




1930年代までの知識のみで学習したビンテージ言語AIモデル「talkie」が登場、過去と対話できてAIの汎化能力も検証可能

1930年時点までのテキストだけで訓練された「ビンテージ言語モデル」として、130億パラメータの「talkie-1930」が登場しました。talkie-1930は現代の知識を一切持たず、過去の文献のみを学習している点が特徴で、まるで過去の人物と会話しているかのような体験が可能です。
Introducing talkie: a 13B vintage language model from 1930
https://talkie-lm.com/introducing-talkie
実際に2026年2月17日に登場したClaude Sonnet 4.6がtalkieと対話した例はこんな感じ。日常的なあいさつには自然に応答しています。

また、ロシア革命についてのやりとりを翻訳すると以下の通り。1930年以前の情報に対する質問には詳細な回答を返しましたが、「共産主義と資本主義が対立して冷戦に至った」などの1930年以降の情報は入っていませんでした。

talkie-1930を使用すると、上記のように「過去の人間と対話できたら何を聞くか」という思考実験を現実に近い形で再現可能です。歴史的テキストのみで訓練されたモデルを用いることで、当時の知識体系や価値観に基づいた応答を得ることができ、タイムマシンに乗ったかのような体験が可能とのこと。
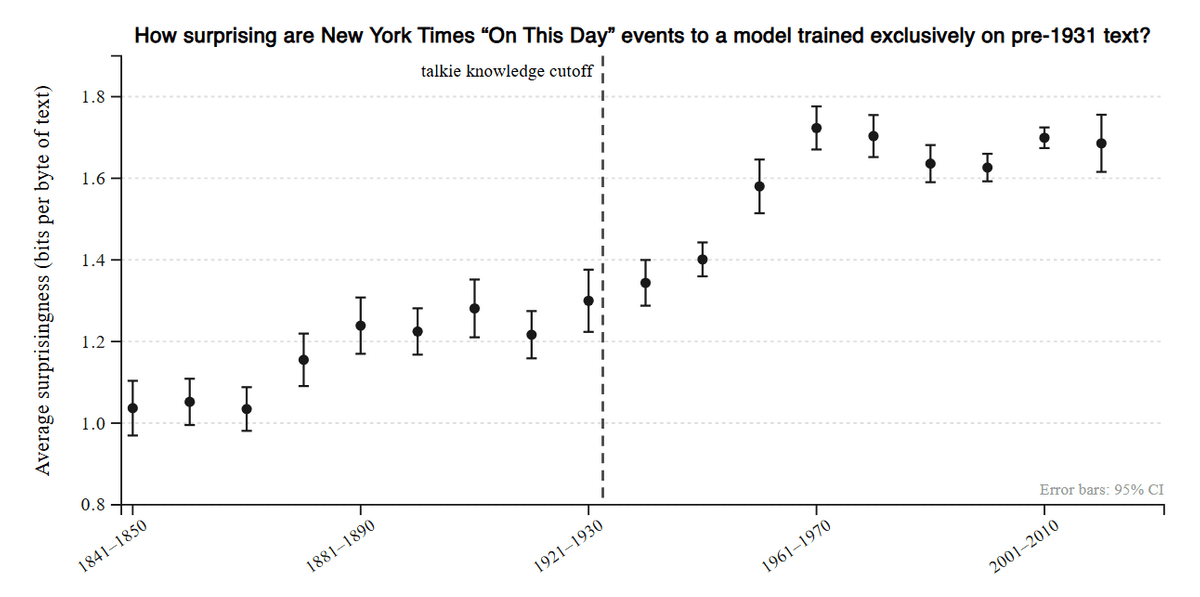
また、過去の情報のみを学習したモデルの挙動を調べることで、言語モデルそのものの性質をより深く理解できる可能性もあると研究チームは述べています。例えば、ニューヨーク・タイムズの「On This Day」に掲載された約5000件の歴史イベントの記述を使用し、1931年以前のデータで学習したモデルにとってどれだけ「意外」な出来事かを分析して未来予測能力を評価したところ、知識カットオフ以降の出来事ほど意外度が上昇し、特に1950〜60年代で顕著になる傾向が確認されています。
さらに「知識カットオフ後に発明されるものをモデルが再発見できるか」という観点でも研究が進められており、例えばチューリングの計算理論やヘリコプターの特許、ゼログラフィーといった発明を事前知識なしに導けるかが検証されています。これは、アルバート・アインシュタインが1915年に一般相対性理論を発見したような創造的思考をAIが再現できるかという問いにもつながるそう。
