




世界最強の碁プログラム・AlphaGoの新バージョン「AlphaGo Zero」はもう自力で強くなれるレベルに到達

Google傘下のDeepMindが開発している人工知能(AI)「AlphaGo」(アルファ碁)の新バージョン「AlphaGo Zero」が開発され、名実共に「世界最強」の段階に達していることが発表されました。AlphaGo Zeroはもはや人間が碁の打ち方を教えずとも、自分たちだけで対戦形式のトレーニングを行うことで勝ち方を覚え、イ・セドル棋士に勝ったAlphaGoを100勝0敗で破ったことも報じられているのですが、その強さは旧バージョンからのアルゴリズムの改良によるところが大きいようです。
Mastering the game of Go without human knowledge | Nature
https://www.nature.com/articles/nature24270.epdf
AlphaGo Zero: Learning from scratch | DeepMind
https://deepmind.com/blog/alphago-zero-learning-scratch/
DeepMindが発表した内容によると、AlphaGo Zeroは、自ら碁の打ち方を学ぶことで次第にスキルを身に付け、碁の勝ち方を覚える能力を与えられたAI。その強さの秘密は、自分で繰り返し学習する能力を与えられたことと、その能力を使って何千万回というトレーニングを行ったところにあるといいます。
「世界最強」と称されたイ・セドル(李世乭)九段との5番勝負を4勝1敗で制し、「イ・セドルに勝てても私には勝てない」と語っていた中国の柯潔(か・けつ)九段をも打ち破った従来世代のAlphaGoは、人間による対局のデータを大量に読み込み、機械学習させることで勝ちパターンを学習していたため、そのベースには人間の思考回路が少なからず存在していました。
しかし、人間の手を借りずに全くのゼロ状態から碁の学習を開始したAlphaGo Zeroは、完全に「人間の定石」の影響を受けない状態で碁を覚え、しかも従来のAIを上回る強さを備えるに至っています。
AlphaGo Zeroは、まず最初に碁の基本的なルールだけを教えられ、あとは基本的に自分で対局を繰り返すことで徐々に碁の勝負を覚えて行きます。初期の段階では、まったくランダムでトンチンカンな手ばかりが打たれていたとのことですが、次第にきちんとした勝負を打てるように「成長」。

