




Googleが言語モデルを使わずに高精度な自動音声認識を可能にする「SpecAugment」を開発

by Pxhere
機械学習・人工知能(AI)分野で第一線を走るGoogleは、Cloud Speech-to-Textのように、音声を自動で認識してテキストに変換する自動音声認識技術を研究しています。Google AIの研究者が、言語モデルを使用せずに最先端の自動音声認識モデルのパフォーマンスを向上させる技術「SpecAugment」を開発したと発表しました。
[1904.08779] SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
https://arxiv.org/abs/1904.08779
Google AI Blog: SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition
https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html
Google's SpecAugment achieves state-of-the-art speech recognition without a language model | VentureBeat
https://venturebeat.com/2019/04/22/googles-specaugment-achieves-state-of-the-art-speech-recognition-without-a-language-model/
言語モデルとは、言語において単語と単語の関係を数学的に表したもの。本来であればただの音でしかない音声を、「単語列に対してどういう単語が来るか」を学習することで、意味のある文章に変換できるというわけです。そのため、自動音声認識を可能にするAIは言語モデルに基づいて訓練が行われる必要があります。
そんな中、Google AIの研究者であるウィリアム・チャン氏やダニエル・パーク氏率いる研究チームが公式ブログで発表したSpecAugmentは、言語モデルの助けを借りずに、従来の方法よりも精度が上回る自動音声認識モデルを構築することが可能な技術になっているそうです。
従来の自動音声認識モデルでは、音声データをスペクトログラムの形で視覚的表現に変換してから、ネットワークモデルに入力します。認識処理はスペクトログラムで行われますが、用意するデータ自体は大量の音声データが必要となり、膨大な計算コストがかかります。
