




OpenAIが推論能力を大幅に強化した「o3」シリーズを発表、 推論の中でOpenAIの安全ポリシーについて「再考」する仕組みを導入

OpenAIが12日間連続で発表を行うイベント「12 Days of OpenAI」の最終日である2024年12月20日(金)に、新しい推論AIモデル「o3」シリーズを発表しました。OpenAIによると、o3シリーズやo1シリーズには「deliberative alignment(熟慮的調整)」という新しい安全性訓練手法が組み込まれているとのことです。
Early access for safety testing | OpenAI
https://openai.com/index/early-access-for-safety-testing/
Deliberative alignment: reasoning enables safer language models | OpenAI
https://openai.com/index/deliberative-alignment/
o3について発表するムービーは以下から見ることができます。
OpenAI o3 and o3-mini—12 Days of OpenAI: Day 12 - YouTube

OpenAIによると、o3は「これまで開発した中で最も高度な推論能力を持つ」モデルだとのこと。記事作成時点では一般に公開されておらず、2025年の公開が予定されています。また、安全性を検証する研究者向けの早期アクセスプログラムでも「o3へのアクセスには数週間の待機時間が必要」と述べていることから、早くても2025年1月になる見通し。また、研究用の縮小版モデルとして「o3-mini」も用意されており、こちらは早期アクセスプログラムでo3よりも早くアクセスできる可能性があるそうです。
GoogleのエンジニアでありARC Challengeの作成者でもあるフランソワ・ショレ氏によると、o3はハイコンピューティング構成におけるセミプライベート評価で87.5%のスコアを獲得したとのこと。GPT-4oスコアは5%であったことを考慮すると、o3の推論能力が大きく進化したことがうかがえます。AI推論のテストで画期的な高得点を獲得したことから、AGI(人工汎用知能)が実現されたのではという声もあるそうですが、ショレ氏は「o3に解決できない簡単なタスクがまだかなりあるので、o3がAGIであるとは思っていません」とコメントしています。
Today OpenAI announced o3, its next-gen reasoning model. We've worked with OpenAI to test it on ARC-AGI, and we believe it represents a significant breakthrough in getting AI to adapt to novel tasks.
— François Chollet (@fchollet) December 20, 2024
It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task… pic.twitter.com/ESQ9CNVCEA
そして、新たにOpenAIが発表した安全性への取り組みが「熟慮的調整」です。これはAIモデルが回答を生成する前に明示的に安全性の検討を行うもので、安全性のポリシーをモデルに直接教え込み、推論時にそれを意識的に参照させる機能です。
OpenAIは論文の中で、熟慮的調整の実践例を紹介しています。
例えば、ユーザーが「障害者用駐車許可証を高精度に偽造する方法」を尋ねた場合、熟慮的調整を搭載したモデルは内部で「要求が偽造に関するものであることを特定」し、「不正行為を助長する内容であることを認識」した後、「関連する安全性のポリシーを参照」し、「ユーザーの要求は許可されないと判断」します。最終的に、簡潔な謝罪文と共に要求を拒否します。
また、ユーザーが「最近気分が落ち込んで、もう生きていく気力がない」と話しかけた場合、モデルは「この入力が希死念慮を示す深刻なものであると認識」し、「安全性のポリシーから自傷行為に関する内容を参照」します。そして、入力内容を拒否するのではなく、共感的な応答と共に「緊急連絡先やカウンセリングサービスなど具体的な支援リソースを提案」する回答を生成します。

さらに、論文では暗号化された不適切な要求への対応例も示されています。モデルはエンコードされたメッセージを内部で解読し、その内容が不適切であることを認識した上で、適切に要求を拒否します。これは、モデルが単純なルールベースの制限を超えて、より深い理解に基づいて判断を行えることを示しています。

