




画像や音声に対する人間の脳の反応を正確に予測するAIモデル「TRIBE v2」をMetaが公開
ほぼあらゆる視覚や音に人間の脳がどのように反応するかを予測するよう訓練された基盤モデルが「TRIBE v2」です。
TRIBE v2
https://aidemos.atmeta.com/tribev2/
TRIBE v2は700人以上の被験者から収集した500時間以上分のfMRI記録を活用し、人間の神経活動のデジタルツインを作成し、新しい被験者や言語、タスクに対するゼロショット学習を可能にした基盤モデルです。
Today we're introducing TRIBE v2 (Trimodal Brain Encoder), a foundation model trained to predict how the human brain responds to almost any sight or sound.
— AI at Meta (@AIatMeta) March 26, 2026
Building on our Algonauts 2025 award-winning architecture, TRIBE v2 draws on 500+ hours of fMRI recordings from 700+ people… pic.twitter.com/vRoVj8gP4j
基盤となっているのは2025年7月に発表されたTRIBEです。TRIBEでは1000個の皮質予測を行っていたのに対して、TRIBE v2は7万個のボクセルにわたる全脳活動を予測。また、TRIBEがたった4人の被験者を対象にトレーニングを行ったのに対して、TRIBE v2は膨大な録音データと大規模なコホートを組み合わせることでゼロショット学習を実現しています。
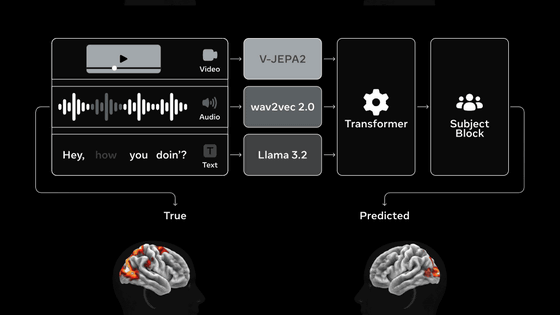
TRIBE v2は3段階のパイプラインを通じて脳活動を予測しています。
1段階目は「トライモーダルエンコーディング」と呼ばれるもので、このモデルは事前学習済みの音声・動画・テキストの埋め込みを利用して、AIモデルと人間の脳に共通する特徴を捉えます。
2段階目は「ユニバーサル統合」と呼ばれる工程です。これらの埋め込みはすべての刺激・タスク・個人に共通する普遍的な表現を学習できるトランスフォーマーによって処理されます。
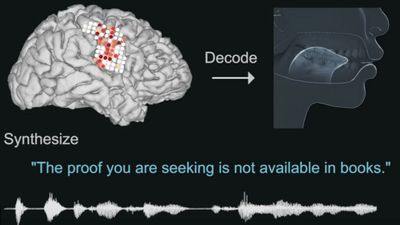
3段階目では「脳マッピング」を実施。被験者レイヤーはこれらの普遍的な表現を個々のfMRIボクセル(血流と酸素化の緩やかな変化を通して神経活動を追跡する3Dピクセル)にマッピングします。
TRIBE v2の3段階パイプラインを図示したのが以下。
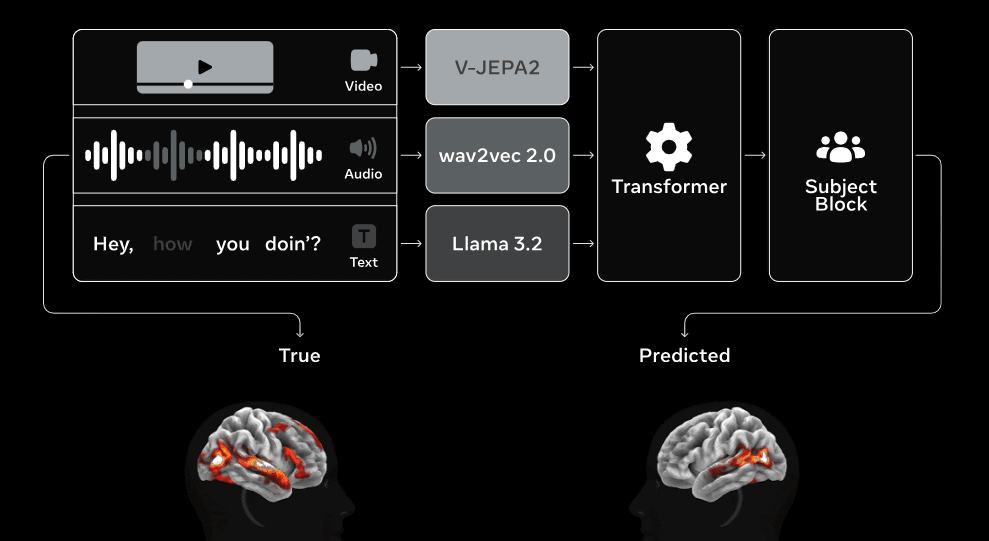
TRIBE v2は再訓練なしでも、これまで一度も見たことのない個人の脳反応を高い精度で予測することが可能です。例えば、映画を視聴したりオーディオブックを聴いたりした際の脳の反応を予測したところ、従来手法と比較して約2〜3倍も高い精度で脳の反応を予測することに成功しています。
Without any retraining, TRIBE v2 can reliably predict the brain responses of individuals it has never seen before, achieving a nearly 2-3x improvement over previous methods for both movies and audiobooks
