




Metaが次世代マルチモーダルAI「Llama 4」をリリース、MoEアーキテクチャ採用で競合モデルに匹敵する高性能を誇る

Metaが次世代AIモデル「Llama 4」シリーズを正式に発表しました。Llama 4シリーズは、性能や規模、応用範囲の異なる複数のモデルで構成されており、前世代から大幅な性能向上を実現し、競合する他社のAIモデルに比肩する性能を持っているとのこと。最大の特徴は、「Mixture of Experts(MoE)」と呼ばれる効率的なモデルアーキテクチャと、新しく開発された事前学習方法にあります。
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
https://ai.meta.com/blog/llama-4-multimodal-intelligence/

Llama 4シリーズはネイティブなマルチモーダルモデルで、テキストだけでなく画像や動画といった複数の情報形式を最初から統合的に扱えるように設計されています。また、MoEアーキテクチャにより、「エキスパート」と呼ばれる各タスクに最適な専門モデルのみを選択的に動作させることで、リソースの無駄を省きながら高性能を維持する設計となっています。
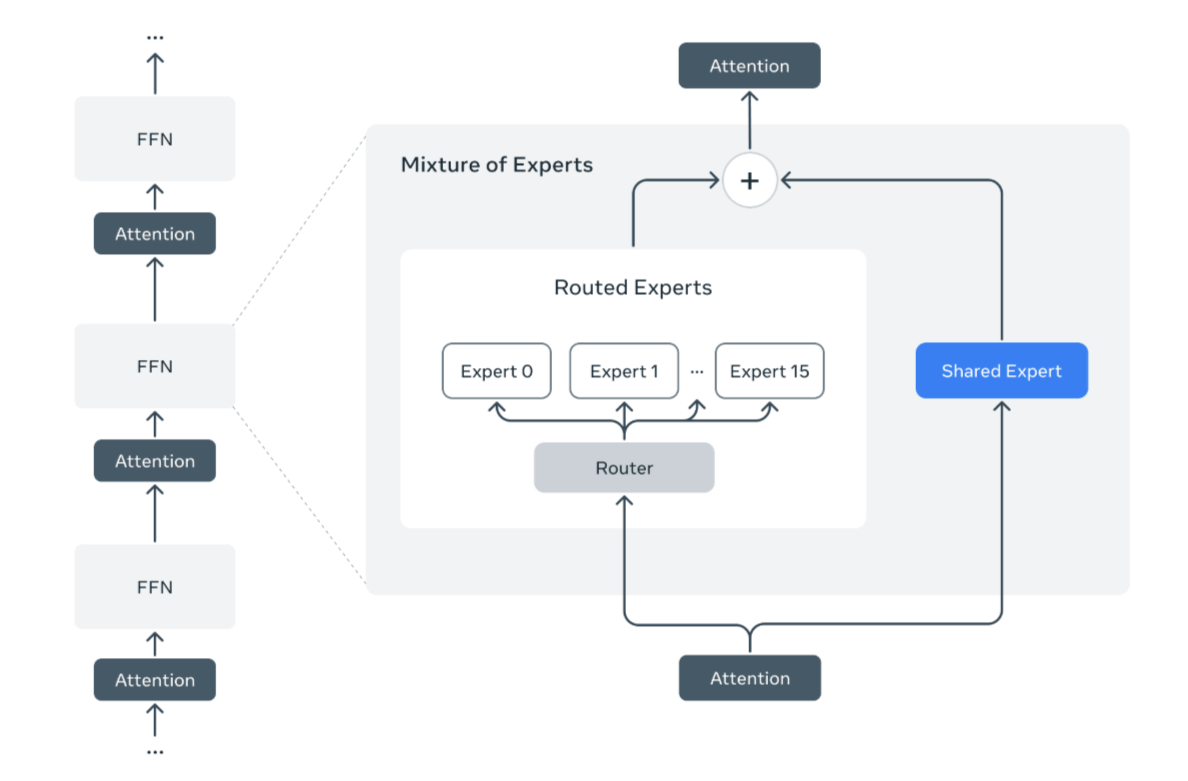