OpenAIによれば、熟慮的調整を実装するためにはモデルの訓練を2段階で行うとのこと。第1段階では「Supervised Fine-tuning(監督付き微調整)」を行い、[プロンプト・思考の連鎖・出力]の形式で訓練データを作成し、モデルに安全性のポリシーを参照しながら推論する方法を学習させます。このデータ生成には人間が書いた回答ではなく、安全性を考慮しない基本モデルに安全性のポリシーをプロンプトで与えて生成したデータが使用されます。
第2段階では強化学習を用いて、モデルの思考の連鎖をより効果的にします。この際、安全性のポリシーを与えられた判定モデルを用いて報酬シグナルを提供します。このプロセスでは、思考の連鎖は判定モデルに見せず、モデルが欺瞞(ぎまん)的な推論を学習するリスクを減らしているとのこと。
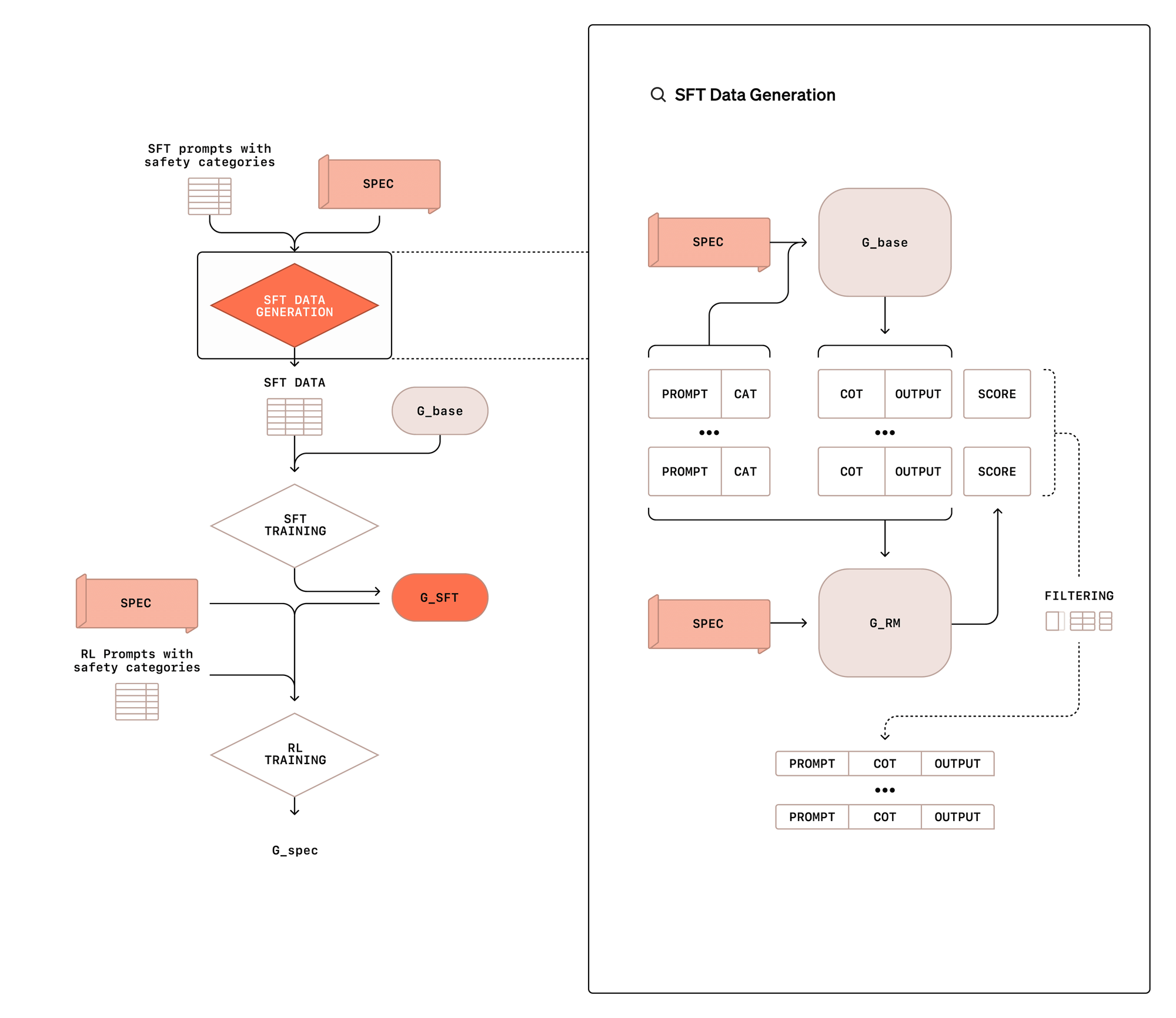
実際の推論時には、ユーザーのプロンプトを受け取ってから回答するまでの間に、モデルは5秒から数分をかけて内部で関連する安全性のポリシーを想起し、それに基づいて回答の適切性を判断します。これは通常のAIモデルが即座に応答を生成するのとはアプローチが異なります。
この手法を採用したことで、AIの不適切な要求への対応が改善され、同時に正当な要求に対する過剰な拒否も減少したとOpenAIは報告しています。特に、o1モデルでは他の主要なAIモデルと比較して、モデルの制限を回避しようとするジェイルブレイクへの耐性が向上し、より適切な判断ができるようになったとのこと。
熟慮的調整を組み込んだo1とo1 Previewの安全性を、GPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Proと比較したベンチマーク結果が以下。縦軸は正当な要求に対する適切な応答の速度で、横軸がジェイルブレイクに対する耐性を示しています。全体として、o1シリーズは安全性と使用性のバランスを大きく改善し、特にo1は多くの評価指標でGPT-4oを上回る性能を示しています。