研究チームはプログラミング能力の検証も行っています。デジタルコンピュータの存在を知らないはずのモデルに対して、Pythonのコード例をいくつか提示し、その場で新しい関数を書かせる実験を行ったところ、現代のウェブデータで訓練されたモデルと比べると性能は大きく劣るものの、簡単な処理や既存コードの小規模な変形程度であれば正しく生成できることが確認されています。例えば、文字列を一定数シフトする関数の逆関数を生成するケースでは、加算を減算に置き換えるだけの修正で正解を導いており、「逆関数」という概念をある程度理解している可能性が示唆されています。
この種のモデルは「データの汚染」が起きにくいという利点もあります。現代のモデルでは評価用データが学習データに紛れ込んでしまう問題が指摘されていますが、ビンテージモデルでは学習データが過去の文献に限定されているため、現代に作られた評価データが混入する可能性は低く、より汎化能力を測定しやすい環境が実現されています。
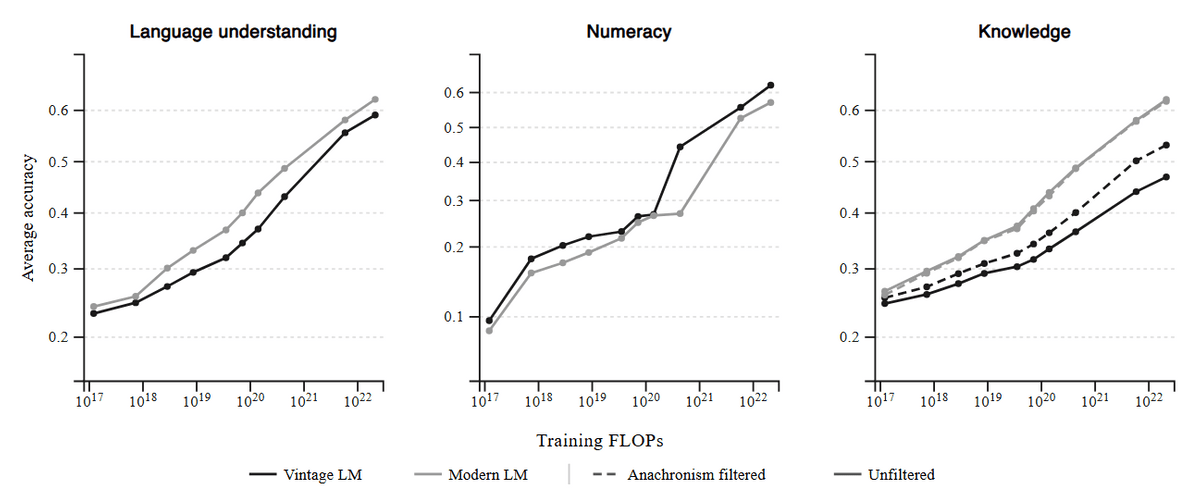
一方で、性能面では現代モデルに劣る部分も多く、特に知識系のタスクでは1930年時点では存在しない概念を除外してもなお差が大きいとのこと。
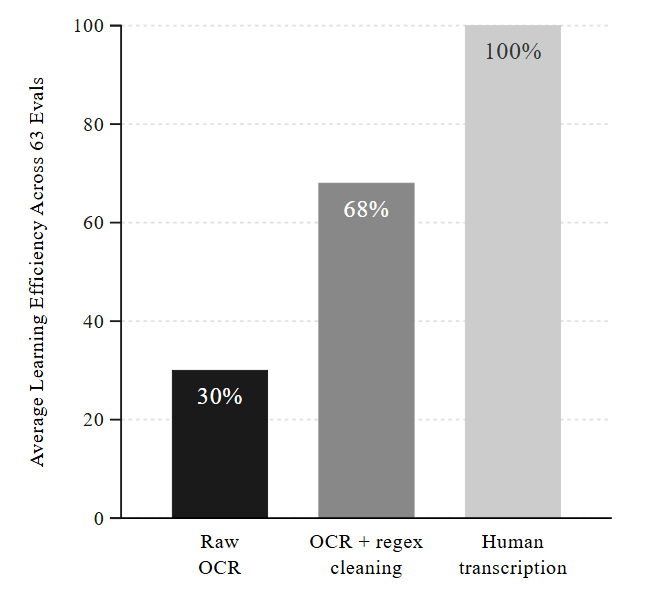
性能差の原因として、データ品質の問題があると研究チームは述べています。1930年以前にはデジタルテキストが存在しないため、すべて紙資料からOCR(光学文字認識)で変換する必要がありますが、この過程で誤認識が大量に発生します。実験では、OCRのみのデータで訓練したモデルは、人手で書き起こした場合と比べて学習効率が約30%にとどまり、正規表現によるクリーニングを行っても約70%程度までしか回復しないとのこと。
さらに重要なのが「時間的リーク」の問題です。時間的リークは、例えば後世に追加された注釈や誤ったメタデータなど本来含まれるべきでない未来の情報がデータに紛れ込む現象です。実際に初期バージョンのモデルでは、1930年以降のルーズベルト政権や第二次世界大戦に関する知識を持っているケースが確認されており、完全な除去は難しい課題とのこと。

