




CloudflareがAIボットを「検索」「代理操作」「学習」など種類ごとに制御する仕組みを公開、無料プランでも「検索は許可、AI学習は拒否」を設定可能

CloudflareがウェブサイトにアクセスするAI関連ボットを用途ごとに管理できる新しいアクセス制御オプションを全ユーザー向けに公開したと発表しました。新オプションでは検索向けの巡回を許可しつつ、AIモデルの学習やユーザーの代わりに操作するエージェントによるアクセスを制限するといった設定が可能になります。
Your site, your rules: new AI traffic options for all customers
https://blog.cloudflare.com/content-independence-day-ai-options/
Google検索などの検索エンジンでは、クローラーがページを読み取って検索結果に表示できるようにすることで、読者が目的のコンテンツにたどり着けるようになります。一方で、同じページ内容がAIモデルの学習に使われ、検索結果のような流入や見返りが戻ってこないケースも増えています。Cloudflareは従来の「クローラーが巡回し、サイト側は参照トラフィックを得る」という関係が崩れつつあると説明しています。
このためサイト運営者は「検索結果には表示されたいが、AIの学習には使われたくない」という難しい選択を迫られます。小規模なブログやニュースサイトの場合、クローラーをまとめて拒否すると読者に見つけてもらいにくくなります。しかし、すべての自動アクセスを許可すると、AI企業がコンテンツを収集してモデルの学習に使う可能性があります。Cloudflareは「この二択だけではサイト運営者にとって不十分だ」として、AIトラフィックをより細かく扱う仕組みを導入しました。
新しい分類では、AI関連のボットは主に「検索(Search)」「代理操作(Agent)」「トレーニング(Training)」の3種類に分けられます。「検索」は検索結果や回答生成のためにページを収集・索引化するアクセスで、サイト運営者に参照トラフィックや何らかの対価が戻ることが期待されるもの。「代理操作」はチャットAIが利用者の依頼を受けてページを開いたり、GeminiやClaudeがブラウザを操作したりするような、利用者の代わりにリアルタイムで作業するアクセスです。「トレーニング」はページ内容をAIモデルの学習や微調整に使うための巡回を指します。
従来のCloudflareには「Block AI Bots」というAIボットをブロックする管理プリセットがあり、主にモデル学習向けの単一用途ボットを対象としていました。今回の発表は既存機能の拡張にあたり、AIボットを一括で拒否するのではなく、「検索」は許可、「トレーニング」は拒否、「代理操作」は用途に応じて判断するといった運用が可能になります。CloudflareはAIの利用形態が検索、チャット、ブラウザ操作、学習などに広がっているため、ボットを「AIかどうか」だけで判断するのではなく、「ウェブサイト上で何をしているのか」「取得した内容をどのように保存・再利用するのか」で扱う必要があると説明しています。
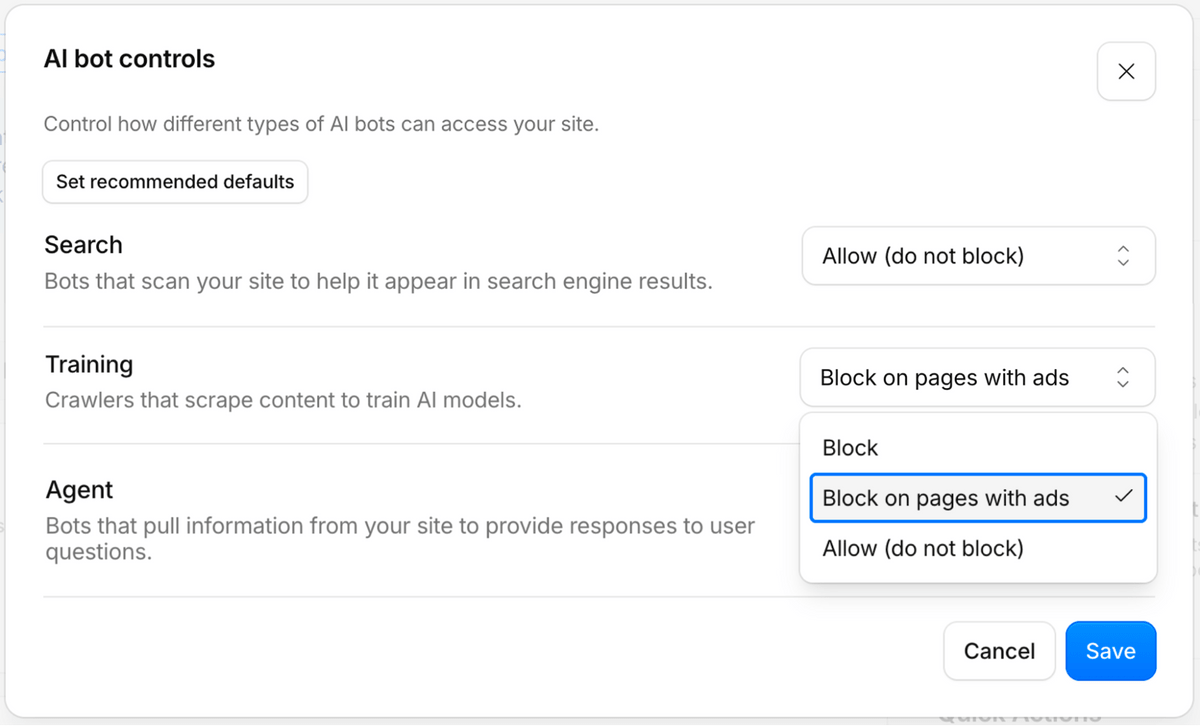
また、1つのクローラーが複数の目的を持つ場合は、複数の分類で扱われます。たとえば検索用インデックスの作成とAI学習の両方に使われるボットは、「検索」だけでなく「トレーニング」としても分類されます。Cloudflareは2026年9月15日以降、「検索」と「トレーニング」を兼ねるような複数用途のクローラーに対して最も制限の強いルールが適用するとしており、「トレーニング」をブロックする設定を選んだユーザーや従来のBlock AI Botsを有効にしているユーザーでは、Googlebot、Applebot、BingBotのような複数用途のクローラーもブロック対象になる場合があるとのことです。
