




32GBのVRAMを搭載して他のグラボより激安の「Intel Arc Pro B70」はローカルAIを実際に動かすとどれぐらいの性能とトークンのコスパを発揮するのか?

32GBのGDDR6メモリを搭載するワークステーション向けGPU「Intel Arc Pro B70」について、ワークステーションメーカーの Puget SystemsがローカルLLM推論と画像生成での実測ベンチマークを公開しました。
Intel Arc Pro B70: Multi-GPU AI Inference Performance | Puget Systems
https://www.pugetsystems.com/labs/articles/intel-arc-pro-b70-multi-gpu-ai-inference-performance/
Intel Arc Pro B70は1枚あたり949ドル(約15万1840円)という価格で、同じ32GB VRAMクラスで販売価格の相場が70~80万円であるNVIDIA GeForce RTX 5090を大きく下回る価格設定が特徴です。日本でも「ASRock Intel Arc Pro B70 Creator 32GB 」が2026年6月19日から販売開始されており、市場想定価格が税込22万4800円となっています。また、Amazon.co.jpだと記事作成時点でIntel製グラフィックボードが税込26万6389円で購入可能です。
Amazon | Intel Arc Pro B70 グラフィックカード - 32GB GDDR6 | インテル | グラフィックボード 通販
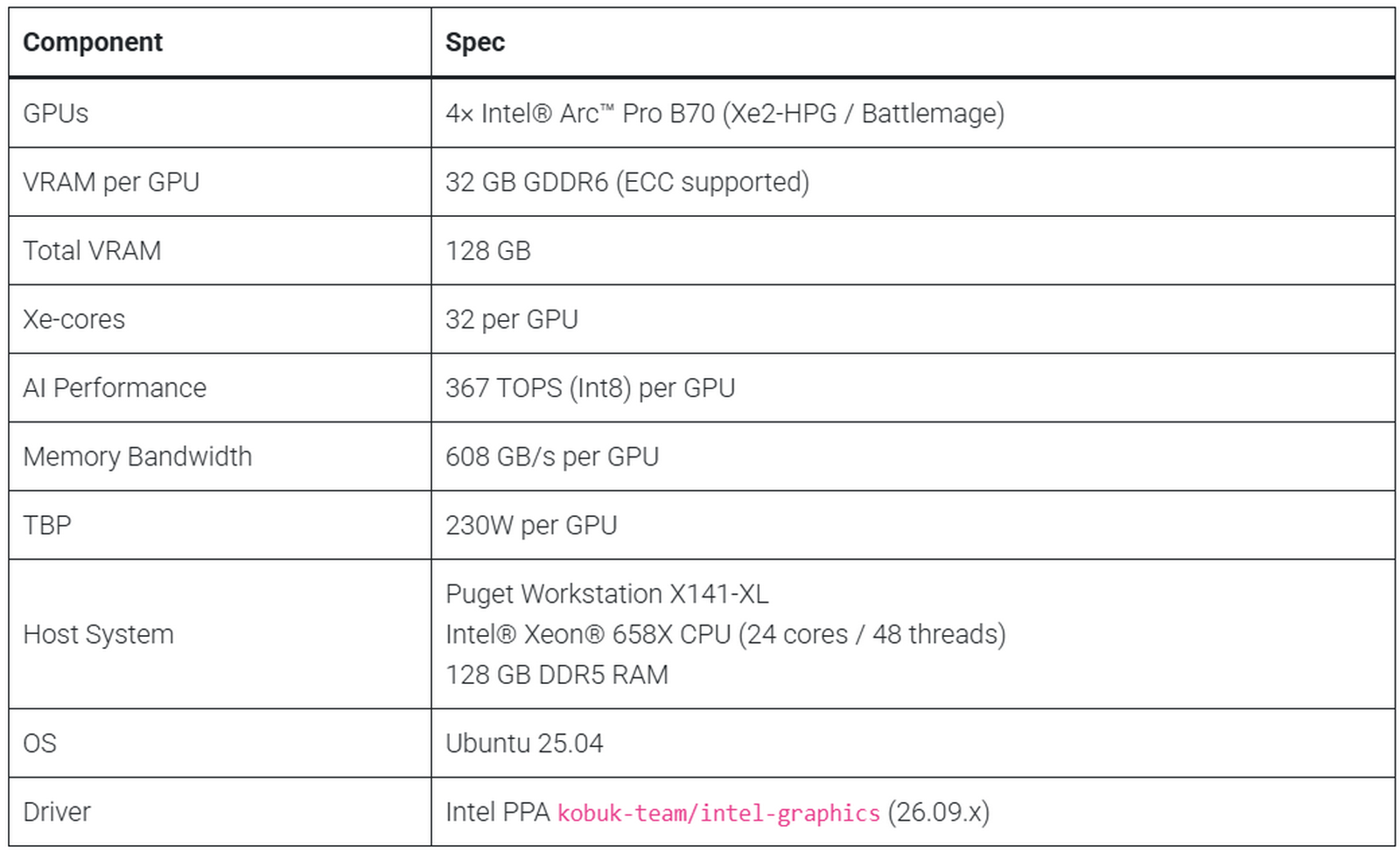
Puget Systemsは検証用にIntel Arc Pro B70を4枚搭載したワークステーションを構築し、合計128GB分のVRAMを用意しました。テスト環境はUbuntu 25.04、Intel Xeon 658X、128GB DDR5メモリ、IntelのLLM Scaler向けvLLMコンテナという構成で、LLMベンチマークはすべてFP16の非量子化モデルで行われました。入力500トークン、出力500トークン、同時ユーザー数1・4・8という条件で測定し、GPU消費電力もあわせて記録することで、100万出力トークンあたりの実行コストも算出しました。
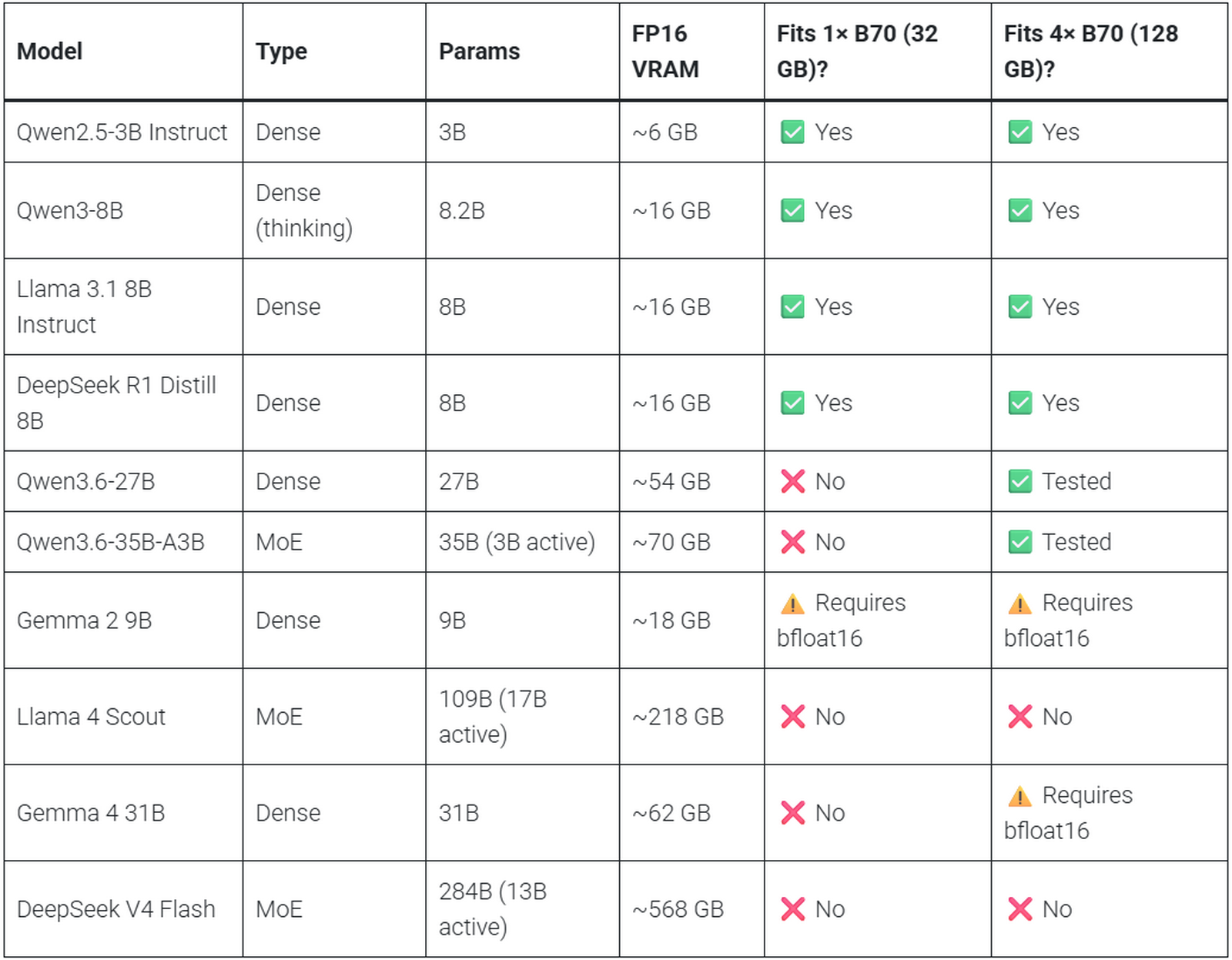