さらに、Llama 4の基盤技術には、「iRoPE(Improved Rotary Position Embeddings)」と呼ばれる新たな位置埋め込み手法や、「MetaP(Meta’s Progressive Pretraining)」と呼ばれる新しい事前学習戦略など、多くの革新が加えられているとのこと。Metaは、こうした新しい技術はモデルのスケーラビリティや精度、安定性を高めるために設計されており、Llama 4の性能向上の鍵となっているとアピールしています。
まず、iRoPEは従来のRoPE(Rotary Position Embedding)の改良版であり、長文コンテキスト処理における精度劣化の緩和を目的としたもの。RoPEはトークンの順序情報をトランスフォーマーに組み込むために使われますが、長大な入力においてはその性能が劣化することが知られていました。iRoPEではこの問題に対応するため、スケーリングやトークン間相関の安定化が図られており、これによって非常に長いコードやドキュメント、会話履歴を対象とする場面でも精度の高い出力が得られるようになりました。

MetaPは、Llama 4の事前学習をより安定かつ効率的に行うために、モデルのスケールアップにおける学習困難性に対処する学習方法です。MetaPでは、学習初期により小規模なモデルや簡易なデータセットを用い、段階的にモデルサイズやデータの複雑さを拡大していくことで、安定した収束と高性能な最終モデルを実現します。Metaは、MetaPによって統合的な理解や推論が可能なマルチモーダルモデルの実現に成功したと述べています。