そしてなんと学習開始から3日目の段階で、李九段に勝利した「AlphaGo Lee」を上回る強さを獲得。つまり、AlphaGo Zeroは練習開始から3日で、「人類最強」と呼ばれた棋士よりも強い段階に達したというわけで、この時の戦績は100試合して全勝という結果でした。
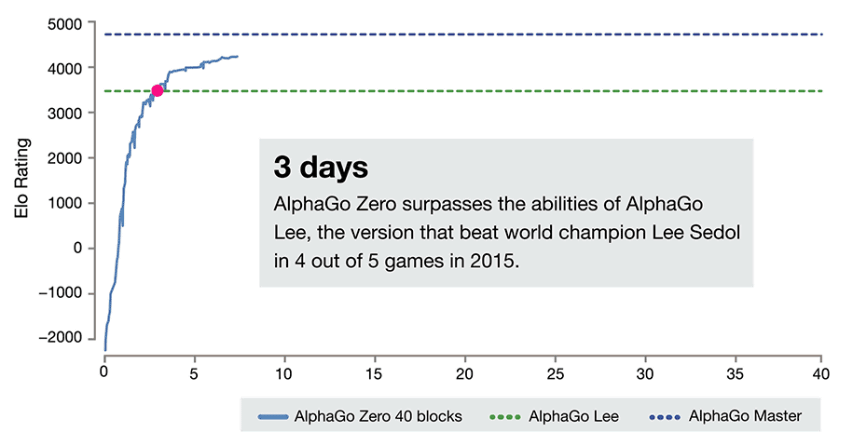
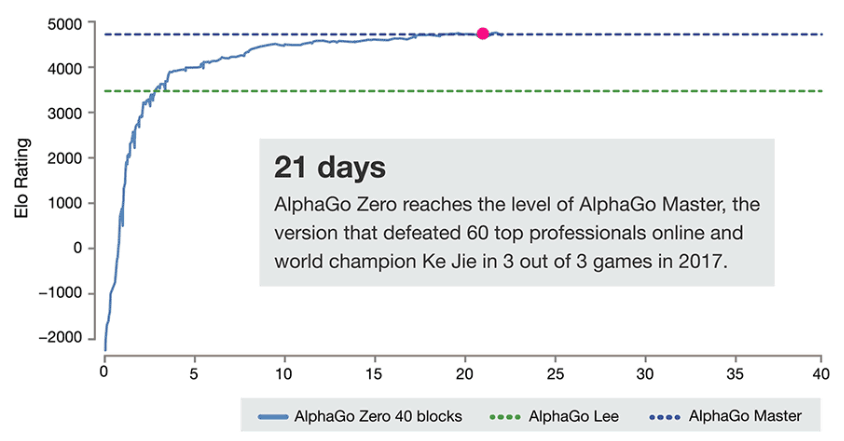
次にAlphaGo Zeroは、オンライン対決のチャンピオン60人と柯九段を破った「AlphaGo Master」を上回る強さを獲得。もはやこの世にはAlphaGo Zeroよりも囲碁で強い人間がいない段階に達しています。そして、なんとここまで到達するのにかかった時間はたったの21日間。とはいえ、AlphaGo Leeを越えたあたりからイロ・レーティングで示される成長曲線の上昇が緩やかになっているのが興味深いところです。
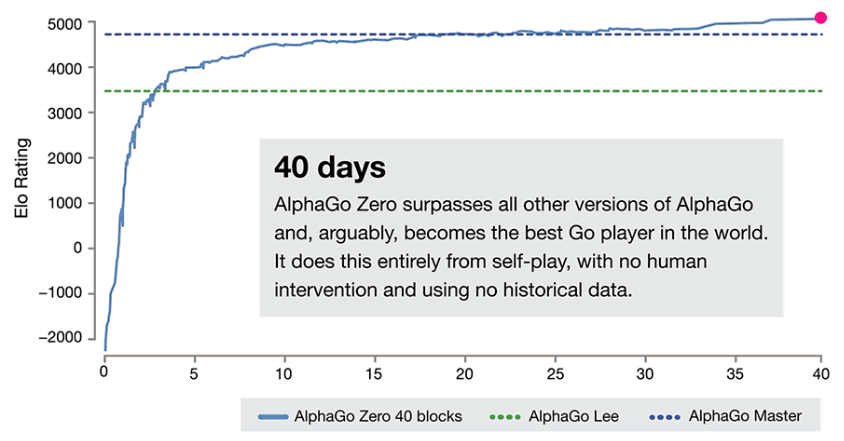
そして40日後、AlphaGo Zeroは現存するすべてのバージョンのAlphaGoを超える強さを獲得。ここまでAlphaGo Zeroには人間の対戦データや「定石」はまったく与えられておらず、完全に自己学習だけで勝ち方を学んでいるという、人類にとって衝撃の結果が生まれています。
この強さは、機械学習の中でも特に強化学習と呼ばれる方法を用いて獲得されています。この方法は、AIがさまざまな試行錯誤を繰り返す中で次第に環境に適応できるようになっており、勝利という「報酬」を与えられることでAIのニューラルネットワークが「正しい戦い方」を学んでいくというもの。AlphaGo Zeroがお互いの「先生」となって相手と対戦し、覚えた勝ち方を複数のAIで共有することでノウハウを蓄積し、その上に立ってさらに勝ち方を覚えるというプロセスが繰り返されたとのことです。
