




複数のPCからリソースをかき集めて巨大なAIモデルをローカル実行できる「mesh-llm」
Mesh LLMは、複数のコンピューターの余剰GPU計算資源を持ち寄り、1台では動かしにくい大規模言語モデルを分散実行できるようにする仕組みです。OpenAI互換APIを備えており、既存のAIツールやエージェントからそのまま使いやすい点が特徴です。
mesh-llm — Decentralised LLM Inference
https://docs.anarchai.org/
michaelneale/mesh-llm: reference impl with llama.cpp compiled to distributed inference across machines, with real end to end demo
https://github.com/michaelneale/mesh-llm
Mesh LLMは余剰GPUを束ねて大きなモデルを動かすための分散推論基盤であり、同時に複数モデル運用やエージェント連携、知識共有まで含めて扱えるのが特徴です。また、自分専用のプライベートメッシュだけでなく、他人と共有できる公開メッシュを作成することもできます。1台では重すぎるLLMをみんなの計算資源で動かせるようにしつつ、使い勝手もなるべく普通のAIサービスに近づけた仕組みだといえます。
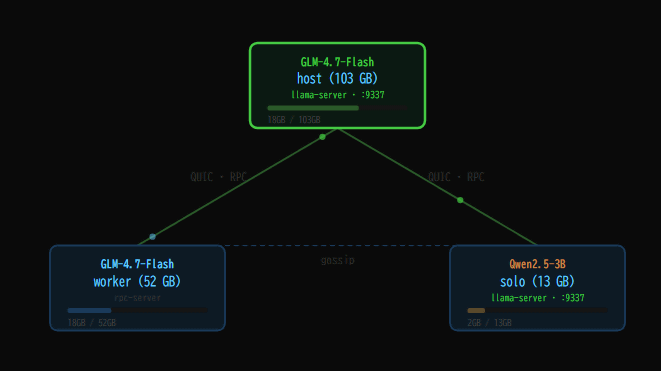
仕組みとしては、モデルが1台のマシンに収まる場合はそのままローカルで実行し、収まらない場合だけ複数ノードに分散します。通常のDense modelではレイヤーごとに処理を分けるパイプライン並列化を使い、MoEモデルではエキスパートを各ノードに分散配置する方式を取ります。特にMoEでは、推論中のノード間通信をできるだけ減らすよう設計されています。
性能面では、モデルの重みをネットワーク越しに送るのではなく、各ノードのローカルファイルから直接読み込むことで起動時間を短縮しています。さらに、小型モデルで候補を先に出し、大型モデルでまとめて確認する投機的デコードにも対応しており、処理速度の向上を狙っています。
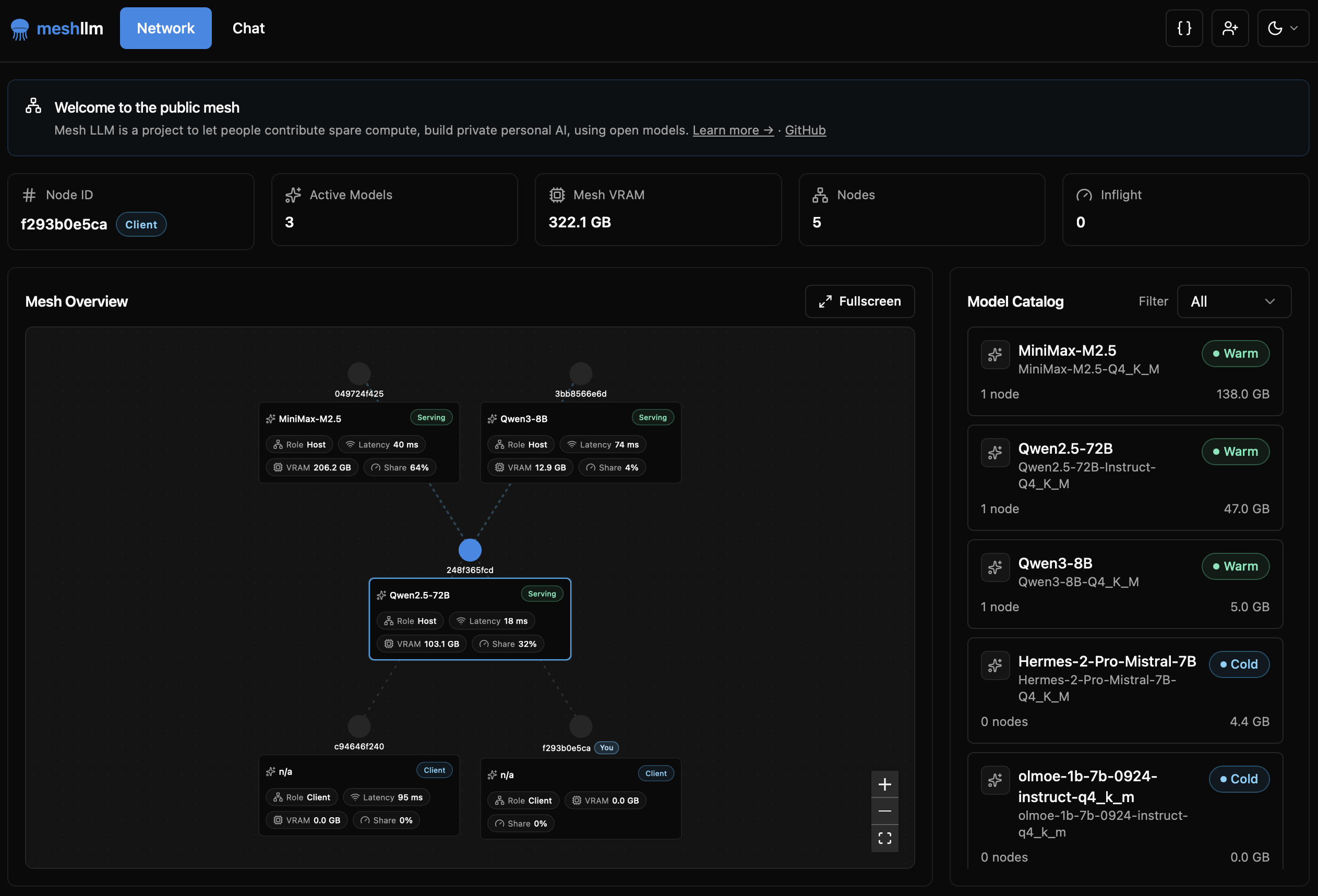