Intel Arc Pro B70を1枚あるいは4枚で動かす場合の、ローカルAIモデルの動作状況は以下の表の通り。Qwen2.5-3B Instruct・Qwen3-8B・Llama 3.1 8B Instruct・DeepSeek R1 Distill 8Bは1枚でも動作可能で、Qwen3.6-27BとQwen3.6-35B-A3Bは4枚であれば動作が確認できたとのこと。ただし、2026年6月時点のvLLM XPUバックエンドではbfloat16(16ビット浮動小数点数演算)が扱えず、Gemma 2 9BやGemma 4 31Bのようにbfloat16を必要とするモデルはIntel Arc Pro B70でそのまま動かせなかったとのこと。
単体のIntel Arc Pro B70で動かした場合、Qwen2.5 3B Instructは毎秒72.9トークン、DeepSeek R1 Distill Llama 8Bは毎秒66.9トークン、Llama 3.1 8B Instructは毎秒35.4トークン、Qwen3 8Bは毎秒34.7トークンを記録しました。3B級モデルや8B級モデルは1枚のIntel Arc Pro B70でも問題なく動作し、特にDeepSeek R1 Distill Llama 8Bは8B級モデルとして高い処理速度を示しています。Qwen3 8Bについては、推論前に「考える」処理が入るため通常の30秒測定では性能を正しく測れず、120秒の測定時間に延ばすことで実際のスループットが確認されました。
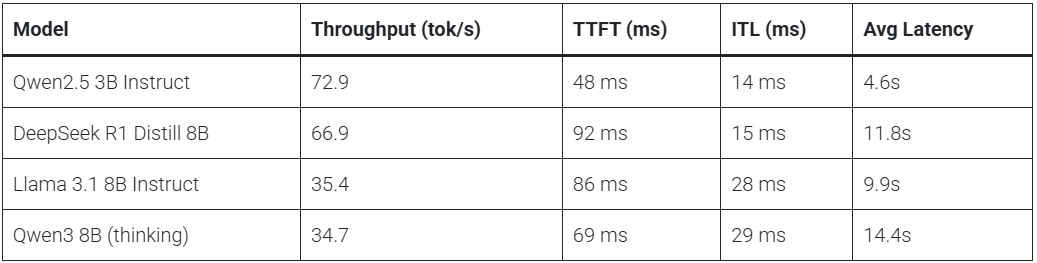
Intel Arc Pro B70×4枚構成でテンソル並列を使うと、8B級モデルでは単体時よりも処理速度が大きく伸びます。Llama 3.1 8B Instructは1ユーザー時に毎秒35.4トークンから毎秒70.3トークンへ、DeepSeek R1 Distill Llama 8Bは毎秒66.9トークンから毎秒136トークンへと、どちらもほぼ2倍に高速化しました。8ユーザー同時実行時には、Llama 3.1 8B Instructが毎秒472トークン、DeepSeek R1 Distill Llama 8Bが毎秒905トークンに達しており、複数人で使う社内向けローカルAIサーバーのような用途では大きな効果が出ています。
また、4枚構成は1枚の32GB VRAMには収まらない中規模モデルをFP16のまま動かせます。Qwen3.6-27B DenseはFP16で約54GB、Qwen3.6-35B-A3B MoEは約70GBのVRAMを必要とするため、単体のIntel Arc Pro B70では動作しません。4枚構成ではQwen3.6-27B Denseが1ユーザー時に毎秒13.1トークン、8ユーザー時に毎秒95.9トークンで動作し、Qwen3.6-35B-A3B MoEは1ユーザー時に毎秒16.3トークン、8ユーザー時に毎秒122トークンで動作しました。
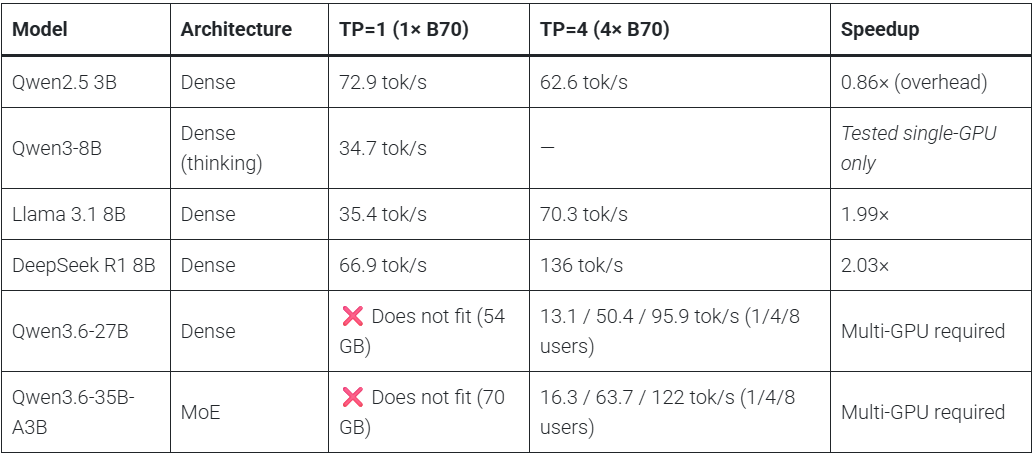