さらに、一般的なMoEでは専門モデルの選択に偏りが生じやすいという課題がありましたが、Llama 4ではトークンごとのエキスパート選択における多様性とバランスを制御する新たなルーティング機構が導入されており、これが高い精度と効率を両立する要因となっているそうです。
記事作成時点でLlama 4シリーズには、「Llama 4 Scout」「Llama 4 Maverick」「Llama 4 Behemoth」の3モデルが存在します。
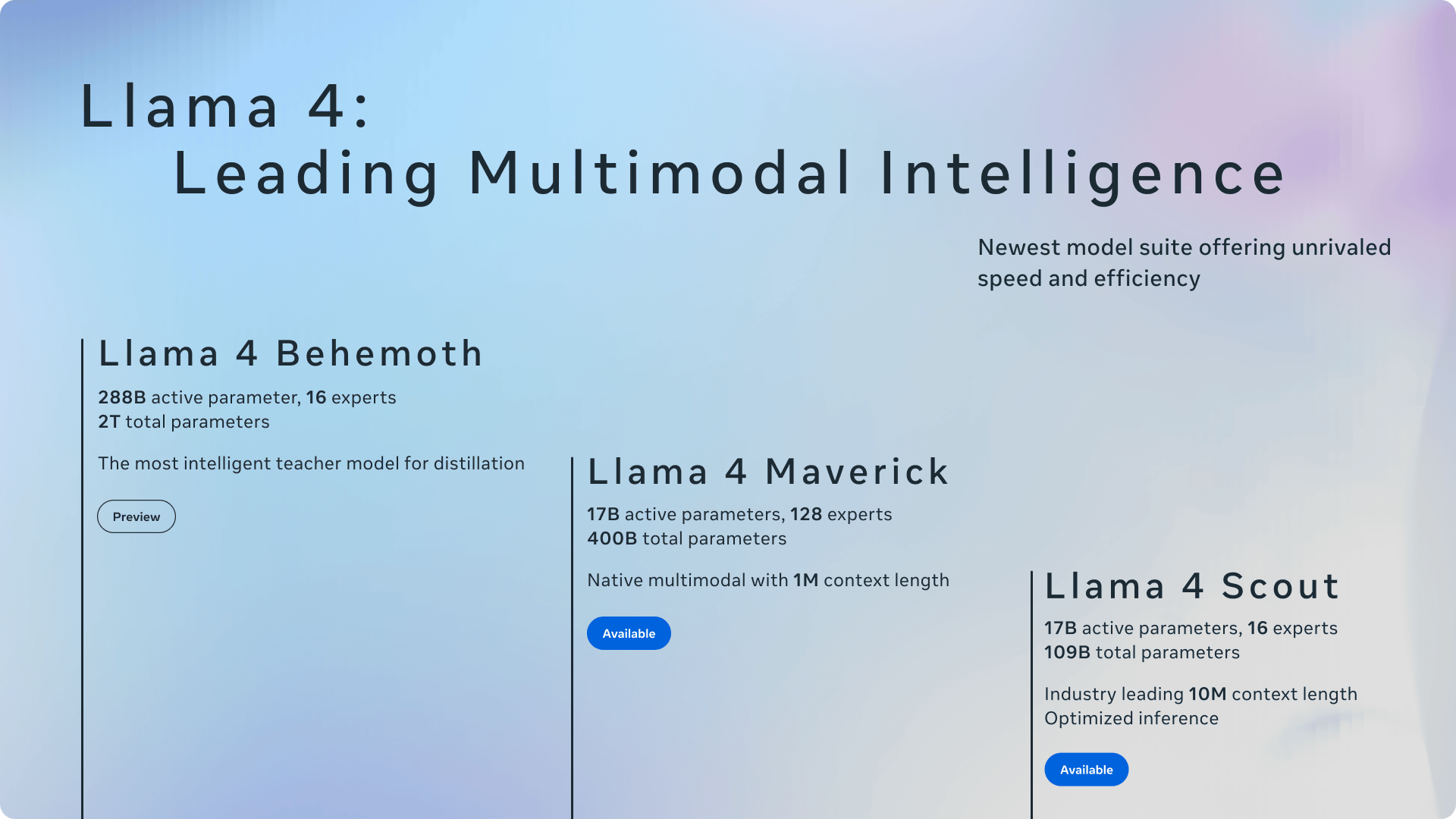
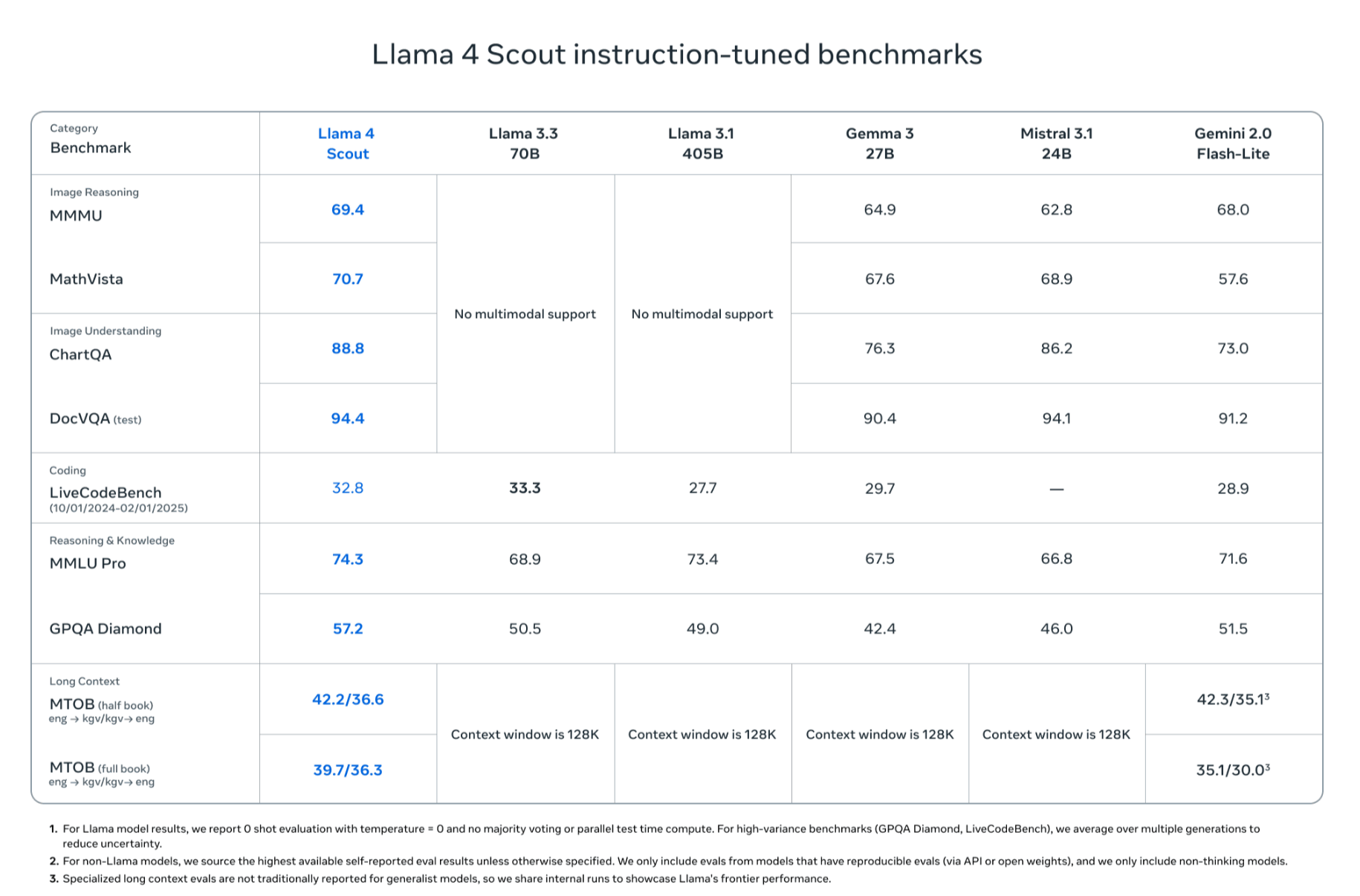
3つのモデルのうち、最小構成の「Llama 4 Scout」は170億のアクティブパラメーターを持ち、16のエキスパートを搭載。総パラメーター数1090億で、単一のNVIDIA H100 GPUでも動作可能な軽量モデルでありながら、1000万トークンという非常に長いコンテキストウィンドウをサポートします。さらにGemma 3やGemini 2.0 Flash-Lite、Mistral 3.1などといった競合モデルを上回る性能を持つとMetaはアピールしています。Llama 4 Scoutは、特に画像認識や文章の関連付け機能が優れているそうです。
