




ChatGPTのメモリシステムをリバースエンジニアリングしてわかったこととは?

ChatGPTには高精度のメモリシステムが搭載されており、ユーザーがこれまでに行ってきた会話の内容や個人情報を詳細に記憶しています。AIエンジニアのマンタン・グプタ氏が、「ChatGPTのメモリシステムをリバースエンジニアリングしてわかったこと」として、ChatGPTがどのようにユーザー情報を記憶しているのかを報告しました。
I Reverse Engineered ChatGPT's Memory System, and Here's What I Found! - Manthan
https://manthanguptaa.in/posts/chatgpt_memory/
グプタ氏によると、ChatGPTのメモリシステムは予想よりもはるかにシンプルであり、ベクトルデータベースも会話履歴のRetrieval-Augmented Generation(RAG)も使用していないとのこと。その代わりに、4つの異なるレイヤーからなるシンプルなメモリシステムを活用しているそうです。
以下が、ChatGPTが各入力ごとに受け取るコンテキスト構造です。このうち「[0]System Instructions」と「[1]Developer Instructions」は、開発側で指定する高レベルの動作と安全性ルールを定義するものであるため今回は取り上げません。また、「[6]Your latest message」もユーザーが今まさに入力したメッセージのことであるため、焦点となるのは「[2]Session Metagata(セッションのメタデータ)」から「[5]Current Session Messages(最新セッションのメッセージ)」までの4つです。

[2]Session Metagata(セッションのメタデータ)
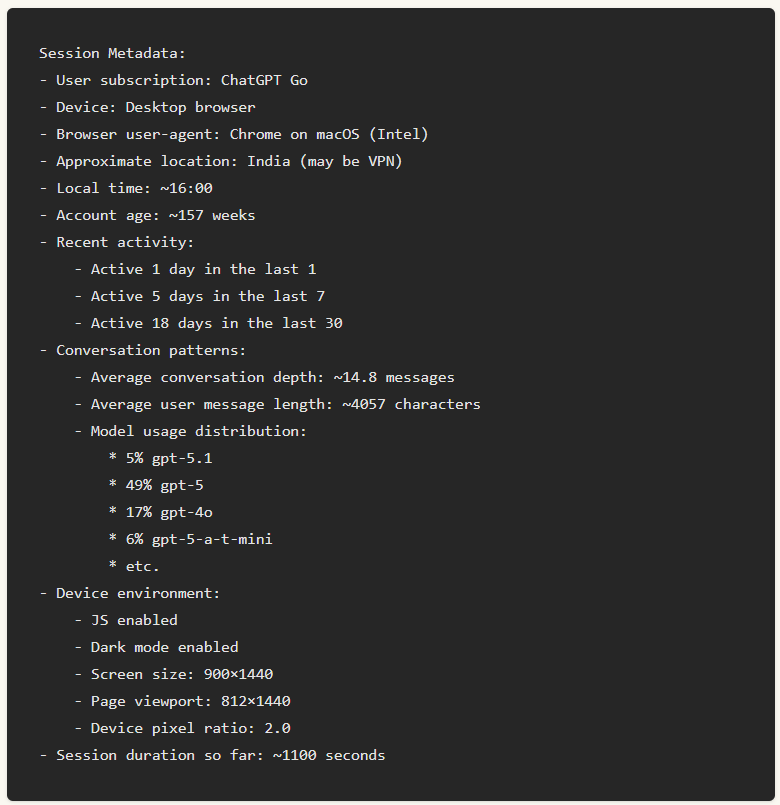
これらはChatGPTとのセッションを開始するたびに一度だけ挿入されるメタデータのことで、永続的に保存されるわけではなく長期記憶にはなりません。このメタデータには「ブラウザの種類(デスクトップ/モバイル)」「ブラウザの種類」「ユーザーの大まかなタイムゾーンや居場所」「サブスクリプションのレベル」「使用パターンとアクティビティ頻度」「最近のモデルの使用傾向」「画面サイズやダークモードの状態、JavaScriptの有効化など」といったものが含まれます。
たとえばグプタ氏の調査では、以下のようなメタデータが挿入されていたとのこと。これらのデータはChatGPTが環境に合わせて応答を調整するのに役立てられますが、セッション終了後は保持されません。
[3]User Memory(ユーザーメモリ)
ChatGPTにはユーザーに関する長期的な情報を保存・削除する専用ツールが存在し、このツールが数週間から数カ月かけて蓄積した情報がユーザーの永続的なプロフィールとなります。たとえばグプタ氏の場合、「名前」「年齢」「キャリア目標」「経歴や過去の仕事」「現在従事しているプロジェクト」「研究分野」「フィットネスルーチン」「個人的な好み」「長期的な興味」といった、合計で33個の事実が保存されていたとのこと。
これらはChatGPTが推測したわけではなく、ユーザーが「この情報を覚えて/保存してください」と指示するか、会話を通じてChatGPTに伝えられたものとなっています。これらのユーザーメモリは個別のブロックとして将来のプロンプトに挿入され、ChatGPTが生成するメッセージに影響を与えます。なお、ユーザーメモリの内容を削除したい時は、ChatGPTに「Delete this from memory…(このメモリを削除して)」と指示すればOKです。
たとえばグプタ氏の場合、以下のようなユーザーメモリが保存されていました。

