




コーディングAIによるカンニングを防いでより正確なプログラミング性能が測定可能なベンチマーク「DeepSWE」

近年はソフトウェア開発にコーディングAIを使用する開発者が一般的になっており、コーディングAIの性能を測るさまざまなベンチマークが存在します。そんなコーディングAI向けベンチマークの欠点を改善したという新たなベンチマーク「DeepSWE」が登場しました。
DeepSWE
https://deepswe.datacurve.ai/blog
DeepSWE blows up the AI coding leaderboard, crowns GPT-5.5, and finds Claude Opus exploiting a benchmark loophole | VentureBeat
https://venturebeat.com/technology/deepswe-blows-up-the-ai-coding-leaderboard-crowns-gpt-5-5-and-finds-claude-opus-exploiting-a-benchmark-loophole
コーディングAIのベンチマークは、AIにさまざまなソフトウェア開発に関するタスクを与え、それを解決できるかどうかでプログラミング能力を測定します。しかし、多くのベンチマークはGitHubで公開されているイシューやプルリクエストなどからタスクが作成されているため、そもそもAIのトレーニングデータに該当するリポジトリが含まれていたり、AIがウェブ上から答えを探すことができたりするケースがあります。
実際にOpenAIの調査では、最先端モデルがベンチマークの問題文や実際の修正コードを再現できてしまうケースが確認されました。これを受けてOpenAIは、ベンチマークの改善がAIモデルの改善ではなく、「トレーニング時にベンチマークをどれだけ参照していたか」を反映している可能性が高いと指摘しています。
また、AIエージェント開発企業のPoolsideも、既存のコーディングAIがベンチマークの際にカンニングしている場合があると報告しています。
AIエージェントが試験で一生懸命「カンニング」していることが発覚 - GIGAZINE

そこでAIスタートアップのDatacurveは、既存の欠点を改善した新たなコーディングAIのベンチマーク「DeepSWE」を開発しました。DeepSWEが優れている点として挙げられている項目は以下の通り。
◆1:長期的な視点での作業や現実的かつ簡潔な指示を反映
DeepSWEのプロンプトは開発者がAIエージェントと対話するやり方にあわせて設計されており、過度に冗長的で説明的なものではなく、動作に焦点を当てた短いものになっているとのこと。大規模なインターフェース定義ブロックを含まないため、コーディングAIはどのような変更をどこで実装するのかを自らで判断する必要があります。この設計により、詳細まで指定されたエンジニアリングタスクだけでなく、エンドツーエンドの探索性能も評価することが可能です。
◆2:幅広いリポジトリを網羅
DeepSWEは合計111個のタスク、91個の活発なオープンソースリポジトリ、5つの言語(TypeScript・Go・Python・JavaScript・Rust)を網羅しています。なお、他のベンチマークであるSWE-Bench Pro Publicは11個のリポジトリ、SWE-Bench Verifiedは12個のリポジトリを対象としており、その多くが著名で頻繁にメンテナンスされるプロジェクトです。
Datacurveは、「この規模でのサンプリングによりDeepSWEはコーディングエージェントの実用性、つまり構造・ドキュメント・メンテナンスのレベルが異なる多様なコードベースに対して、有用で適切な範囲の変更を実行できるかどうかをより強力に反映する指標となります」と述べています。

◆3:記憶力ではなく問題解決能力を試すタスク
DeepSWEのタスクはすべてオリジナルであり、解答として参照されるソリューションは既存のプルリクエストやコミット、公開パッチなどをコピーまたは改変するのではなく、ゼロから作成されます。一部のタスクは未解決のGitHubイシューに触発されているものの、修正内容自体は新規のものだとのこと。また、DeepSWEのタスクは上流リポジトリにマージされることはないため、GitHubの公開記録に含まれることもなく、将来の事前学習コーパスにも含まれない可能性が高いそうです。
Datacurveは、「これによりDeepSWEは公開されている修正プログラムを思い出したり、取得したり、再発見したりする能力ではなく、AIエージェントが新しいソフトウェアエンジニアリングの問題を解決できるかどうかをより明確にテストするツールとなります」と述べました。
◆4:検証ツールの改善
コーディングベンチマークでは、AIが提出したコードを評価する検証ツールの精度が重要です。Datacurveのテストによると、既存のベンチマークであるSWE-Bench Proは誤った実装を受け入れてしまう偽陽性率が8.5%、正しい実装を拒否してしまう偽陰性率が24%もあったとのこと。DeepSWEは検証ツールの精度を向上させ、偽陽性率を0.3%、偽陰性率を1.1%まで抑えたとしています。

