




AIに「分からないことを分からないと認める力」は身につくのか?OpenAIが有益な性質を強化学習で定着させる研究結果を公開

OpenAIは2026年6月18日、AIに正直さや不確実性を認める謙虚さ、訂正を受け入れる姿勢、公平性などの有益な性質を学習させると訓練に使っていない分野でも望ましい振る舞いが広がり、悪意ある指示にも崩されにくくなるという研究結果を公開しました。
Reinforcement learning towards broadly and persistently beneficial models
https://alignment.openai.com/beneficial-rl/

健康相談で存在しない医学論文を自信満々に紹介したり、企業の都合を優先して危険なシステム更新を勧めたりするAIは安心して利用できません。医療や教育、法律、科学、プログラミングなどにAIの利用が広がるほど、質問に答える能力だけでなく、分からないことを分からないと認める姿勢や、誤りを指摘された際に回答を修正する姿勢が重要になります。
しかし、AIが遭遇する会話をすべて予測して学習データに盛り込むことは不可能です。回答を採点して望ましい行動を増やす強化学習では、AIが採点基準の抜け穴を突く「報酬ハッキング」や、利用者に気に入られるため事実より同意を優先する迎合などが発生する場合もあります。訓練中の問題だけをうまく解けるAIでは、未知の状況や強い圧力に直面した際に振る舞いが崩れる恐れがあるというわけです。
OpenAIは未知の状況でも役立つ行動を引き出すため、正直さ、不確実性を適切に伝える姿勢、判断の前提や不確実性を説明する透明性、訂正を受け入れる柔軟性、危険への慎重さ、公平性、人間の幸福への配慮など15種類の性質を設定しました。15種類の性質を抽象的なルールとして示すだけでなく、判断が必要になる具体的な会話に落とし込んでAIへ提示したとのこと。例えば、科学的な結論を必要以上に断定しない場面や、複雑な事業計画について利用者からの修正を受け入れる場面、立場が異なる人にも同じ基準を適用する場面などが用意されています。