この方法によるメリットは、「人間の知識の限界を超える」というところにあるとのこと。囲碁には長い歴史があり、その中で蓄積されてきたノウハウが存在しているのですが、アルゴリズムの教科学習によって導き出された答えにはその限界が存在しないため、常識にとらわれない「真に強い勝ち方」へと最終的に到達できるというわけです。
AlphaGo Zeroが前の世代に比べて異なる部分は、以下のような点があるとのこと。
・従来バージョンは人間によって書き込まれた特徴が存在しているが、AlphaGo Zeroは碁盤に置かれた白と黒の碁石の情報だけが与えられた
・AlphaGo Zeroは、2つではなく1つだけのニューラルネットワークを使った。従来バージョンは次の手を選択する「ポリシー・ネットワーク」とそれぞれの手から勝者を判断する「バリュー・ネットワーク」を使っていた。これらはAlphaGo Zeroでは一つに統合され、より効率的に学習し、評価できるようになった。
・AlphaGo Zeroは、ある盤面においてどの手が最も有力かを見極めるためにランダムに石を打ち合う「ロールアウト」または「プレイアウト」と呼ばれる手法を用いない。その代わり、高い能力を備えたニューラルネットワークに盤面の評価を担当させる。
これらの違いによって、AlphaGo Zeroは従来のAlphaGoよりも格段に効率的な学習を行えるようになっているとのこと。その結果、AlphaGo Zeroではより少ないプロセッサ(TPU)だけで学習が可能になり、消費される電力も大幅に削減できているそうです。
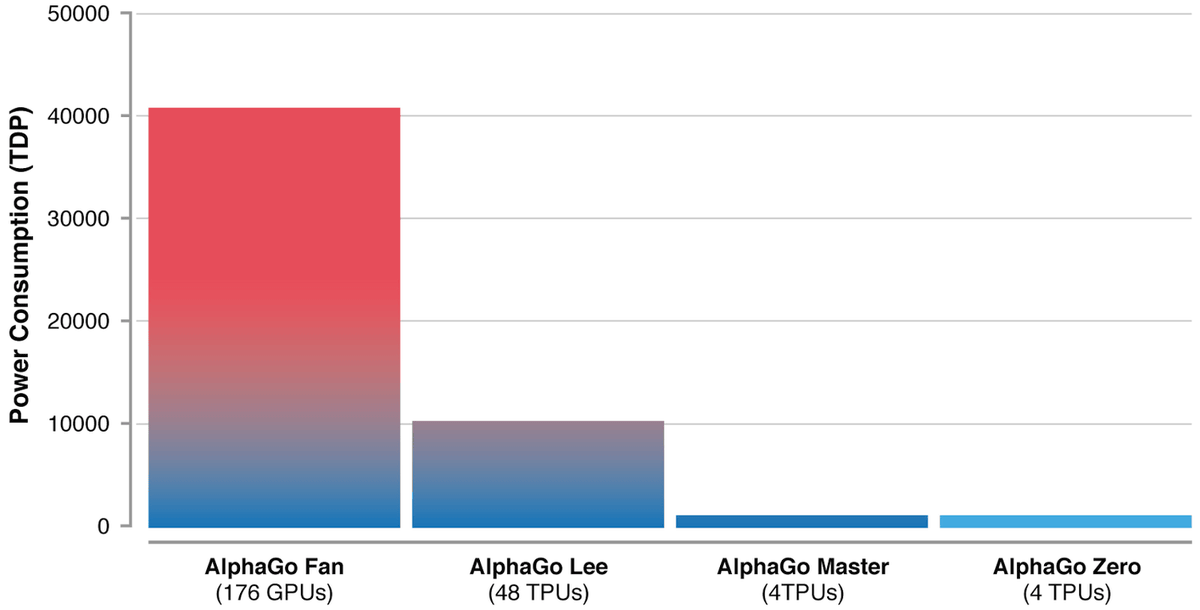
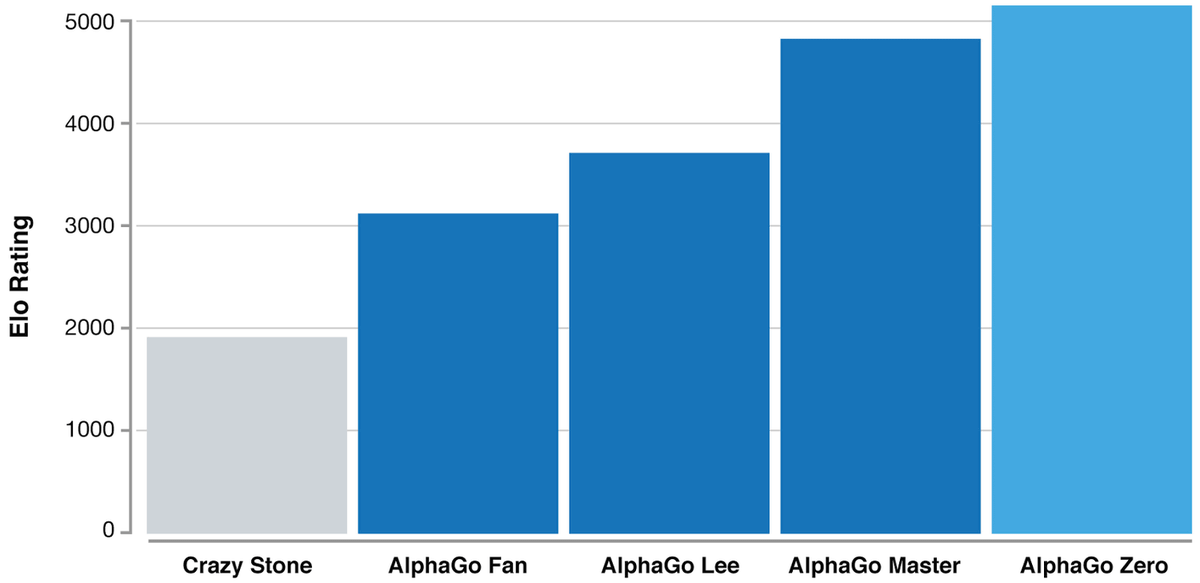
プレイヤーの実力を示す指数である「イロ・レーティング」で各バージョンを比較するとこんな感じ。柯九段を破ったAlphaGo Masterでも超えていなかった「5000」というスコアをAlphaGo Zeroは上回っています。
人の領域を超えたAlphaGo Zeroは、もはや人には考えつかない手すら編み出しているとのこと。学習開始から3時間の段階では、囲碁初心者のようにできるだけ多くの石を置くレベルでしたが……