Mesh LLMは1つのモデルを分散実行するだけでなく、複数のモデルを同時に扱える点も特徴です。どのモデルをどのノードで動かすかを自動で振り分け、需要が高いモデルには待機ノードを回す仕組みも備えています。公開メッシュを自動発見して参加する機能もあり、GPUを持たない環境でもクライアント専用ノードとして利用できます。
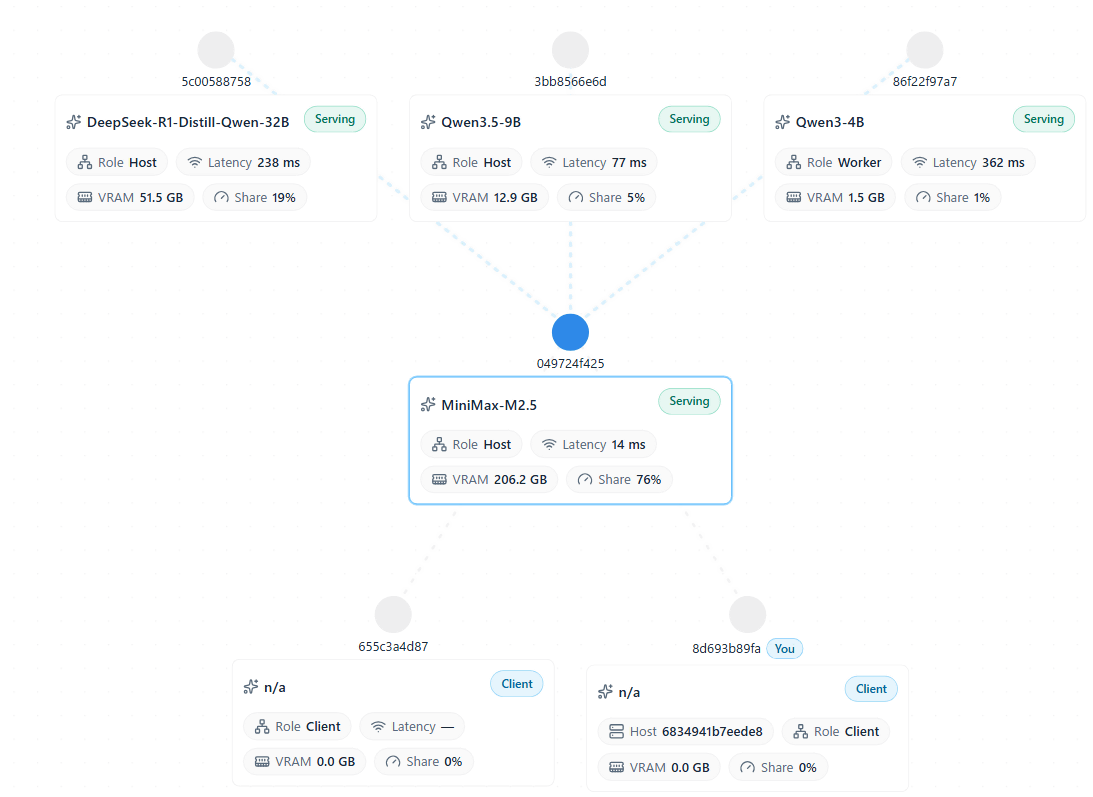
利用者向けにはウェブコンソールが用意されており、メッシュの接続状況や各ノードのVRAM使用量、利用可能なモデルなどをブラウザから確認できます。また、ブラックボードという知識共有機能もあり、エージェント同士や利用者同士が作業状況や調査結果を共有できます。これはGPUなしでも使えますが、公開メッシュでは投稿内容が他の参加者にも見えるため、私的利用では非公開メッシュが推奨されています。
・関連記事
スマホでAIモデルをローカル実行できる無料アプリ「Off Grid」レビュー、LLMも画像生成モデルも実行可能でiOS・Androidどっちも対応 - GIGAZINE
無料&広告なしで音声をテキストに変換できるアプリ「Notely Voice」レビュー、ネット接続不要でスマホのみでWhisperを実行して長文メモを簡単に作れる - GIGAZINE
チャット形式でプログラミングが可能なローカルで動作するオープンソースなAIツール「Open Interpreter」を使ってみた - GIGAZINE
AndroidスマホでもiPhoneでもAIモデルをローカルで実行してチャットできる無料アプリ「Cactus Chat」レビュー - GIGAZINE
無料でiPhone/iPad・AndroidスマホでいろいろなローカルAIを動かしチャット&ローカルAIベンチマークができるオープンソースアプリ「PocketPal AI」、サブスク不要&オフラインでどこでも利用可能 - GIGAZINE
・関連コンテンツ








in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article 'mesh-llm' allows you to locally run mas….