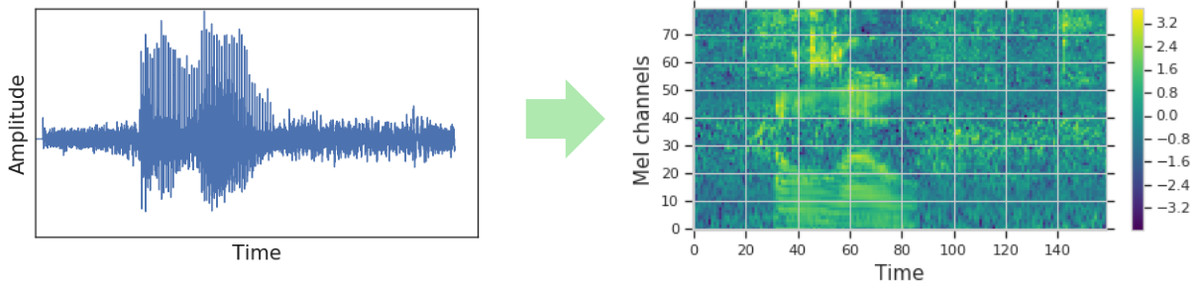
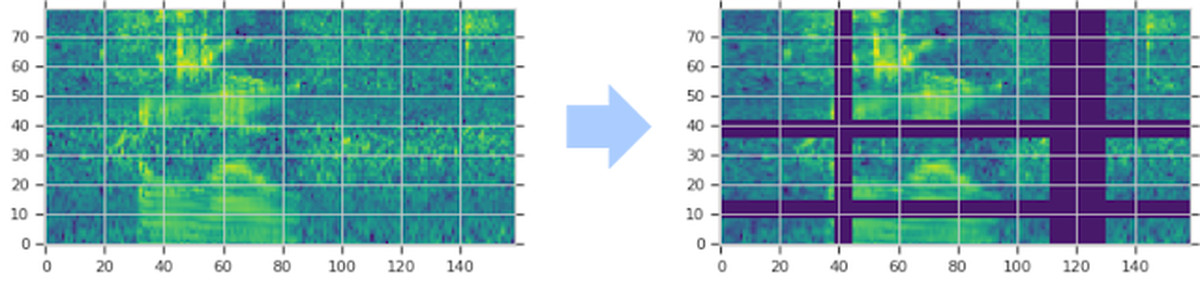
SpecAugmentは、スペクトログラムデータを直接編集してマスクをかけ、スペクトログラムデータの増強を行うというもの。このSpecAugmentを用いることで、モデルの過学習を防ぐことができ、さらに言語モデルの支援がなくても従来のモデルよりも高い精度で音声認識することが可能になったそうです。
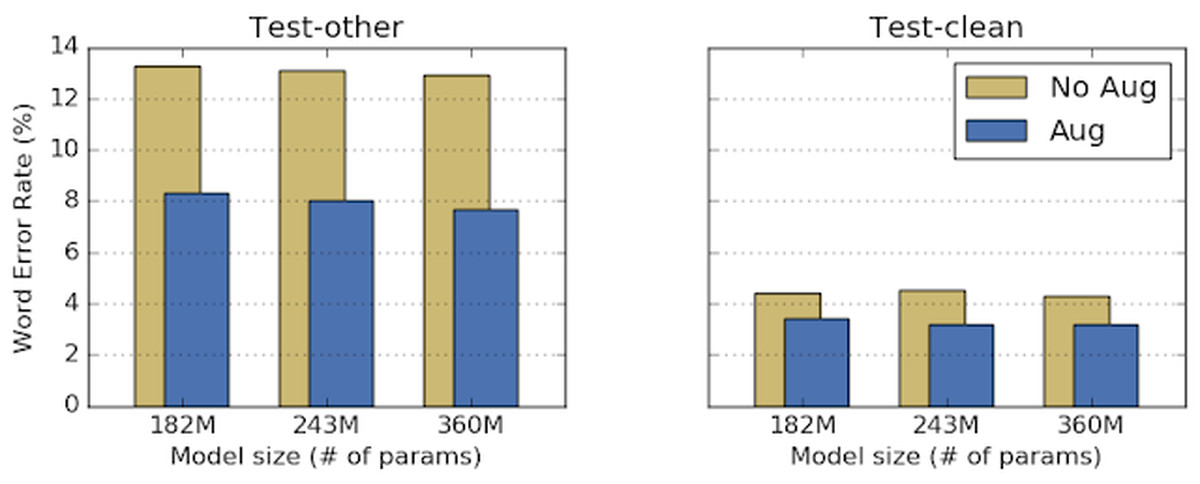
以下のグラフは左がノイズの多い音声、右がノイズの少ない音声での精度を比較したものです。従来の自動音声認識モデル(黄色)の誤認識率はノイズが多い音声だと12~14%、ノイズが少ない音声だと4~5%ほどとなっています。対してSpecAugmentを用いた自動音声認識モデル(青色)だと、ノイズが多い音声で8%前後、ノイズが少ない音声だと約3%と、明らかに誤認識率が低下し、精度が上がっていることがわかります。
こうした技術に支えられる自動音声認識モデルは、メールの口述筆記モードに使われたり、スマートスピーカーに搭載されるような会話型AIの音声をテキストに変換するような場面で利用されるとのこと。また、誤認識率が低下することで、実際に指を動かしてタイプするよりも早い入力が音声で可能になることが期待できます。
・関連記事
Amazon・Apple・Google・Microsoft・サムスンの音声アシスタントが音声データをどう扱っているか比較してみた - GIGAZINE
自然言語処理などに利用されるAIモデルは言葉の「言い換え」に脆弱であると研究者らが指摘 - GIGAZINE
Googleが新たに低遅延&オフラインで使用可能な音声認識システムを開発 - GIGAZINE
Googleがスマホ上で音声をリアルタイムでテキストに起こすアプリを聴覚障害者向けに開発 - GIGAZINE
Google Chrome上でマイクから録音した声をリアルタイムで文字に書き起こしてくれる「The Recording Studio」 - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article Google develops 'SpecAugment' that enabl….