細胞は発火率の変化によって報酬予測の誤差を示していることがわかっているため、マウスが学習済みのタスクにおいて想定外の報酬を受け取った際のドーパミン細胞の活動が標準のTDアルゴリズムと分布型のTDアルゴリズムのどちらに近いか評価し、脳においても異なる報酬予測の多様性が観測できるか実験しています。
グラフは与えた報酬である水の量で色分けされていて、縦軸でドーパミン細胞が分けられ、横軸は報酬予測の誤差を示しています。標準のTDアルゴリズムに近ければ左側のグラフのようにドーパミン細胞ごとに報酬予測の誤差は同じはず。逆に分布型のTDアルゴリズムに近ければ右側のグラフのようにドーパミン細胞ごとに報酬予測の誤差が異なるはずです。
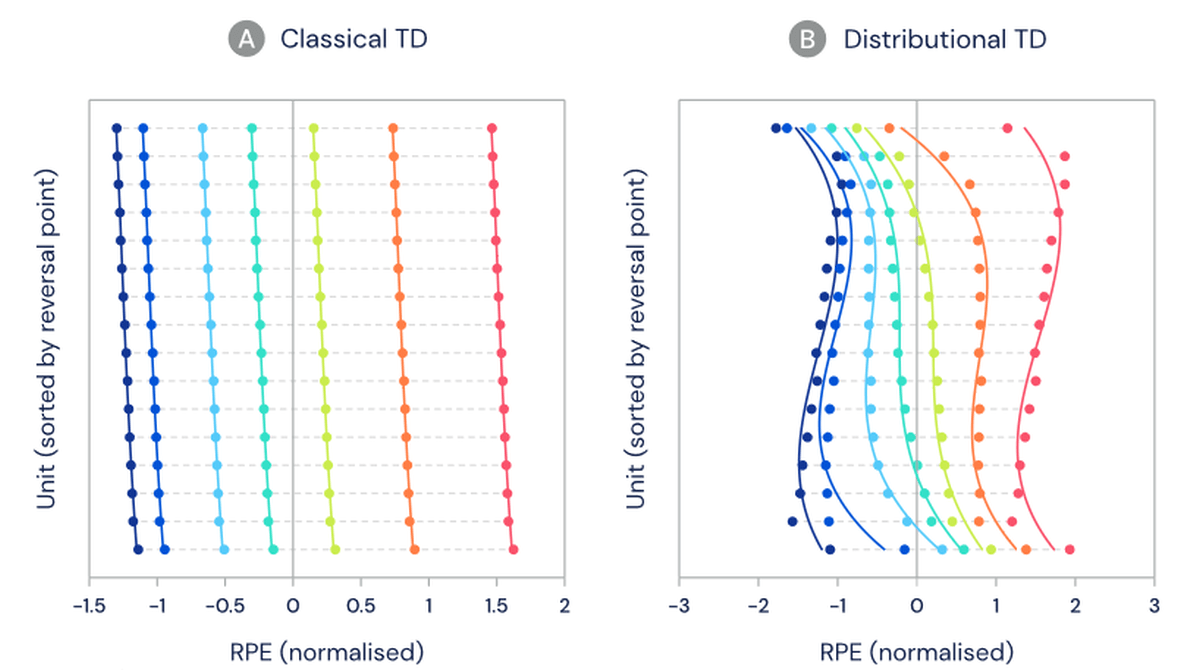
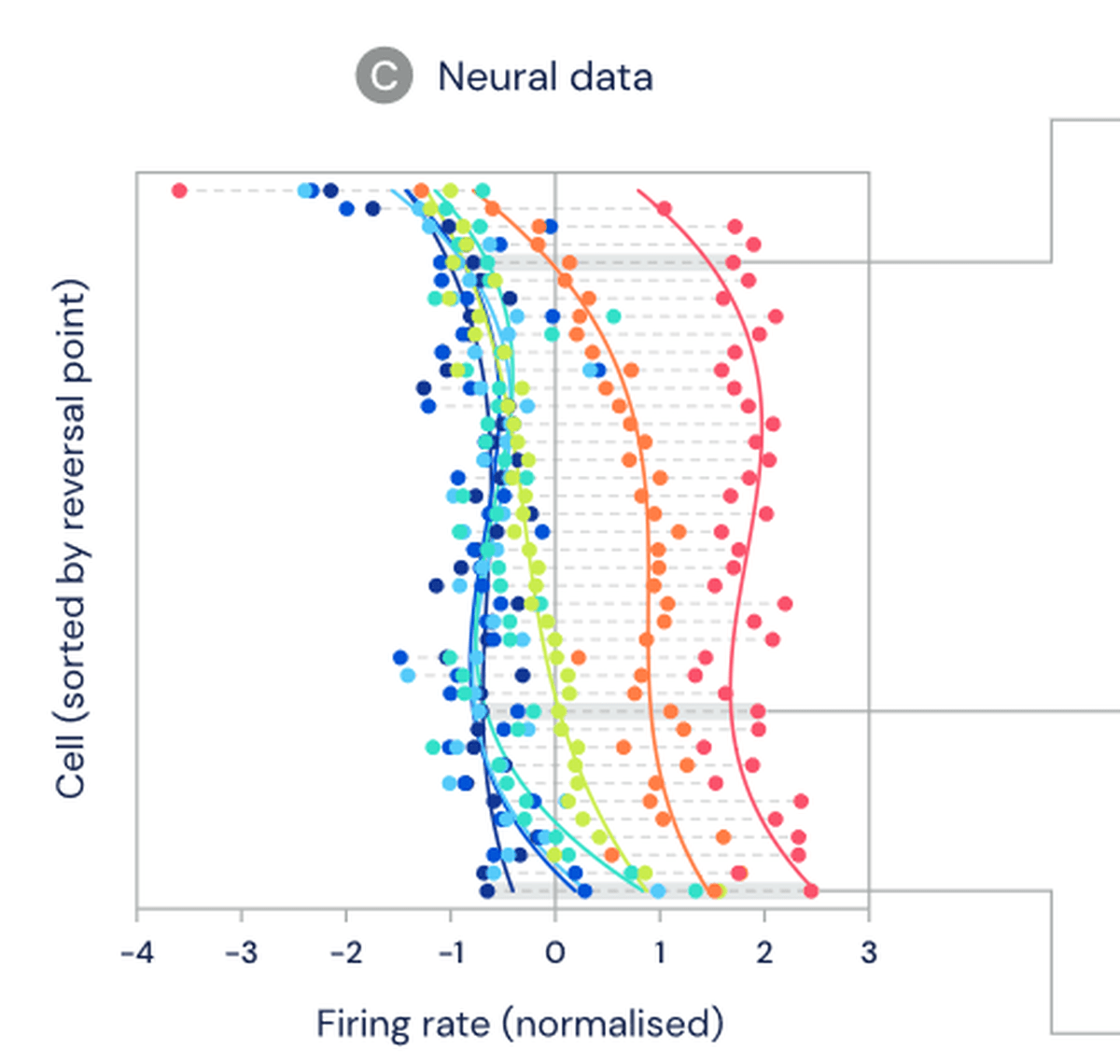
実験の結果、異なるドーパミン細胞間でノイズでは説明できない有意な差異が見られました。ドーパミン細胞の発火率の分布は分布型のTDアルゴリズムに近い形になっています。