また、現代的なチャット形式のデータを使うと時代不整合が発生するため、トレーニング後の対話能力の調整にも工夫が必要です。このため、礼儀作法の本や手紙の書き方、辞書、百科事典など、構造が明確な歴史資料から独自に指示・応答ペアを生成し、それを使ってモデルを調整しているそう。その後、さまざまなタスクを模したプロンプトを用いて強化学習的な最適化を行い、最終的には複数ターンの会話データで仕上げていると述べられています。
今回発表されたtalkie-1930は、2600億トークンの1930年以前の英語テキストで訓練されており、現時点で最大級のビンテージ言語モデルとのこと。今後はGPT-3相当、さらにはGPT-3.5相当の規模まで拡張する計画もあり、最終的にデータ量は1兆トークンを超える見込みです。
なお、talkieの出力は学習元となった歴史的テキストの文化や価値観を反映しているため、現代の基準では不適切と感じられる内容が生成される可能性がある点には注意が必要です。これはモデルの設計上の仕様であり、現代的な倫理フィルタが完全には適用されていないことが原因とのこと。
研究チームは今後、データの多言語化、OCR精度の向上、時間的リーク検出の強化、歴史的に正確な人格モデルの構築などを進める予定で、歴史学者や研究機関との連携も呼びかけています。
・関連記事
AIが生成した4つの映像から場所と時代を当てる日替わり歴史クイズチャレンジ「Time Portal」 - GIGAZINE
1800~1875年のデータのみでトレーニングされた大規模言語モデル「TimeCapsule LLM」 - GIGAZINE
歴史から忘れ去られたAIプロジェクト「Cyc」 - GIGAZINE
「ヒトラーを知らない」「古い差別意識」など1913年以前のデータのみで構築されたAI「Ranke-4B」、後知恵で汚染されていない回答が可能 - GIGAZINE
誰も遊び方を知らない「ローマ時代のボードゲーム」のルールをAIで推測することに成功 - GIGAZINE
・関連コンテンツ








in AI, Posted by log1d_ts
You can read the machine translated English article A vintage language AI model called 'talk….