'mesh-llm' allows you to locally run massive AI models by gathering resources from multiple PCs.
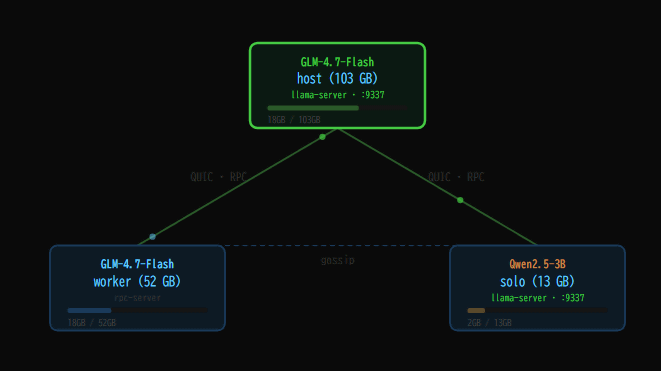
Mesh LLM is a mechanism that brings together the surplus GPU computing resources of multiple computers to enable distributed execution of large-scale language models that would be difficult to run on a single computer. It features an OpenAI-compatible API, making it easy to use directly with existing AI tools and agents.
mesh-llm — Decentralized LLM Inference
michaelneale/mesh-llm: reference impl with llama.cpp compiled to distributed inference across machines, with real end to end demo
https://github.com/michaelneale/mesh-llm
Mesh LLM is a distributed inference platform that aggregates surplus GPUs to run large models, and is characterized by its ability to handle multiple models simultaneously, agent coordination, and knowledge sharing. In addition to private meshes for personal use, it is also possible to create public meshes that can be shared with others. It can be said that this system makes LLM, which is too heavy for a single machine, run using everyone's computing resources, while making it as user-friendly as possible to ordinary AI services.
The mechanism works as follows: if the model fits on a single machine, it runs locally; if not, it is distributed across multiple nodes. While typical Dense models use pipeline parallelism, separating processing by layer, MoE models employ a method of distributing experts across each node. MoE, in particular, is designed to minimize inter-node communication during inference.