一方で、単体GPUの速度だけを見るとNVIDIA GeForce RTX 5090の方がかなり高速です。Puget Systemsは、RTX 5090なら8B級のFP16モデルでおおむね毎秒140~200トークンを出せる一方、Intel Arc Pro B70は毎秒35~67トークン程度だったとのこと。ただし、どちらも1枚でFP16のまま扱えるモデル規模はおおむね15B程度までであり、Intel Arc Pro B70は1枚あたりの速度よりも、安価にVRAM容量を積み増せる点に強みがあります。
Puget Systemsは、電気代を0.18ドル(約29.0円)/kWh、システム全体の消費電力を「GPU平均消費電力+ホスト側300W」として、100万出力トークンあたりのコストを計算しています。以下は、各ローカルAIの処理速度と100万出力トークン当たりのコスト、Gemini 3.1 Pro・Claude Opus 4.8・GPT-5.5とのコスト比較をまとめた表です。
| モデル | GPU構成 | 処理速度 | システム消費電力 | 100万出力トークンあたりのコスト | Gemini 3.1 Proとのコスト比較 | Claude Opus 4.8とのコスト比較 | GPT-5.5とのコスト比較 |
|---|---|---|---|---|---|---|---|
| Qwen2.5 3B | 1枚 | 毎秒72.9トークン | 628W | 0.43ドル(約69.2円) | 28分の1 | 58分の1 | 70分の1 |
| DeepSeek R1 8B | 1枚 | 毎秒66.9トークン | 650W | 0.49ドル(約78.9円) | 25分の1 | 51分の1 | 62分の1 |
| Qwen3 8B | 1枚 | 毎秒34.7トークン | 593W | 0.85ドル(約137円) | 14分の1 | 29分の1 | 35分の1 |
| Llama 3.1 8B | 1枚 | 毎秒35.4トークン | 650W | 0.92ドル(約148円) | 13分の1 | 27分の1 | 33分の1 |
| Qwen3.6-35B-A3B | 4枚 | 毎秒16.3トークン | 720W | 2.21ドル(約356円) | 5.4分の1 | 11分の1 | 14分の1 |
| Qwen3.6-27B | 4枚 | 毎秒13.1トークン | 832W | 3.18ドル(約512円) | 3.8分の1 | 7.9分の1 | 9.4分の1 |