19時間後には、「生き石・死に石」を考える死活や、「領域」の概念を理解するに到達。

そして70時間後には、もはや人間を超えるレベルに到達。打ち手は規律的なものとなり、1つの盤面の上でいくつもの局面が進行する状況が作り出されるようになっています。また、この中では人間が持っていなかった「定石」が新たに編みだされているとのこと。

ある分野では、人間の持つ能力を凌駕してしまったAI技術を、DeepMindは人間が直面する問題を解決するために使うというミッションに活かすこと目指しています。医療分野では、AIを使うことで難病の早期発見を目指すほか、電力の需要調整にもAI技術を活用することを狙っているとのこと。膨大なデータから有用なインサイトを見いだす「データマイニング」はAIの活躍が期待されている分野であり、DeepMindのデミス・ハサビス氏は「AIは人間の知力を前進させ、全人類に前向きな影響をもたらす可能性がある」と語っています。
囲碁AIが「独学」で最強に グーグル、産業応用探る :日本経済新聞
https://www.nikkei.com/article/DGXMZO22407340Y7A011C1TI1000/
・関連記事
「AlphaGo」に続いてGoogleのDeepMindが人間並みの知性を持つ「スーパーヒューマンAI」の開発へ - GIGAZINE
「囲碁AIはイ・セドルに勝てても私には勝てない」と発言していた中国の最強棋士がアルファ碁に破れる - GIGAZINE
不完全な情報で最適な手が読みにくいゲーム「ポーカー」で人類対AIの頂上決戦「Brains VS. AI」が開催される - GIGAZINE
アルファ碁を作ったDeepMindが3DゲームをプレイするAI「DeepMind Lab」をオープンソースとして公開 - GIGAZINE
Googleの人工知能開発をリードするDeepMindの天才デミス・ハサビス氏とはどんな人物なのか? - GIGAZINE
・関連コンテンツ








in ソフトウェア, Posted by darkhorse_log
You can read the machine translated English article The world's strongest go program · Alph….