In terms of performance, startup time is reduced by reading model weights directly from local files on each node, rather than sending them over the network. Furthermore, it supports speculative decoding, which first generates candidates with a small model and then checks them all together with a larger model, aiming to improve processing speed.
Mesh LLM is characterized not only by its ability to distribute the execution of a single model, but also by its ability to handle multiple models simultaneously. It automatically allocates which model runs on which node, and has a mechanism to allocate standby nodes for models with high demand. It also has a function to automatically discover and join public meshes, and can be used as a dedicated client node even in environments without GPUs.
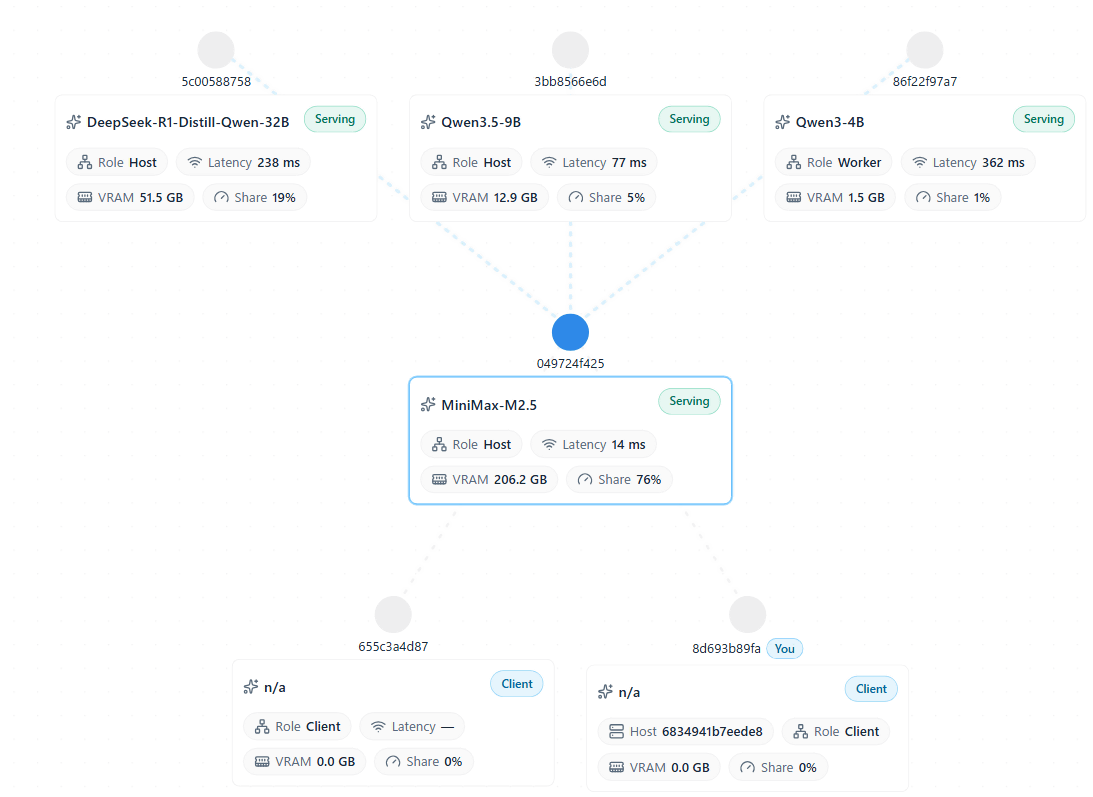
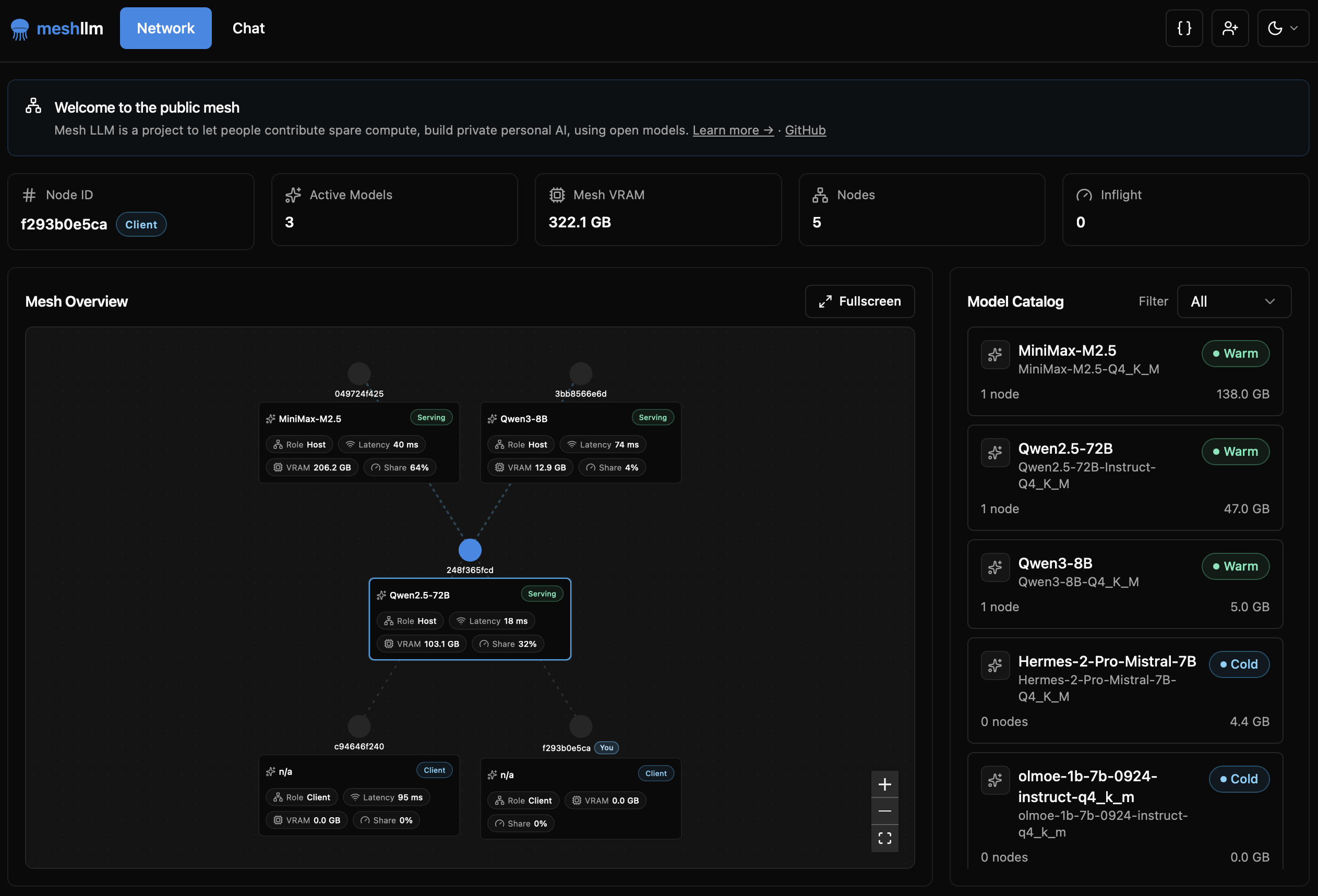
A web console is available for users, allowing them to check the mesh connection status, VRAM usage of each node, and available models from their browser. There is also a knowledge-sharing feature called Blackboard, which allows agents and users to share their work status and research findings with each other. This can be used even without a GPU, but since posts are visible to other participants in public meshes, private meshes are recommended for personal use.
Related Posts:







