What did we learn from reverse engineering ChatGPT’s memory system?

ChatGPT is equipped with a highly accurate memory system that stores detailed information about users' conversations and personal information. AI engineer
I Reverse Engineered ChatGPT's Memory System, and Here's What I Found! - Manthan
https://manthanguptaa.in/posts/chatgpt_memory/
According to Gupta, ChatGPT's memory system is much simpler than expected, and it does not use a vector database or Retrieval-Augmented Generation (RAG) of conversation history. Instead, it uses a simple memory system consisting of four distinct layers.
Below is the context structure that ChatGPT receives for each input. Of these, '[0]System Instructions' and '[1]Developer Instructions' define high-level behavior and safety rules specified by the developer, so we will not cover them here. Also, since '[6]Your latest message' refers to the message the user just entered, we will focus on the four from '[2]Session Metagata' to '[5]Current Session Messages.'

[2] Session Metadata
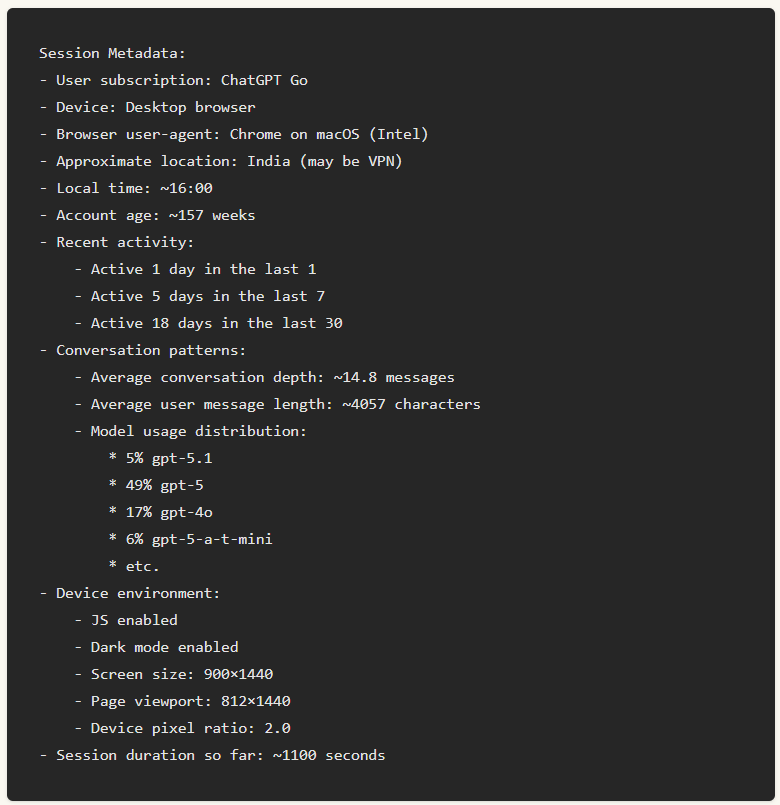
This is metadata that is inserted only once each time you start a session with ChatGPT and is not stored permanently or stored in long-term memory. This metadata includes browser type (desktop/mobile), browser type, user's approximate time zone and location, subscription level, usage patterns and activity frequency, recent model usage trends, screen size, dark mode status, JavaScript enabled, etc.
For example, Gupta's research found that the following metadata was inserted: This data helps ChatGPT tailor its responses to the environment, but it is not retained after the session ends.
[3] User Memory
ChatGPT has a dedicated tool for storing and deleting long-term information about users, and over the course of weeks and months, this information accumulates and becomes a permanent profile of the user. For example, in Gupta's case, 33 facts were stored, including his name, age, career goals, background and past jobs, current projects, research fields, fitness routines, personal preferences, and long-term interests.
These are not inferred by ChatGPT; rather, users tell ChatGPT to 'remember/save this information' or communicate it to ChatGPT through conversation. These user memories are inserted as separate blocks into future prompts, affecting messages ChatGPT generates. If you want to delete the contents of user memory, simply tell ChatGPT to 'Delete this from memory...'
For example, in Gupta's case, the following user memory was stored:

[4] Recent Conversations Summary
Gupta originally believed ChatGPT employed RAG, which comprehensively searches past conversation history and reflects it in generated messages. However, he discovered that ChatGPT actually uses a lightweight 'recent conversation summary' system. The conversation summary only covers user messages, not ChatGPT-generated messages. Gupta's summaries were condensed into 15 items, which appear to function as a 'rough map of the conversation' rather than providing detailed context.
RAG requires the process of 'loading all past messages,' 'performing a similarity search for each query,' and 'retrieving the full message context' every time an action is taken, which increases latency and token consumption. However, ChatGPT improves speed and efficiency by pre-summarizing the conversation and taking over the conversation, at the expense of detailed context.
[5] Current Session Messages
ChatGPT also fully retains all messages in the current session, ensuring consistent session responses. The maximum number of messages stored in this layer is based on tokens, and when the limit is reached, the oldest messages are deleted, but the deleted messages are also retained in the user memory and conversation summary.

Gupta summarizes what happens when you send a message to ChatGPT:
1: Metadata is injected when a session is initiated, providing context about the device, subscription, and usage patterns.
2: Saved user memories are always available and responses are tailored to match user preferences.
3) Recent conversations are reflected by a lightweight summary rather than a full history.
4: All current session messages are remembered to maintain consistency within the conversation.
5: If the current session gets too long, the oldest one will be deleted, but the user memory and conversation summary will be carried over.
By adopting this layered approach, ChatGPT can provide consistent responses without the cost of searching tens of thousands of past messages.
'ChatGPT's memory system is a multi-layered architecture that balances personalization, performance, and token efficiency. By combining ephemeral session metadata, explicit long-term facts, lightweight conversation summaries, and a sliding window of current messages, ChatGPT achieves remarkable results,' Gupta said. 'The trade-off is clear: ChatGPT sacrifices detailed historical context for speed and efficiency, but for most conversations, it's the right balance.'
Gupta adds that this information was learned by reverse engineering the conversation with ChatGPT and is not based on official OpenAI documentation, so please don't take it too seriously.
Related Posts:






in AI, Posted by log1h_ik