上記の表で最も安いQwen2.5 3Bは、100万出力トークンあたり0.43ドル(約69.2円)で動作しています。8B級モデルでもDeepSeek R1 8Bが0.49ドル(約78.9円)、Llama 3.1 8Bが0.92ドル(約148円)となっており、クラウドAPIの100万出力トークンあたり12ドル(約1930円)~30ドル(約4830円)という価格と比べると大幅に安価です。4枚構成が必要なQwen3.6-27Bでも3.18ドル(約512円)で、Puget Systemsの比較ではGemini 3.1 Proより3.8倍、Claude Opus 4.8より7.9倍、GPT-5.5より9.4倍安くなっています。
また、同時ユーザー数を増やすと、トークン単価はさらに下がります。Qwen2.5 3Bは1ユーザー時の0.43ドル(約69.2円)から、4ユーザー時に0.113ドル(約18.2円)、8ユーザー時に0.060ドル(約9.66円)まで低下しました。DeepSeek R1 8Bも8ユーザー時には0.068ドル(約10.9円)、Llama 3.1 8Bも0.128ドル(約20.6円)まで下がっており、複数人が継続的に使う環境ほどローカル実行のコスト優位が大きくなります。
ただし、表のローカルコストは電気代のみで、ワークステーション本体の購入費は含まれていません。Puget Systemsの4枚構成テストシステムは2026年6月時点で約1万8000ドル(約290万円)とされており、初期投資はかなり大きくなります。Qwen3.6-27Bをローカルで動かしてクラウドAIのGemini 3.1 Proと比較した場合、100万トークンあたり8.82ドル(約1420円)節約できる計算で、約20億4100万トークンを処理するとシステム価格を回収できるとのこと。
LLMだけでなく、画像生成でもIntel Arc Pro B70は実用的な結果を出しています。Puget SystemsはComfyUI+Z-Image Turboの組み合わせで、1024×1024ピクセルの画像生成をテストしました。Z-Image Turboは4ステップで高速生成する蒸留拡散モデルで、ComfyUIはNVIDIA専用のCUDAカーネルに依存せずPyTorchで推論を行うため、Intel Arc Pro B70をXPUデバイスとしてそのまま認識したとのことです。
以下はZ-Image Turboで、Arc Pro B70上で生成された画像です。ComfyUI+Z-Image Turboのテストでは、15.6GBのパイプライン全体がIntel Arc Pro B70の32GB VRAMに収まり、オフロードなしで動作しました。

初回はモデル読み込みと実行時に必要な処理をその場で最適化・コンパイルする影響で10.6秒かかりましたが、2回目以降の安定動作では平均3.9秒で1024×1024ピクセル画像を生成したとのこと。10回連続の生成テストは失敗ゼロで、平均4.7秒、p50は3.96秒、スループットは毎分12.86枚、ピークVRAM使用量は19.3GBでした。