報酬量の分布からTDアルゴリズムに従ってドーパミン細胞が反応するのなら、ドーパミン細胞の発火率から報酬量の分布を求めることもできるはず。TDアルゴリズムをデコードして計算してみたところ、計算結果は実際の報酬量の分布と非常に近いことがわかりました。図の灰色部分が実際の報酬量の分布であり、濃い青色が計算結果の平均値です。
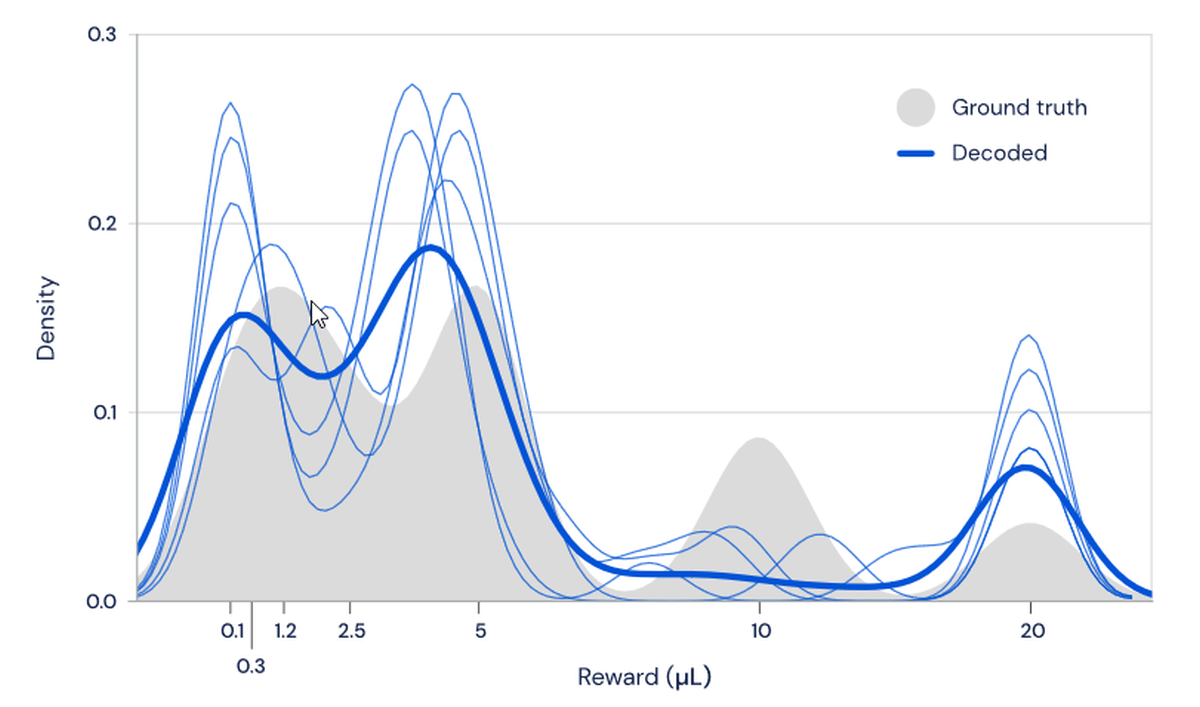
この研究から、脳内のドーパミン細胞はそれぞれ悲観的だったり楽観的だったりと異なるレベルで調整されており、それらが全体として調和していることがわかりました。人工知能の強化学習においては、この多様性の調整がニューラルネットワークにおける学習速度を上げる要素になっており、脳は同じ理由で多様性を確保している可能性があるとのこと。
この発見は人工知能にとっても神経科学にとっても興味深いものであるとのこと。機械学習のアルゴリズムが脳にも備わっていたことは、機械学習の研究が正しい道を進んでいることを示唆しており、神経科学にとっては、もし脳が楽観的なドーパミン神経と悲観的なドーパミン神経に対して選択的に反応する場合、うつ病などにつながる可能性はあるのか、ドーパミン細胞の多様性は脳の他の多様性とどのように関係しているのかといった、メンタルヘルスやモチベーションに対する理解への新しい洞察を与えてくれると述べられています。
・関連記事
DeepMindのAIは人間の医師と同等の精度で目の病気を診断できる - GIGAZINE
人工知能の発達はどのように科学的研究を変えていくのか? - GIGAZINE
DeepMindが「前進せよ」という指令だけで自分で学んで不気味な動きで突き進むAIフィギュアのムービーを公開 - GIGAZINE
Samsungが謎の人工知能プロジェクト「NEON」をスタート - GIGAZINE
Samsungが謎の人工知能プロジェクト「NEON」をスタート - GIGAZINE
世界最強の碁プログラム・AlphaGoの新バージョン「AlphaGo Zero」はもう自力で強くなれるレベルに到達 - GIGAZINE
・関連コンテンツ






in サイエンス, Posted by darkhorse_log
You can read the machine translated English article It turns out that the algorithm of machi….