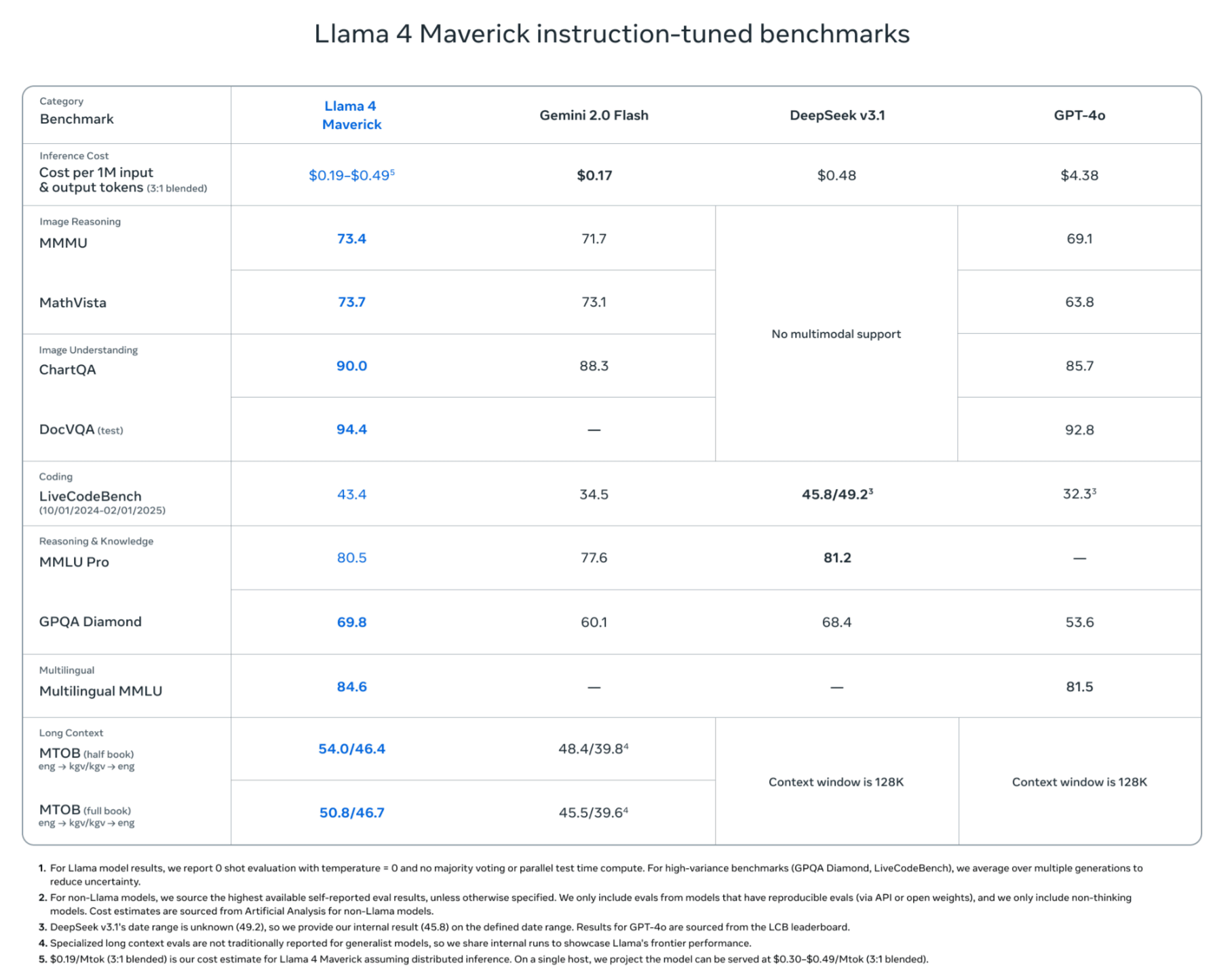
「Llama 4 Maverick」は170億のアクティブパラメーターを持ち、128のエキスパートを搭載。総パラメーター数は4000億で、単一のNVIDIA DGX H100で実行可能。より高度な推論やコーディングタスクに特化しており、OpenAIのGPT-4oやDeepSeek-V3と同等以上の精度を、より少ない計算資源で達成するよう設計されています。
ただし、IT系ニュースサイトのTechCrunchは、ベンチマークに使われたLlama 4 Maverickが一般に公開されているものとは異なる「会話用に調整された実験用バージョン」だったことから、「LM Arenaなどの評価プラットフォームで示された性能が、実際に開発者や一般ユーザーが利用できるモデルと一致しない可能性がある」と指摘しています。実際に、LM Arena版のMaverickは絵文字の多用や冗長な応答傾向が観察されており、一般版とは明らかに挙動が異なると研究者が報告しています。
Okay Llama 4 is def a littled cooked lol, what is this yap city pic.twitter.com/y3GvhbVz65