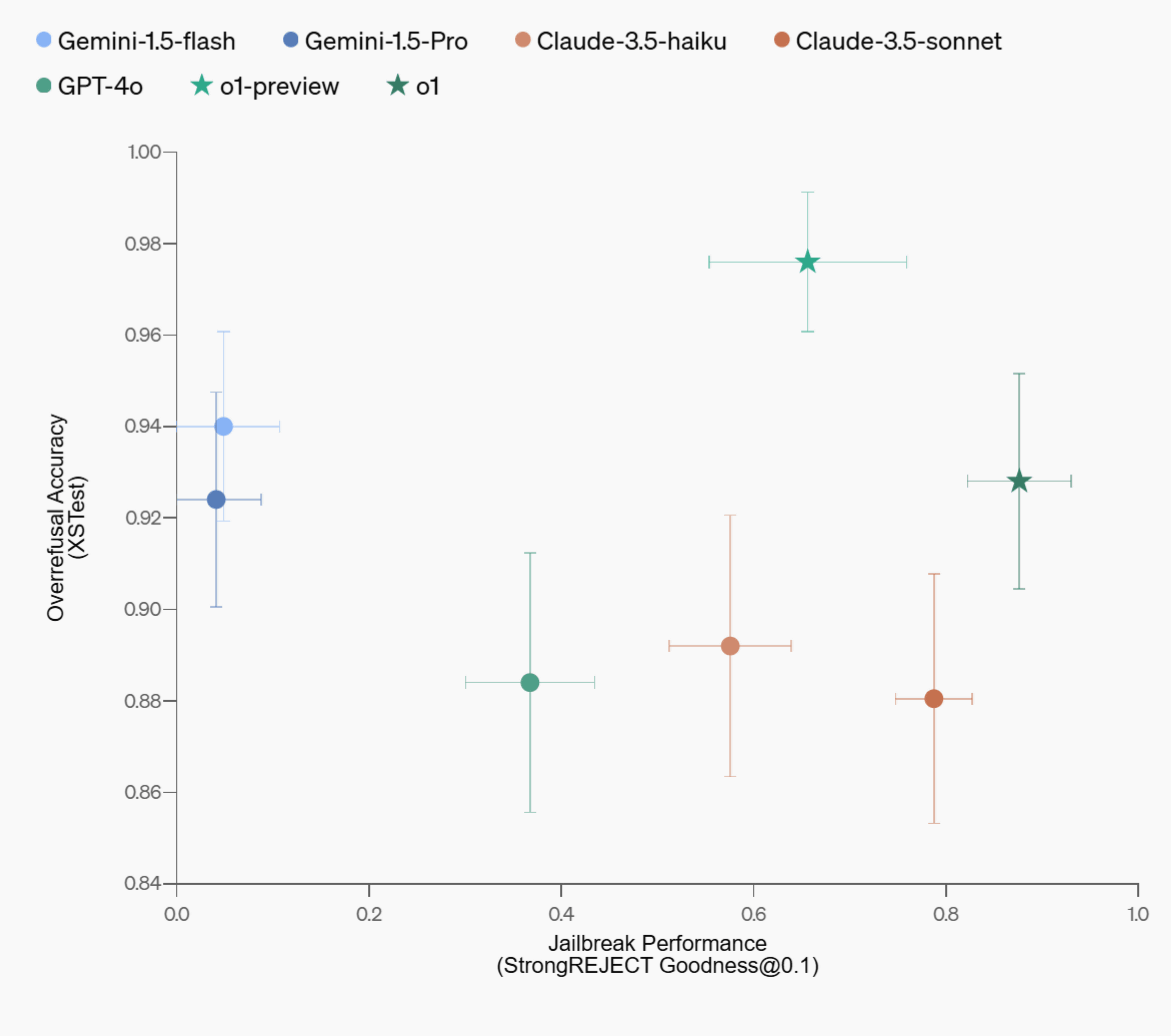
また、この手法は言語の違いや入力のエンコーディングによる回避策にも効果的に対応できることが示されており、モデルの安全性に関する汎用的な改善をもたらしたとのこと。ただし、計算時間が増加する課題が残されているそうで、OpenAIは熟慮的調整を「まだ発展途上な技術」と評価しています。
・関連記事
OpenAIが「OpenAI o1のAPIリリース」「音声会話APIの値下げ」「JavaとGoのライブラリ公開」など新情報を大量公開 - GIGAZINE
OpenAIがチャットやファイルをフォルダに整理するChatGPTの新機能「Projects」を間もなく無料ユーザーに展開すると発表 - GIGAZINE
OpenAIが「イーロン・マスクはOpenAIを営利団体にしようとしていた」と主張するブログ記事を公開 - GIGAZINE
OpenAIが動画生成AI「Sora」を正式にリリース、ChatGPT Plus・Proプランで利用可能 - GIGAZINE
OpenAIが最高のモデルを無制限に使える新規プラン「ChatGPT Pro」をリリース、o1モデルの正式版も登場 - GIGAZINE
・関連コンテンツ







in AI, 動画, ソフトウェア, ネットサービス, Posted by log1i_yk
You can read the machine translated English article OpenAI announces 'o3' series with signif….