さらにCloudflareは2026年9月15日以降、新しくCloudflareに追加されるドメインについて、広告が表示されるページでは「トレーニング」と「代理操作」をデフォルトでブロックし、「検索」はデフォルトで許可する設定にすると発表しました。広告が表示されるページは人間の読者が訪れて広告を見ることを前提にしたページであり、AI学習やエージェントによるアクセスが人間の訪問機会を奪う可能性があるためです。一方で、「検索」は読者の流入につながる性質があるため、多くのサイト運営者にとって許可するメリットがあるとCloudflareは見ています。
Enterprise Bot Managementユーザー向けには、新たに「BotBase」も公開されました。BotBaseはCloudflareが追跡している既知のボットやエージェントを検索できるデータベースで、各ボットが「検索」「代理操作」「トレーニング」などのどの分類に入るのかをCloudflareダッシュボード上で確認できます。特定のボットだけを狙ってルールを作りたい場合は、対象ボットのトラフィックを絞り込んだり、検出IDをコピーしてセキュリティルールに利用したりできるとのことです。
ボットが取得したコンテンツをどの程度再利用するのかを示す仕組みの整備も進められています。Cloudflareは「即時(immediate)」「参考文献(reference)」「完全利用(full)」という3段階のcontent useを説明しており、「即時」は保存や再利用をしない利用、「参考文献」は索引化や抜粋とリンクバックを伴う利用、「完全利用」は要約や再掲載まで含む利用を意味します。Cloudflareはrobots.txtに記載できるContent Signalsへ新たに「use=reference」のような指定を追加するテストを始めており、Cloudflare管理のrobots.txtを有効にしているユーザーには「検索は許可、AI学習は拒否、利用はreferenceまで」という趣旨の意思表示が追加されるとのことです。
また、以前はCloudflareが身元や用途を確認したVerified botであれば基本的にアクセスが許可される扱いでしたが、Cloudflareは2026年7月1日からVerifiedというラベルだけで自動的に許可される扱いを見直し、「検索」など許可された分類に属しているかどうかでアクセス可否を決めるとのこと。Cloudflareはボット運営者に対して、検索、エージェント、学習のような目的を分けてクローラーを運用することを強く推奨しており、サイト運営者が「なぜアクセスされているのか」を理解しやすくする狙いがあります。
Cloudflareは一連の変更について、ウェブの環境が変わり続けても、コンテンツを作る人が使われ方を決められ、ボット側が目的を正直に示すほどアクセスを得やすくなる信頼ベースのウェブを目指す方針は変わらないと述べています。新しいAIトラフィック管理オプションは記事作成時点ですでに利用可能で、Cloudflareの管理画面から設定できるとのことです。
・関連記事
AIがウェブサイトに訪問するたびに課金できるシステム「Monetization Gateway」をCloudflareが発表 - GIGAZINE
AIにコンテンツのスクレイピングを許可するかどうかをクリエイターが簡単に制御できる機能をCloudflareが提供開始 - GIGAZINE
各種AIボットによるウェブサイトへのアクセス数をCloudflareが集計してグラフ化、最も活動量の多いAIボットは何なのか? - GIGAZINE
ウェブをマネタイズするためのAPI「Web Monetization API」 - GIGAZINE
CloudflareがAIクローラーを無限生成迷路に閉じ込める「AI Labyrinth」を発表 - GIGAZINE
・関連コンテンツ







in ネットサービス, Posted by log1d_ts
You can read the machine translated English article Cloudflare has unveiled a system that al….