— Nathan Lambert (@natolambert) April 6, 2025
最上位モデルとなる「Llama 4 Behemoth」は、2880億のアクティブパラメーターと16のエキスパートを搭載し、総パラメーター数が2兆に及ぶ巨大モデルです。Metaによると、このモデルはSTEM分野におけるベンチマークで、GPT-4.5やClaude 3 Sonnetを上回る成績を記録しており、特に数学・プログラミング・科学系の課題において高い精度を発揮するとのこと。ただし、記事作成時点ではまだトレーニング中で、リリースされていません。
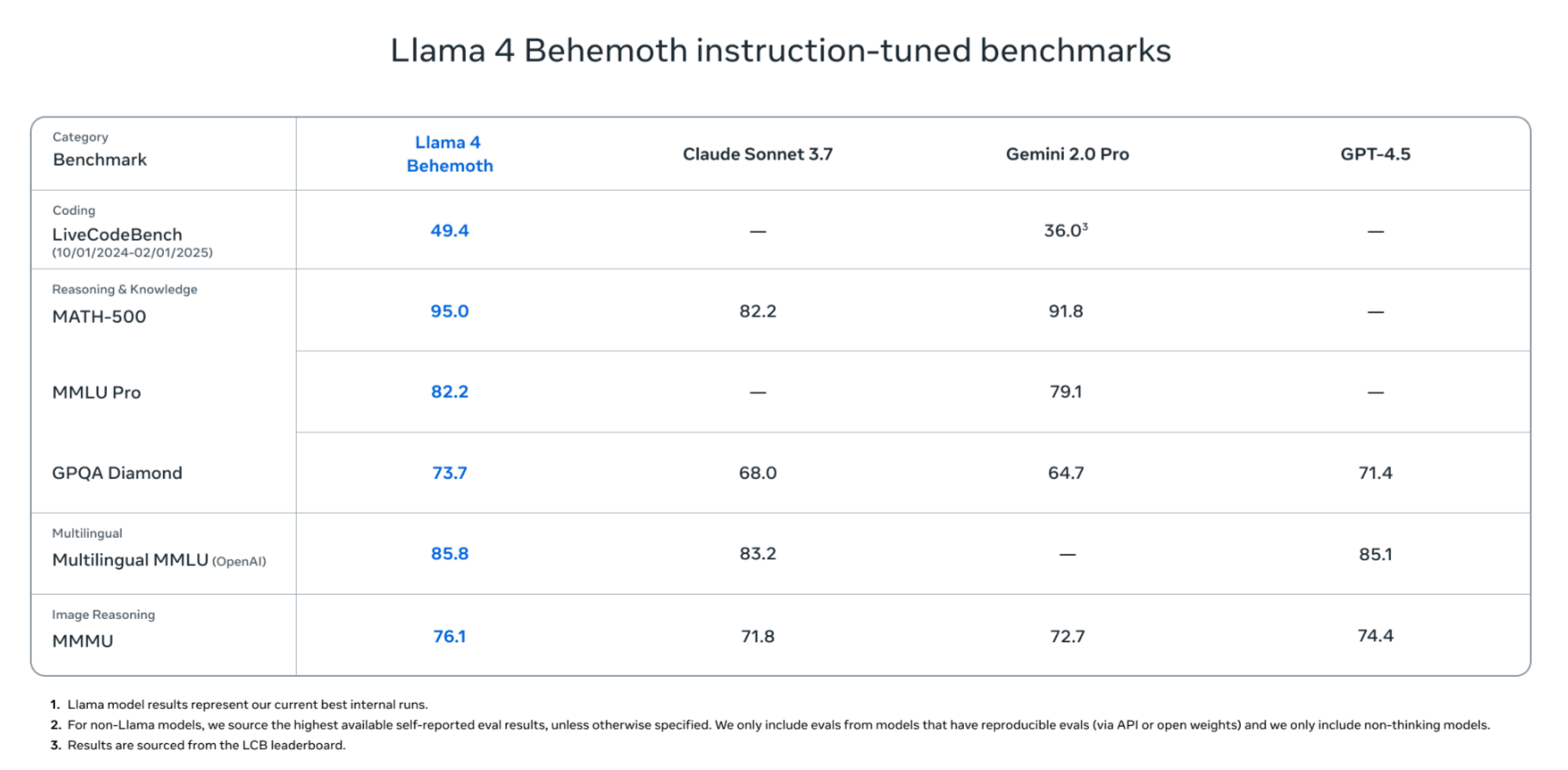
Llama 4シリーズは200以上の言語をサポートし、前世代のLlama 3と比較して他言語トークンが10倍に増加。また、政治的・社会的な議論が多いトピックへの拒否率が大幅に減少したほか、バイアス軽減のための取り組みも進めているとMetaは述べています。
これらの新モデルはMetaのAIアシスタントに順次組み込まれる予定で、記事作成時点で、WhatsAppやMessenger、Instagram、ウェブブラウザ版のMetaAIで利用可能。また、Llama 4 ScoutとLlama 4 Maverickは、モデルがllama.comあるいはHugging Faceで公開されており、今後研究コミュニティに向けて研究用のモデルアクセスも提供予定となっています。
・関連記事
SEO100点をGIGAZINEが達成、2025年1月のGIGAZINEいろいろやったことデータランキングまとめ - GIGAZINE
Metaは10万台以上のNVIDIA H100を使用してLlama-4をトレーニングしている - GIGAZINE
さまざまなAIをWindowsのローカルPCで動かせる「Run llama.cpp Portable Zip on Intel GPU with IPEX-LLM」がDeepSeekにも対応したことをIntelが発表 - GIGAZINE
Llama 3.3 70BベースでGPT-4o超えの満足度を達成するAIをPerplexityが発表 - GIGAZINE
MetaがAIモデル「Llama 3.3」をリリース、70BモデルでLlama 3.1の405Bモデルに匹敵する性能を発揮 - GIGAZINE
Metaのマーク・ザッカーバーグCEOがAI「Llama」の開発チームに対し著作権で保護された作品の無断使用を許可したと訴訟で追及される - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article Meta releases next-generation multimodal….