Puget Systemsはこの結果から、Intel Arc Pro B70は「1枚で最速のGPU」ではなく「32GB VRAMを安価に積めるAI向けGPU」だと見るのが実態に近いと論じています。8B級モデルを単体で動かす用途であればIntel Arc Pro B70は十分実用的で、4枚構成にすると27B~35B級モデルをFP16のままローカルで扱えるようになります。さらに、同時ユーザー数が増える環境では100万出力トークンあたりの電気代が数十円規模まで下がり、トークン単価の面ではクラウド駆動のAIに対して大きな優位性を示します。
もっとも、ソフトウェア面の制約は残っています。また、IntelのLLM ScalerコンテナではINT4、FP8、GPTQのサポートが用意されているものの、Puget Systemsの今回のベンチマークでは量子化推論は未検証であり、すべてFP16で測定されています。
また、Puget Systemsは、Intel公式のvLLMコンテナではArc Pro B70向けではないライブラリとの競合が発生し、マルチGPU推論を動かすにはコンテナ設定や環境変数の調整が必要だったと説明。Intel Arc Pro B70は安価な大容量VRAMという魅力を持つ一方で、CUDA環境に慣れたユーザーが何も考えずに置き換えられる製品ではなく、Linux環境やIntel XPUまわりの調整に対応できるユーザー向けの選択肢と評価しました。
・関連記事
PCのメモリは16GBで足りるのか? RAM容量はどういう時にパフォーマンスに影響を与えるのかを検証 - GIGAZINE
無料で「ComfyUI」「Open WebUI」などからローカルAIモデルをGPUで動かすDocker環境を一発で構築し動かし続ける「Puget Systems Docker App Packs」 - GIGAZINE
AIが科学者にとってどれだけ役立つかを測定できるベンチマークテスト「LifeSciBench」をOpenAIが公開 - GIGAZINE
ComfyUIがOpenAI・Anthropic・Google・MoonshotのAIを競わせてプルリクをレビューする仕組みを公開 - GIGAZINE
「どのLLMがロシアのプロパガンダに対抗するのに優れているか?」がわかるベンチマークをエストニア政府が発表 - GIGAZINE
「Premiere Pro」や「DaVinci Resolve」を実際に自動操作してPCの性能を測定できるベンチマークツール「Puget Bench 2.0」の使い方まとめ - GIGAZINE
・関連コンテンツ






in AI, ハードウェア, Posted by log1i_yk
You can read the machine translated English article With 32GB of VRAM and significantly lowe….