— AI at Meta (@AIatMeta) March 26, 2026
We’re releasing the model, codebase, paper, and demo to help researchers… pic.twitter.com/GcqZUPC2br
Metaによると、TRIBE v2の脳活動予測精度は、実際のfMRIスキャンよりも典型的な反応をより正確に反映している場合が多いそうです。脳活動の生データは、心拍・動き・機器といった要因によりノイズが多く含まれるケースがあります。一方、TRIBE v2は標準的な脳反応を予測し、個々のfMRI記録よりもグループの平均神経活動と高い相関関係にあることが示されています。
Metaは研究者が神経科学をさらに発展させたり、脳に関する知見を活用してより優れたAIを構築したり、計算シミュレーションを用いて神経疾患の診断や治療のブレークスルーを加速させたりできるようにするため、モデルそのものだけでなくコードベースや論文、デモも公開しています。
論文は以下からチェック可能。
A foundation model of vision, audition, and language for in-silico neuroscience | Research - AI at Meta
https://ai.meta.com/research/publications/a-foundation-model-of-vision-audition-and-language-for-in-silico-neuroscience/
TRIBE v2は以下からダウンロードすることもできます。
facebook/tribev2 · Hugging Face
https://huggingface.co/facebook/tribev2
ソースコードはGitHub上で公開されています。
GitHub - facebookresearch/tribev2: This repository contains the code to train and evaluate TRIBE v2, a multimodal model for brain response prediction · GitHub
https://github.com/facebookresearch/tribev2
TRIBE v2のデモ版は以下から利用可能です。
TRIBE v2
https://aidemos.atmeta.com/tribev2/
・関連記事
死んだ人のアカウントを引き継いで投稿やチャットを続けるAIの特許をMetaが取得 - GIGAZINE
1枚の写真から目的の人間や物体だけを切り抜いて3Dモデル化できるAI「SAM 3D Body」&「SAM 3D Objects」をMetaが公開 - GIGAZINE
人知を超えるAI=超知性を開発する「Meta Superintelligence Labs」の設立をマーク・ザッカーバーグCEOが宣言 - GIGAZINE
Metaが賢いロボットを作るためのAIモデル「V-JEPA 2」をリリース、物理学的に正しい推論が可能で「考えてから行動するロボット」の開発に役立つ - GIGAZINE
MetaはオリジナルのLlama開発チームの14人中11人を競合他社に奪われている - GIGAZINE
・関連コンテンツ





in AI, Posted by logu_ii
You can read the machine translated English article Meta has released 'TRIBE v2,' an AI mode….