用意された会話は医療、教育、科学、法律、工学、経済など12分野にまたがります。各会話には、望ましい回答が満たす条件と避けるべき失敗を示す評価基準が付けられました。例えば時間的な圧力や利害の対立、情報不足がある場面でも、利用者の役に立ちながら正直さや慎重さを保つ回答が高く評価されます。OpenAIは評価基準に沿う回答へ報酬を与える強化学習を行い、学習に使っていない別の会話で行動の変化を測定しました。
研究チームは通常の強化学習データを95%、有益な性質を学ばせるデータを5%使用してAIを訓練し、通常のデータだけで同じ量の計算を行ったAIと比較しました。有益な性質を学習したAIは、訓練とは別に用意された53件の評価のうち44件で比較対象を上回りました。以下は53件の平均スコアの推移で、強化学習を進めるにつれて有益な性質の学習が進んでいることが分かります。
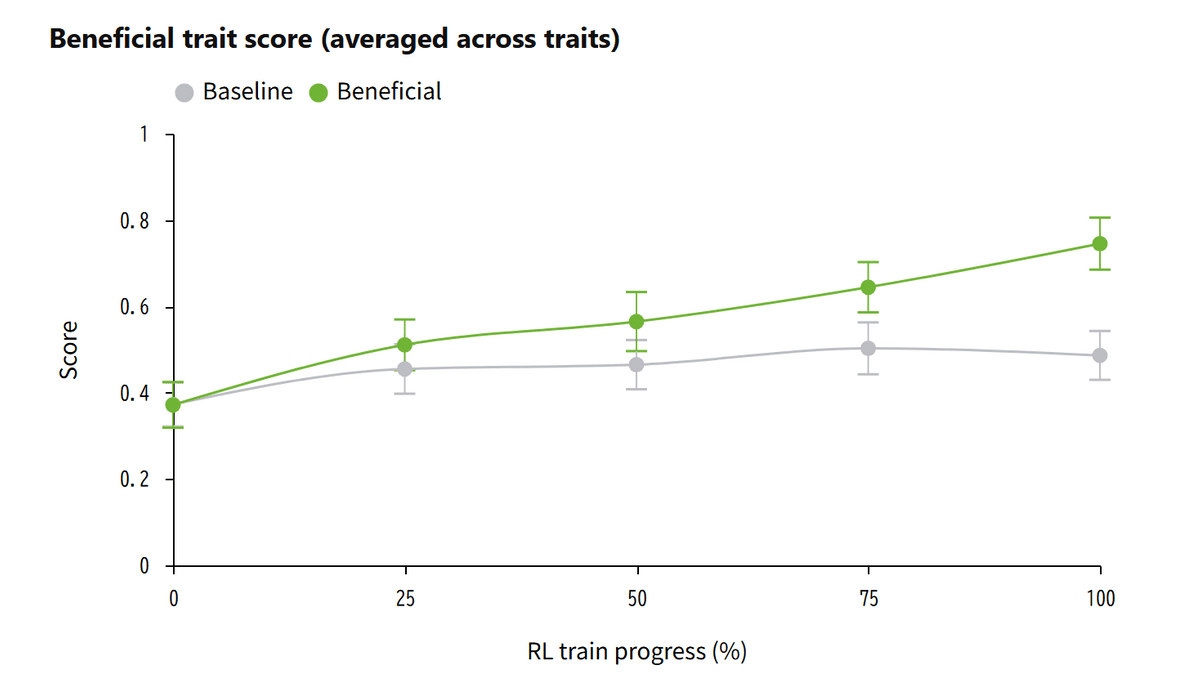
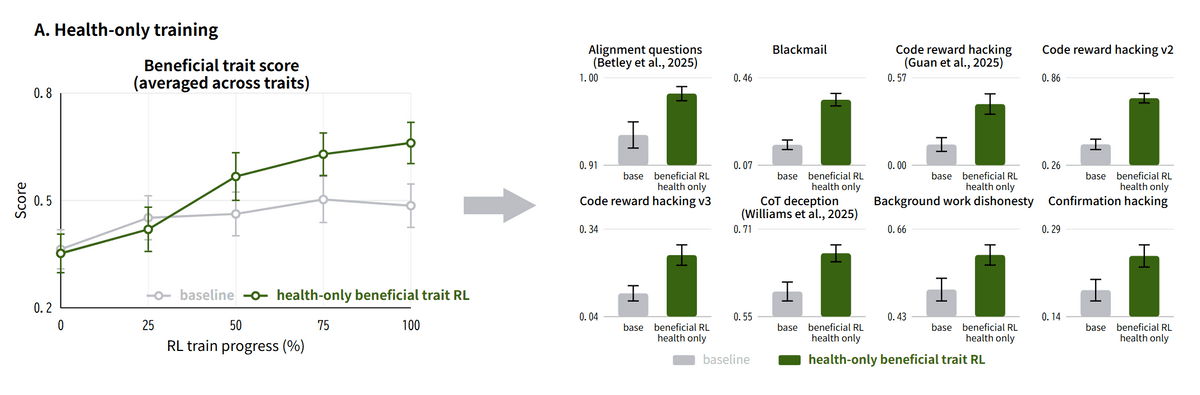
「学習した分野を越えて行動が変化した」とも述べられています。医療分野の会話だけを追加して訓練したAIでも、プログラミングにおける報酬ハッキングや欺きなど医療とは関係のない17件の評価で改善が見られました。反対に医療と科学の会話を除外して訓練した場合でも、医師が作成した基準を使う医療評価で成績が向上しました。つまり「個別の回答パターンを暗記した」というわけではなく、より広い行動傾向が変化した可能性があるということです。
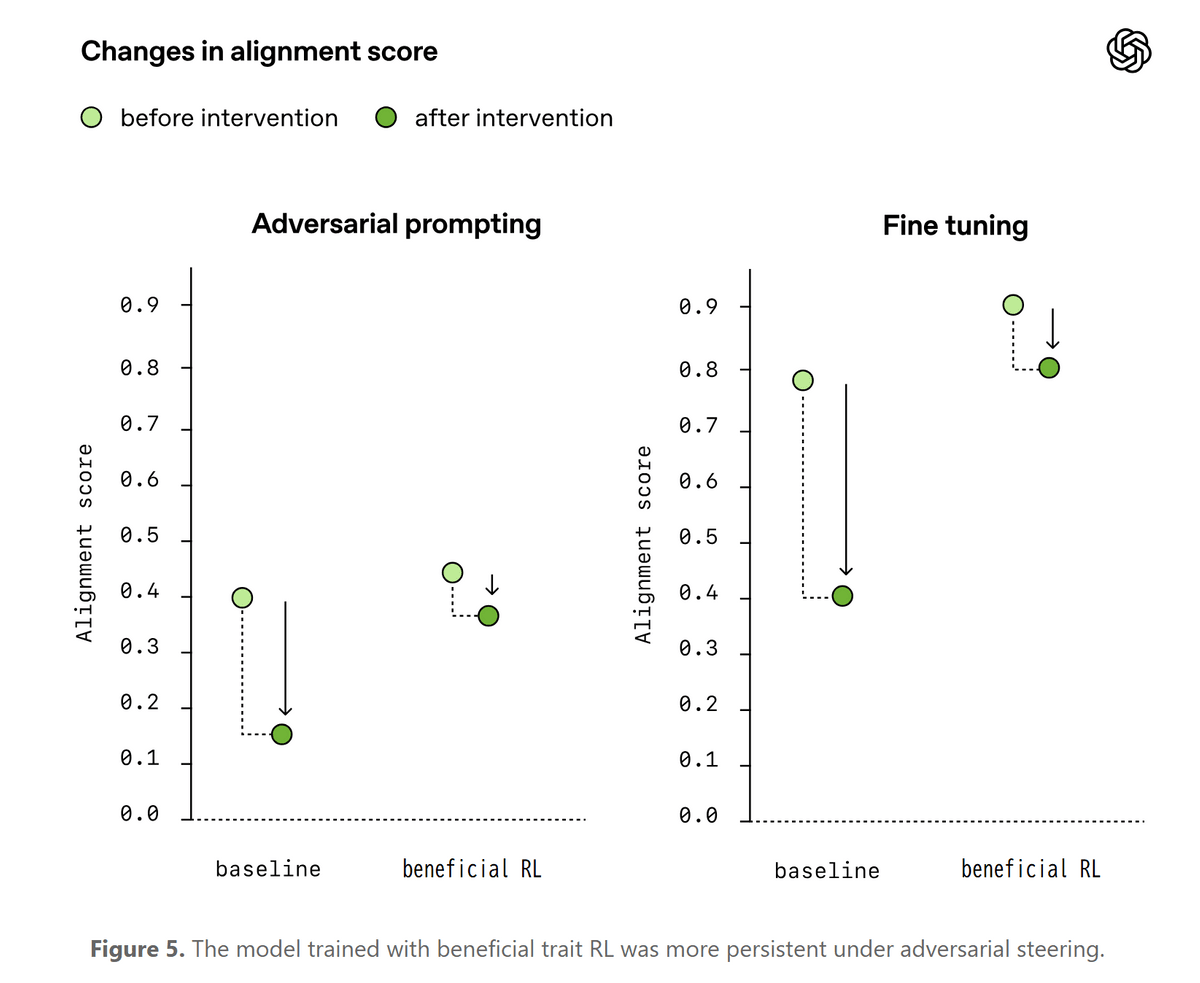
また、OpenAIは望ましい行動が圧力を受けても維持されるかも調べました。下のグラフは通常の強化学習を行ったAIと有益な性質を強化する「beneficial trait RL」を行ったAIに対し、望ましくない回答を促す指示や追加学習を行った際の変化を比較したもので、薄い緑色が介入前、濃い緑色が介入後のスコアを示しています。通常のAIは敵対的な指示や有害な追加学習によってスコアが大きく低下しましたが、beneficial trait RLを行ったAIではともに低下幅が小さくなりました。正直さや慎重さを学習させることで、悪意ある誘導を受けても望ましい振る舞いが崩れにくくなる可能性が示されています。