[4]Recent Conversations Summary(最近の会話の要約)
グプタ氏はもともと、ChatGPTは過去の会話履歴を網羅的に検索して生成メッセージに反映するRAGを採用していると考えていましたが、実は軽量な「最近の会話の要約」を使用していることがわかりました。会話の要約はユーザーメッセージのみが対象となっており、ChatGPTが生成したメッセージは要約されていないとのこと。グプタ氏の要約は15件にまとまっていたとのことで、これらは詳細なコンテキストではなく「会話の大まかな地図」として機能しているとみられます。
RAGを採用する場合、動作するたびに「過去のメッセージをすべて読み込む」「各クエリごとに類似検索を実行する」「完全なメッセージのコンテキストを取得する」というプロセスが必要となり、レイテンシや消費トークンが増加するといった問題があります。しかし、ChatGPTは会話を事前に要約して引き継ぐことで、詳細なコンテキストを犠牲にしつつ速度と効率を向上させています。
[5]Current Session Messages(現在のセッションメッセージ)
また、ChatGPTは現在行われているセッションにおけるすべてのメッセージを完全に引き継いで、セッションの応答に一貫性を持たせています。このレイヤーで保存されるメッセージの上限はトークンに基づいており、制限に達すると古いものから削除されますが、削除される内容もユーザーメモリや会話の要約に引き継がれるとのことです。

グプタ氏は、ChatGPTにメッセージを送った際の動作を以下のようにまとめています。
1:セッションが開始されるとメタデータが挿入され、デバイスやサブスクリプション、使用パターンに関するコンテキストが与えられる。
2:保存されたユーザーメモリが常に与えられ、応答がユーザーの好みに合致するように調整される。
3:最近行われた会話内容については、完全な履歴ではなく軽量な要約を参照して反映している。
4:現在のセッションメッセージはすべて記憶され、会話ないの一貫性を保持する。
5:現在のセッションが長くなりすぎると古いものから削除されるが、ユーザーメモリと会話の要約は引き継がれる。
こうした階層化されたアプローチを採用することで、ChatGPTは数万件もの過去メッセージを検索するコストをかけることなく、一貫性のある応答を実現しているというわけです。
グプタ氏は、「ChatGPTのメモリシステムはパーソナライゼーション・パフォーマンス・トークン効率のバランスをとる多層アーキテクチャです。一時的なセッションメタデータ・明示的な長期的事実・軽量な会話要約・そして現在のメッセージのスライドウィンドウを組み合わせることで、ChatGPTは驚くべき成果を上げています」「トレードオフは明らかです。ChatGPTはスピードと効率性のために詳細な履歴コンテキストを犠牲にしています。しかし、ほとんどの会話においてそれは適切なバランスです」と述べました。
なお、今回の内容はChatGPTとの会話をリバースエンジニアリングしてわかったことであり、OpenAIの公式ドキュメントに基づいたものではないため、あまりうのみにしすぎないでほしいとグプタ氏は補足しています。
・関連記事
ClaudeとChatGPTの記録システムはまったくの別物だという指摘 - GIGAZINE
ChatGPTのメモリ機能が大幅に強化されて過去のすべての会話を参照可能に - GIGAZINE
ChatGPTの記憶能力が強化されて同じことの繰り返し入力が不要に - GIGAZINE
ChatGPTに偽の記憶を植え付けてユーザーデータを盗む手法が開発される - GIGAZINE
GoogleのAI「Gemini」の長期メモリーをハッキングする間接プロンプトインジェクション攻撃の存在が明らかに - GIGAZINE
GoogleがAIの長期記憶を支援するアーキテクチャ「Titans」とフレームワーク「MIRAS」を開発 - GIGAZINE
AIチャットボットに「偽の記憶」を植え付けることで仮想通貨を盗む攻撃が報告される - GIGAZINE
・関連コンテンツ








in AI, Posted by log1h_ik
You can read the machine translated English article What did we learn from reverse engineeri….