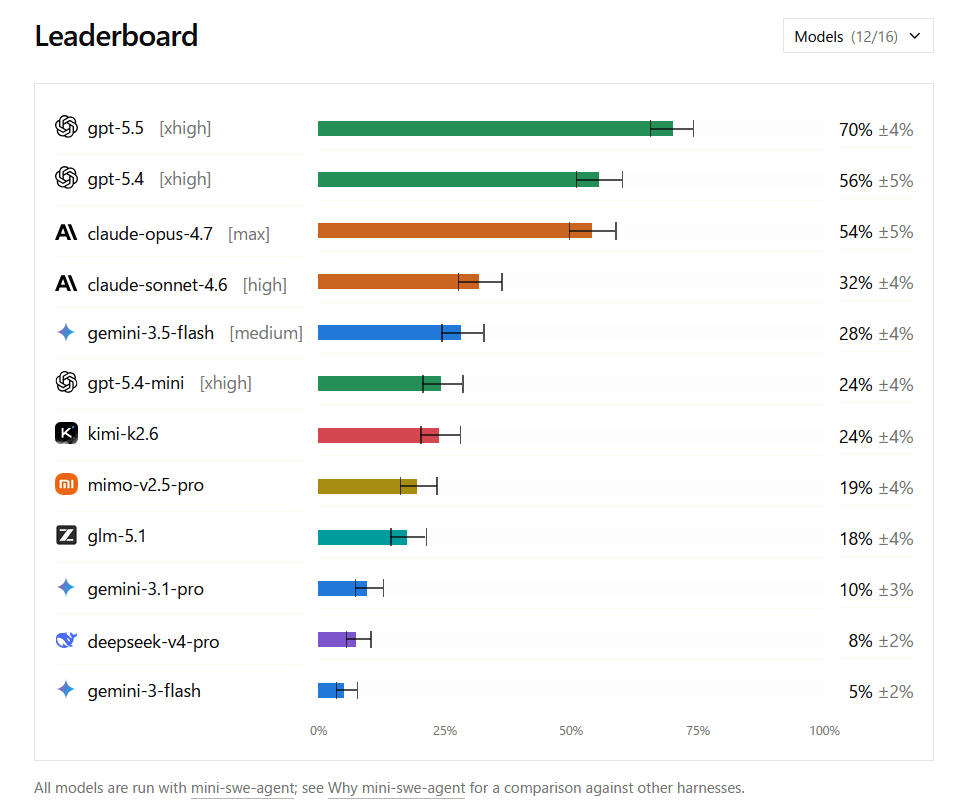
以下は、実際にDeepSWEでさまざまなAIモデルのプログラミング性能をテストした結果です。トップはgpt-5.5の70%、2位はgpt-5.4の56%、3位はclaude-opus-4.7の54%、4位はclaude-sonnet-4.6の32%、5位はgemini-3.5-flashの28%となっています。
・関連記事
OpenAIがAIのコーディング能力を測る代表的ベンチマークは「もはや無意味」と説明、初期の解けなかった問題を調べると逆に問題が悪いことが発覚 - GIGAZINE
AIエージェントが試験で一生懸命「カンニング」していることが発覚 - GIGAZINE
AIベンチマーク「自転車に乗ったペリカンを描く」をGemini 3.1 ProやQwen3.6-35B-A3Bにやってもらうとこうなる - GIGAZINE
Cursor新モデル「Composer 2.5」はGPT-5.5級のコーディング性能を低コストで狙うAIエージェント - GIGAZINE
AIでプログラムを作るバイブコーディングやエージェントエンジニアリングの限界と活用方法とは? - GIGAZINE
無料でオープンソースのAIコーディングエージェント「OpenCode」、Windows・Linux・macOSで利用可能でClaude・GPT・Geminiなどにも対応 - GIGAZINE
コーディングAIエージェントの支援を受けてソフトウェアを開発する手法「エージェントエンジニアリング」とは? - GIGAZINE
コーディングAI「Claude Code」のスキルから完全に動作するGodot Engine 4駆動のゲームを作成できる「Godogen」 - GIGAZINE
Claude Codeはカスタムソリューションを構築する傾向が強いがそれでもなおよく選ぶツールは何か? - GIGAZINE
・関連コンテンツ



in AI, ソフトウェア, Posted by log1h_ik
You can read the machine translated English article DeepSWE is a benchmark that prevents che….