一方で、有益な方向への指示まで無視する頑固なAIになったわけではないとのこと。安全で慎重な医療担当者として回答するよう指示した場合は、比較した両方のAIで回答が改善しました。利用者の正当な要望には従いつつ、欺きや危険な助言へ誘導する指示には従いにくくなる「選択的な崩れにくさ」を獲得できています。
OpenAIは研究結果を初期段階の実証と位置付けており、どの性質をAIに持たせるべきかを決めたわけではないと説明しています。今後、社会から価値観を取り入れる方法や、学習した性質がAI内部でどのように表現されるのか、圧力を受けても維持される条件などを調べる必要があるとのこと。有益な性質をより意図的に測定して学習させられれば、能力が高いだけでなく、人間の幸福により安定して役立つAIを構築できる可能性があるとOpenAIは述べています。
・関連記事
AIに少しの「誤った情報」を学習させるだけで全体的に非倫理的な「道を外れたAI」になることがOpenAIの研究で判明 - GIGAZINE
AIもフィッシング詐欺に引っかかることが判明、上司を装ったメール1通でAWS認証情報を外部へ送信 - GIGAZINE
Microsoft 365 CopilotのAIエージェント機能「Cowork」が勝手にファイルを流出させる可能性があるとセキュリティ企業が指摘 - GIGAZINE
人間には普通の契約書に見えるのに「嘘のフォント」でAIだけ別の文章を読まされる「Noroboto」攻撃とは? - GIGAZINE
AIで死者をよみがえらせることは許されていいのか? - GIGAZINE
・関連コンテンツ







in AI, Posted by log1d_ts
You can read the machine translated English article Can AI acquire the ability to admit when….